네트워크 경량화의 종류
1.Efficient Architecture Design: 효율이 높은 아키텍쳐를 설계
2. Network Pruning: 중요도가 낮은 파라미터를 제거
3. Network Quantization: 파라미터를 좀 더 작은 크기의 타입으로 표현
4. Knowledge Distillation: 학습된 큰 네트워크를 작은 네트워크 학습에 사용
5. Network Compile: 바이너리 형태로 네트워크를 변환
6. Matrix Decomposition: 네트워크의 행렬 연산을 더 작은 행렬 연산으로 변환
…
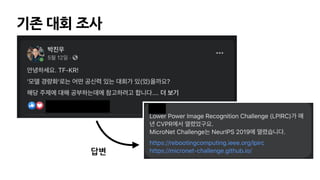
Lower Power ImageRecognition Challenge (LPIRC)
CVPR에서 매년 열리는 경량화 대회
•2019년 대회 내용
- https://ieeexplore.ieee.org/document/8693826
•실제 장비 위에서의 추론 결과를 평가지표로 사용
- 점수: Accuracy (mAP) / Energy (Watt-Hour)
•트랙: Image Classification / Object Detection / 시간 내 모든 데이터 추론
- 1, 2번 트랙은 지정된 라이브러리, 하드웨어만 사용가능
•참가팀들의 주요전략
- 입력 사이즈 낮추기
- Quantization
- 소프트웨어 및 하드웨어 최적화
13.
•2019년 대회 내용
-https://ieeexplore.ieee.org/document/8693826
•실제 장비 위에서의 추론 결과를 평가지표로 사용
- 점수: Accuracy (mAP) / Energy (Watt-Hour)
•트랙: Image Classification / Object Detection / 시간 내 모든 데이터 추론
- 1, 2번 트랙은 지정된 라이브러리, 하드웨어만 사용가능
•참가팀들의 주요전략
- 입력 사이즈 낮추기
- Quantization
- 소프트웨어 및 하드웨어 최적화
Lower Power Image Recognition Challenge (LPIRC)
CVPR에서 매년 열리는 경량화 대회
구현 미공개
14.
MicroNet Challenge
NeurIPS 2019에서열린 경량화 대회
•대회 내용
- https://micronet-challenge.github.io/
•네트워크의 총 연산횟수, 파라미터의 갯수, 크기를 평가지표로 사용
- 제출한 네트워크는 대회에서 제시한 최소 성능을 만족해야 함
- 베이스라인 네트워크에 대비한 연산횟수, 파라미터 갯수를 비율로 합산하여 점수로 환산
- Quantization을 적용한만큼 연산횟수 및 파라미터 갯수가 줄어든 것으로 계산
- 네트워크의 Sparsity(0이 있는 정도)만큼 연산횟수 및 파라미터 갯수가 줄어든 것으로 계산
•트랙: ImageNet Classification / CIFAR-100 Classification
15.
•대회 내용
- https://micronet-challenge.github.io/
•네트워크의총 연산횟수, 파라미터의 갯수, 크기를 평가지표로 사용
- 제출한 네트워크는 대회에서 제시한 최소 성능을 만족해야 함
- 베이스라인 네트워크에 대비한 연산횟수, 파라미터 갯수를 비율로 합산하여 점수로 환산
- Quantization을 적용한만큼 연산횟수 및 파라미터 갯수가 줄어든 것으로 계산
- 네트워크의 Sparsity(0이 있는 정도)만큼 연산횟수 및 파라미터 갯수가 줄어든 것으로 계산
•트랙: ImageNet Classification / CIFAR-100 Classification
구현 공개
MicroNet Challenge
NeurIPS 2019에서 열린 경량화 대회
MicroNet Challenge
KAIST AI(CIFAR-100 Track 2위팀)
MobileNet-v3의 축소판 네트워크를 정의하고 MicroNet이라 명명 (0.75M)
1. 네트워크 학습 (600 epochs)
2. 네트워크 가중치를 45%까지 pruning한 뒤, 다시 학습 (600 epochs)
3. 네트워크 가중치를 65%까지 pruning한 뒤, 다시 학습 (600 epochs)
ㅋ
https://github.com/Kthyeon/micronet_neurips_challenge
18.
