Download as PDF, PPTX















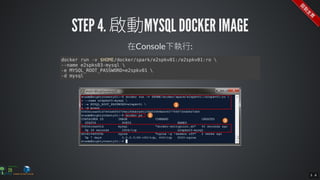
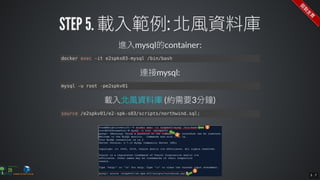




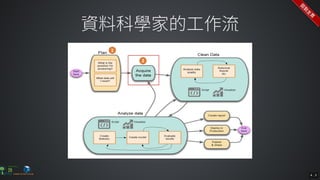
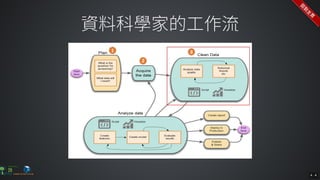
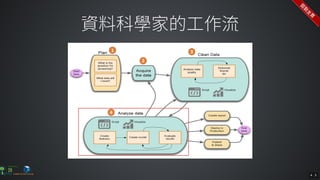
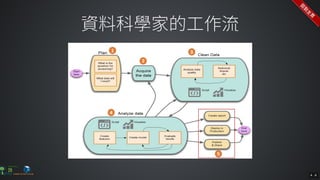
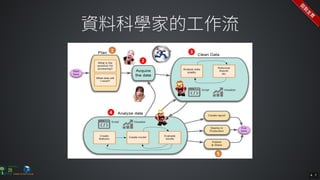
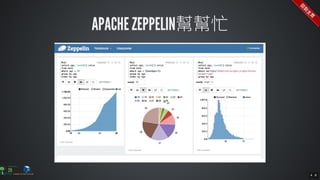



















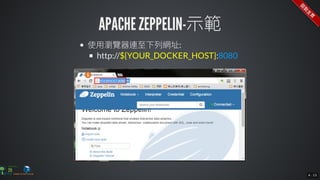
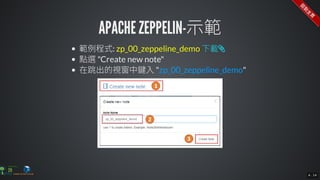

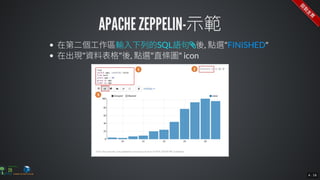

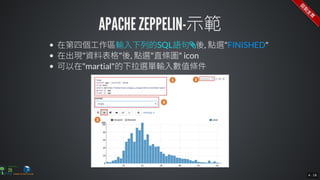





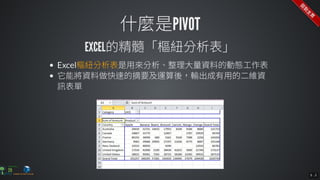


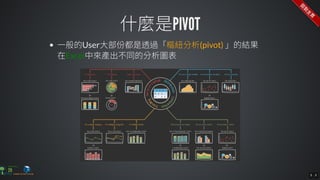

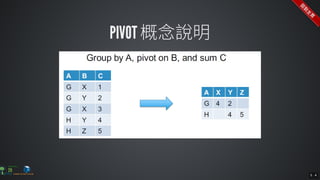

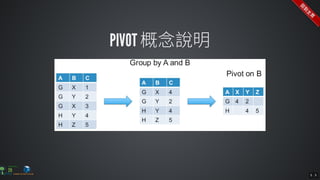

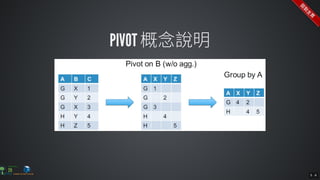


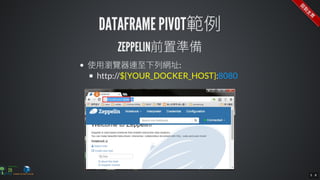
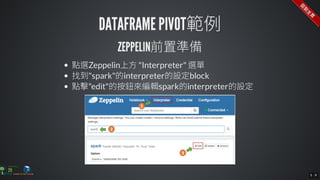

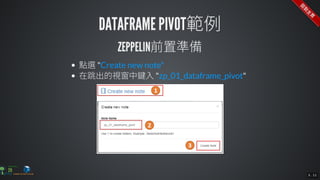
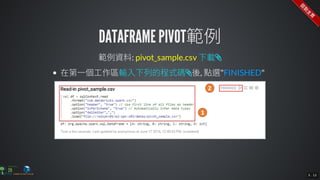










