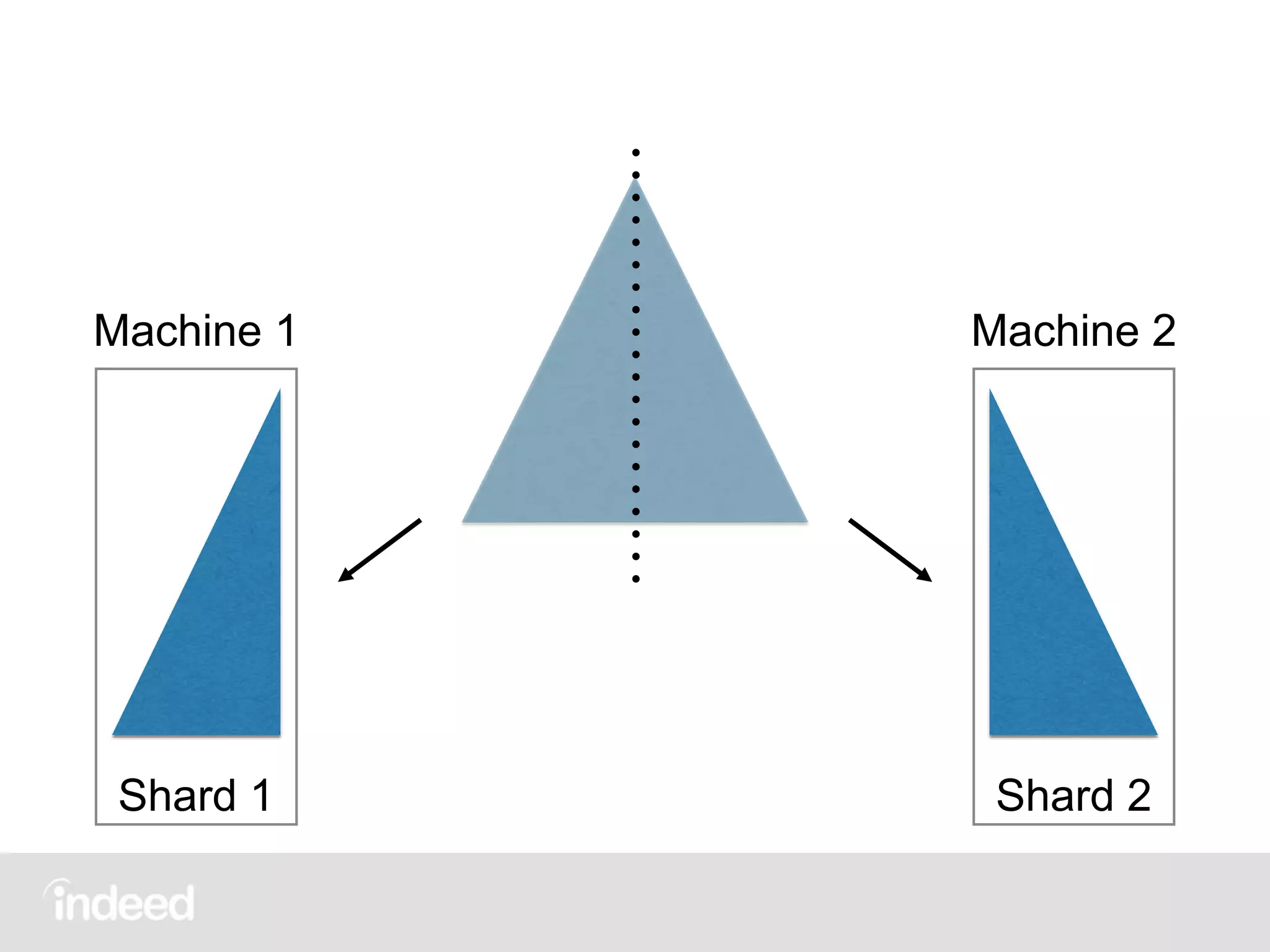
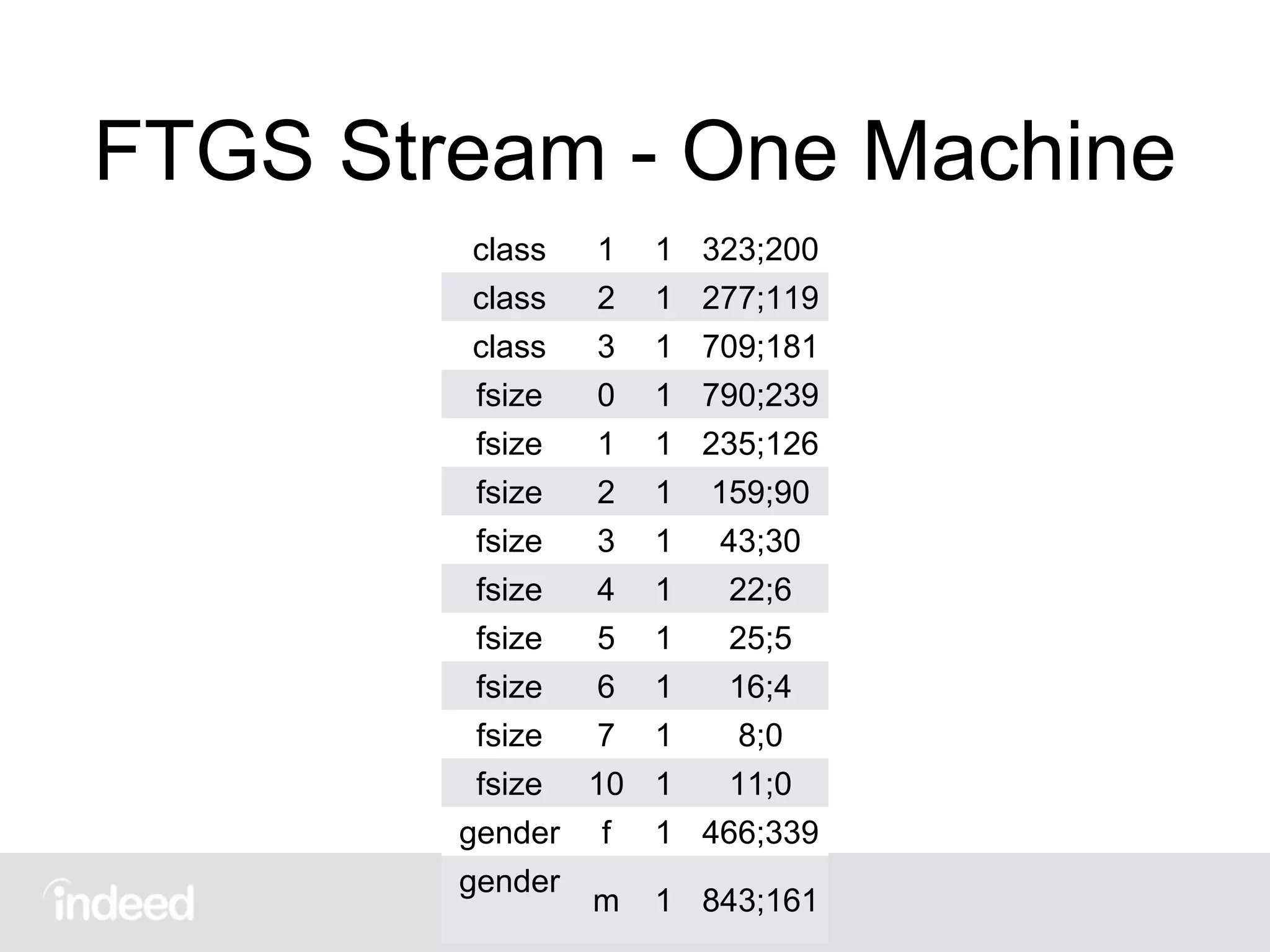
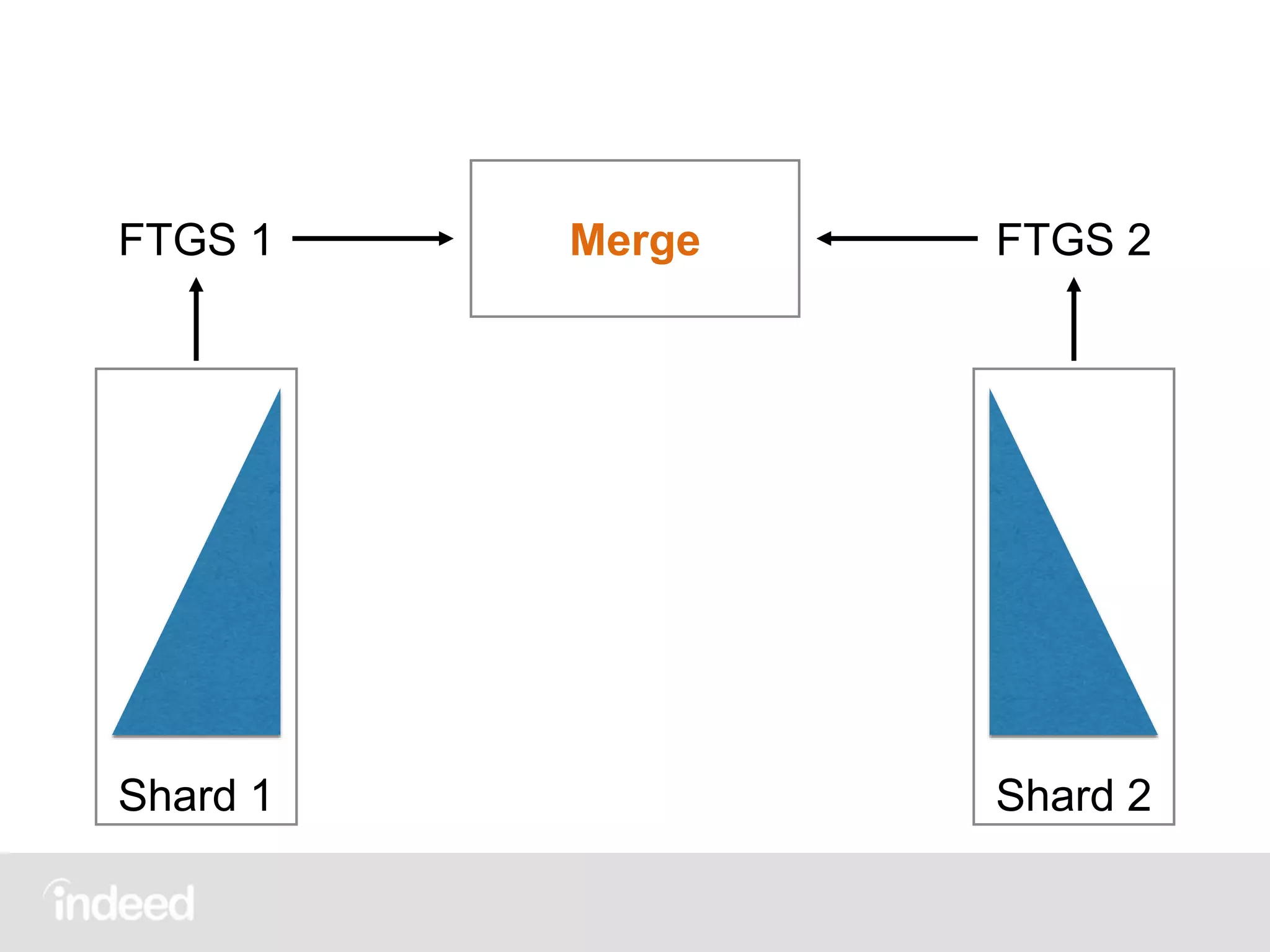
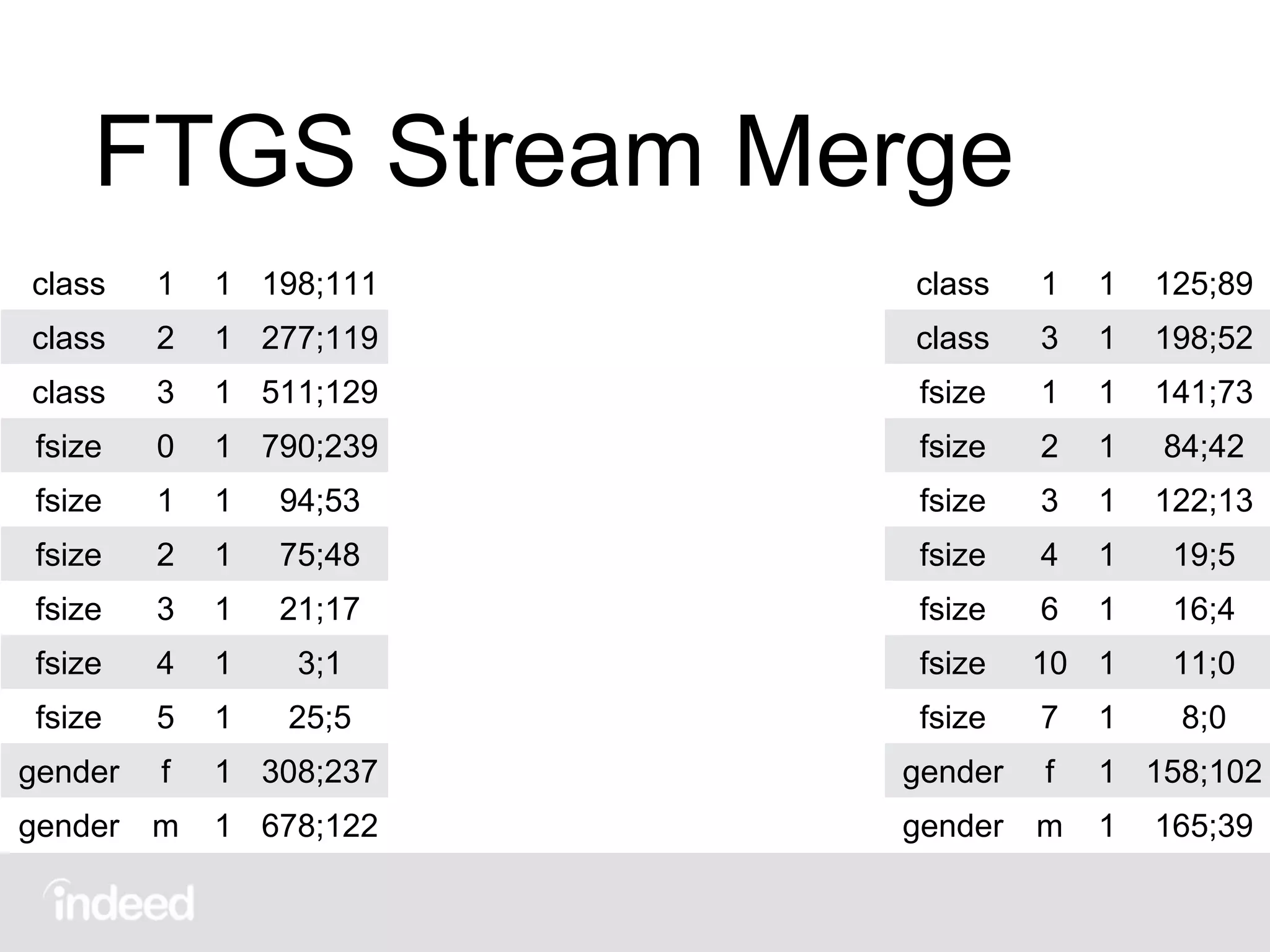
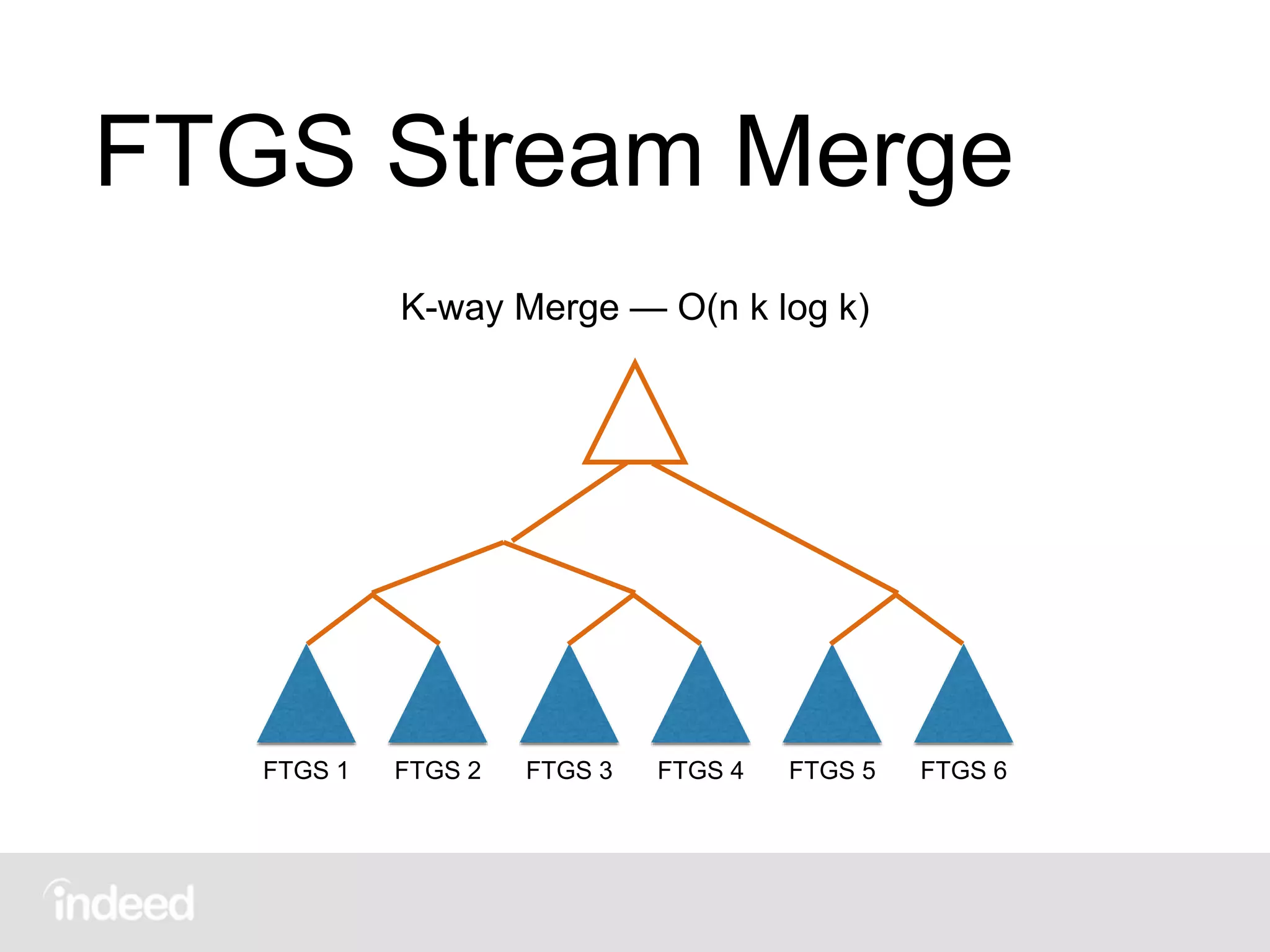
