Downloaded 23 times



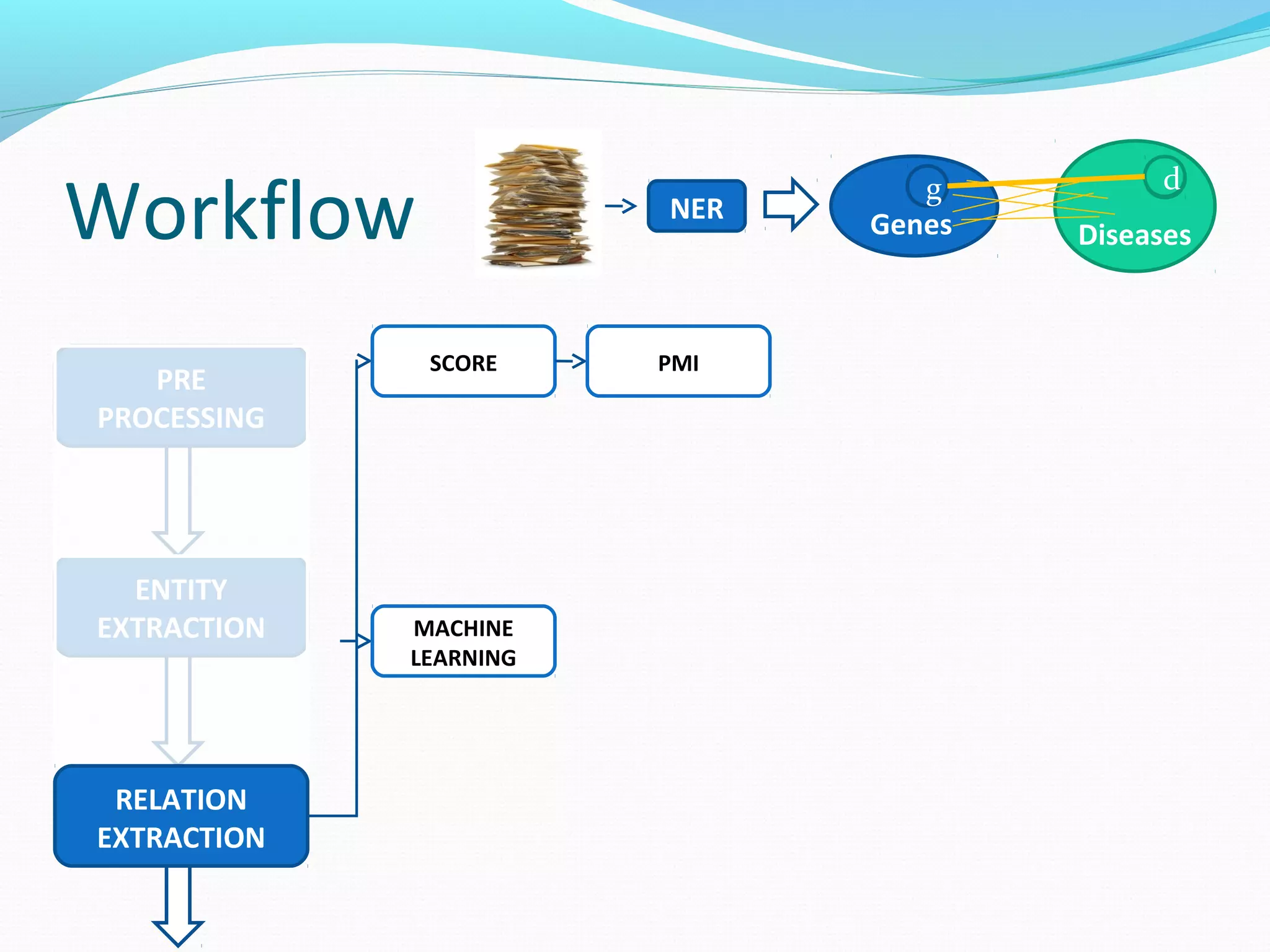
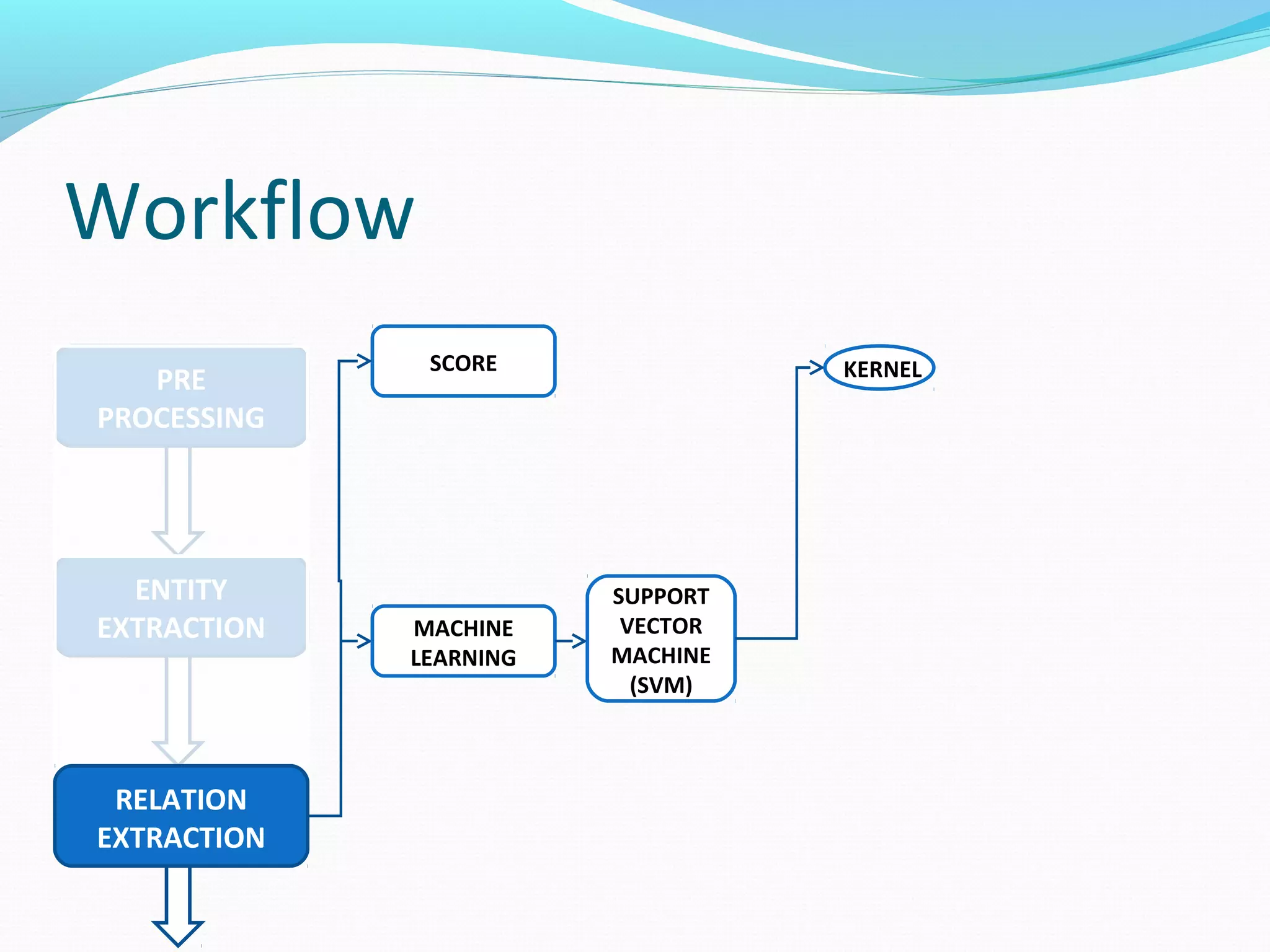

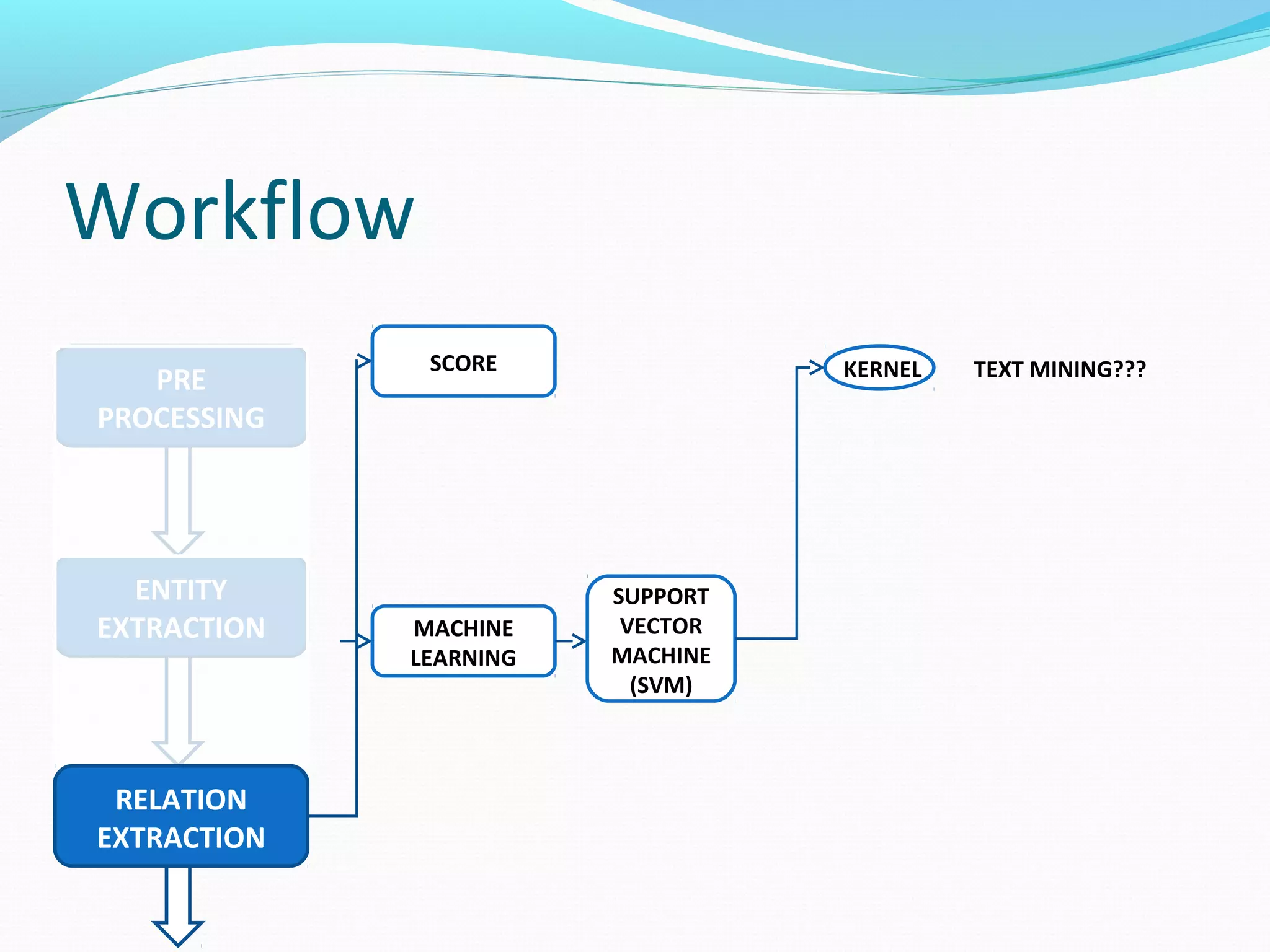
