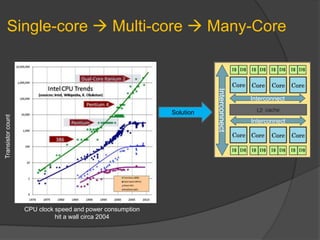
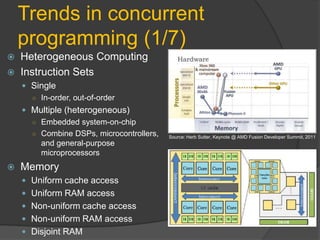
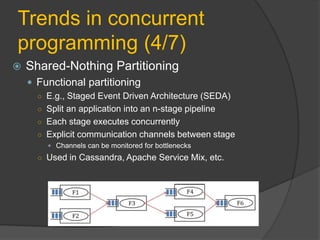
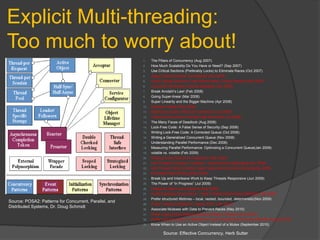
Downloaded 38 times


















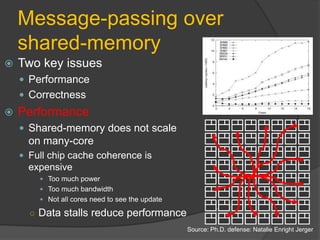
![Message-passing over
shared-memory
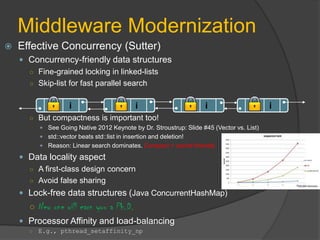
Correctness
Hard to achieve in explicit threading (even in task-based libraries)
Lock-based programs are not composable
―Perhaps the most fundamental objection [...] is that lock-based programs do not compose: correct fragments may fail when
combined. For example, consider a hash table with thread-safe insert and delete operations. Now suppose that we want to
delete one item A from table t1, and insert it into table t2; but the intermediate state (in which neither table contains the item)
must not be visible to other threads. Unless the implementer of the hash table anticipates this need, there is simply no way to
satisfy this requirement. [...] In short, operations that are individually correct (insert, delete) cannot be composed into larger
correct operations.‖
—Tim Harris et al., "Composable Memory Transactions", Section 2: Background, pg.2
Message-passing
Composable
Easy to verify and debug
Observe in/out messages only](https://image.slidesharecdn.com/esc-204slidestambe-120406161205-phpapp02/85/Retargeting-Embedded-Software-Stack-for-Many-Core-Systems-30-320.jpg)





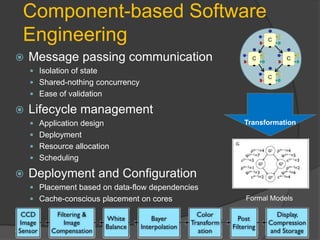
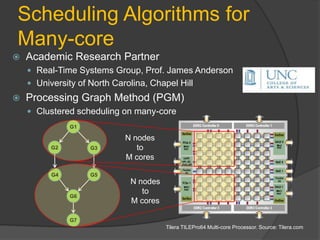
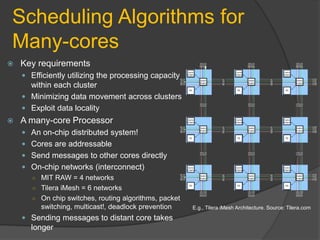
The document discusses the challenges and advancements in many-core systems, focusing on collaborative research at the University of North Carolina. It highlights issues with existing embedded software stacks, communication methods, and innovative techniques for achieving scalable applications in various domains. Key areas include scalable scheduling, resource allocation, and the development of middleware for better concurrency management.



































