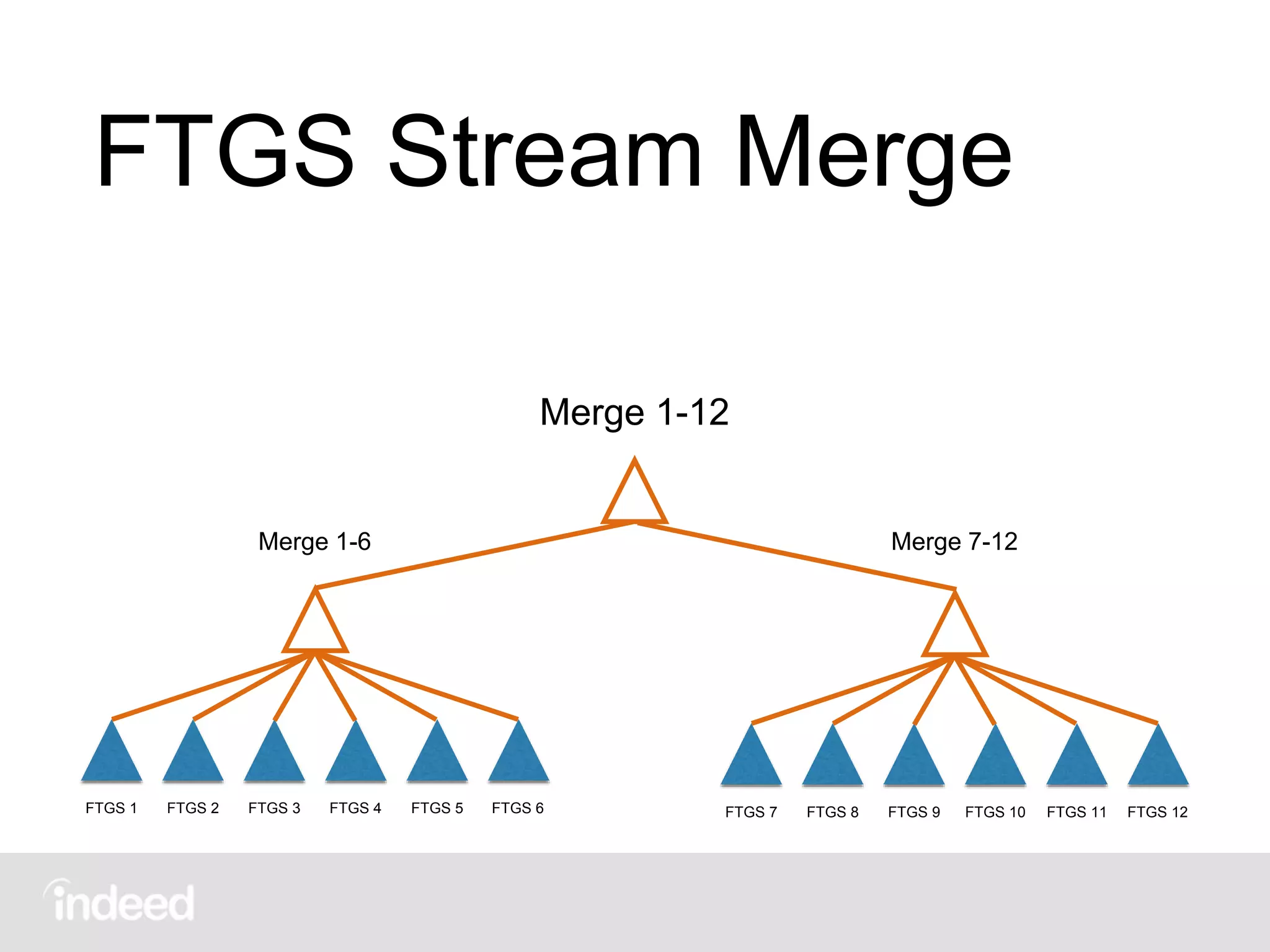
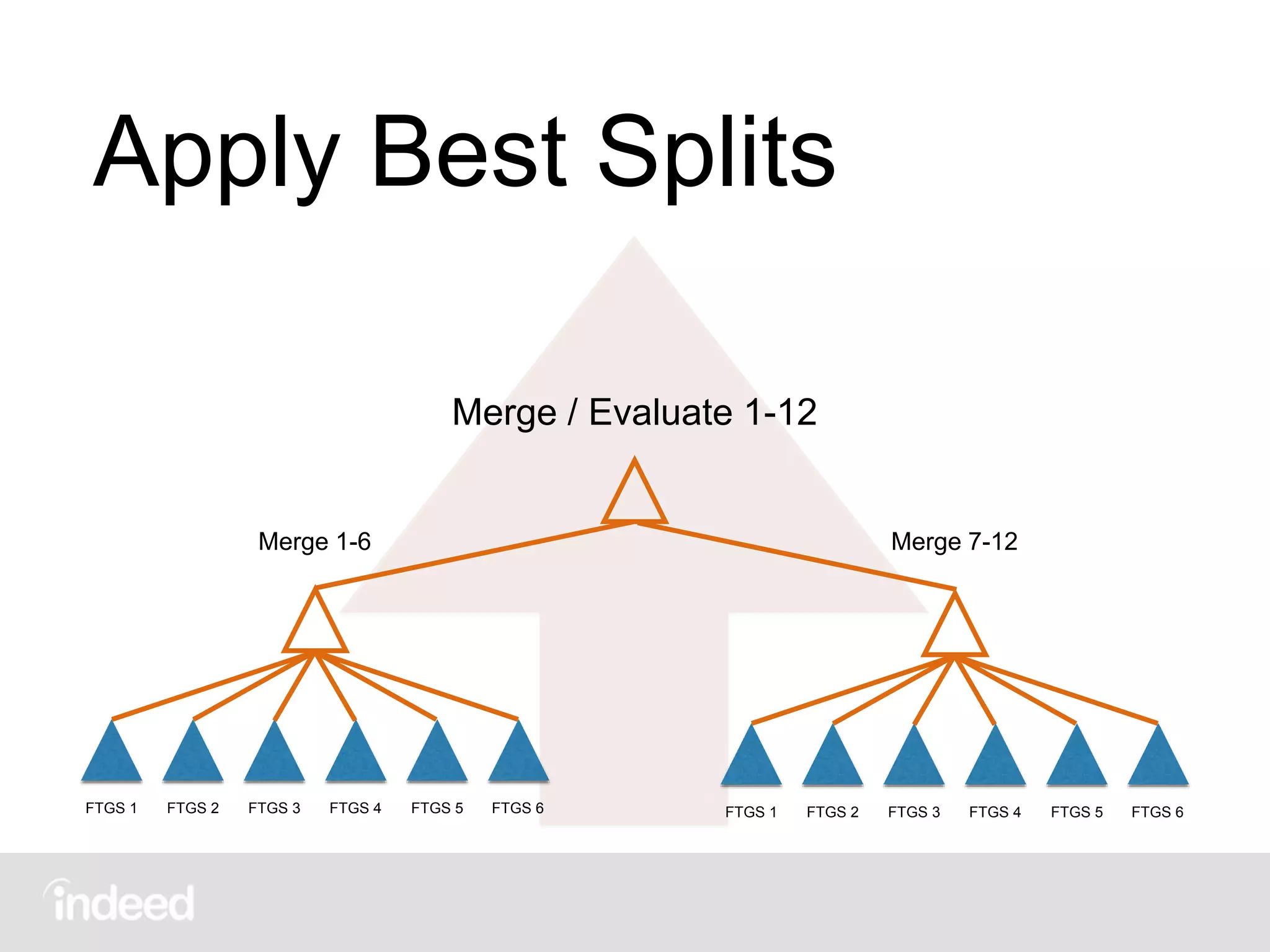
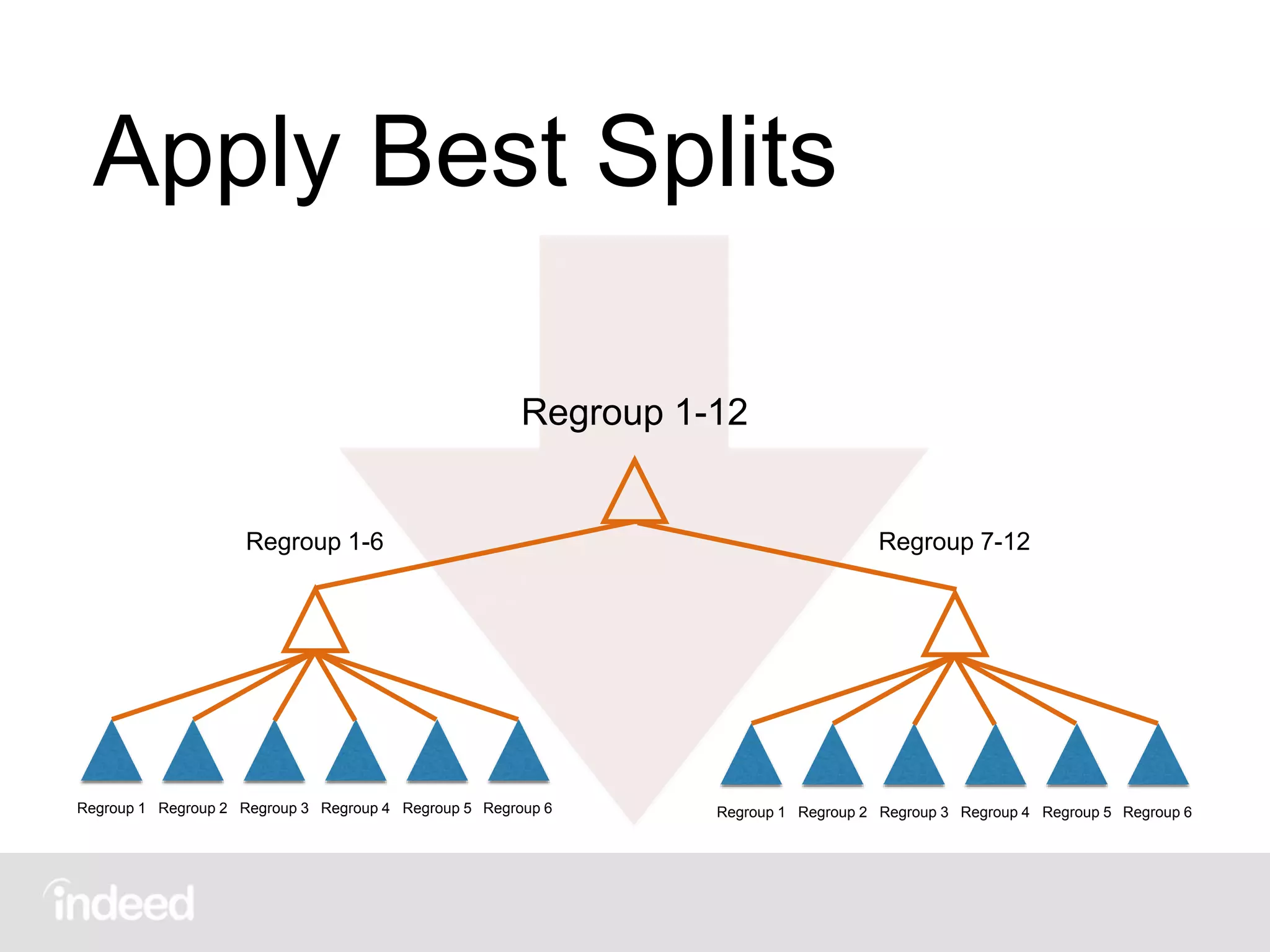
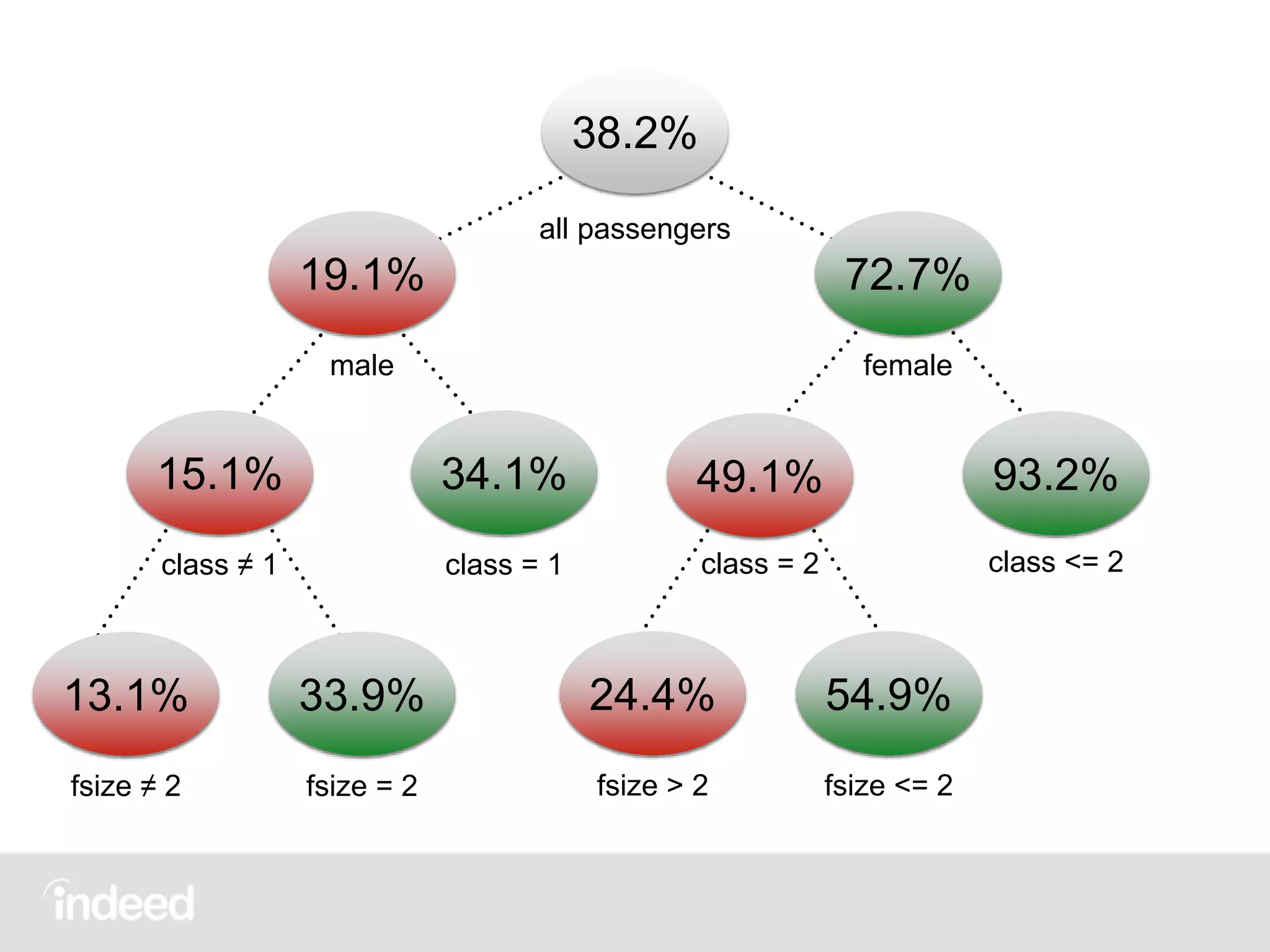
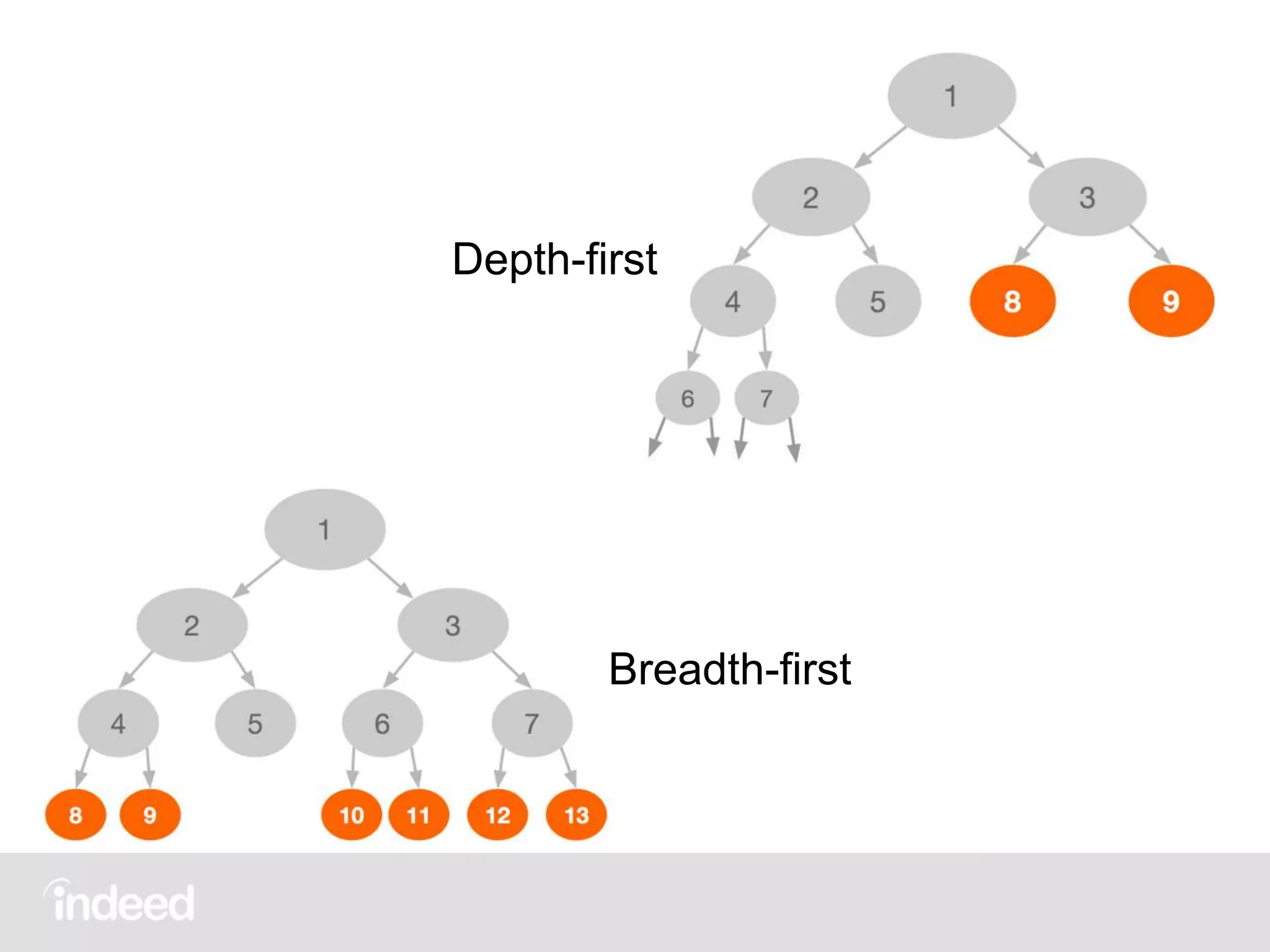
