Downloaded 766 times





![6
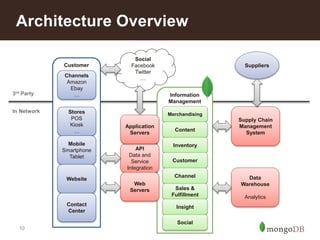
MongoDB Strategic Advantages
Horizontally Scalable
-Sharding
Agile
Flexible
High Performance &
Strong Consistency
Application
Highly
Available
-Replica Sets
{ customer: “roger”,
date: new Date(),
comment: “Spirited Away”,
tags: [“Tezuka”, “Manga”]}](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-5-320.jpg)
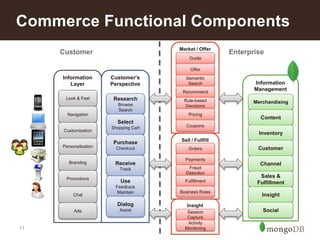
![7
build your data to fit your application
Relational MongoDB
{ customer_id : 1,
name : "Mark Smith",
city : "San Francisco",
orders: [ {
order_number : 13,
store_id : 10,
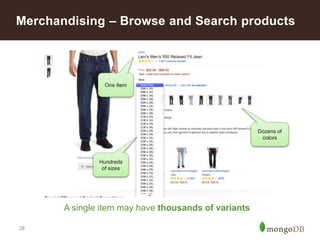
date: “2014-01-03”,
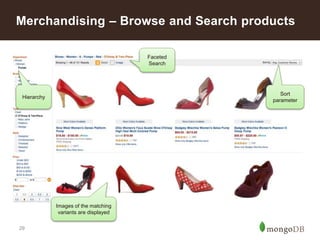
products: [
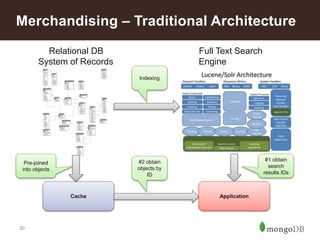
{SKU: 24578234,
Qty: 3,
Unit_price: 350},
{SKU: 98762345,
Qty: 1,
Unit_Price: 110}
]
},
{ <...> }
]
}
CustomerID First Name Last Name City
0 John Doe New York
1 Mark Smith San Francisco
2 Jay Black Newark
3 Meagan White London
4 Edward Danields Boston
Order Number Store ID Product Customer ID
10 100 Tablet 0
11 101 Smartphone 0
12 101 Dishwasher 0
13 200 Sofa 1
14 200 Coffee table 1
15 201 Suit 2](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-6-320.jpg)



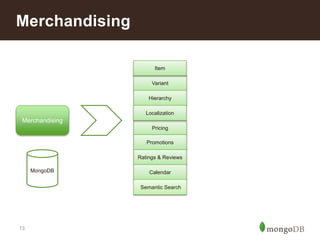



![18
• Get item by id
db.definition.findOne( { _id: "301671" } )
• Get item from Product Ids
db.definition.findOne( { _id: { $in: ["301671", "301672" ] } } )
• Get items by department
db.definition.find({ department: "Shoes" })
• Get items by category prefix
db.definition.find( { category: /^Shoes/Women/ } )
• Indices
productId, department, category, lastUpdated
Merchandising - Item Definition](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-17-320.jpg)



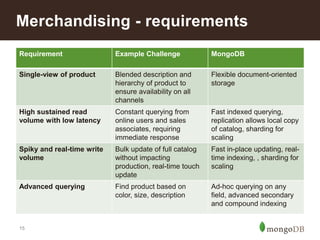
![23
• Get all prices for a given item
db.prices.find( { _id: /^p301671_/ )
• Get all prices for a given sku (price could be at item level)
db.prices.find( { _id: { $in: [ /^sku730223104376_/, /^p301671_/ ])
• Get minimum and maximum prices for a sku
db.prices.aggregate( { match }, { $group: { _id: 1, min: { $min: price },
max: { $max : price} } })
• Get price for a sku and store id (returns up to 4 prices)
db.prices.find( { _id: { $in: [ "sku730223104376_store1234",
"sku730223104376_sgroup0",
"p301671_store1234",
"p301671_sgroup0"] , { price: 1 })
Merchandising – per store Pricing](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-21-320.jpg)




