






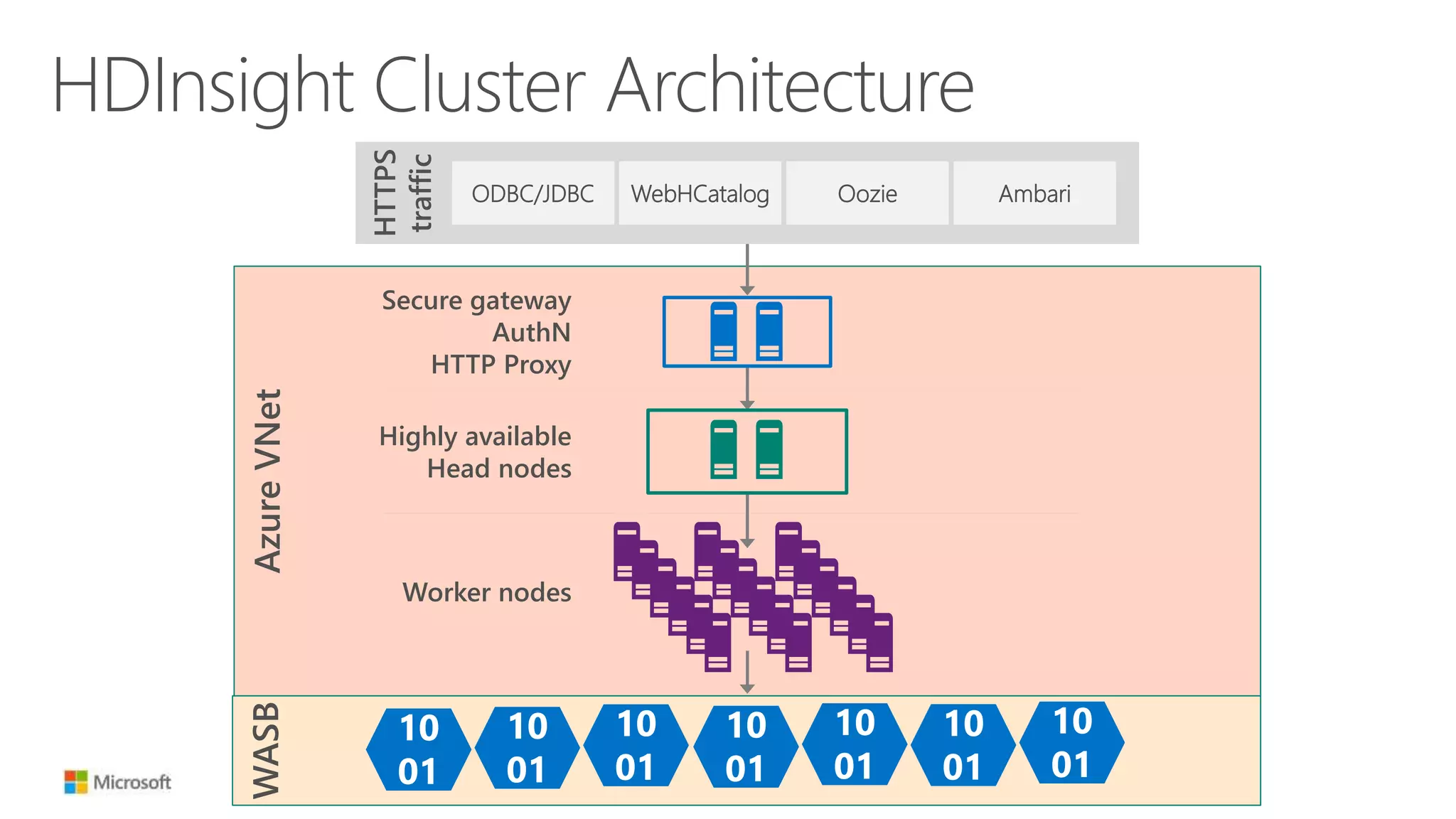
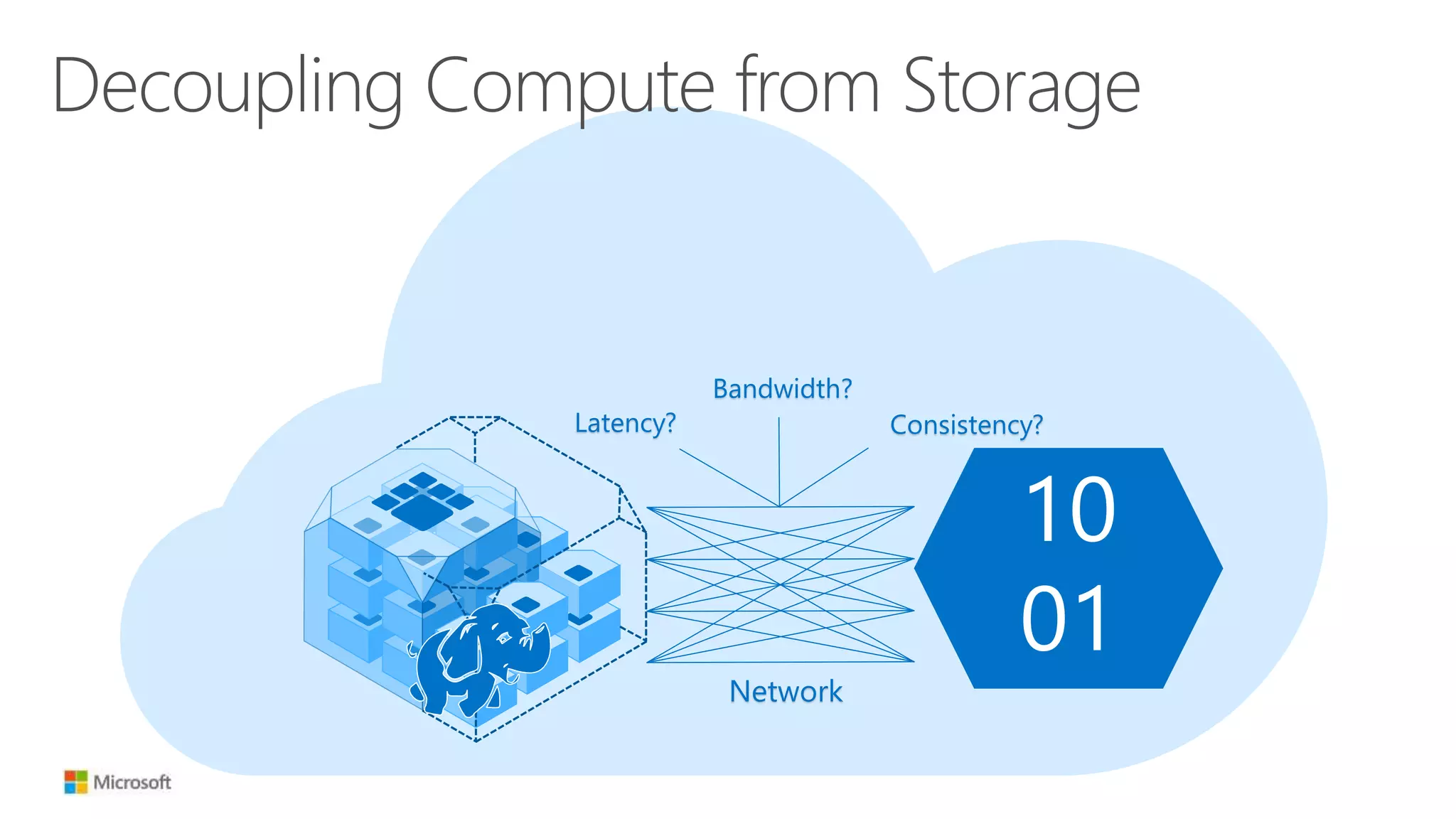
![Decoupling Compute from Storage
10
01
Network
HDD-like latency
50 Tb+ aggregate