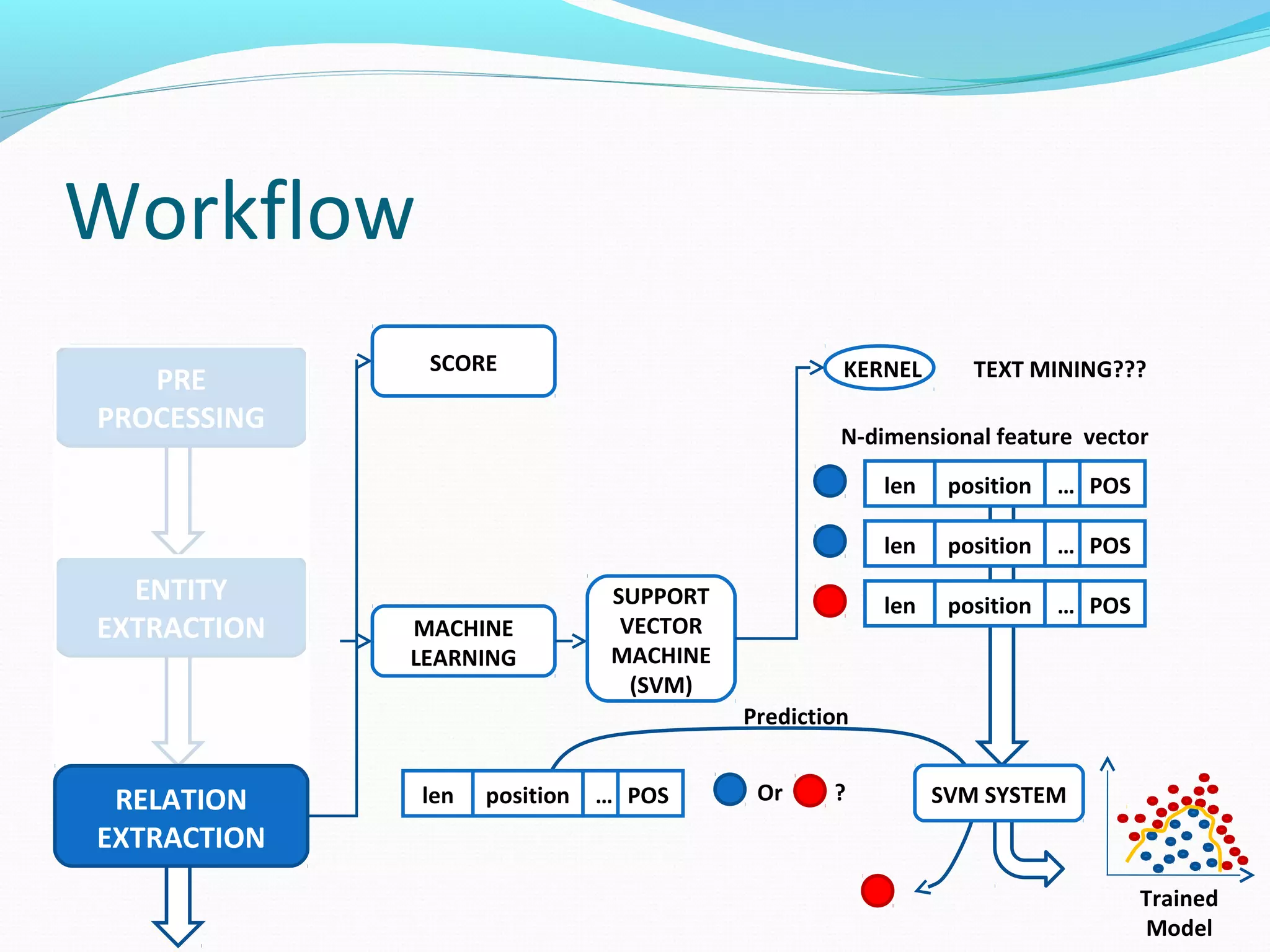
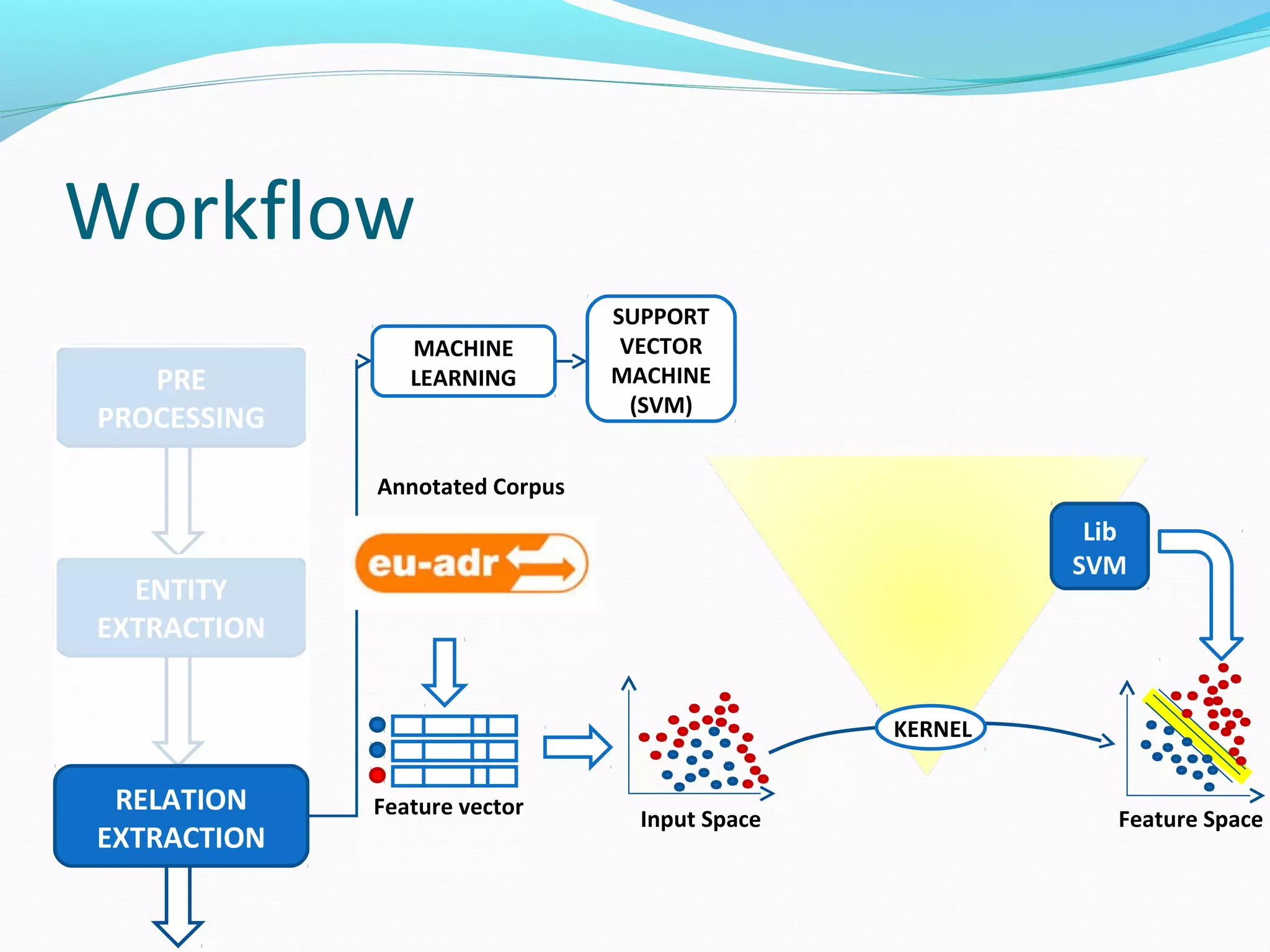
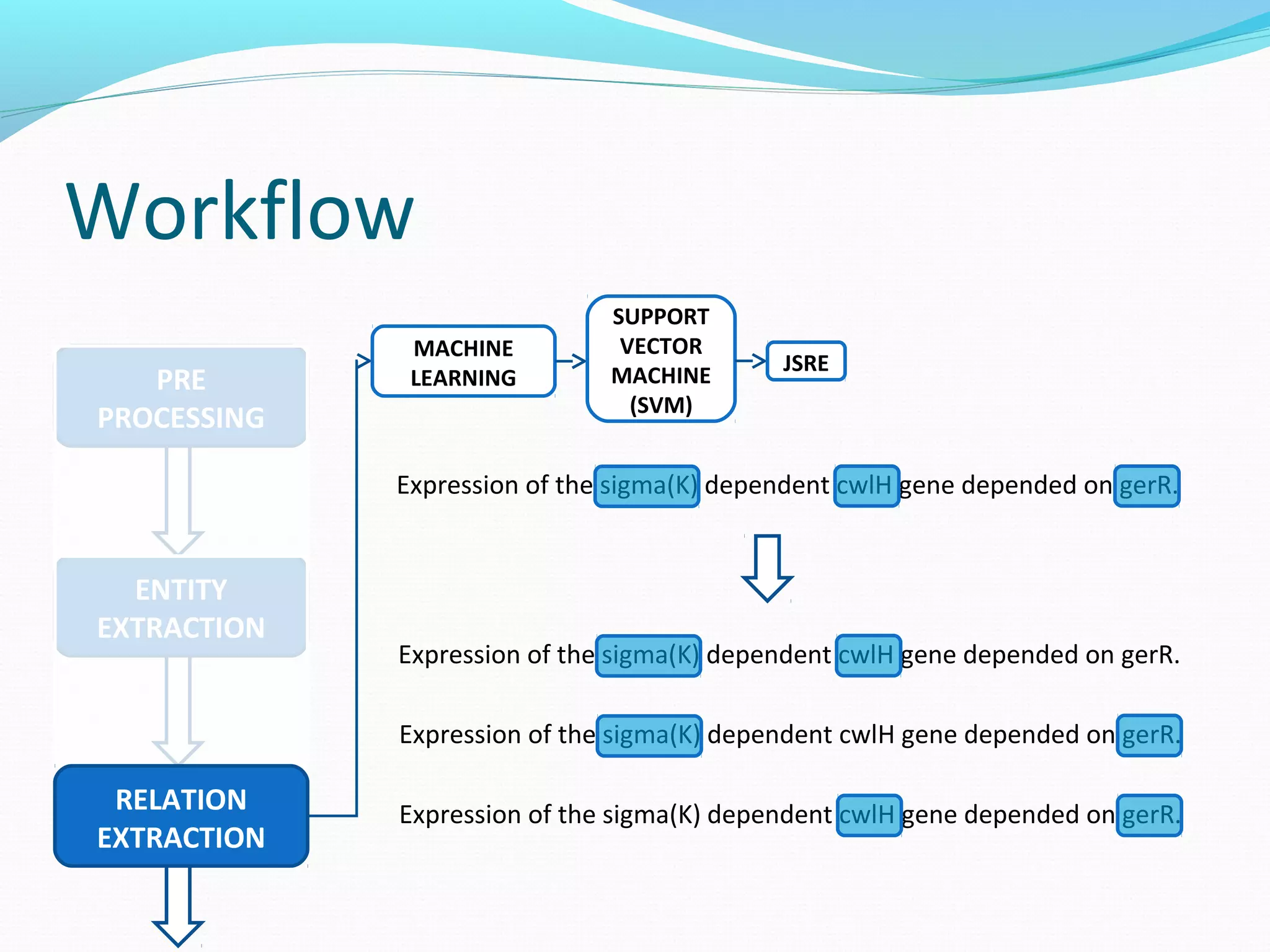
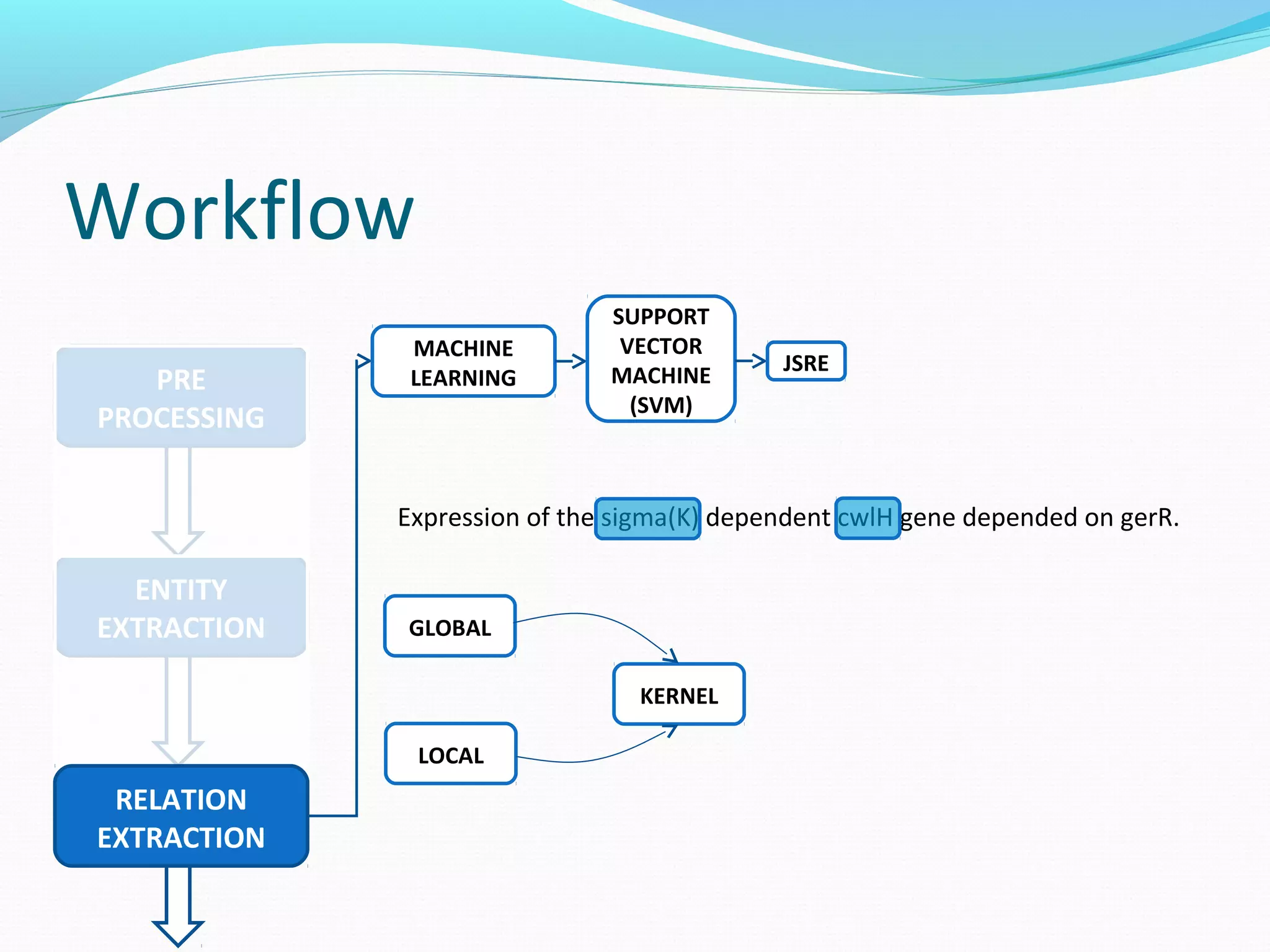
![Workflow
ENTITY
EXTRACTION
PRE
PROCESSING
RELATION
EXTRACTION
MACHINE
LEARNING
SUPPORT
VECTOR
MACHINE
(SVM)
JSRE
Expression of the sigma(K) dependent cwlH gene depended on gerR.