MicroNet Challenge
• MixNet/ EfficientNet / MobileNet-v2 or v3를 주로 사용
• One-Shot Pruning보다는 Iterative Pruning을 이용
• Quantization 또한 점진적으로(Iterative) 적용하는 경우가 많음
• Pruning과 Quantization을 한 뒤, fine-tuning 또는 재학습 과정에서
Knowledge Distillation을 흔히 사용
• Learning Rate Scheduler로 Cosine Annealing이 많이 이용
• Regularization 전략을 적극적으로 이용
상위팀 전략 요약
19.
MicroNet Challenge
상위팀 전략요약 (오늘 다뤄볼 내용)
• MixNet / EfficientNet / MobileNet-v2 or v3를 주로 사용
• One-Shot Pruning보다는 Iterative Pruning을 이용
• Quantization 또한 점진적으로(Iterative) 적용하는 경우가 많음
• Pruning과 Quantization을 한 뒤, fine-tuning 또는 재학습 과정에서
Knowledge Distillation을 흔히 사용
• Learning Rate Scheduler로 Cosine Annealing이 많이 이용
• Regularization 전략을 적극적으로 이용
Efficient Architectures
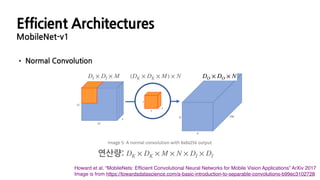
MobileNet-v1
• NormalConvolution
Howard et al. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” ArXiv 2017
Image is from https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
DI × DI × M DO × DO × N
연산량: DK × DK × M × N × DI × DI
(DK × DK × M) × N
23.
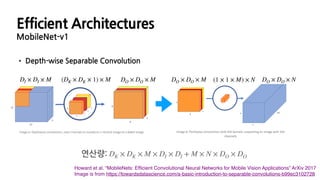
Efficient Architectures
MobileNet-v1
• Depth-wiseSeparable Convolution
연산량: DK × DK × M × DI × DI + M × N × DO × DO
Howard et al. “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications” ArXiv 2017
Image is from https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
DI × DI × M DO × DO × M(DK × DK × 1) × M (1 × 1 × M) × N DO × DO × NDO × DO × M
24.
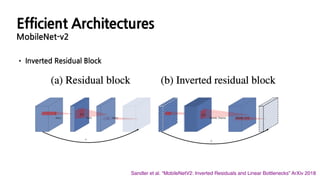
• Inverted ResidualBlock
Sandler et al. “MobileNetV2: Inverted Residuals and Linear Bottlenecks” ArXiv 2018
Efficient Architectures
MobileNet-v2
25.
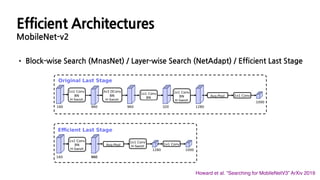
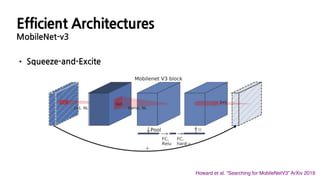
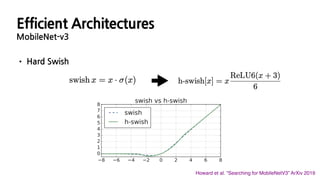
• Block-wise Search(MnasNet) / Layer-wise Search (NetAdapt) / Efficient Last Stage
Howard et al. “Searching for MobileNetV3” ArXiv 2019
Efficient Architectures
MobileNet-v2
Efficient Architectures
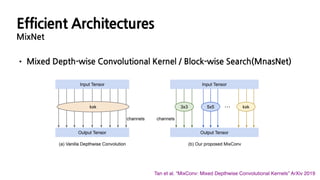
MixNet
• MixedDepth-wise Convolutional Kernel / Block-wise Search(MnasNet)
Tan et al. “MixConv: Mixed Depthwise Convolutional Kernels” ArXiv 2019
29.