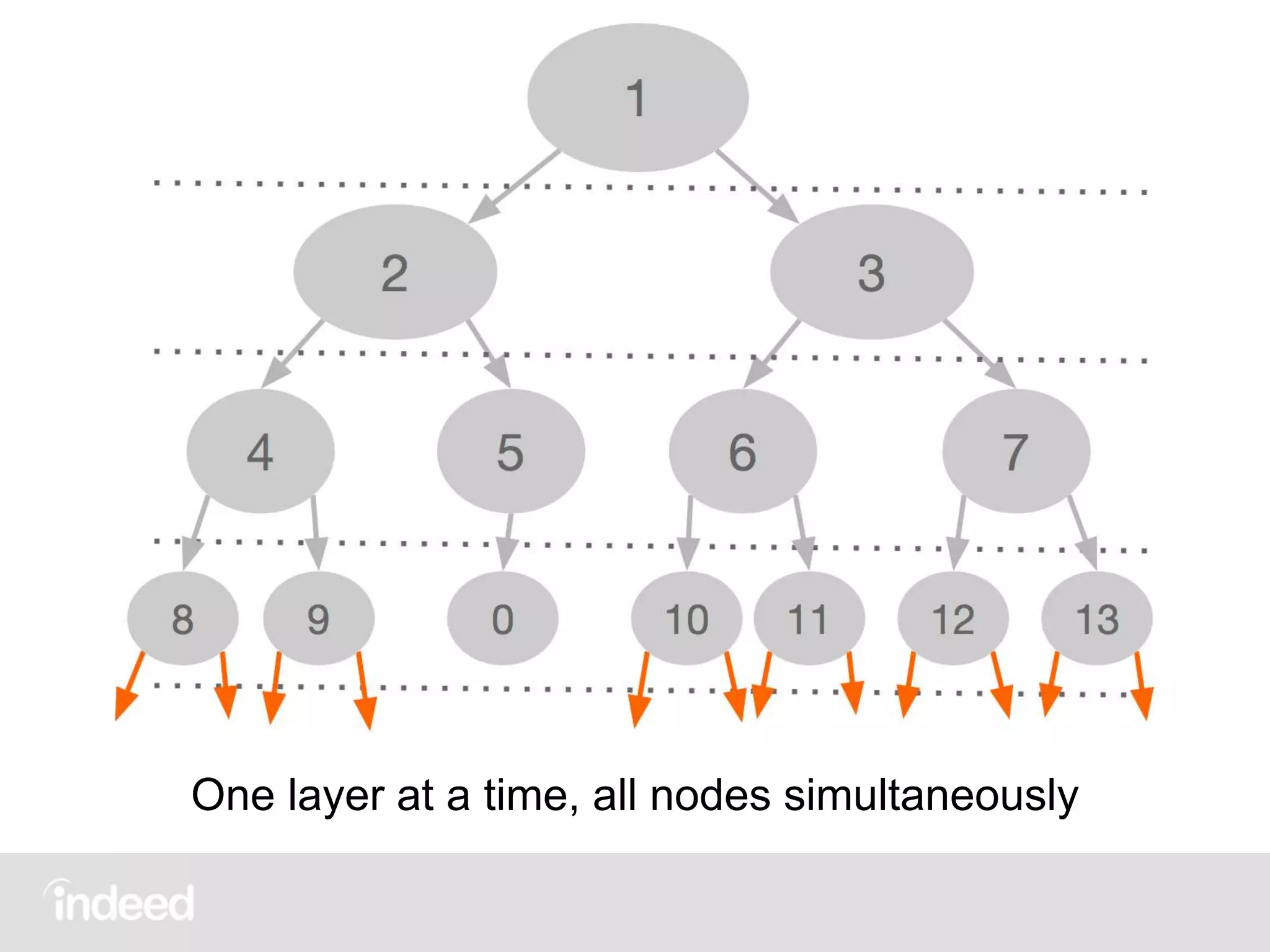
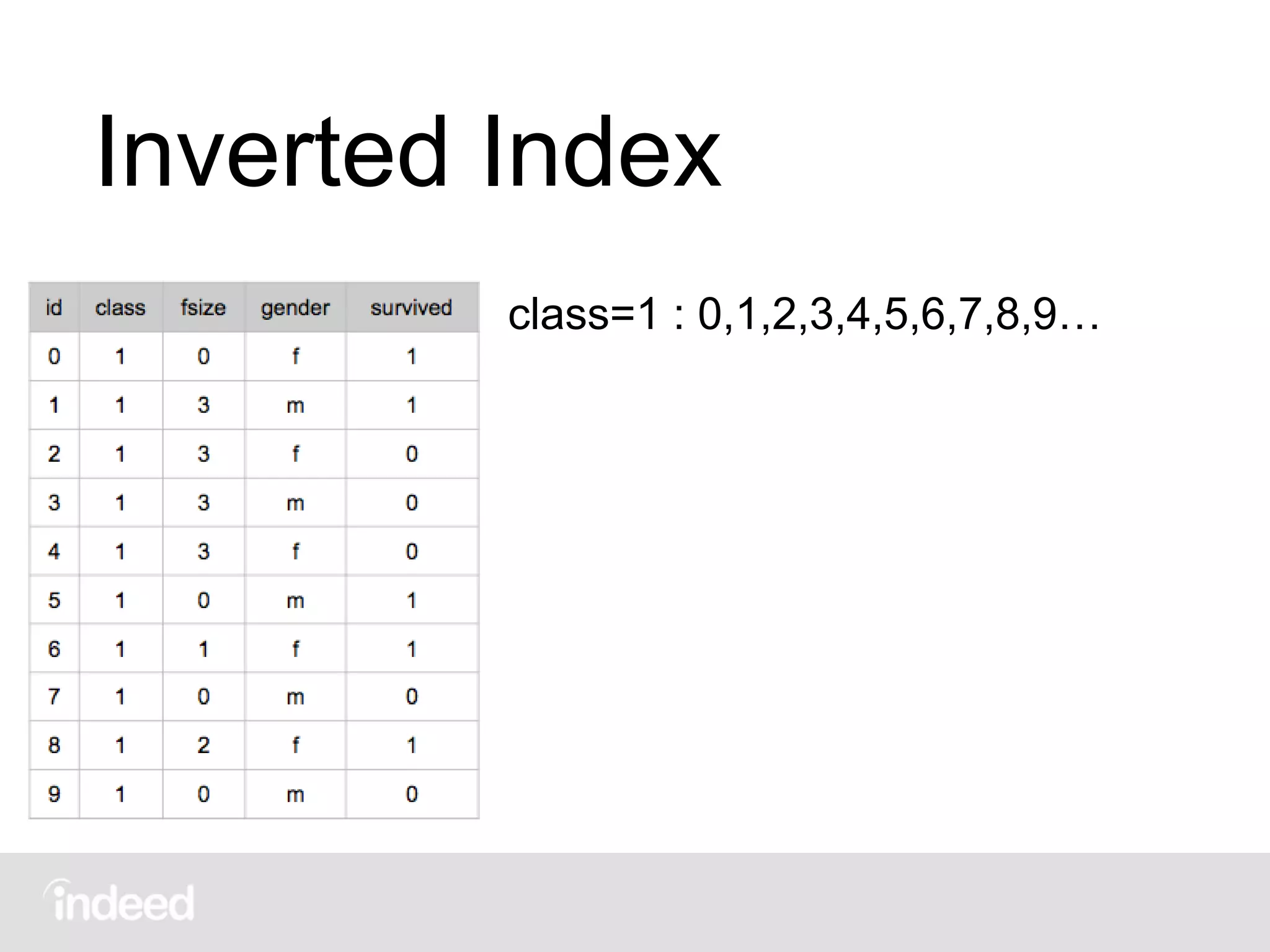
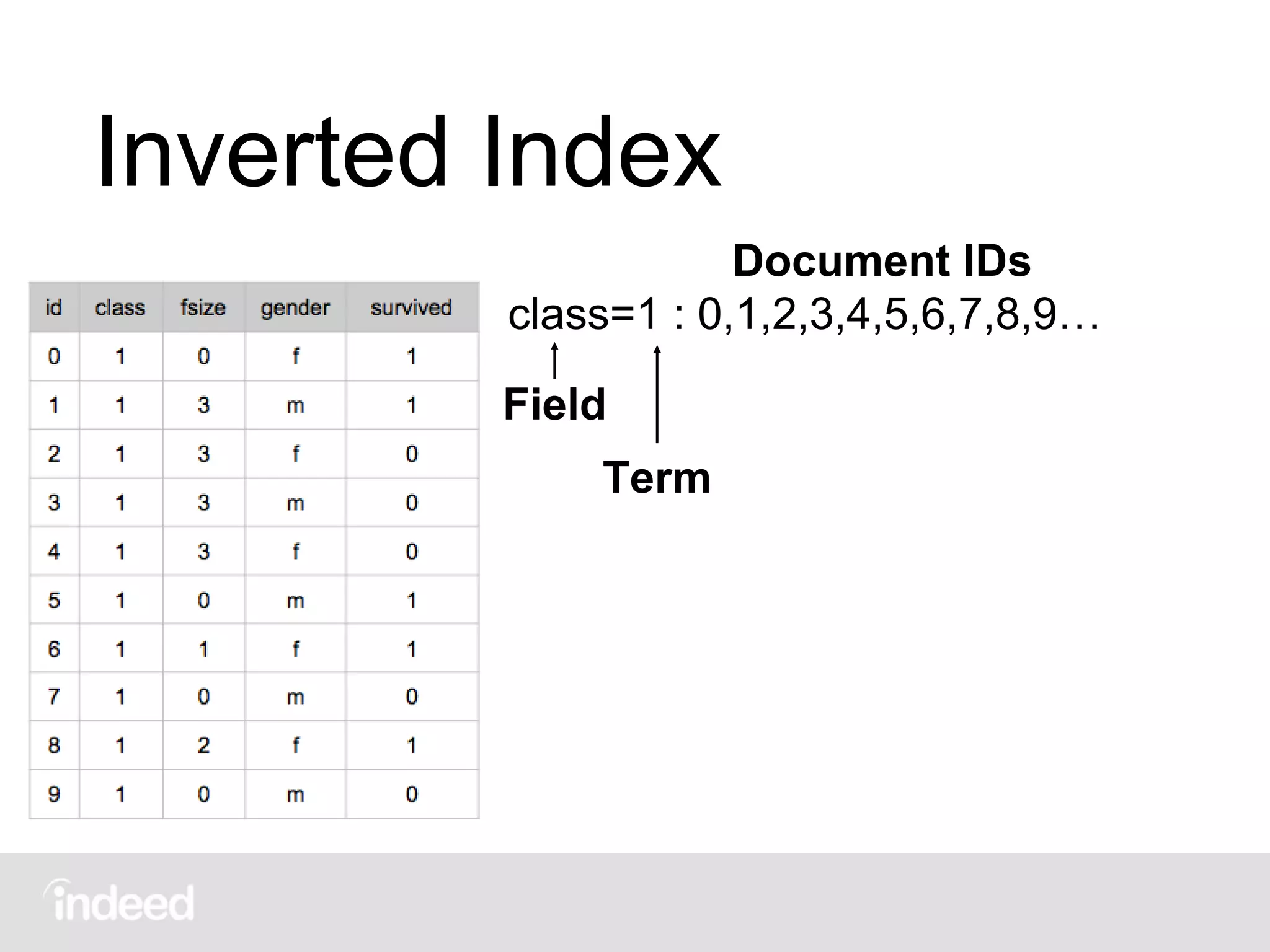
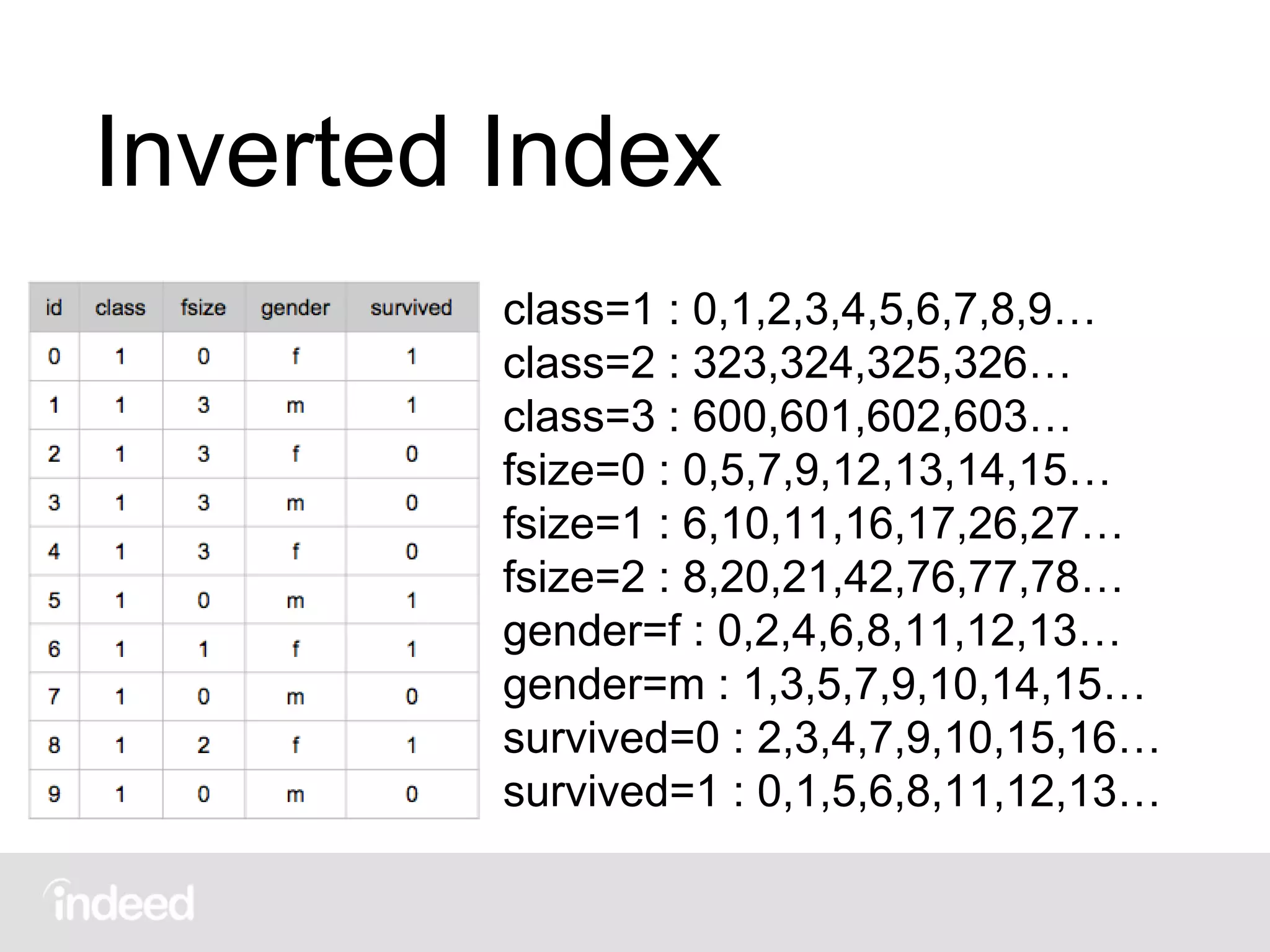
The document discusses machine learning techniques, specifically decision tree learning, used to classify documents based on various attributes like gender and class. It outlines processes such as evaluating splits for optimal criteria and maintaining statistical counts for groups of documents. Additionally, it covers the use of inverted indices and primary lookup tables essential for efficient data retrieval in search engines.