![34
> db.summaries.findOne()
{ "_id": "p39",
"title": "Evening Platform Pumps 39",
"department": "Shoes", "category": "Shoes/Women/Pumps",
"thumbnail": "http://cdn…/pump-small-39.jpg", "image":
"http://cdn…/pump-39.jpg",
"price": 145.99,
"rating": 0.95,
"attrs": [ { "brand" : "Guess"}, … ],
"sattrs": [ { "style" : "Designer"} , { "type" : "Platform"}, …],
"vars": [
{ "sku": "sku2441",
"thumbnail": "http://cdn…/pump-small-39.jpg.Blue",
"image": "http://cdn…/pump-39.jpg.Blue",
"attrs": [ { "size": 6.0 }, { "color": "Blue" }, …],
"sattrs": [ { "width" : "B"} , { "heelHeight" : 5.0 }, …],
}, … Many more skus …
] }
Merchandising – Summary Model](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-30-320.jpg)









![52
Stores – Sample Geo Queries
• Get nearby stores sorted by distance
db.runCommand({
geoNear : "stores",
near : {
type : "Point",
coordinates : [-82.8006, 40.0908] },
maxDistance : 10000.0,
spherical : true
})](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-46-320.jpg)
![53
Stores – Sample Geo Queries
• Get the five nearest stores within 10 km
db.stores.find({
location : {
$near : {
$geometry : {
type : "Point",
coordinates : [-82.80, 40.09] },
$maxDistance : 10000 } }
}).limit(5)](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-47-320.jpg)

![55
Inventory – Sample Document
• > db.inventory.findOne()
• {
• "_id": "5354869f300487d20b2b011d",
• "storeId": "store0",
• "location": [-86.95444, 33.40178],
• "productId": "p0",
• "vars": [
• { "sku": "sku1", "q": 14 },
• { "sku": "sku3", "q": 7 },
• { "sku": "sku7", "q": 32 },
• { "sku": "sku14", "q": 65 },
• ...](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-49-320.jpg)



![59
Inventory – Sample Aggregations
• Aggregate total quantity for a product
db.inventory.aggregate( [
{ $match : { productId : "p200" } },
{ $unwind : "$vars" },
{ $group : {
_id : "result",
count : { $sum : "$vars.q" } } } ] )
{ "_id" : "result", "count" : 101752 }](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-53-320.jpg)
![60
Inventory – Sample Aggregations
• Aggregate total quantity for a store
db.inventory.aggregate( [
{ $match : { storeId : "store100" } },
{ $unwind : "$vars" },
{ $match : { "vars.q" : { $gt : 0 } } },
{ $group : {
_id : "result",
count : { $sum : 1 } } } ] )
{ "_id" : "result", "count" : 29347 }](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-54-320.jpg)
![61
Inventory – Sample Aggregations
• Aggregate total quantity for a store
db.inventory.aggregate( [
{ $match : { storeId : "store100" } },
{ $unwind : "$vars" },
{ $group : {
_id : "result",
count : { $sum : "$vars.q" } } } ] )
{ "_id" : "result", "count" : 29347 }](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-55-320.jpg)
![64
Inventory – Sample Geo-Query
• Get inventory for an item near a point
db.runCommand( {
geoNear : "inventory",
near : {
type : "Point",
coordinates : [-82.8006, 40.0908] },
maxDistance : 10000.0,
spherical : true,
limit : 10,
query : { "productId" : "p200",
"vars.sku" : "sku11736" } } )](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-57-320.jpg)
![65
Inventory – Sample Geo-Query
• Get closest store with available sku
db.runCommand( {
geoNear : "inventory",
near : {
type : "Point",
coordinates : [-82.800672, 40.090844] },
maxDistance : 10000.0,
spherical : true,
limit : 1,
query : {
productId : "p200",
vars : {
$elemMatch : { sku : "sku11736",
q : { $gt : 0 } } } } } )](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-58-320.jpg)
![66
Inventory – Sample Geo-Aggregation
• Get count of inventory for an item near a point
db.inventory.aggregate( [
{ $geoNear: {
near : { type : "Point",
coordinates : [-82.800672, 40.090844] },
distanceField: "distance",
maxDistance: 10000.0, spherical : true,
query: { productId : "p200",
vars : { $elemMatch : { sku : "sku11736",
q : {$gt : 0} } } },
includeLocs: "dist.location",
num: 5 } },
{ $unwind: "$vars" },
{ $match: { "vars.sku" : "sku11736" } },
{ $group: { _id: "result", count: {$sum: "$vars.q"} } }])](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-59-320.jpg)