BETWEEN AFTERFORE [1] [2]
GLOBAL](https://image.slidesharecdn.com/groupmeeting2012121-141009084418-conversion-gate02/75/Relation-Extraction-52-2048.jpg)
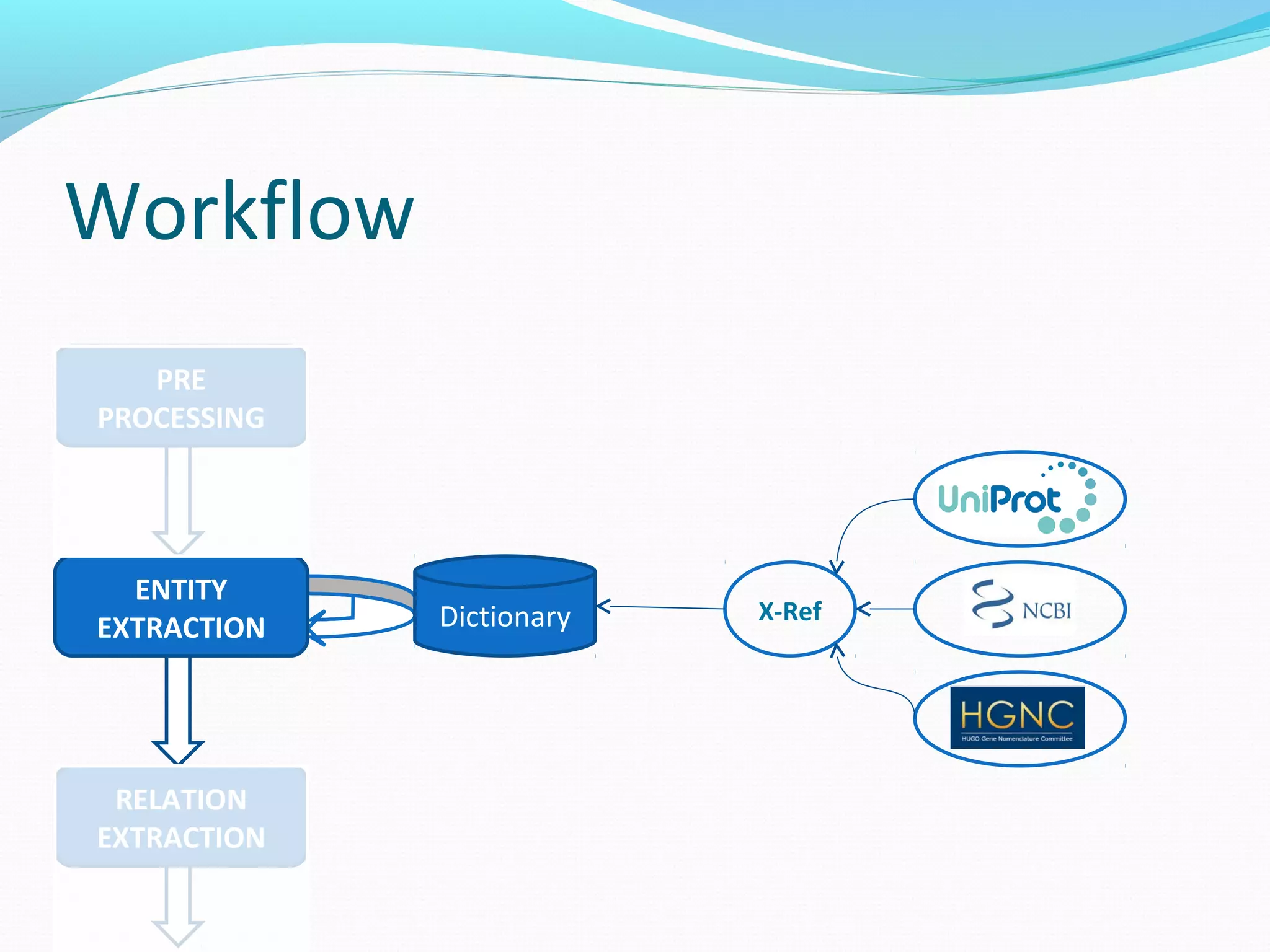
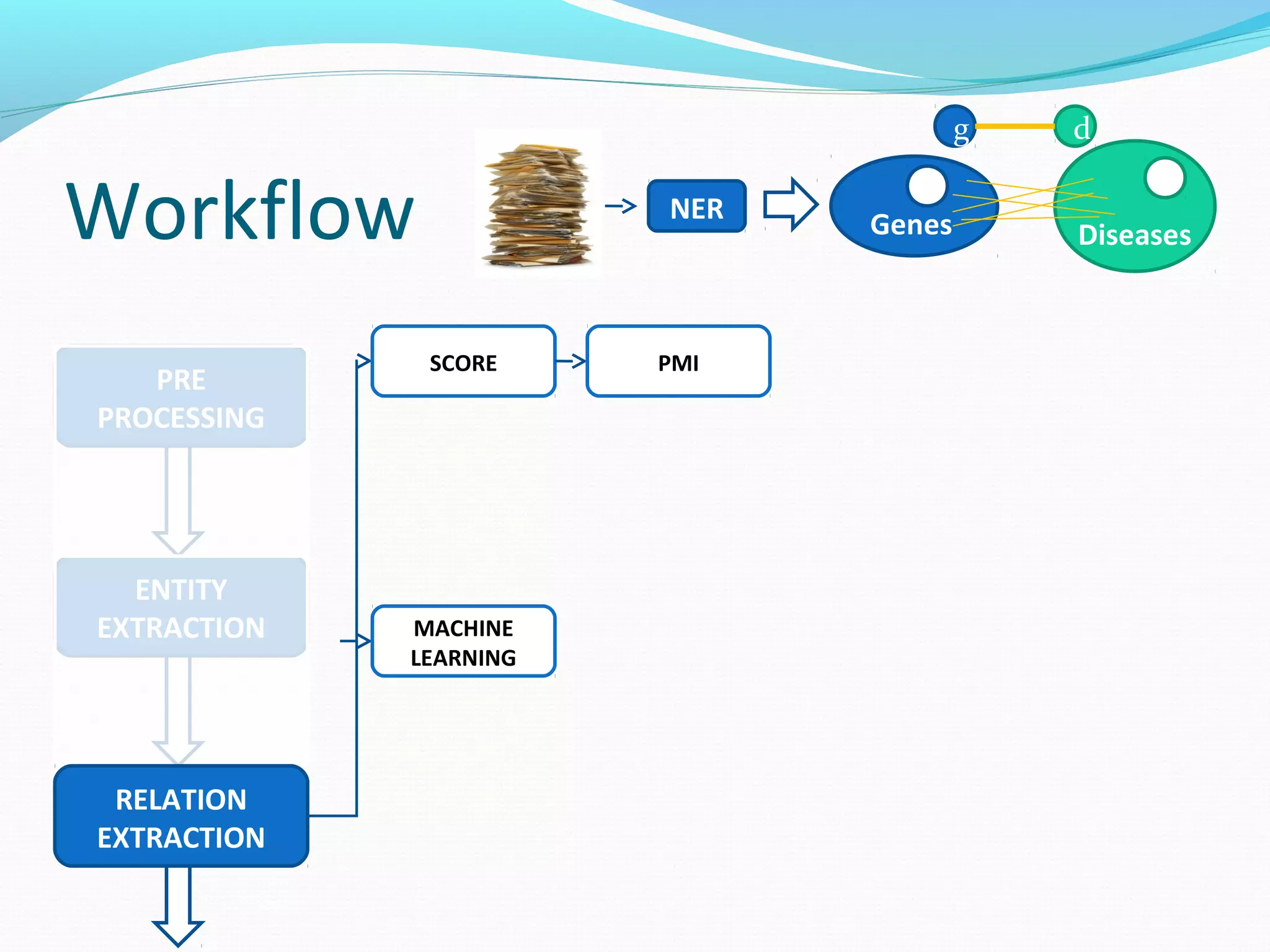
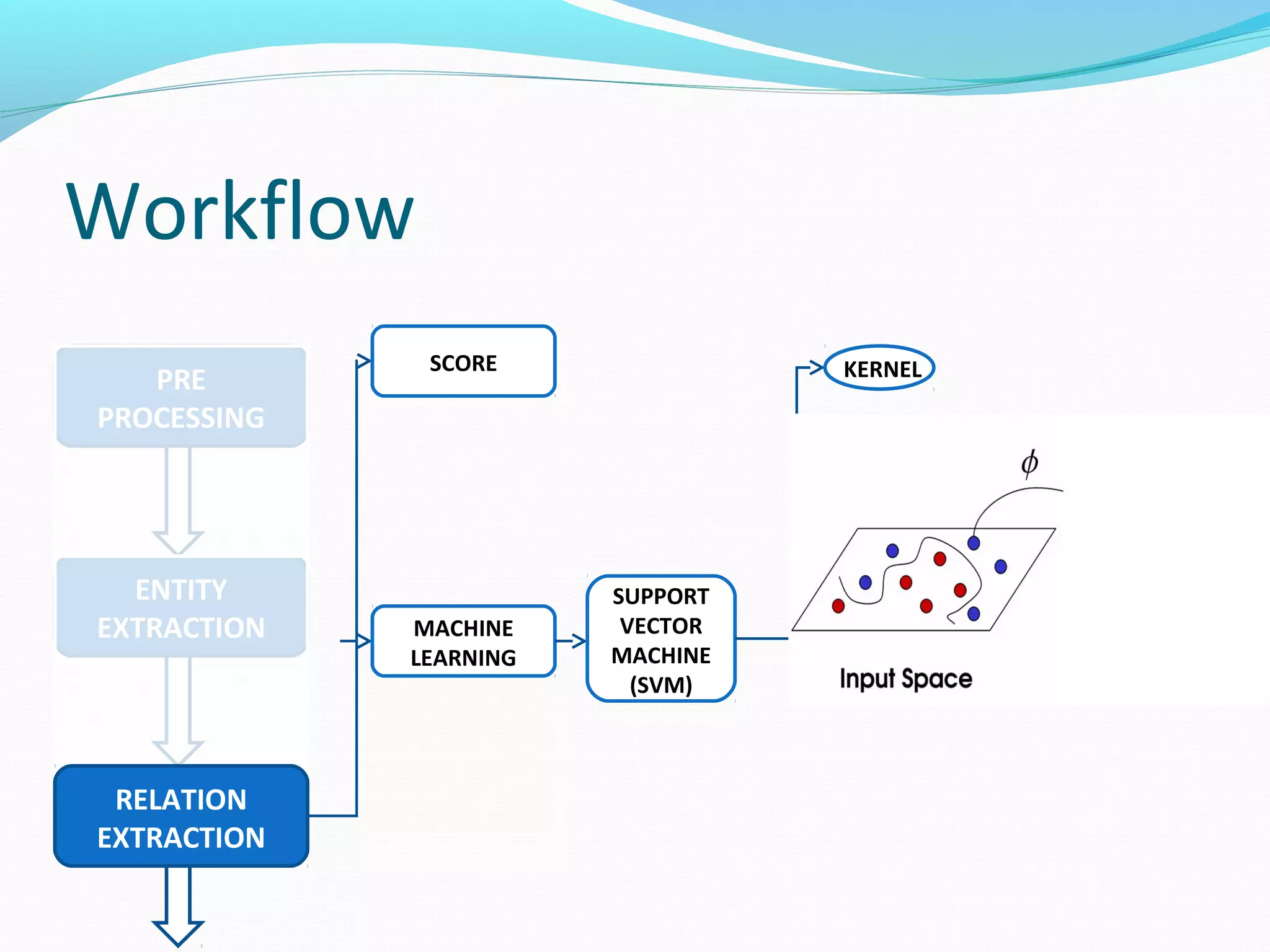
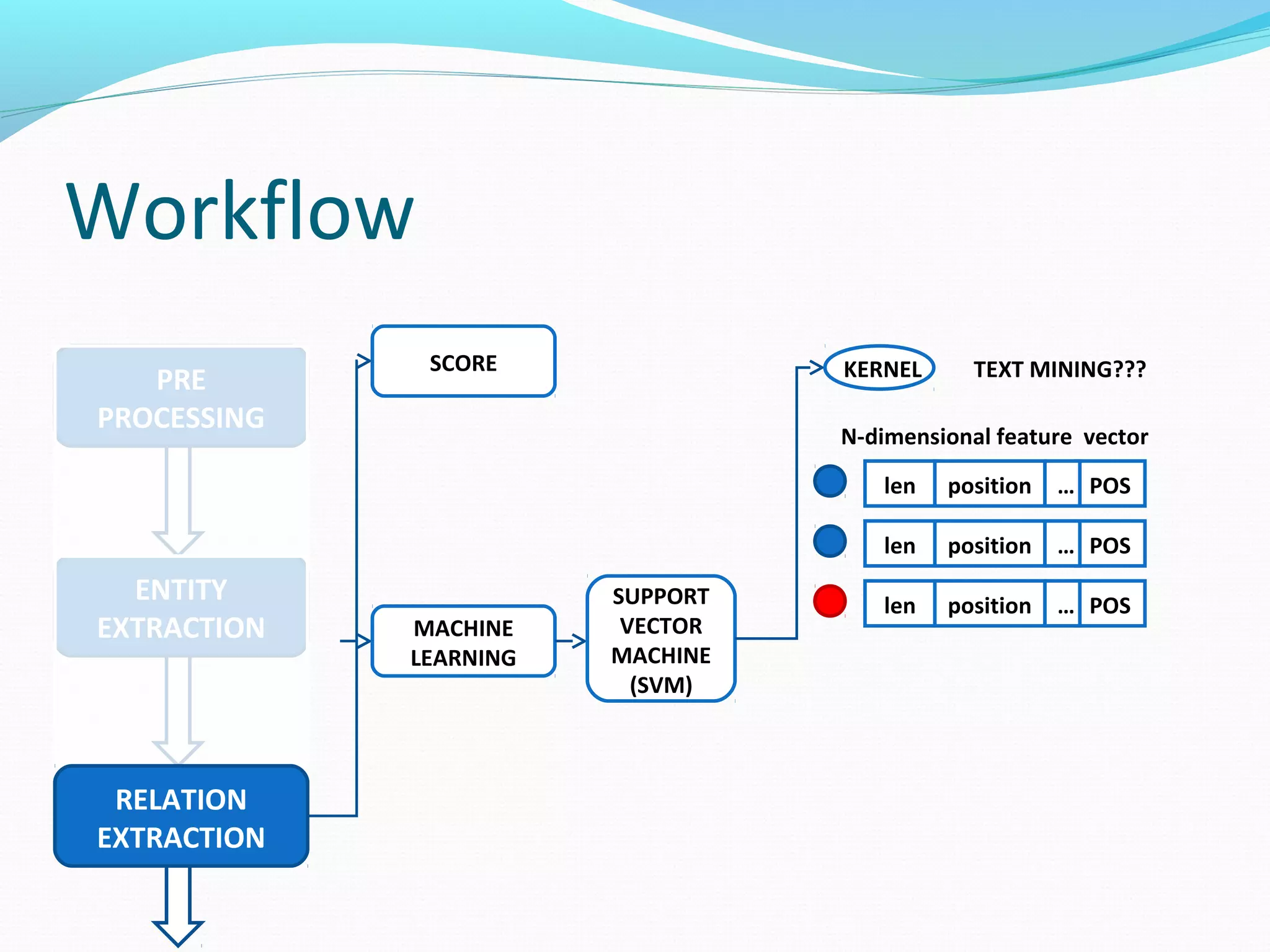