![50
0
80
9
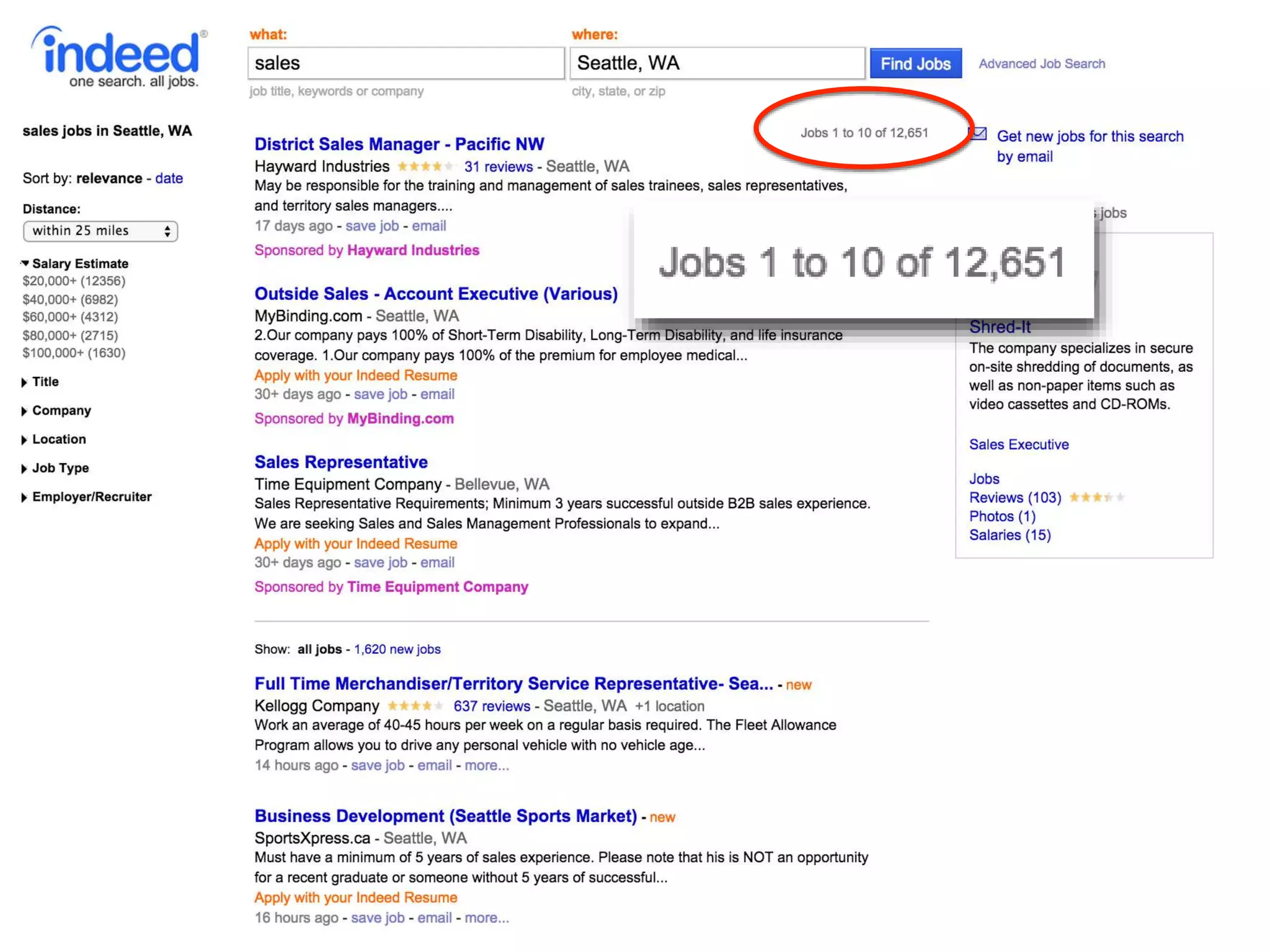
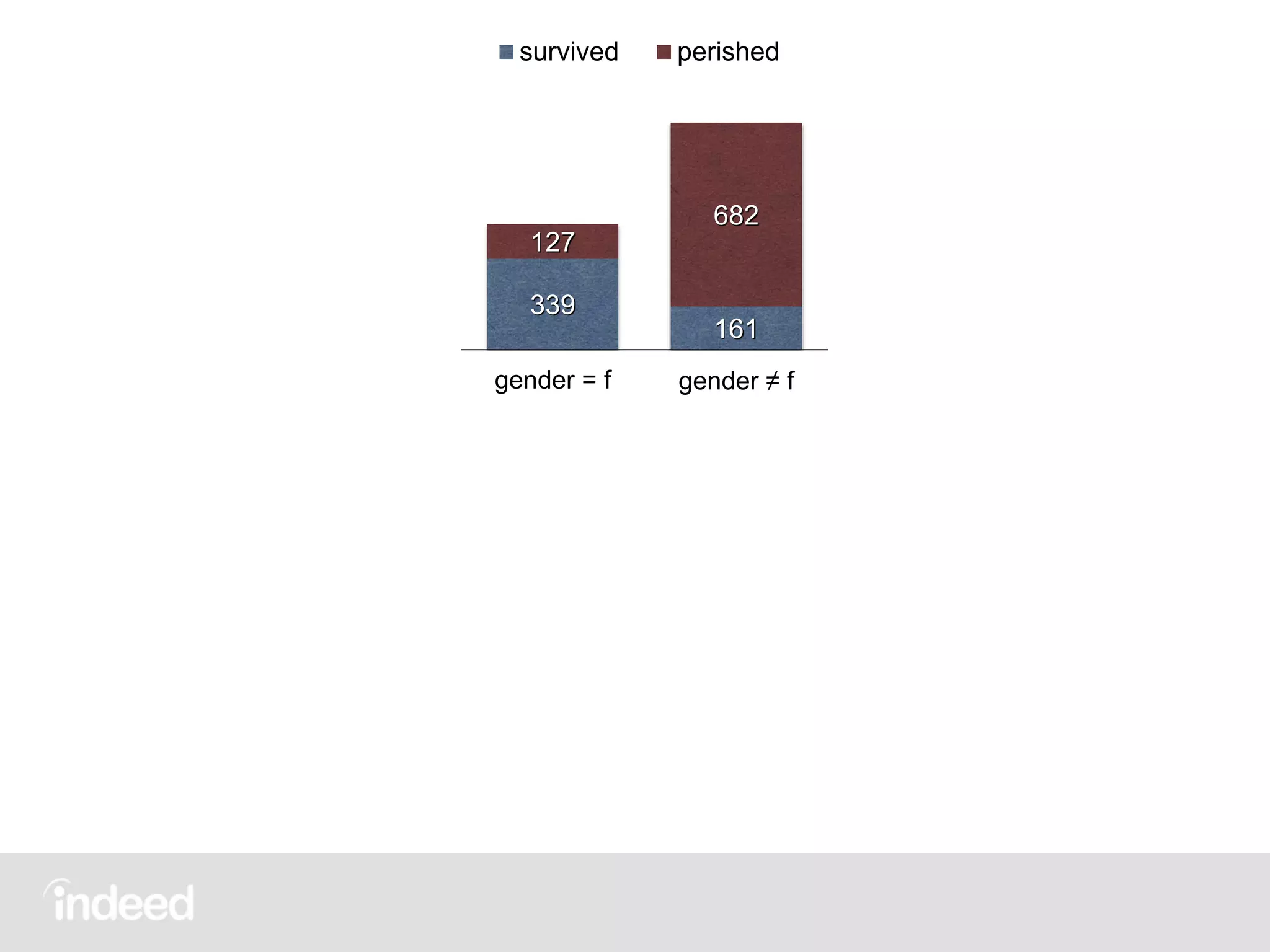
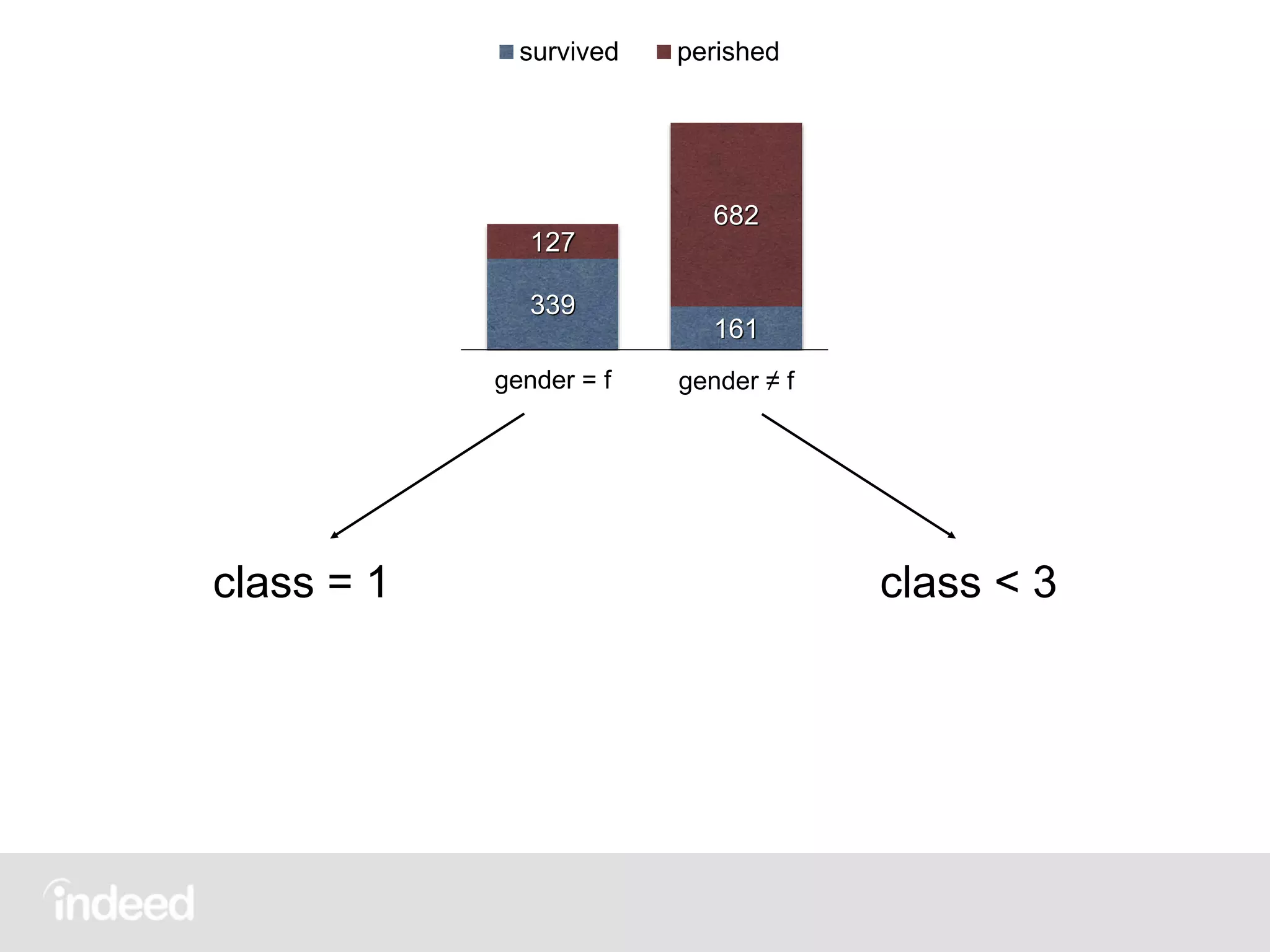
all passengers
survived perished
319
181
281 528
class ∈ [1, 2] class ∉ [1, 2]
339
161
127
682
gender = f gender ≠ f
200 300
123
686
class = 1 class ≠ 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-10-2048.jpg)
![H=0.6267
H=0.6244
H=0.5525
50
0
80
9
all passengers
survived perished
319
181
281 528
class ∈ [1, 2] class ∉ [1, 2]
339
161
127
682
gender = f gender ≠ f
200 300
123
686
class = 1 class ≠ 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-11-2048.jpg)
![H=0.6267
H=0.6244
H=0.5525
50
0
80
9
all passengers
survived perished