bandwidth[1]
Strong consistency
[1] Azure Flat Network Architecture](https://image.slidesharecdn.com/june10525pmmicrosoftthacker-150618233626-lva1-app6891/75/Hadoop-in-the-cloud-The-what-why-and-how-from-the-experts-18-2048.jpg)
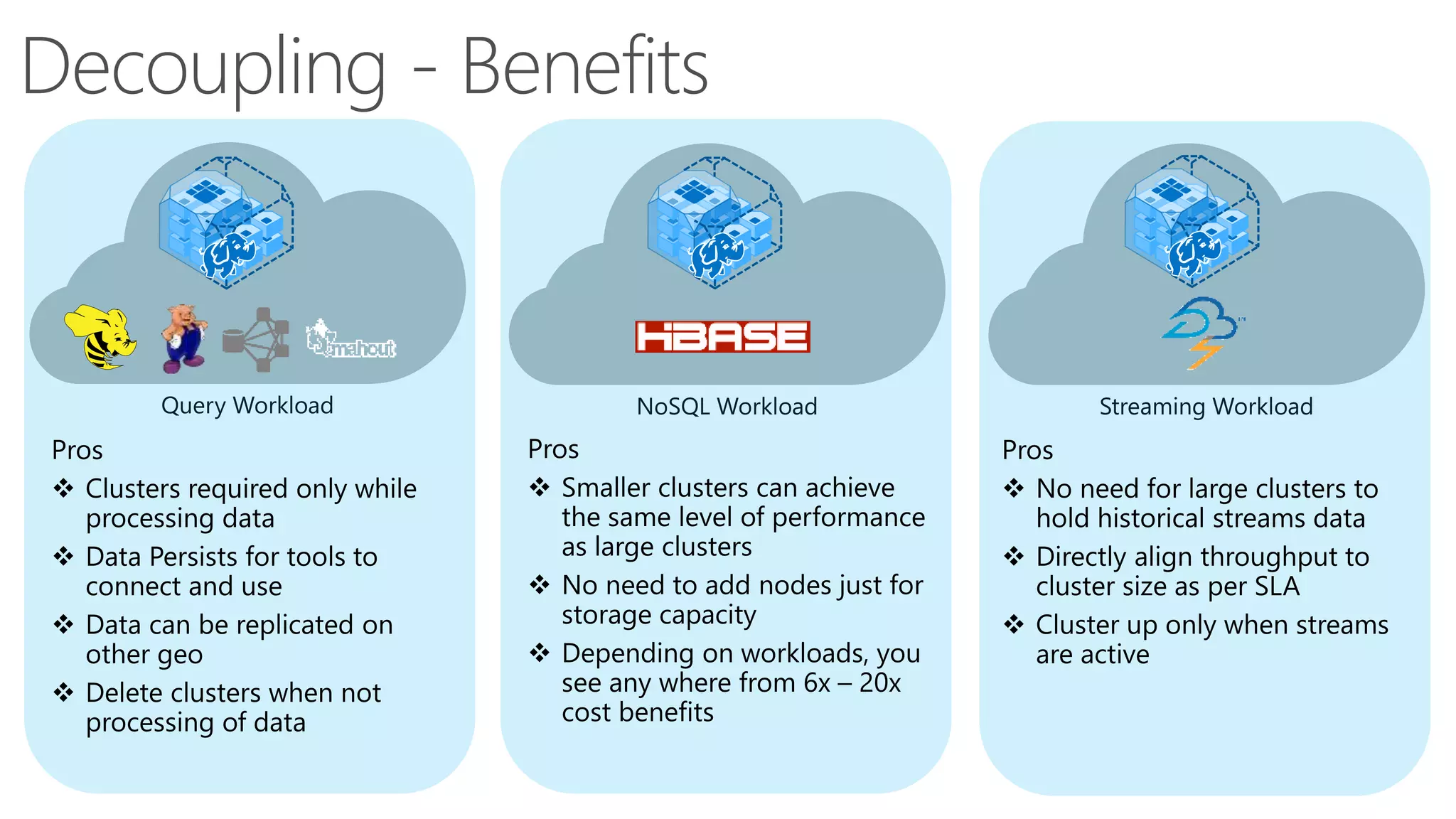
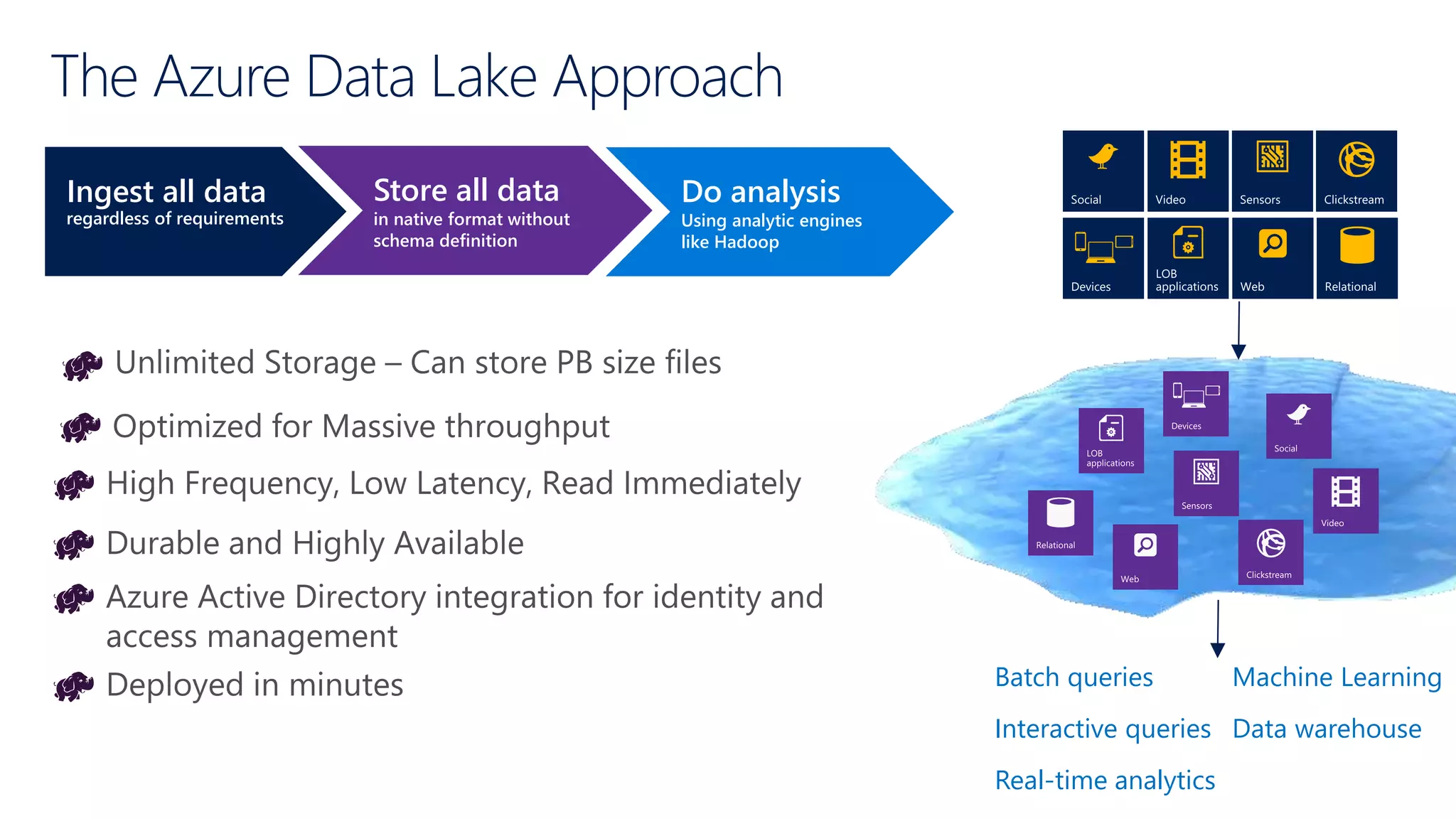
