Download to read offline

![Topological methods
Topological methods are based on the simple
premise that, given a query that describes
some required features, we are interested in
identifying library assets that come closest to
providing these features. Such methods are
critically dependent on what it means to come
closest, which in turn depends on some
definition of distance between the query and
candidate assets [1].](https://image.slidesharecdn.com/topologicalmethodsppt-120927011701-phpapp02/85/Topological-methods-2-320.jpg)




![What is PageRank?
• In short PageRank is a “vote”, by all the other
pages on the Web, about how important a
page is [3].
• A link to a page counts as a vote of support
• PR(A) = (1-d) + d(PR(T1)/C(T1)
+…+PR(Tn)/C(Tn))](https://image.slidesharecdn.com/topologicalmethodsppt-120927011701-phpapp02/85/Topological-methods-7-320.jpg)


![Simple Example
• Each page has one outgoing link (backlink). So that
means [2] :
• C(T1) = 1 for A
and
• C(T2) = 1 for B](https://image.slidesharecdn.com/topologicalmethodsppt-120927011701-phpapp02/85/Topological-methods-10-320.jpg)



![References:
[1] A survey of software reuse libraries A. Mili a,_, R. Mili
b and R.T. Mittermeir Annals of Software
Engineering 5 (1998) 349–414 349
[2] http://wwwdb.stanford.edu/~backrub/google.html
http://www-db.stanford.edu/~backrub/google.html
[3] Semantic Component Retrieval in Software
Engineering Inaugural dissertation zur Erlangung des
akademischen Grades eines Doktors der
Naturwissenschaften der, Universitat Mannheim,
Mannheim, 2008](https://image.slidesharecdn.com/topologicalmethodsppt-120927011701-phpapp02/85/Topological-methods-15-320.jpg)

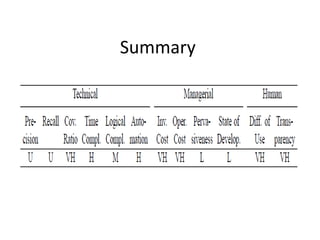
Topological methods are techniques for software component retrieval from repositories based on similarity between query specifications and component properties. They rely on defining a distance measure between queries and components. PageRank is used to calculate importance scores for components based on their relationships to other components defined by shared keywords. It is an iterative process where initial scores are calculated and used to recalculate new scores until they converge. PageRank allows for ranking of components in a repository based on their relevance to queries.





























