319
181
281 528
class ∈ [1, 2] class ∉ [1, 2]
339
161
127
682
gender = f gender ≠ f
200 300
123
686
class = 1 class ≠ 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-12-2048.jpg)
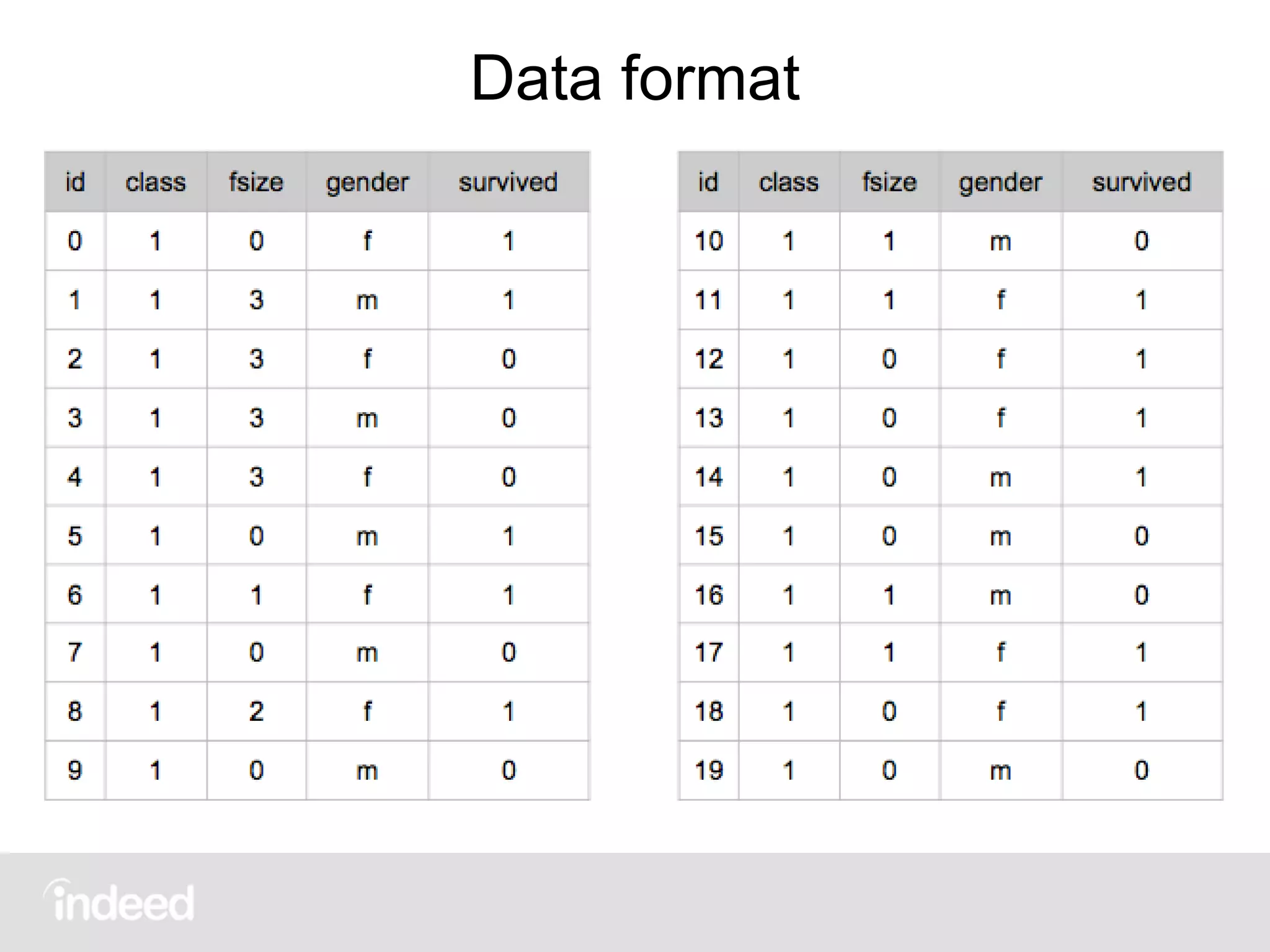

![Primary Lookup Tables
• groups[doc]: Where in the tree each doc is. All
docs start at root, so initially all 1s.
• values[doc]: Value to be classified for each doc.
For the titanic this is 1 if survived, 0 if not. In
general, invert the field of interest.](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-23-2048.jpg)




![Get Group Stats
• count[grp]: Count of how many documents in the
group contain the current term. All 0s initially.