Efficient Architectures
EfficientNet
• 입력크기 / 너비 / 깊이와 성능이 같은 FLOPS에도 각 scaling factor에 따라 달라짐에 주목
• MnasNet과 유사한 베이스라인 네트워크(B0)를 정의한 뒤, 로 가정하고 아래의
최적화를 수행하여 탐색
• 를 일정 비율로 증가시키며 여러 형태의 네트워크를 도출 (B1~B7)
ϕ = 1
α, β, γ
ϕ
Tan et al. “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” ArXiv 2019
이 제약조건에 의해
Total FLOPS가 대략 만큼 증가2ϕ
30.
Efficient Architectures
더 볼만한논문들
• Tan et al. “MnasNet: Platform-Aware Neural Architecture Search for Mobile” ArXiv
2018
• Xie et al. “Self-training with Noisy Student improves ImageNet classification” ArXiv
2019
• Xie et al. “Adversarial Examples Improve Image Recognition” ArXiv 2019
• Touvron et al. “Fixing the train-test resolution discrepancy: FixEfficientNet” ArXiv
2020
Network Pruning
소분류
• StructuredPruning: 파라미터를 그룹 단위로 pruning하는 기법들을 총칭. 여기서의 그룹
은 channel / filter, layer 등이 될 수 있다. Dense computation에 최적화된 소프트웨어 또는
하드웨어에 적합한 기법.
• Unstructured Pruning: 파라미터 각각을 독립적으로 pruning하는 기법. 즉, pruning을 수
행할 수록 네트워크 내부의 행렬이 점차 희소(sparse)해진다. Structured Pruning과 달리
sparse computation에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법.
Frankle et al. “WHAT IS THE STATE OF NEURAL NETWORK PRUNING?” ArXiv 2020
34.
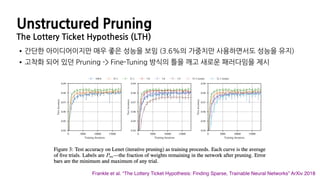
Unstructured Pruning
The LotteryTicket Hypothesis (LTH)
Frankle et al. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” ICLR 2019
• 네트워크의 초기 파라미터 값을 매 pruning iteration 마다 파라미터 초기화에 사용
1. 네트워크를 임의로 초기화 (where )
2. 네트워크를 j번 학습하여 파라미터 를 도출
3. 파라미터 를 p% 만큼 pruning하여 마스크 을 생성
4. 파라미터를 로 초기화하고 이를 당첨된 복권(winning ticket)이라 지칭
5. 2~4를 반복
f(x; θ0) θ0 ∼ Dθ
θj
θj m
θ0 f(x; m ⊙ θ0)
35.
Unstructured Pruning
The LotteryTicket Hypothesis (LTH)
Frankle et al. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” ArXiv 2018
•간단한 아이디어이지만 매우 좋은 성능을 보임 (3.6%의 가중치만 사용하면서도 성능을 유지)
•고착화 되어 있던 Pruning -> Fine-Tuning 방식의 틀을 깨고 새로운 패러다임을 제시
36.
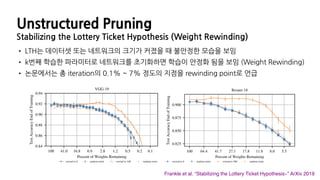
Unstructured Pruning
Stabilizing theLottery Ticket Hypothesis (Weight Rewinding)
• LTH는 데이터셋 또는 네트워크의 크기가 커졌을 때 불안정한 모습을 보임
• k번째 학습한 파라미터로 네트워크를 초기화하면 학습이 안정화 됨을 보임 (Weight Rewinding)
• 논문에서는 총 iteration의 0.1% ~ 7% 정도의 지점을 rewinding point로 언급
Frankle et al. “Stabilizing the Lottery Ticket Hypothesis∗” ArXiv 2019
37.