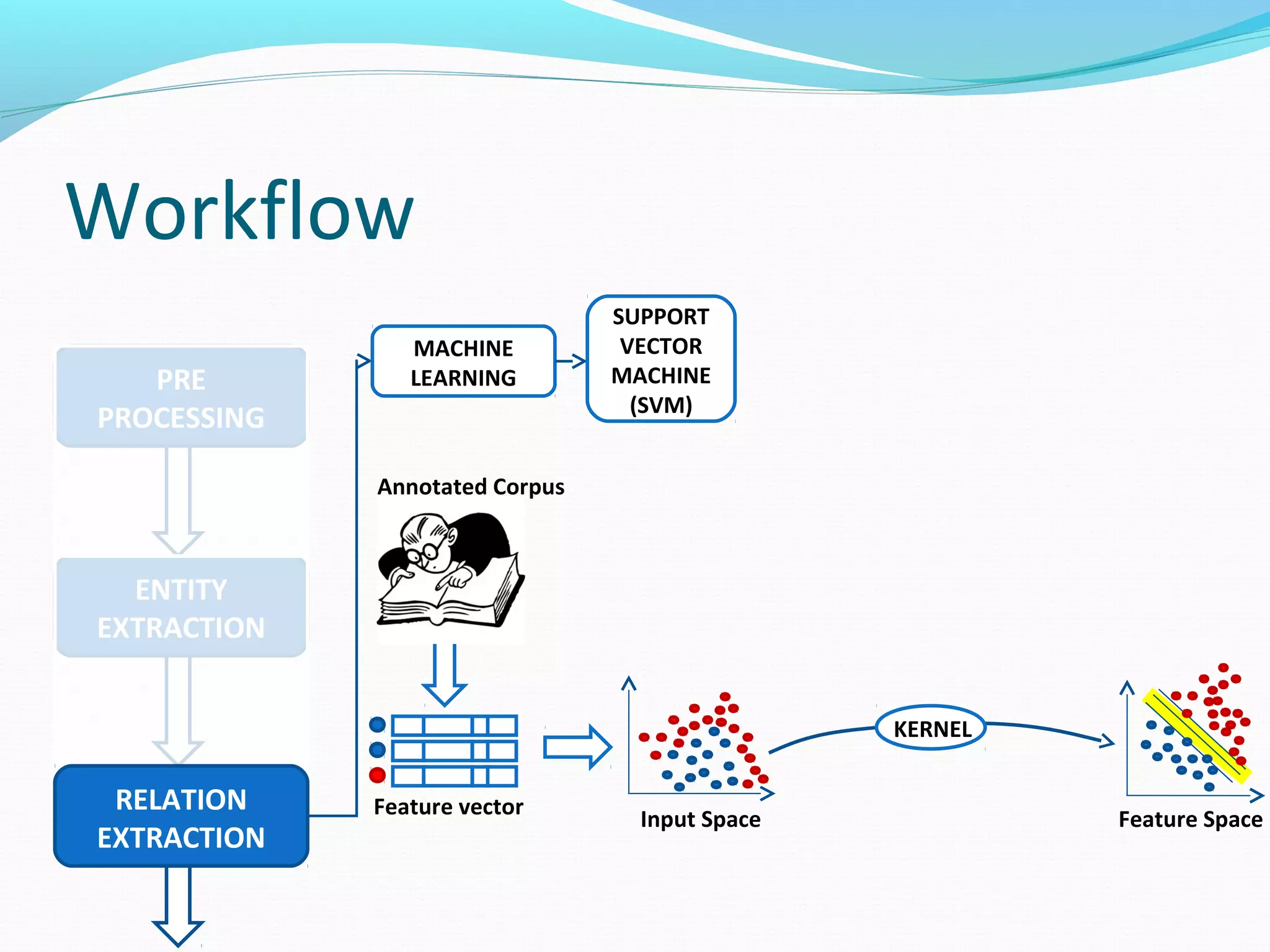
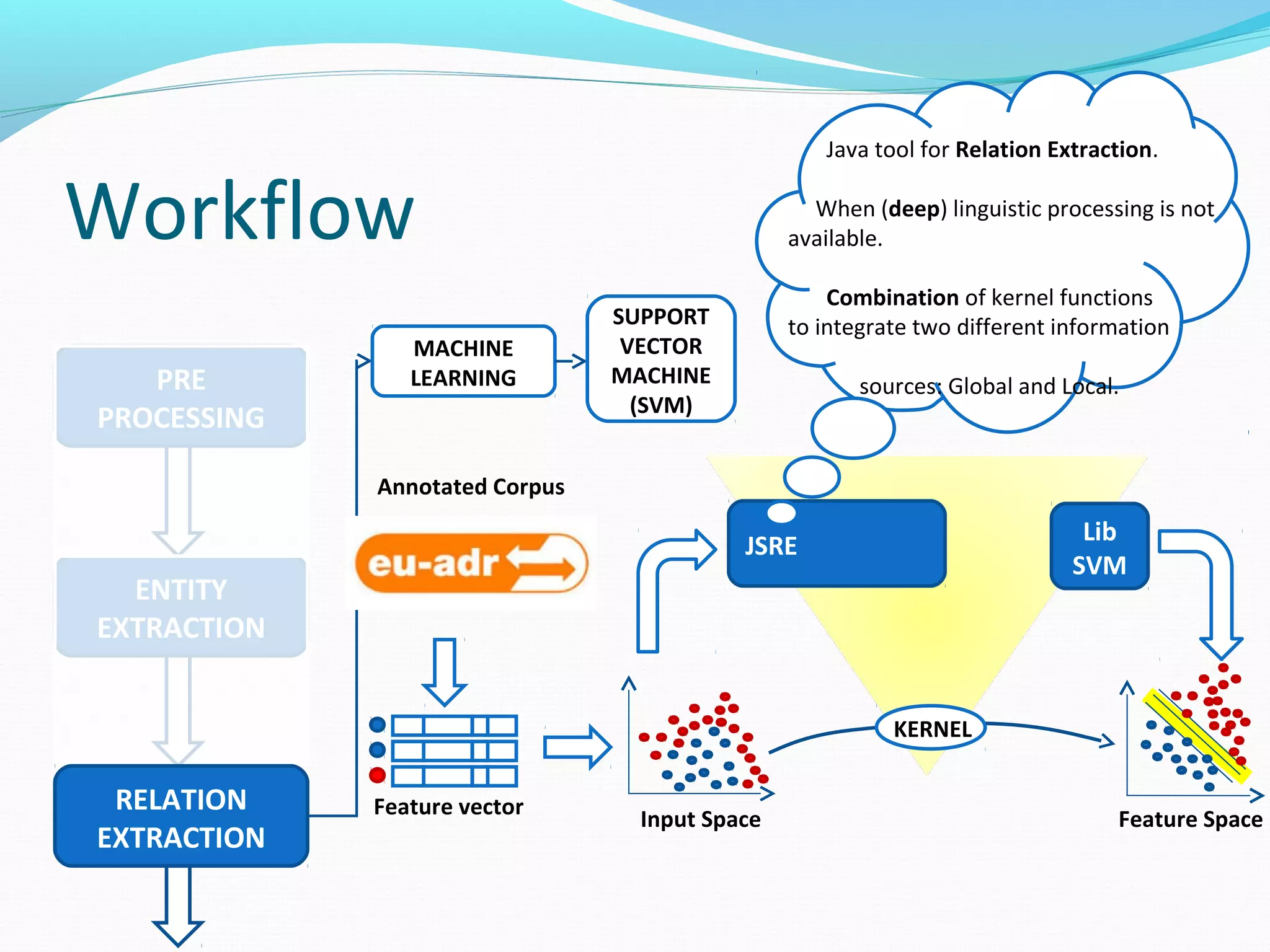
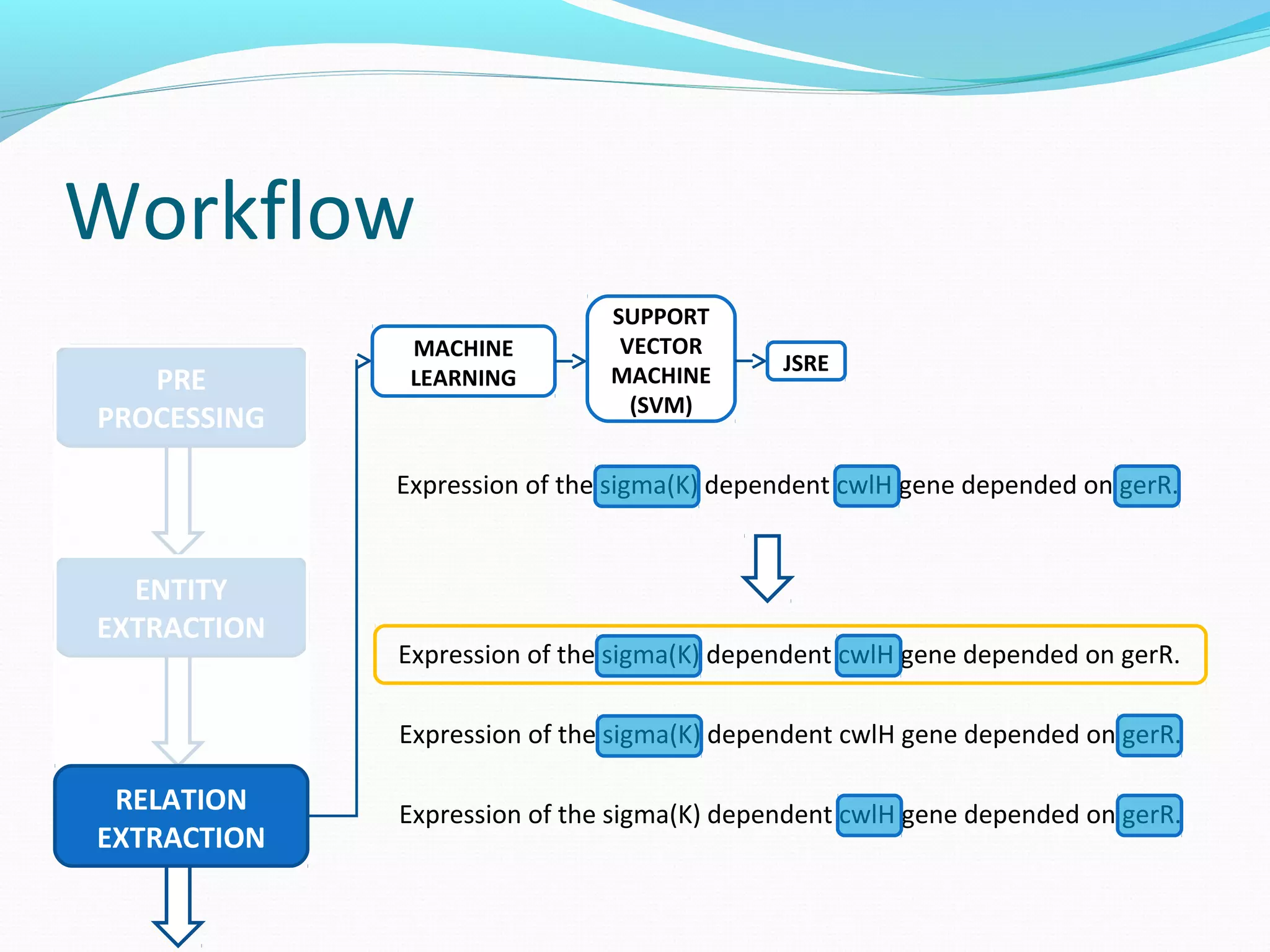
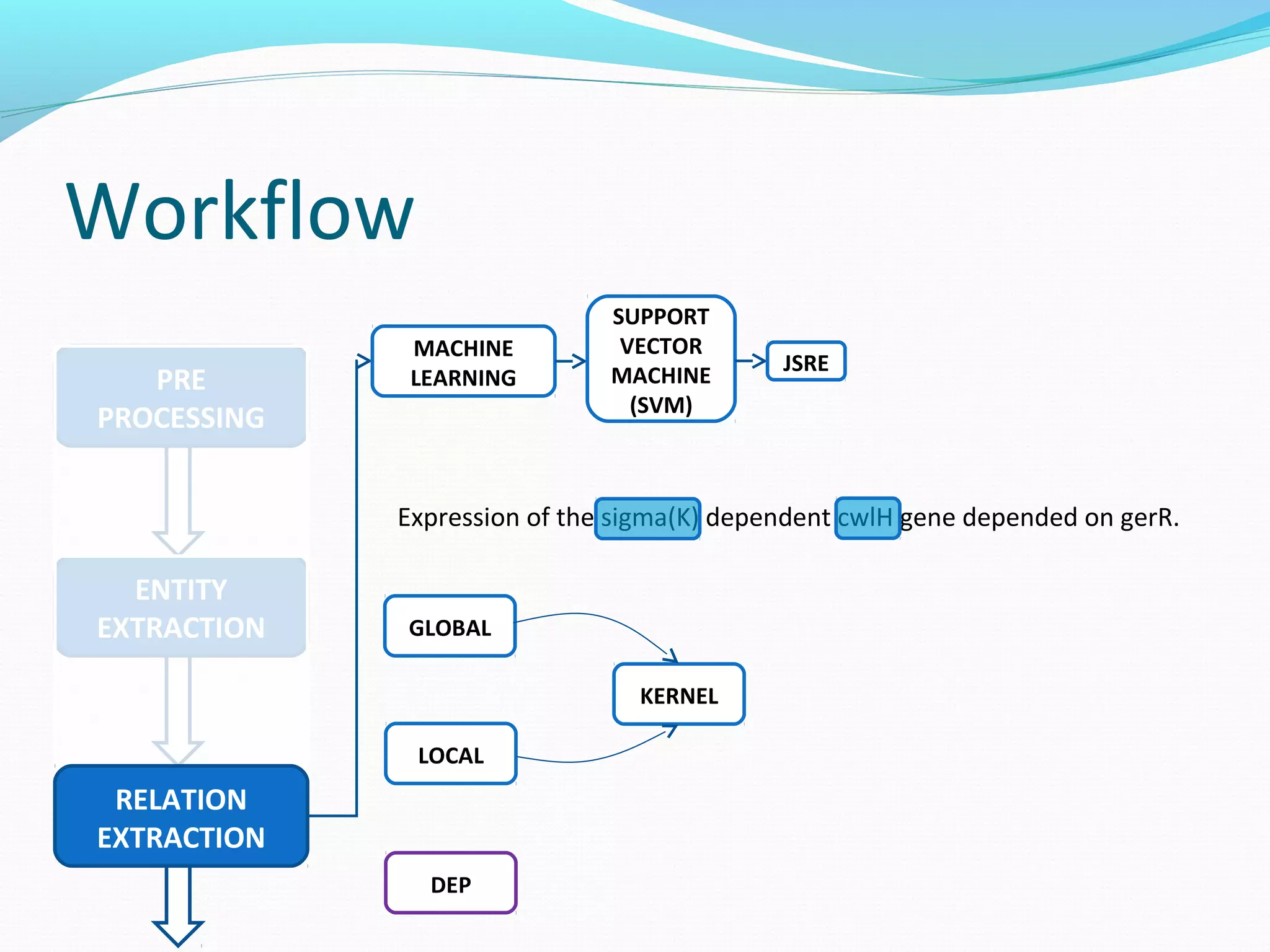
![Workflow
ENTITY
EXTRACTION
PRE
PROCESSING
RELATION
EXTRACTION
MACHINE
LEARNING
SUPPORT
VECTOR
MACHINE
(SVM)
JSRE
Expression of the sigma(K) dependent cwlH gene depended on gerR.
