Download as PDF, PPTX













![PRACTICAL EXAMPLES
A SIMPLE REGEXP EXPRESSION
local reconf = config['regexp'] -- Define alias for regexp module
-- Define a single regexp rule
reconf['PRECEDENCE_BULK'] = {
-- Header regexp that detects bulk email
re = 'Precedence=/bulk/Hi',
-- Default score
score = 0.1,
description = "Message marked as bulk",
group = 'upstream_spam_filters'
}
rspamd.local.lua:](https://image.slidesharecdn.com/rspamd-symbols-160725105309/85/Rspamd-symbols-16-320.jpg)
![PRACTICAL EXAMPLES
A MORE COMPLEX EXAMPLE
rspamd.local.lua:
local reconf = config['regexp'] -- Define alias for regexp module
-- Define encodings types
-- /X is undecoded header
local subject_encoded_b64 = 'Subject=/=?S+?B?/iX'
local subject_encoded_qp = 'Subject=/=?S+?Q?/iX'
-- Define whether subject must be encoded (contains non-7bit characters)
local subject_needs_mime = 'Subject=/[x00-x08x0bx0cx0e-x1fx7f-xff]/X'
-- Final rule
reconf['SUBJECT_NEEDS_ENCODING'] = {
-- Combine regexps
re = string.format('!(%s) & !(%s) & (%s)', subject_encoded_b64,
subject_encoded_qp, subject_needs_mime),
score = 3.5,
description = "Subject contains non-ASCII chars but it is not encoded",
group = 'headers'
}](https://image.slidesharecdn.com/rspamd-symbols-160725105309/85/Rspamd-symbols-17-320.jpg)
![PRACTICAL EXAMPLES
A MORE COMPLEX EXAMPLE
rspamd.local.lua:
local reconf = config['regexp'] -- Define alias for regexp module
-- Define encodings types
-- /X is undecoded header
local subject_encoded_b64 = 'Subject=/=?S+?B?/iX'
local subject_encoded_qp = 'Subject=/=?S+?Q?/iX'
-- Define whether subject must be encoded (contains non-7bit characters)
local subject_needs_mime = 'Subject=/[x00-x08x0bx0cx0e-x1fx7f-xff]/X'
-- Final rule
reconf['SUBJECT_NEEDS_ENCODING'] = {
-- Combine regexps
re = string.format('!(%s) & !(%s) & (%s)', subject_encoded_b64,
subject_encoded_qp, subject_needs_mime),
score = 3.5,
description = "Subject contains non-ASCII chars but it is not encoded",
group = 'headers'
}](https://image.slidesharecdn.com/rspamd-symbols-160725105309/85/Rspamd-symbols-18-320.jpg)
![PRACTICAL EXAMPLES
A MORE COMPLEX EXAMPLE
rspamd.local.lua:
local reconf = config['regexp'] -- Define alias for regexp module
-- Define encodings types
-- /X is undecoded header
local subject_encoded_b64 = 'Subject=/=?S+?B?/iX'
local subject_encoded_qp = 'Subject=/=?S+?Q?/iX'
-- Define whether subject must be encoded (contains non-7bit characters)
local subject_needs_mime = 'Subject=/[x00-x08x0bx0cx0e-x1fx7f-xff]/X'
-- Final rule
reconf['SUBJECT_NEEDS_ENCODING'] = {
-- Combine regexps
re = string.format('!(%s) & !(%s) & (%s)', subject_encoded_b64,
subject_encoded_qp, subject_needs_mime),
score = 3.5,
description = "Subject contains non-ASCII chars but it is not encoded",
group = 'headers'
}](https://image.slidesharecdn.com/rspamd-symbols-160725105309/85/Rspamd-symbols-19-320.jpg)






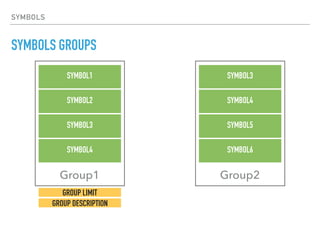
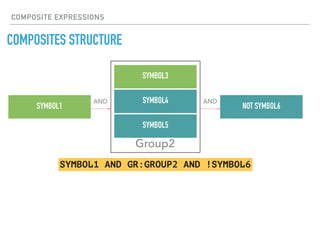
The document discusses the use of symbols and rules in Rspamd for defining spam detection logic. Symbols represent metadata like rule names and scores, while rules define spam detection expressions using regular expressions and logic. Symbols can be grouped and rules can reference symbols to define dependencies. Composites allow combining multiple rules and introducing logic to remove symbols and weights conditionally. Practical examples show how to define simple regex rules, complex rules combining multiple checks, and composites modifying rule results.









