Unstructured Pruning
COMPARING REWINDINGAND FINE-TUNING IN NEURAL NETWORK PRUNING (Learning Rate Rewinding)
• Fine-tuning처럼 학습한 파라미터 값을 그대로 상속받되, Learning Rate Schedule을 특정 시점
(k)으로 rewinding하는 전략을 제안하고 이를 Learning Rate Rewinding이라 명명
• 저자들은 k=0일때 대체로 좋은 성능을 보이므로 k=0으로 두고 따로 튜닝하지 않는 것을 제안
Renda et al. “COMPARING REWINDING AND FINE-TUNING IN NEURAL NETWORK PRUNING” ArXiv 2020
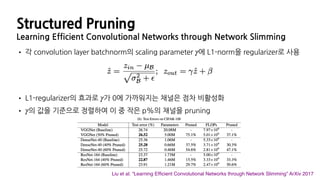
Structured Pruning
Channel-Wise MagnitudeBased Pruning
• 네트워크를 학습한 뒤, Convolution Layer 각 filter의 크기(magnitude)를 구하여
그 크기가 작은 p%의 채널을 pruning하는 방법
1. 모든 convolution filter의 각 가중치에 L1-norm을 취한 것을 합
2. 1에서 구한 값을 기준으로 filter들을 정렬
3. 정렬된 filter 중 값이 작은 p%를 제거
4. 3으로 인해 제거되는 feature map을 염두하여 다음 layer의 filter 차원을 축소
Li et al. “Pruning Filters for Efficient ConvNets” ArXiv 2016
42.
Structured Pruning
Learning EfficientConvolutional Networks through Network Slimming
• 각 convolution layer batchnorm의 scaling parameter 에 L1-norm을 regularizer로 사용
• L1-regularizer의 효과로 가 0에 가까워지는 채널은 점차 비활성화
• 의 값을 기준으로 정렬하여 이 중 작은 p%의 채널을 pruning
γ
γ
γ
Liu et al. “Learning Efficient Convolutional Networks through Network Slimming” ArXiv 2017
43.
Network Pruning
더 볼만한논문들
• Yang et al. “NetAdapt: Platform-Aware Neural Network Adaptation for Mobile
Applications” ArXiv 2018
• Liu et al. “RETHINKING THE VALUE OF NETWORK PRUNING” ArXiv 2018
• Morcos et al. “One ticket to win them all: generalizing lottery ticket initializations across
datasets and optimizers” ArXiv 2019
• Frankle et al. “Linear Mode Connectivity and the Lottery Ticket Hypothesis” ArXiv 2019
• Frankle et al. “WHAT IS THE STATE OF NEURAL NETWORK PRUNING?” ArXiv 2020
Quantizer Design
Uniform AffineQuantizer
• Uniform Affine Quantizer를 이용하여 ( , )의 값의 범위를 가진 floating point
변수를 (0, − 1)의 범위를 가진 integer 변수로 quantization하면 다음과 같다.
xmin xmax
Nlevels
Krishnamoorthi et al. “Quantizing deep convolutional networks for efficient inference: A whitepaper” ArXiv 2018
: Scale
: zero point
Δ
z
47.
Quantizer Design
Uniform SymmetricQuantizer
•Zero-point가 0이며, floating point 변수를 signed integer로 매핑한다.
Krishnamoorthi et al. “Quantizing deep convolutional networks for efficient inference: A whitepaper” ArXiv 2018
: ScaleΔ
48.