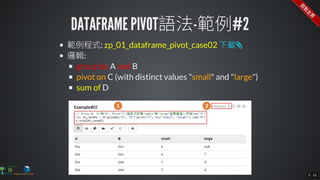







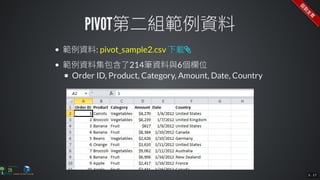
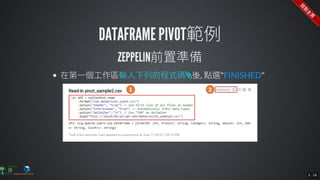




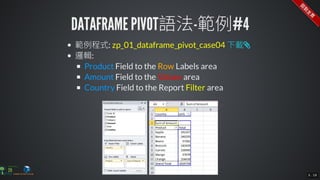

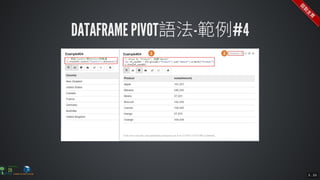





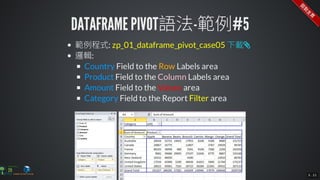
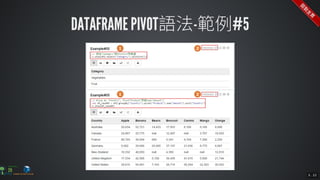

































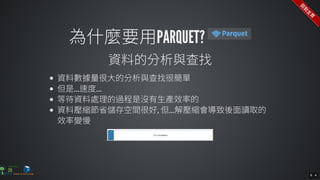










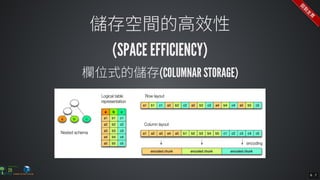





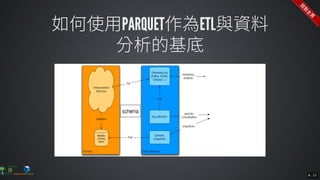
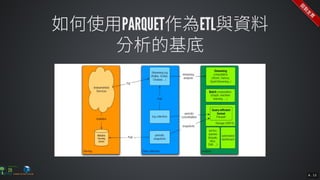
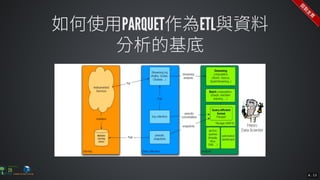









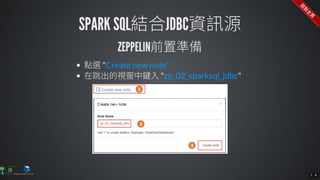



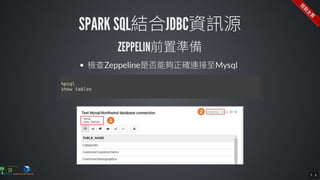























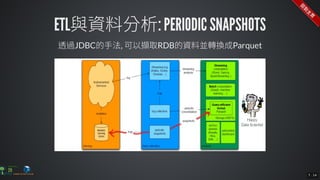



























The document contains commands for setting up a Docker environment with MySQL and Zeppelin services, including running MySQL with specified environment variables and executing SQL scripts. It also details how to work with data frames in Spark, specifically using `.groupBy()` and `.pivot()` functions to manipulate data. Additionally, it involves reading data from JDBC and Parquet formats and performing operations like schema printing and showing data.
![Spark手把手:[e2-spk-s02]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s02slides-160611131623-thumbnail.jpg?width=640&height=640&fit=bounds)
![Spark手把手:[e2-spk-s01]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s01slides-160609233431-thumbnail.jpg?width=640&height=640&fit=bounds)


![Accumulo Summit 2015: Zookeeper, Accumulo, and You [Internals]](https://cdn.slidesharecdn.com/ss_thumbnails/zookeeperaccumuloandyou-150501220518-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


























![Spark手把手:[e2-spk-s04]](https://cdn.slidesharecdn.com/ss_thumbnails/e2-spk-s04slides-160708052705-thumbnail.jpg?width=640&height=640&fit=bounds)






















