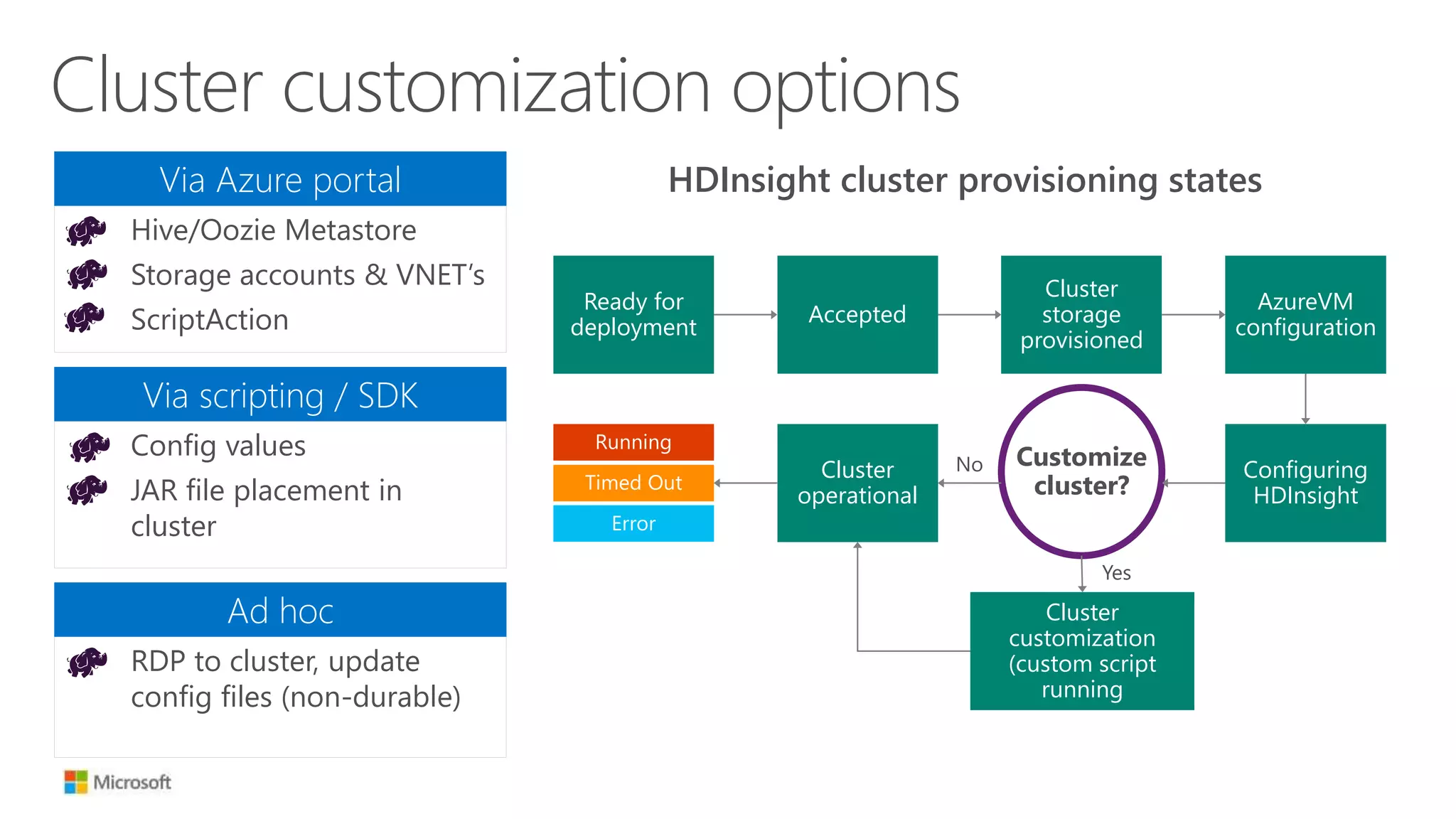


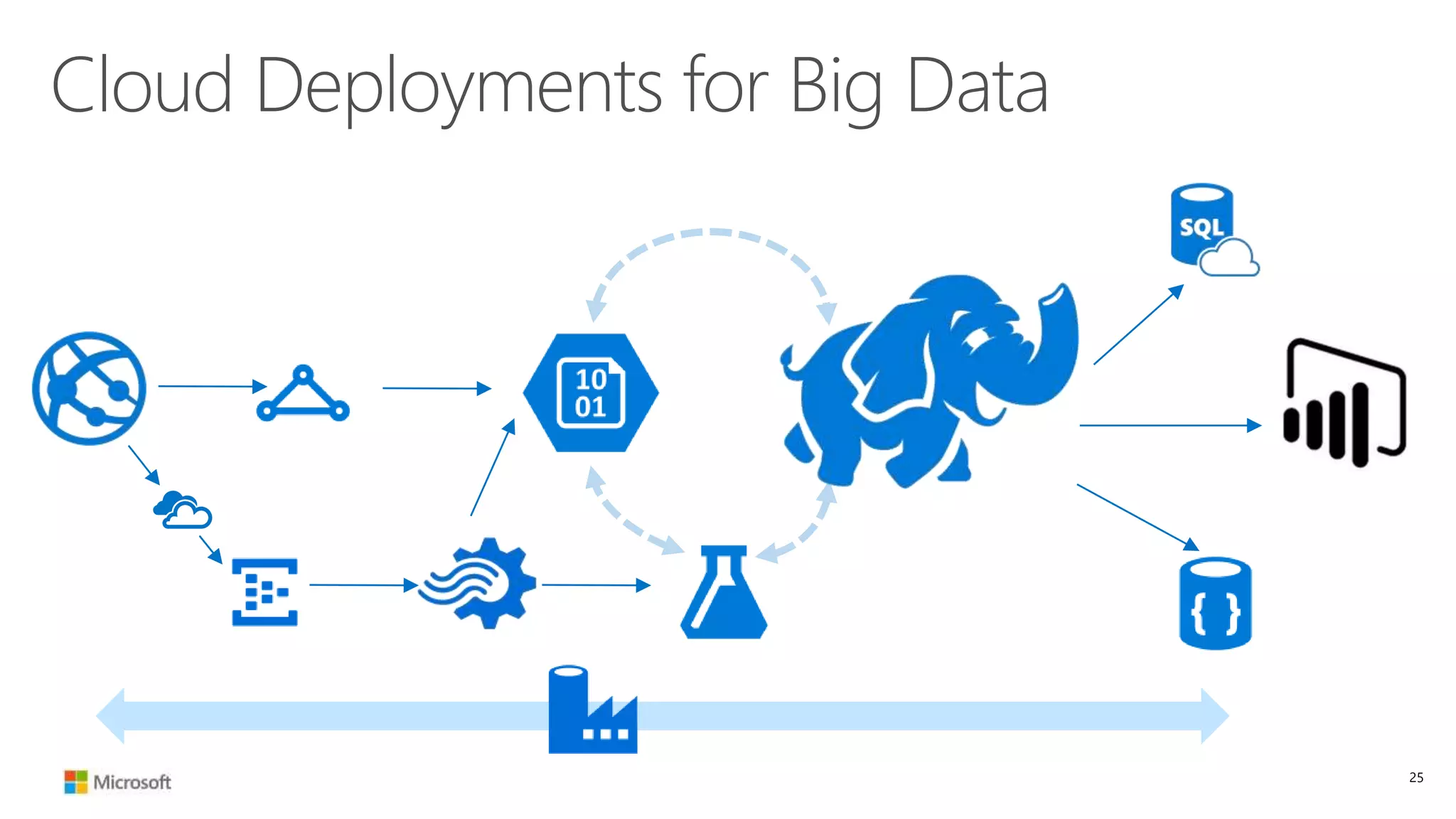
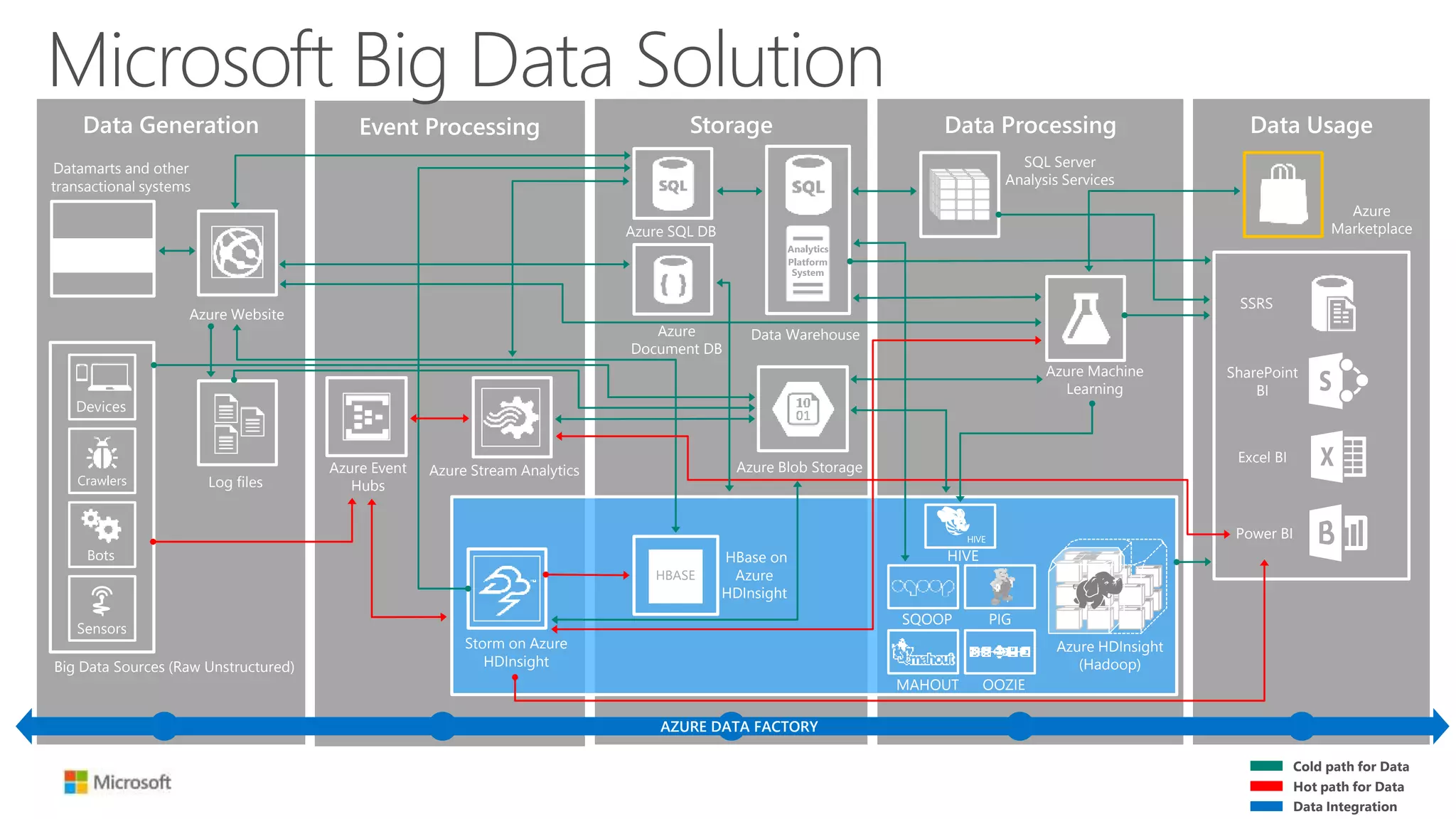



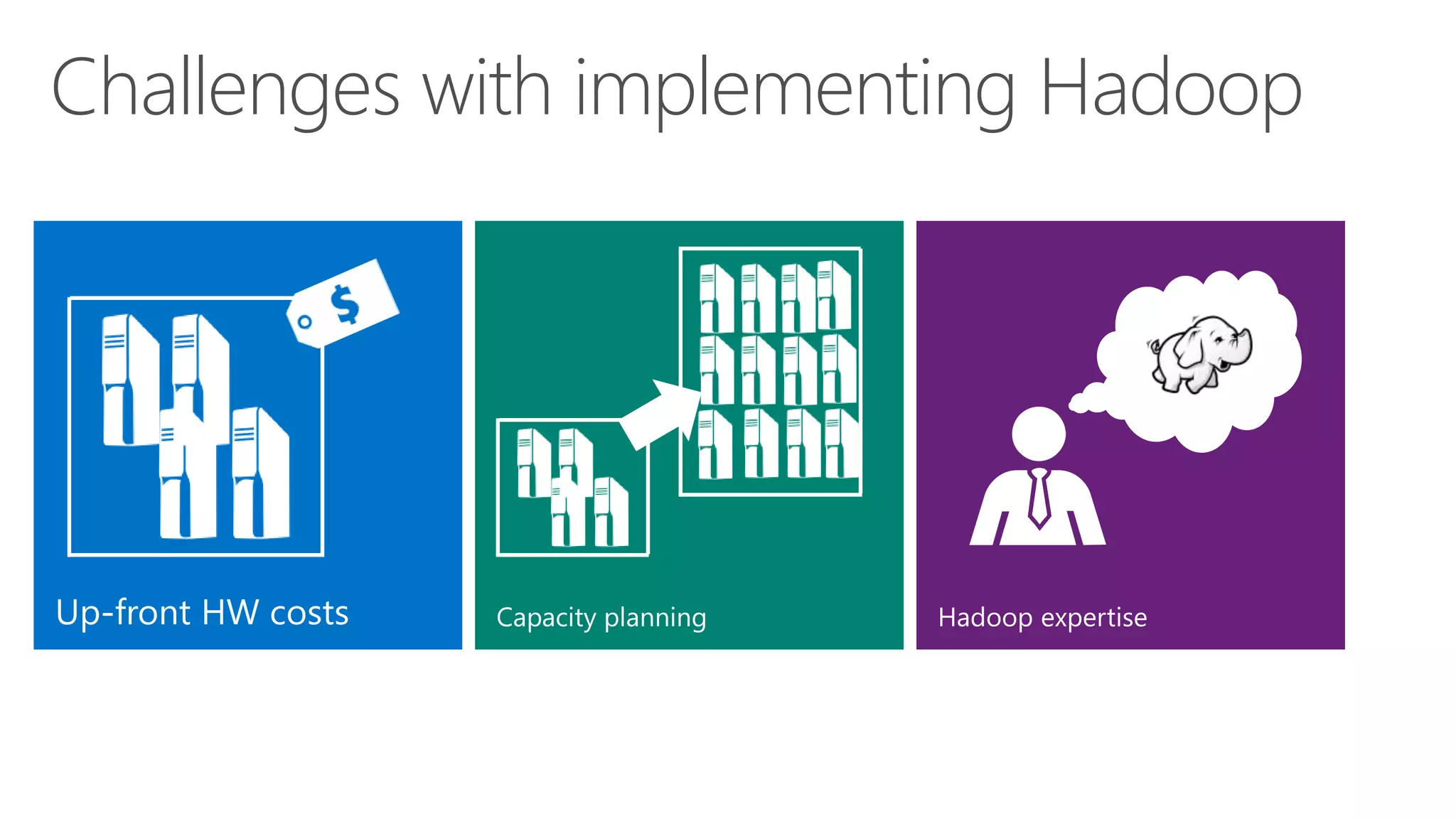
