Downloaded 61 times





























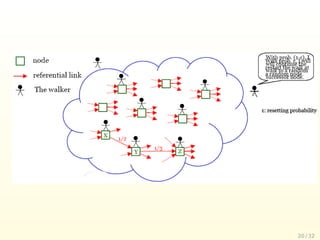




















The document discusses various reputation systems used online, including HITS and PageRank for ranking web pages based on hyperlink structure, eBay and EigenTrust for calculating trustworthiness in peer-to-peer networks, and VKontakte for determining user reputation on a Russian social network. It provides an overview of how these systems work, such as by modeling random walks on graphs or defining hub and authority scores. The document also outlines some open challenges in reputation systems like spam protection and understanding real-world implementations.



































