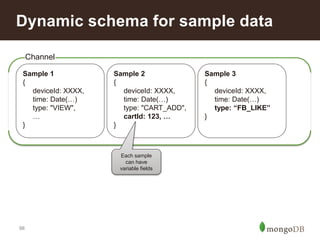
![97
{ _id: ObjectId(),
geoCode: 1, // used to localize write operations
sessionId: "2373BB…",
device: { id: "1234",
type: "mobile/iphone",
userAgent: "Chrome/34.0.1847.131"
}
userId: "u123",
type: "VIEW|CART_ADD|CART_REMOVE|ORDER|…", // type of activity
itemId: "301671",
sku: "730223104376",
order: { id: "12520185",
… },
location: [ -86.95444, 33.40178 ],
tags: [ "smartphone", "iphone", … ], // associated tags
timeStamp: Date("2014/04/01 …")
}
User Activity - Model](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-76-320.jpg)
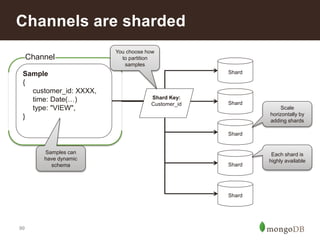
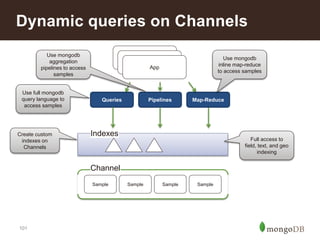




![107
• Get the recent number of views, purchases, etc for a user
db.activities.aggregate(([
{ $match: { userId: "u123", time: { $gt: DATE } }},
{ $group: { _id: "$type", count: {$sum: 1} } }])
• Get the total recent sales for a user
db.activities.aggregate(([
{ $match: { userId: "u123", time: { $gt: DATE }, type: "ORDER" }},
{ $group: { _id: "result", count: {$sum: "$totalPrice"} } }])
• Get the recent number of views, purchases, etc for an item
db.activities.aggregate(([
{ $match: { itemId: "301671", time: { $gt: DATE } }},
{ $group: { _id: "$type", count: {$sum: "1"} } }])
• Those aggregations are very fast, real-time
Insight – User Stats](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-86-320.jpg)
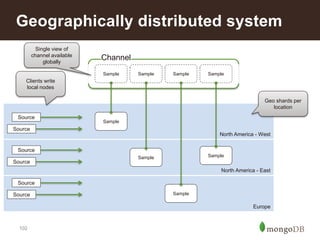
![108
• number of activities for unique visitors for the past hour. Calculation of
uniques is hard for any system!
db.activities.aggregate(([
{ $match: { time: { $gt: NOW-1H } }},
{ $group: { _id: "$userId", count: {$sum: 1} } }], { allowDiskUse: 1 })
• Aggregation above can have issues (single shard final grouping, result
not persisted). Map Reduce is a better alternative here
var map = function() { emit(this.userId, 1); }
var reduce = function(key, values) { return Array.sum(values); }
db.activities.mapreduce(map, reduce,
{ query: { time: { $gt: NOW-1H } },
out: { replace: "lastHourUniques", sharded: true })
db.lastHourUniques.find({ userId: "u123" }) // number activities for a user
db.lastHourUniques.count() // total uniques
Insight – User Stats](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-87-320.jpg)
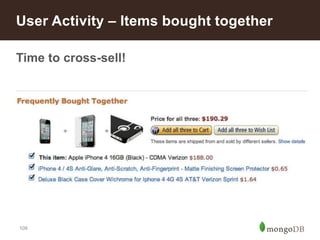
![110
Let's simplify each activity recorded as the following:
{ userId: "u123", type: order, itemId: 2, time: DATE }
{ userId: "u123", type: order, itemId: 3, time: DATE }
{ userId: "u234", type: order, itemId: 7, time: DATE }
Calculate items bought by a user with Map Reduce:
- Match activities of type "order" for the past 2 weeks
- map: emit the document by userId
- reduce: push all itemId in a list
- Output looks like { _id: "u123", items: [2, 3, 8] }
User Activity – Items bought together](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-89-320.jpg)