• vsum[grp]: Summation of the value to be classified
from the documents within that group that contain
the current term. Also all 0s initially.](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-28-2048.jpg)
![Get Group Stats
// for current field+term
foreach doc
grp = grps[doc]
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-29-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc
grp = grps[doc]
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-30-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc]
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-31-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-32-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-33-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc]](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-34-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-35-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 0, vsum[1] = 0](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-36-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 1, vsum[1] = 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-37-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 2, vsum[1] = 2](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-38-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 3, vsum[1] = 2](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-39-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 4, vsum[1] = 2](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-40-2048.jpg)
![Get Group Stats
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 323, vsum[1] = 200](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-41-2048.jpg)
![50
0
80
9
all passengers
survived perished
319
181
281 528
class ∈ [1, 2] class ∉ [1, 2]
339
161
127
682
gender = f gender ≠ f
200 300
123
686
class = 1 class ≠ 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-42-2048.jpg)
![Get Group Stats
// for current field+term (gender=m)
foreach doc (1,3,5,7,…)
grp = grps[doc] (1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[1] = 1, vsum[1] = 1](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-43-2048.jpg)



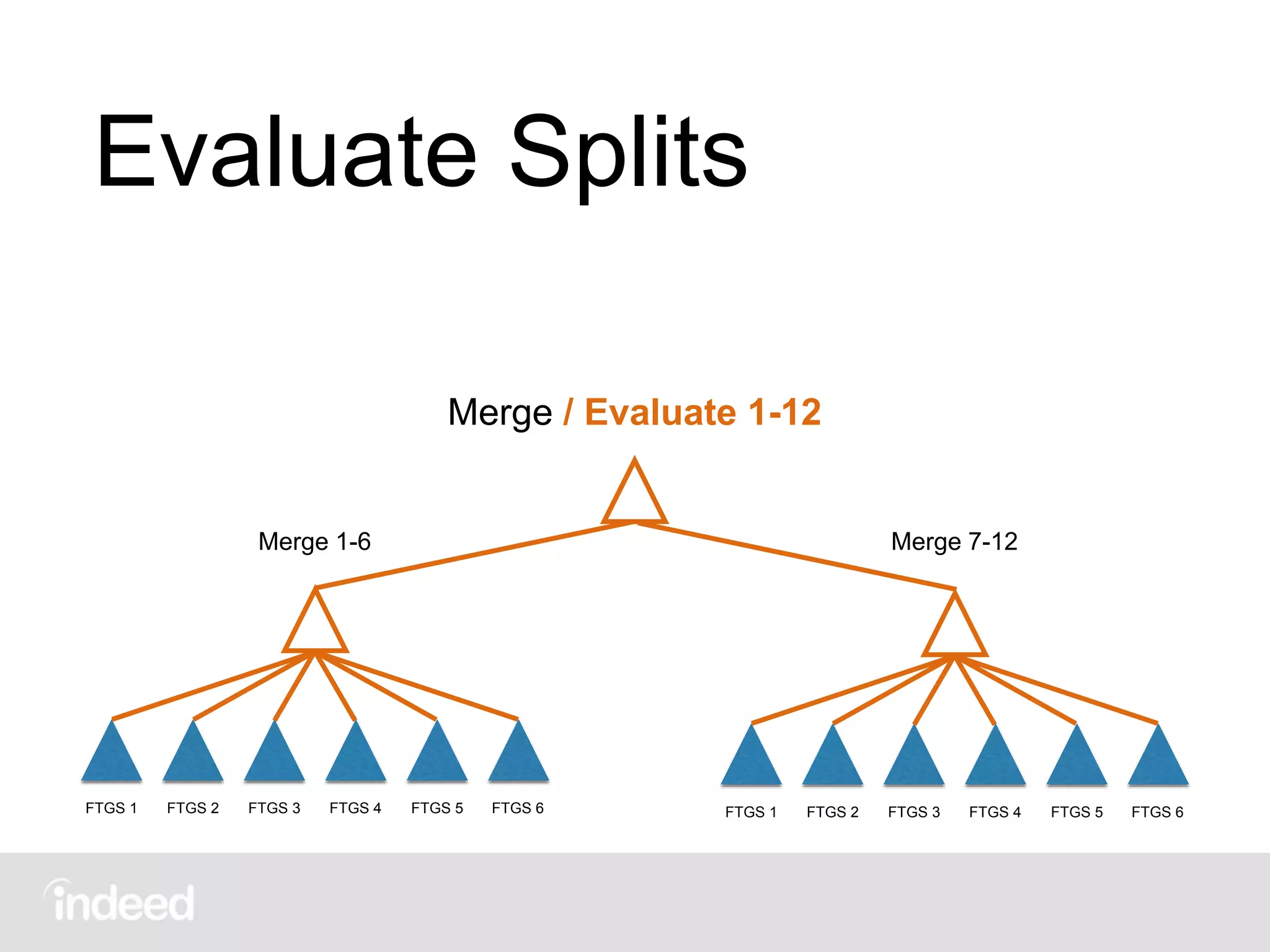
![Evaluate Splits
More tables:
• totalcount[group], totalvalue[group]: Total
number of documents and total values for each
group — in this example, number of passengers and
survivors respectively
• bestsplit[group], bestscore[group]: Current best
split and score for each group, initially nulls](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-47-2048.jpg)
![Evaluate Splits
foreach group
if not admissible (…) skip
score = calcscore(cnt[grp], vsum[grp],
totcnt[grp], totval[grp])
if score < bestscore[grp]
bestscore[grp] = score
bestsplit[grp] = (field,term)](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-48-2048.jpg)

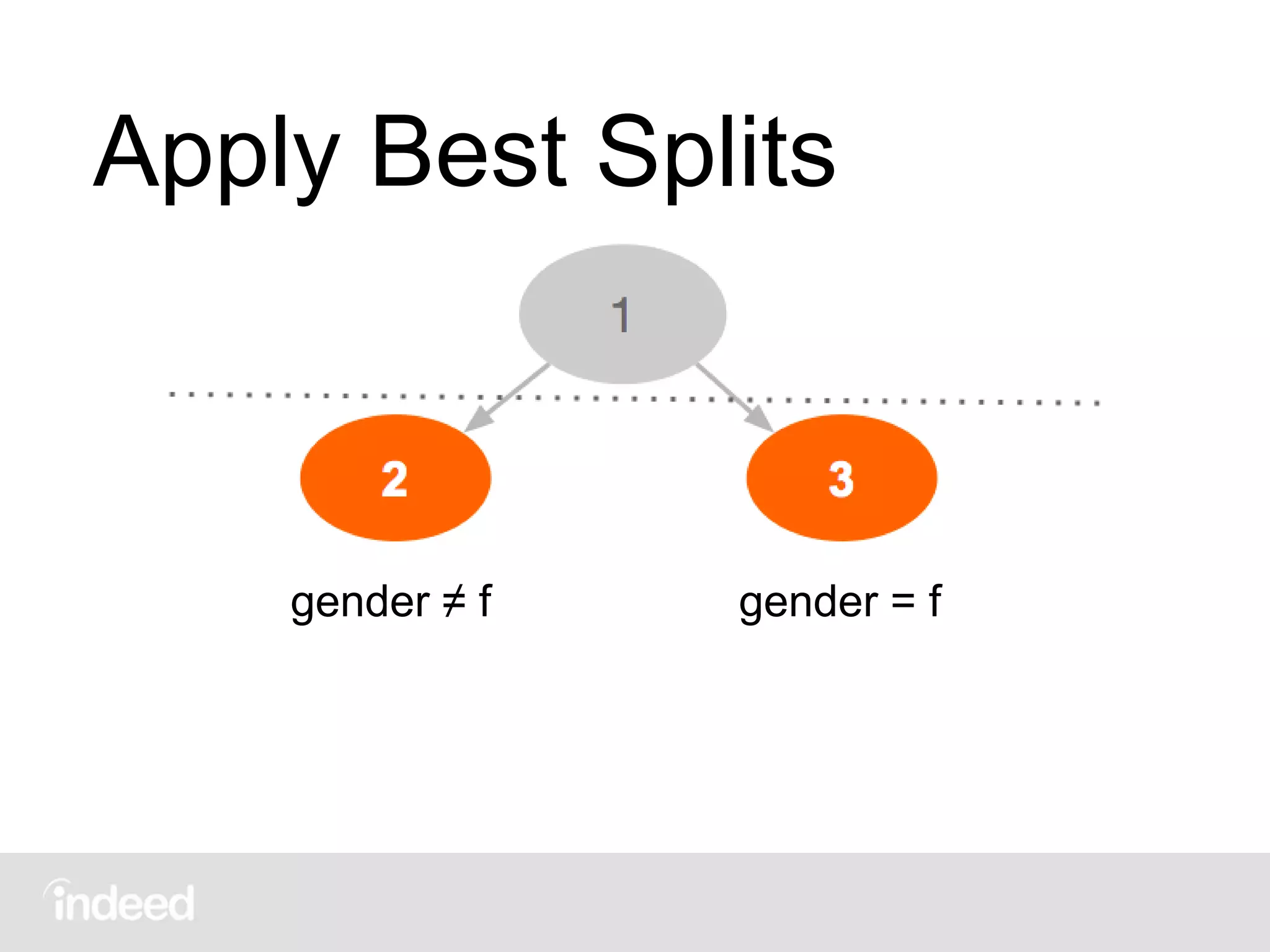
![Main Loop
foreach field (class,fsize,gender,…)
foreach term (class=1,class=2,…)
get group stats
evaluate splits
apply best splits (bestsplit[1]=(gender,f))
repeat n times or until no more splits found](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-50-2048.jpg)

![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 1 7 1 14 1
1 1 8 1 15 1
2 1 9 1 16 1
3 1 10 1 17 1
4 1 11 1 18 1
5 1 12 1 19 1
6 1 13 1 20 1
gender=f : 0,2,4,6,8,11,12,13,17,18,21,23,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-53-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 1 14 1
1 1 8 1 15 1
2 1 9 1 16 1
3 1 10 1 17 1
4 1 11 1 18 1
5 1 12 1 19 1
6 1 13 1 20 1
gender=f : 0,2,4,6,8,11,12,13,17,18,21,23,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-54-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 1 14 1
1 1 8 1 15 1
2 3 9 1 16 1
3 1 10 1 17 1
4 1 11 1 18 1
5 1 12 1 19 1
6 1 13 1 20 1
gender=f : 0,2,4,6,8,11,12,13,17,18,21,23,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-55-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 1 14 1
1 1 8 1 15 1
2 3 9 1 16 1
3 1 10 1 17 1
4 3 11 1 18 1
5 1 12 1 19 1
6 1 13 1 20 1
gender=f : 0,2,4,6,8,11,12,13,17,18,21,23,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-56-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 1 14 1
1 1 8 3 15 1
2 3 9 1 16 1
3 1 10 1 17 3
4 3 11 3 18 3
5 1 12 3 19 1
6 3 13 3 20 1
gender=f : 0,2,4,6,8,11,12,13,17,18,21,23,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-57-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 1 14 1
1 1 8 3 15 1
2 3 9 1 16 1
3 1 10 1 17 3
4 3 11 3 18 3
5 1 12 3 19 1
6 3 13 3 20 1
gender≠f : 1,3,5,7,9,10,14,15,16,19,20,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-58-2048.jpg)
![Apply Best Splits
DocID group[ID] DocID group[ID] DocID group[ID]
0 3 7 2 14 2
1 2 8 3 15 2
2 3 9 2 16 2
3 2 10 2 17 3
4 3 11 3 18 3
5 2 12 3 19 2
6 3 13 3 20 2
gender≠f : 1,3,5,7,9,10,14,15,16,19,20,…](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-59-2048.jpg)
![Main Loop
foreach field (class,fsize,gender,…)
foreach term (class=1,class=2,…)
get group stats
evaluate splits
apply best splits (bestsplit[1]=(gender,f))
repeat n times or until no more splits found](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-60-2048.jpg)
![Main Loop
foreach field (class,fsize,gender,…)
foreach term (class=1,class=2,…)
get group stats
evaluate splits
apply best splits (bestsplit[1]=(gender,f))
repeat n times or until no more splits
found](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-61-2048.jpg)



![Get Group Stats (1st loop)
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (1,1,1,1,1,1,1,1,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-65-2048.jpg)
![Get Group Stats (Now)
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (3,2,3,2,3,2,3,2,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-66-2048.jpg)
![Get Group Stats (Now)
// for current field+term (class=1)
foreach doc (0,1,2,3,4,5,6,7,8,…)
grp = grps[doc] (3,2,3,2,3,2,3,2,…)
if grp == 0 skip
count[grp]++
vsum[grp] += vals[doc] (1,1,0,0,0,1,1,0,…)
count[2] = 179, vsum[2] = 61
count[3] = 144, vsum[3] = 139](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-67-2048.jpg)
![Evaluate Splits
foreach group
if not admissible (…) skip
score = calcscore(cnt[grp], vsum[grp],
totcnt[grp], totval[grp])
if score < bestscore[grp]
bestscore[grp] = score
bestsplit[grp] = (field,term)](https://image.slidesharecdn.com/scalingdecisiontrees-150908203254-lva1-app6892/75/Scaling-decision-trees-George-Murray-July-2015-68-2048.jpg)