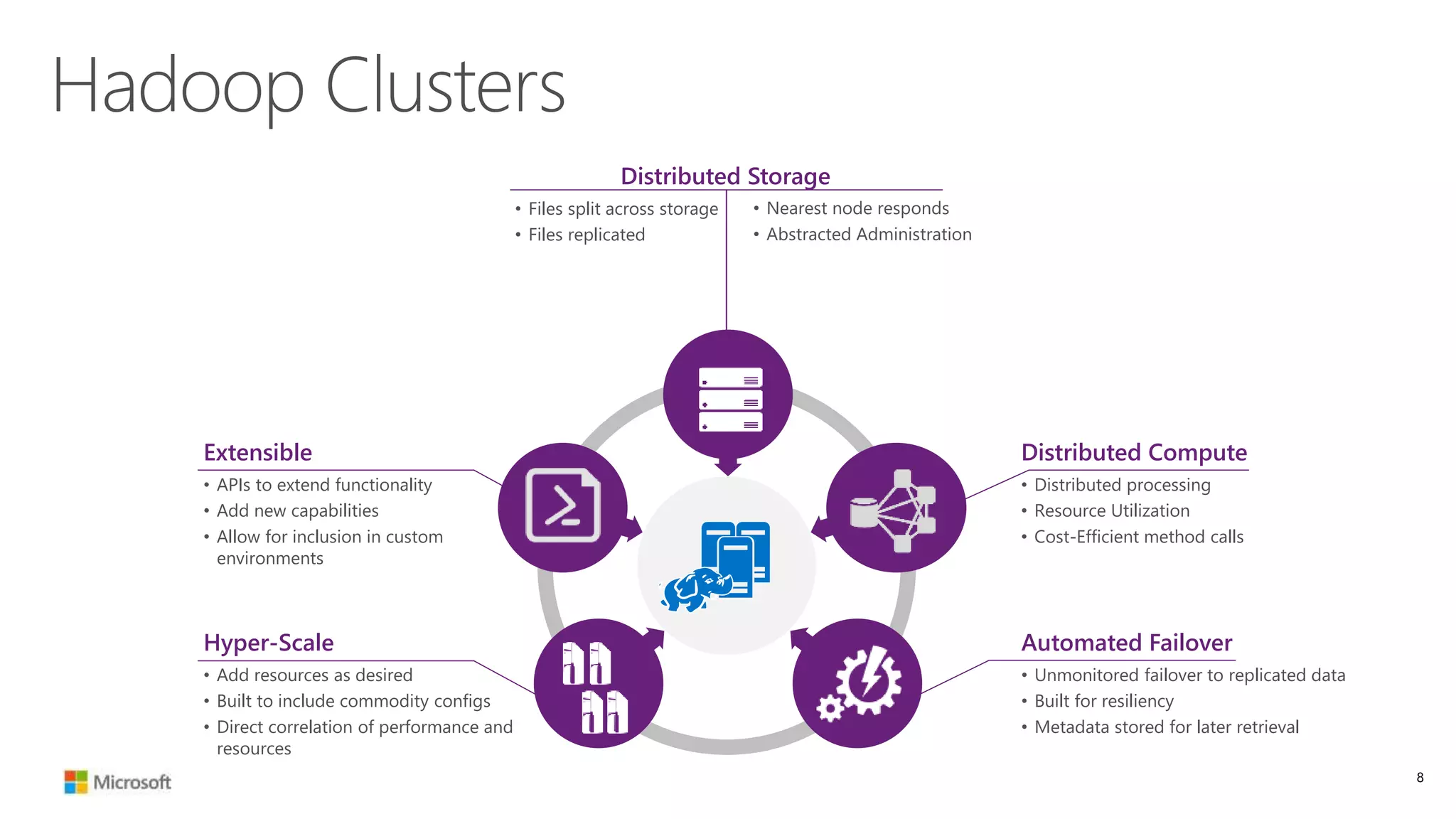
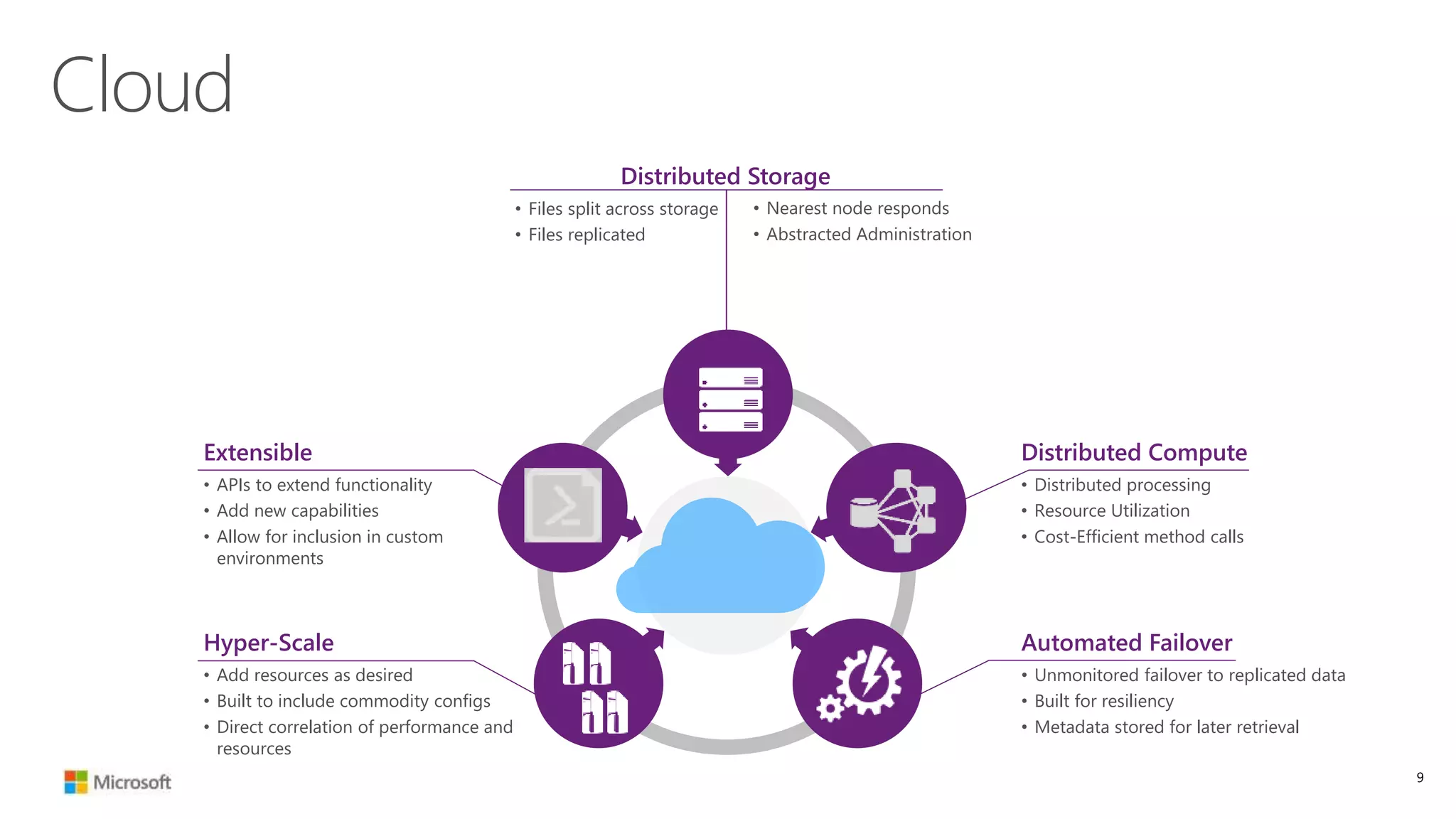
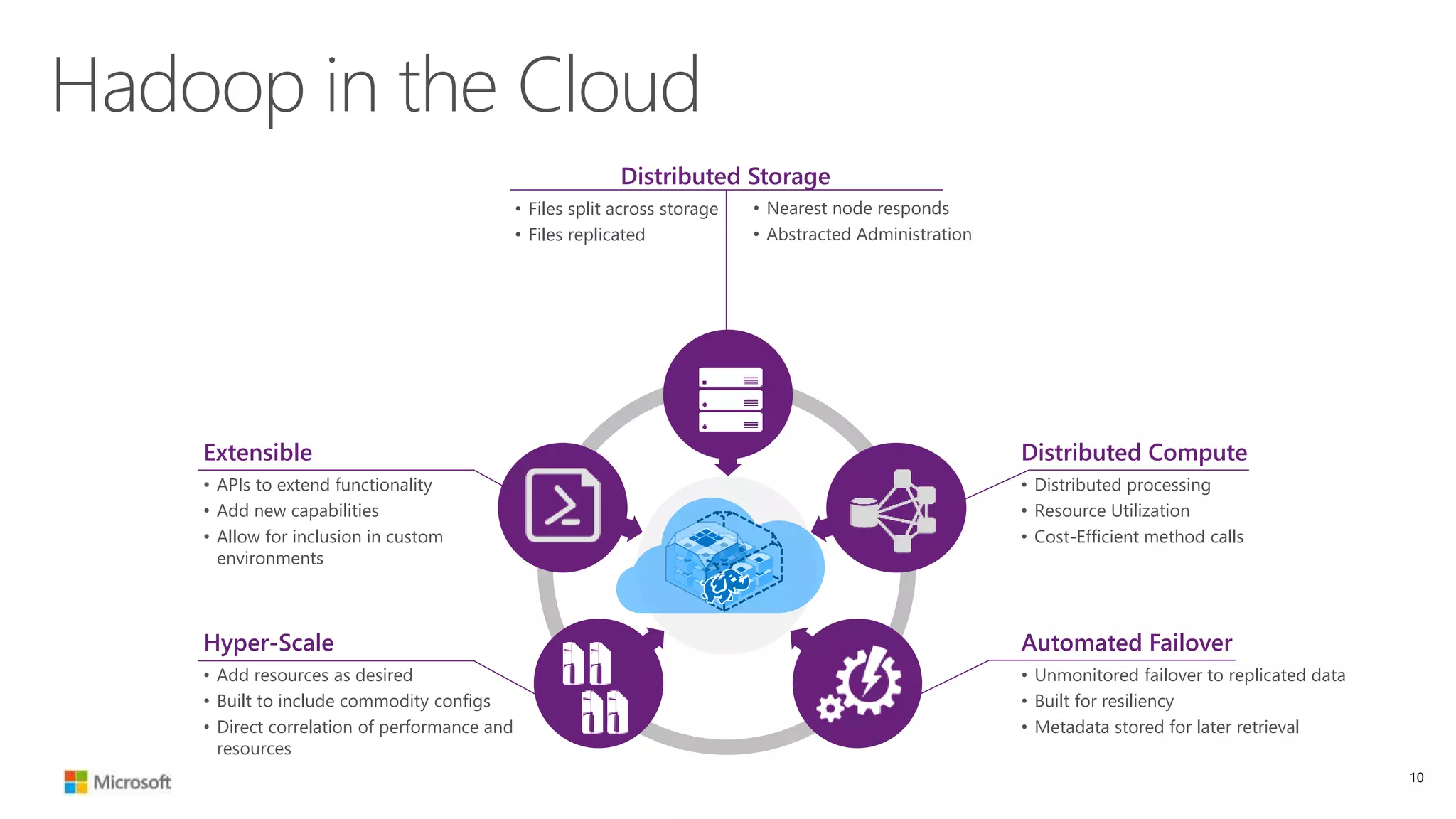
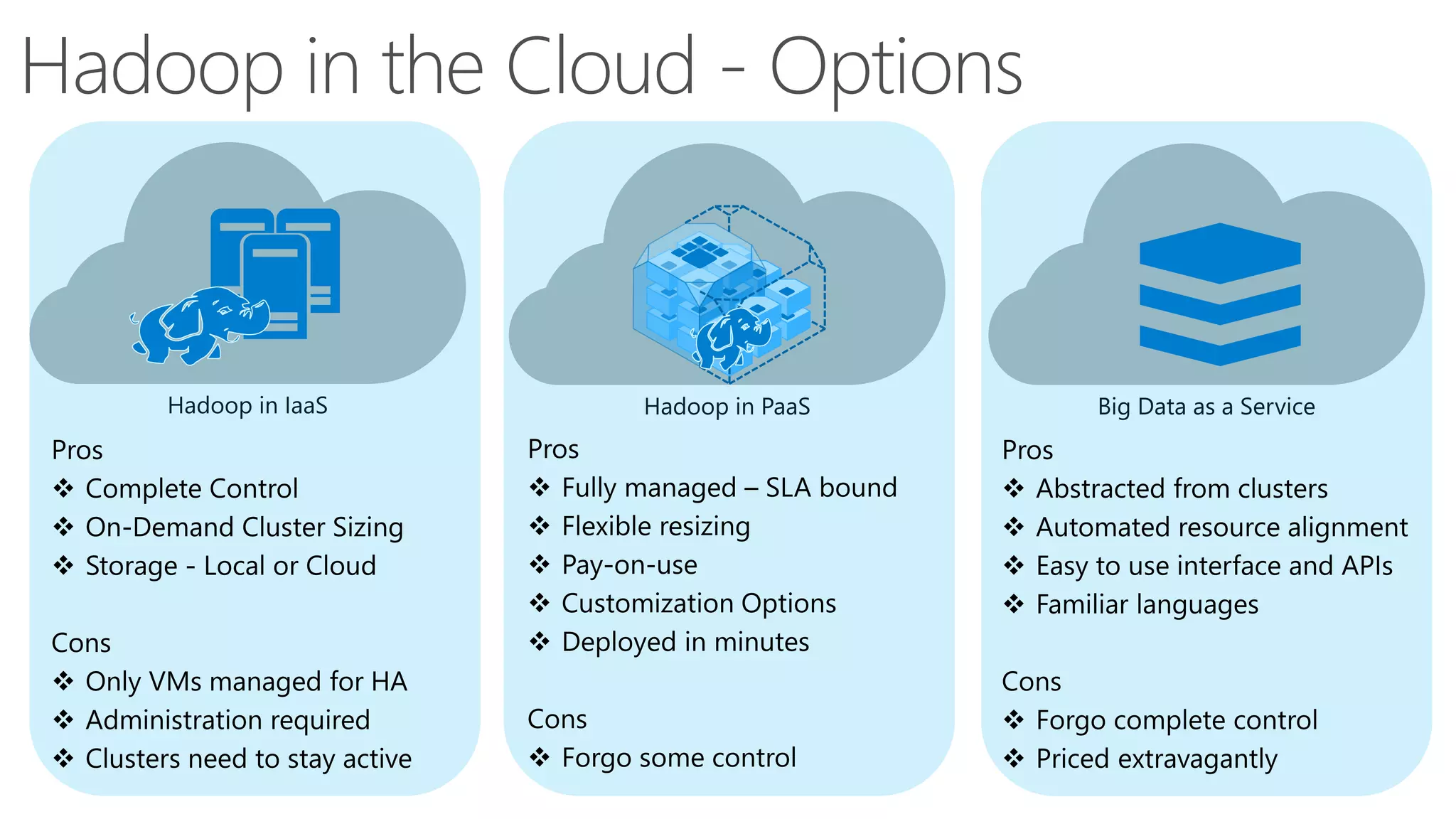