![112
Then obtain the most popular combinations per item:
- Index created on { _id.a : 1, count: 1 } and { _id.b: 1, count: 1 }
- Query with a threshold:
- db.combinations.find( { _id.a: "u123", count: { $gt: 10 }} ).sort({ count: -1 })
- db.combinations.find( { _id.b: "u123", count: { $gt: 10 }} ).sort({ count: -1 })
Later we can create a more compact recommendation collection
that includes popular combinations with weights, like:
{ itemId: 2, recom: [ { itemId: 32, weight: 36},
{ itemId: 158, weight: 23}, … ] }
User Activity – Items bought together](https://image.slidesharecdn.com/retailreferencearchitecture-140626110316-phpapp02/85/Retail-Reference-Architecture-91-320.jpg)







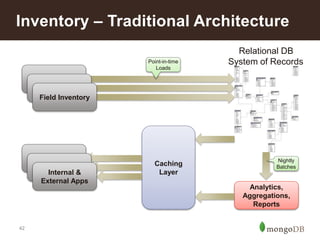
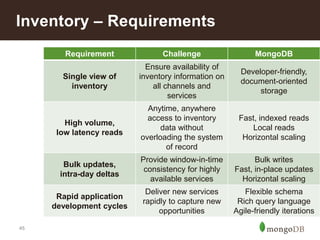
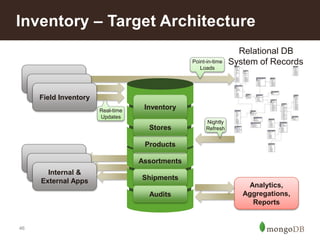
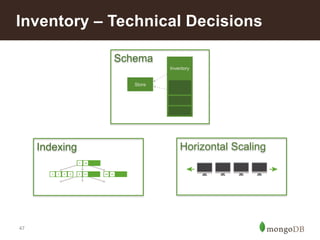
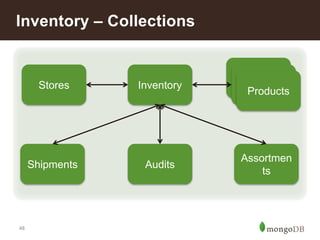
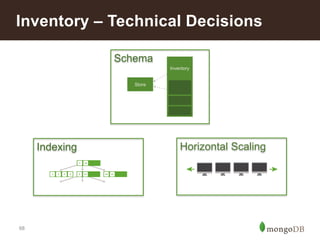
This document discusses using MongoDB for inventory management in retail applications. Some key points: - MongoDB allows for a single view of inventory across all channels with real-time updates and bulk writes for refresh. Its flexible schema and horizontal scaling are well-suited for inventory needs. - Collections would include Stores, Inventory, Products, Audits, Assortments, and Shipments. Stores documents contain store-specific metadata. - Inventory documents have embedded documents for products and variants with attributes like size and color. This embedded structure allows for efficient queries on combinations of attributes. - The target architecture replaces traditional batch-based ETL with real-time updates to MongoDB for improved customer experience and business operations.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