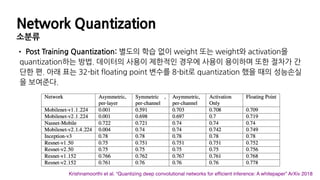
Network Quantization
소분류
• PostTraining Quantization: 별도의 학습 없이 weight 또는 weight와 activation을
quantization하는 방법. 데이터의 사용이 제한적인 경우에 사용이 용이하며 또한 절차가 간
단한 편. 아래 표는 32-bit floating point 변수를 8-bit로 quantization 했을 때의 성능손실
을 보여준다.
Krishnamoorthi et al. “Quantizing deep convolutional networks for efficient inference: A whitepaper” ArXiv 2018
49.
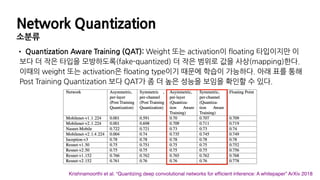
Network Quantization
소분류
• QuantizationAware Training (QAT): Weight 또는 activation이 floating 타입이지만 이
보다 더 작은 타입을 모방하도록(fake-quantized) 더 작은 범위로 값을 사상(mapping)한다.
이때의 weight 또는 activation은 floating type이기 때문에 학습이 가능하다. 아래 표를 통해
Post Training Quantization 보다 QAT가 좀 더 높은 성능을 보임을 확인할 수 있다.
Krishnamoorthi et al. “Quantizing deep convolutional networks for efficient inference: A whitepaper” ArXiv 2018
Knowledge Distillation
Distilling theKnowledge in a Neural Network (a.k.a. Hinton Loss)
• Student network와 ground truth label의 cross-entropy + teacher network와 student
network의 inference 결과에 대한 KLD loss로 정의
• 는 large teacher network의 출력을 smoothing(flat) 하는 역할을 한다.(Soft Target)
• 는 두 loss의 균형을 조절하는 파라미터다.
T
α
Hinton et al. “Distilling the Knowledge in a Neural Network” ArXiv 2015
54.
Knowledge Distillation
Feature DistillationMethods
• Teacher network와 student network의 출력을 이용하는 것과 달리 feature distillation은
네트워크 feature 정보를 이용하여 distillation loss를 정의.
• Ruffy et al. (2019), Tian et al. (2020)은 SOTA임을 주장하는 많은 논문들의 실제 재현성
능이 HintonLoss 를 크게 상회하지 못하였고, 특히 feature distillation methods들은 성능 재
현이 매우 어렵다고 밝혔다.
Tian et al. “Contrastive Representation Distillation” ICLR 2020
https://github.com/HobbitLong/RepDistiller
Ruffy et al. “The State Of Knowledge Distillation For Classification Tasks” ArXiv 2019
https://github.com/karanchahal/distiller
HintonLoss



















































![[IGC 2017] 펄어비스 민경인 - Mmorpg를 위한 voxel 기반 네비게이션 라이브러리 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=640&height=640&fit=bounds)
![[KAIST 채용설명회] 데이터 엔지니어는 무슨 일을 하나요?](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC2017] 딥러닝으로 게임 콘텐츠 제작하기 - VAE를 이용한 콘텐츠 생성 기법 연구 사례](https://cdn.slidesharecdn.com/ss_thumbnails/v072-170426075401-thumbnail.jpg?width=640&height=640&fit=bounds)

![[0410 박민근] 기술 면접시 자주 나오는 문제들](https://cdn.slidesharecdn.com/ss_thumbnails/0410-111117021726-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215]네이버콘텐츠통계서비스소개 김기영](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=640&height=640&fit=bounds)
![오딘: 발할라 라이징 MMORPG의 성능 최적화 사례 공유 [카카오게임즈 - 레벨 300] - 발표자: 김문권, 팀장, 라이온하트 스튜디오...](https://cdn.slidesharecdn.com/ss_thumbnails/t3s1-221108101729-c6b32f4f-thumbnail.jpg?width=640&height=640&fit=bounds)













![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=640&height=640&fit=bounds)