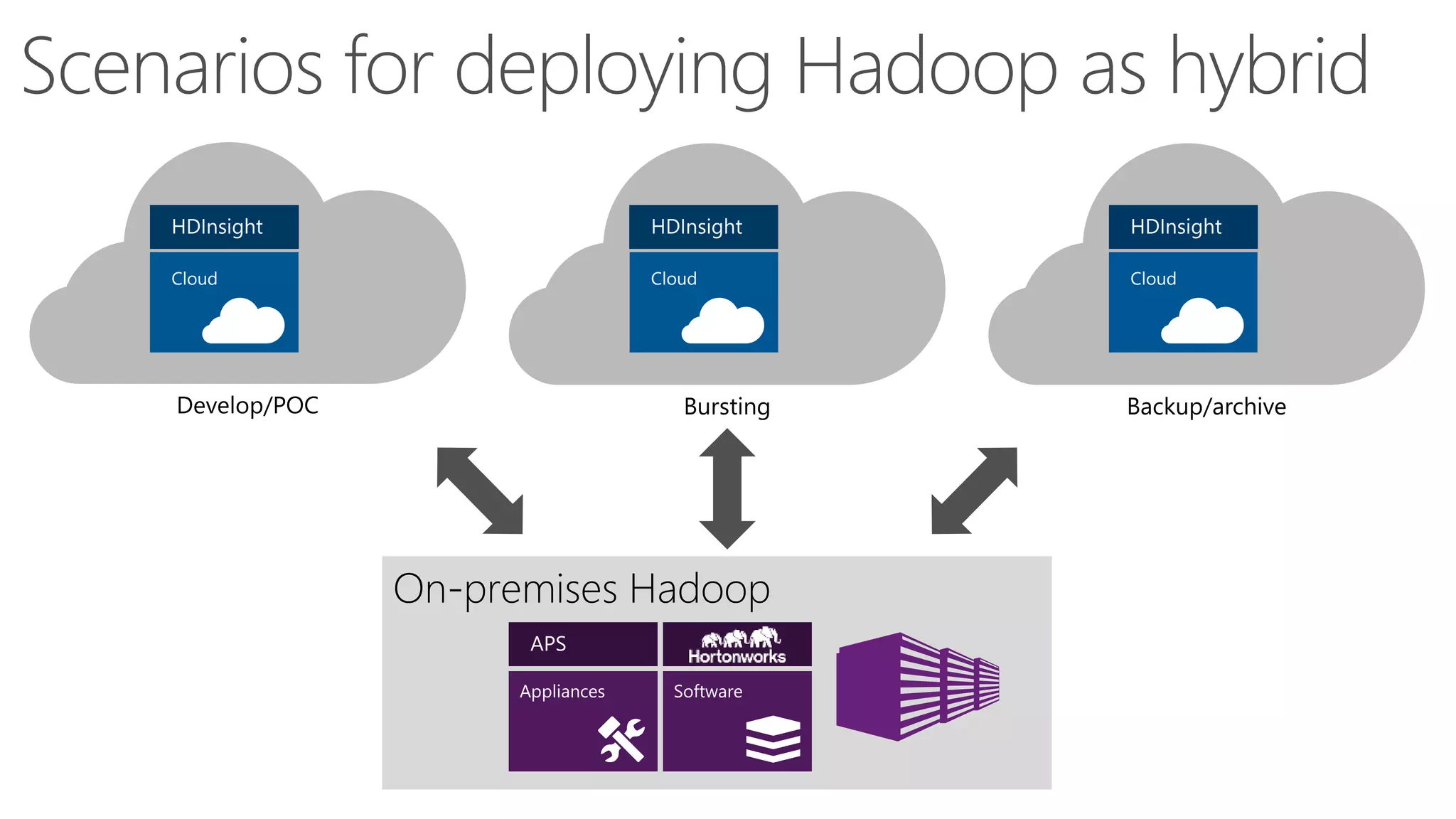
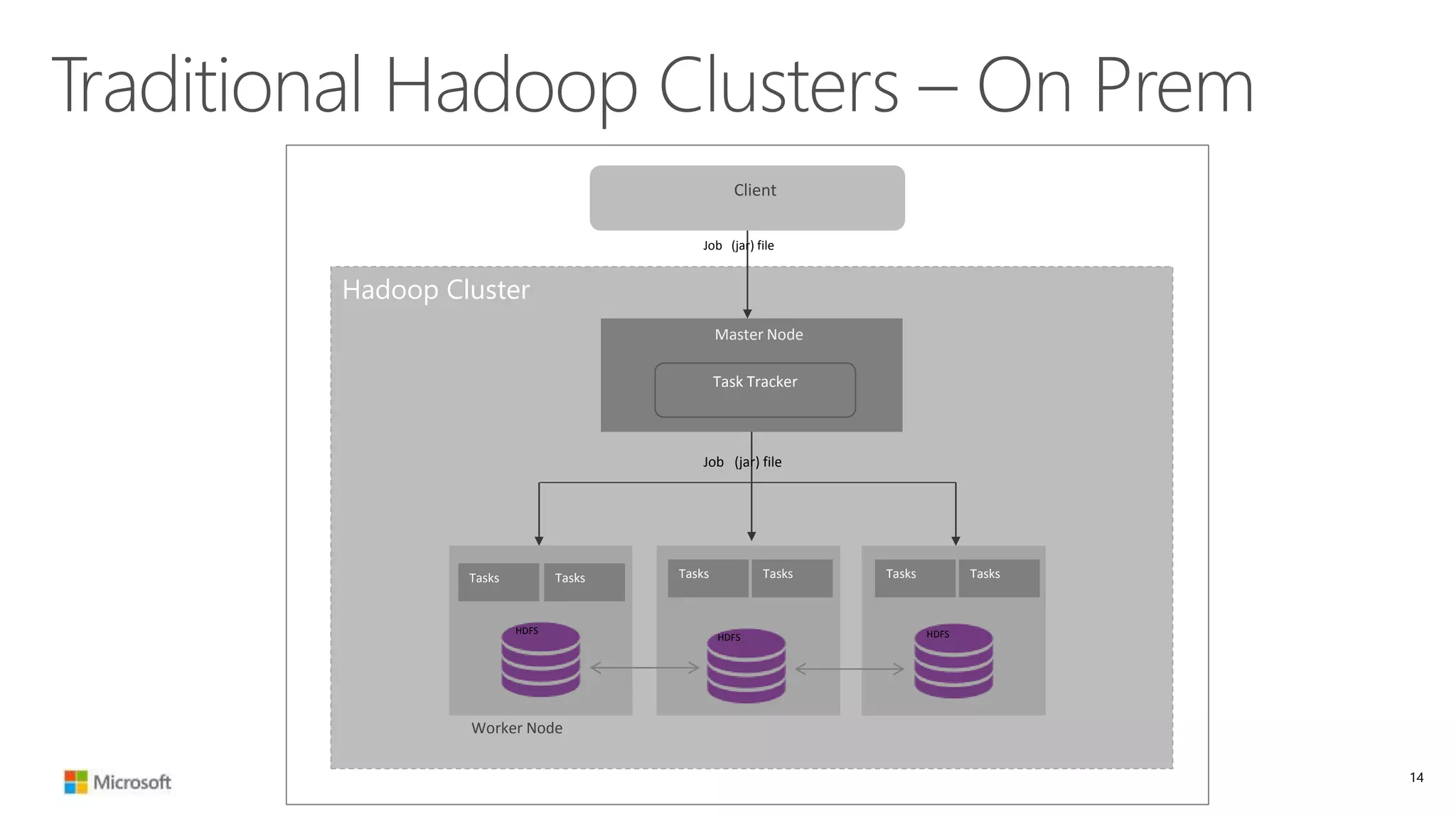
The document discusses Hadoop in the cloud and its benefits. It summarizes that Hadoop in the cloud provides distributed storage, automated failover, hyper-scaling, distributed computing, and extensibility. It also discusses deploying Hadoop clusters in Azure HDInsight and options for customizing clusters and integrating them.















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















