The document provides an overview of reinforcement learning, detailing its definition, history, usages, and open problems. It highlights practical applications in robotics, recommendation systems, and power management, along with challenges such as multi-task learning and safe exploration. The review suggests solutions like imitation learning and hierarchical learning for overcoming these challenges.



![History…
■ Studies of animal learning (1911)
– The law of effect [Thorndike, 1911]
■ Operant conditioning [Skinner, 1938]
– process by which humans and animals learn to
behave in such a way as to obtain rewards and avoid
punishments
■ Bellman formulation [1957 Bellman]
– this recursive formula provides the utility of
following certain policy expecting the highest reward
■ Q-Learning [Watkins, 1989. Ph.D. thesis]
– It solve the problem by calculation quantity of state
to actions
4](https://image.slidesharecdn.com/reinforcementlearning-171226154635/85/Reinforcement-learning-4-320.jpg)




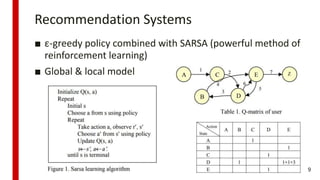

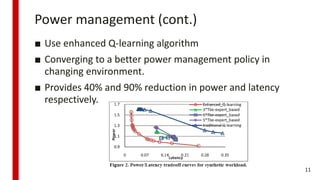


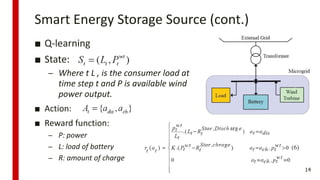
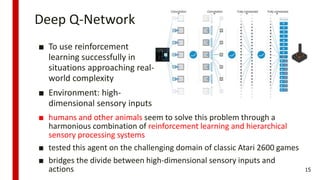
















![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







