Downloaded 102 times







![Support vector machine (SVM)
• Non-probabilistic binary linear classifier
• Can parametrize the number of iteractions
• Slower!
• “One Vs. All” approach with committee [1 e 2]
• Six models, then 21 models
• The model that had more votes is the winner
[1] e Silva, Sergio Roberto de Lima, and
Mauro Roisenberg. "Continuous
authentication by keystroke dynamics
using committee machines." Intelligence
and Security Informatics. Springer Berlin
Heidelberg, 2006. 686-687.
[2] Sun, Bing-Yu, et al. "Support vector
machine committee for
classification."Advances in Neural
Networks–ISNN 2004. Springer Berlin
Heidelberg, 2004. 648-653.
Finance Vs. Sport Finance Vs. Movies Finance Vs. Cars
Sport Vs. Movies Sport Vs. Cars
Movies Vs. Cars](https://image.slidesharecdn.com/smart-crawler-lhzs-ia-ufsc-2015-150603140002-lva1-app6891/85/Smart-Crawler-11-320.jpg)

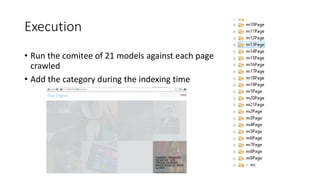
![Implementation details - Training
1. Set of pages is used as input to the models
String [] pagesCars={"http://g1.globo.com/carros/index.html","http://quatrorodas.abril.com.br/"};
String [] pagesFinance={"http://www.valor.com.br/","http://www.infomoney.com.br/", "http://exame.abril.com.br/"};
String [] pagesSport={"http://globoesporte.globo.com/","http://oledobrasil.com.br/","http://espn.uol.com.br"};
String [] pagesMovies={"http://www.imdb.com/list/ls002231878/","http://www.adorocinema.com/","http://www.filmeb.com.br/",
"http://www.revistabula.com/3165-lista-dos-100-melhores-filmes-de-todos-os-tempos-segundo-hollywood/"};
2. Set of pages is used as input to the models](https://image.slidesharecdn.com/smart-crawler-lhzs-ia-ufsc-2015-150603140002-lva1-app6891/85/Smart-Crawler-13-320.jpg)





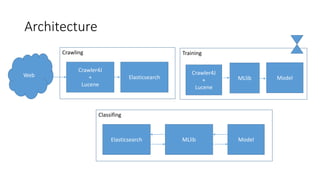
The document outlines a smart crawler designed to classify web page contents into categories such as finance, sports, movies, and cars using machine learning techniques like Naive Bayes and Support Vector Machines (SVM). It discusses the architecture of the system, tools used for crawling and parsing, and the process for training and testing models. Despite achieving good classification accuracy, the document highlights challenges faced, such as template issues and the need for better training data.













































