BETWEEN AFTERFORE [1] [2]
GLOBAL](https://image.slidesharecdn.com/groupmeeting2012121-141009084418-conversion-gate02/75/Relation-Extraction-53-2048.jpg)
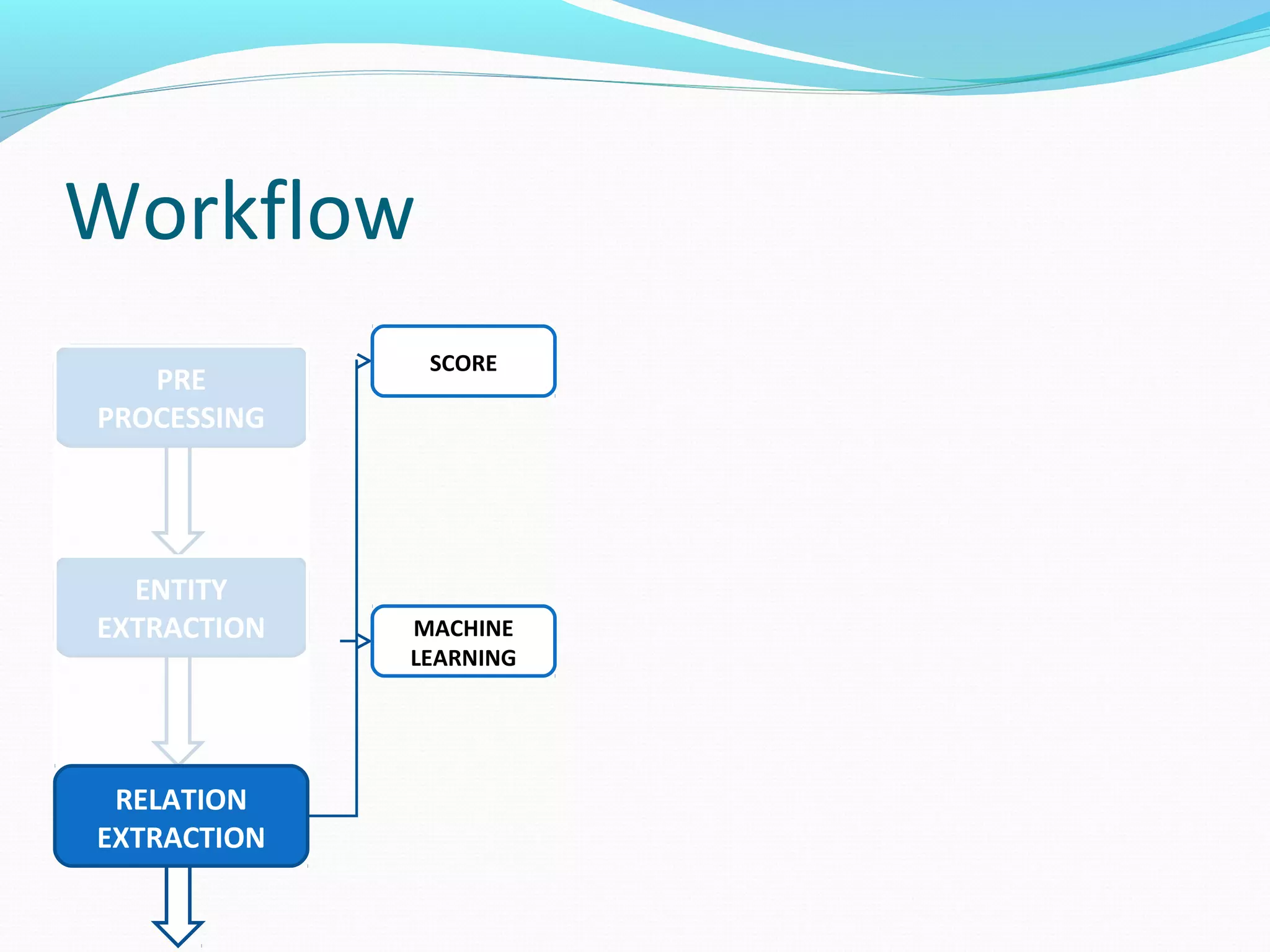
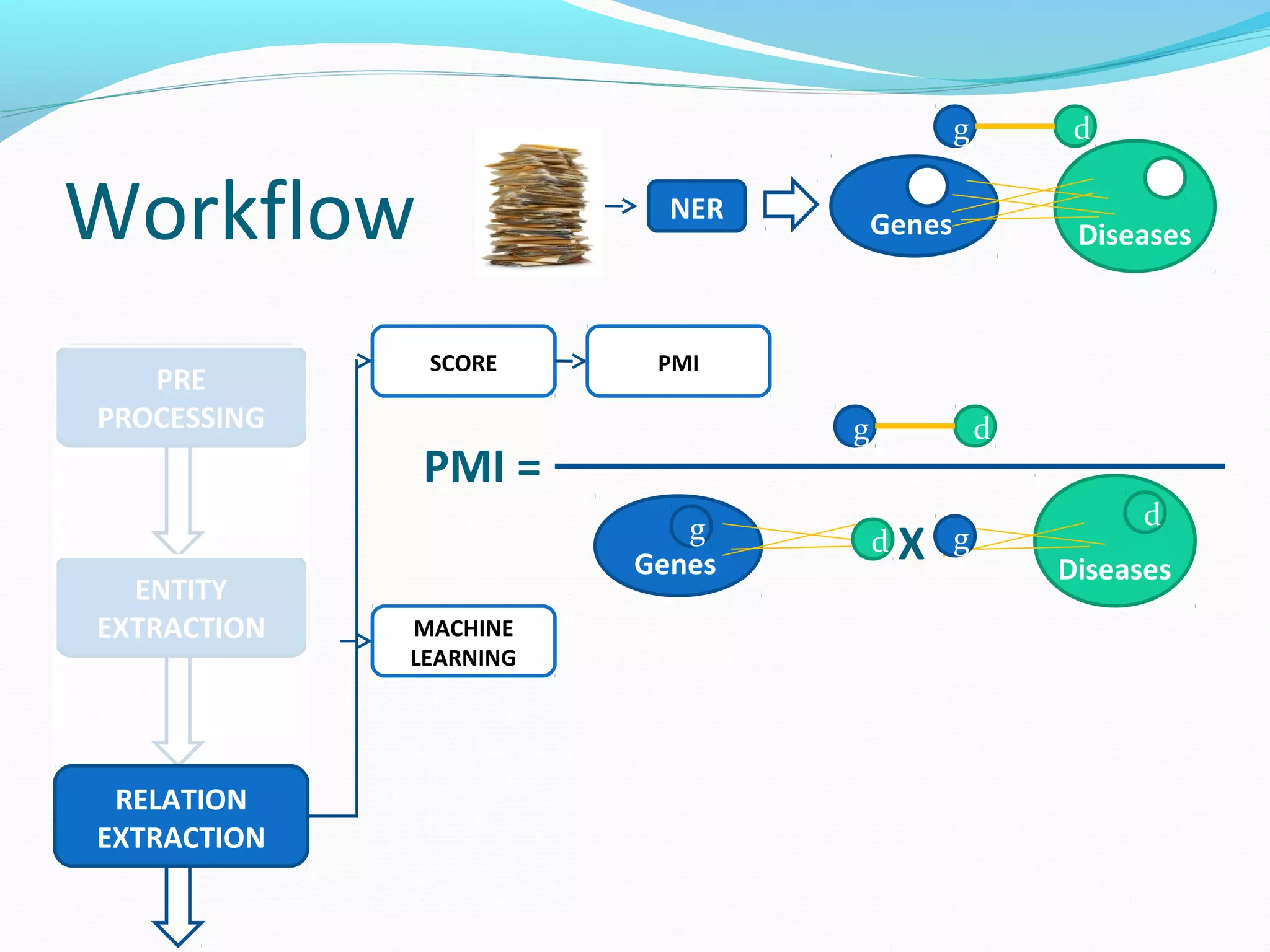
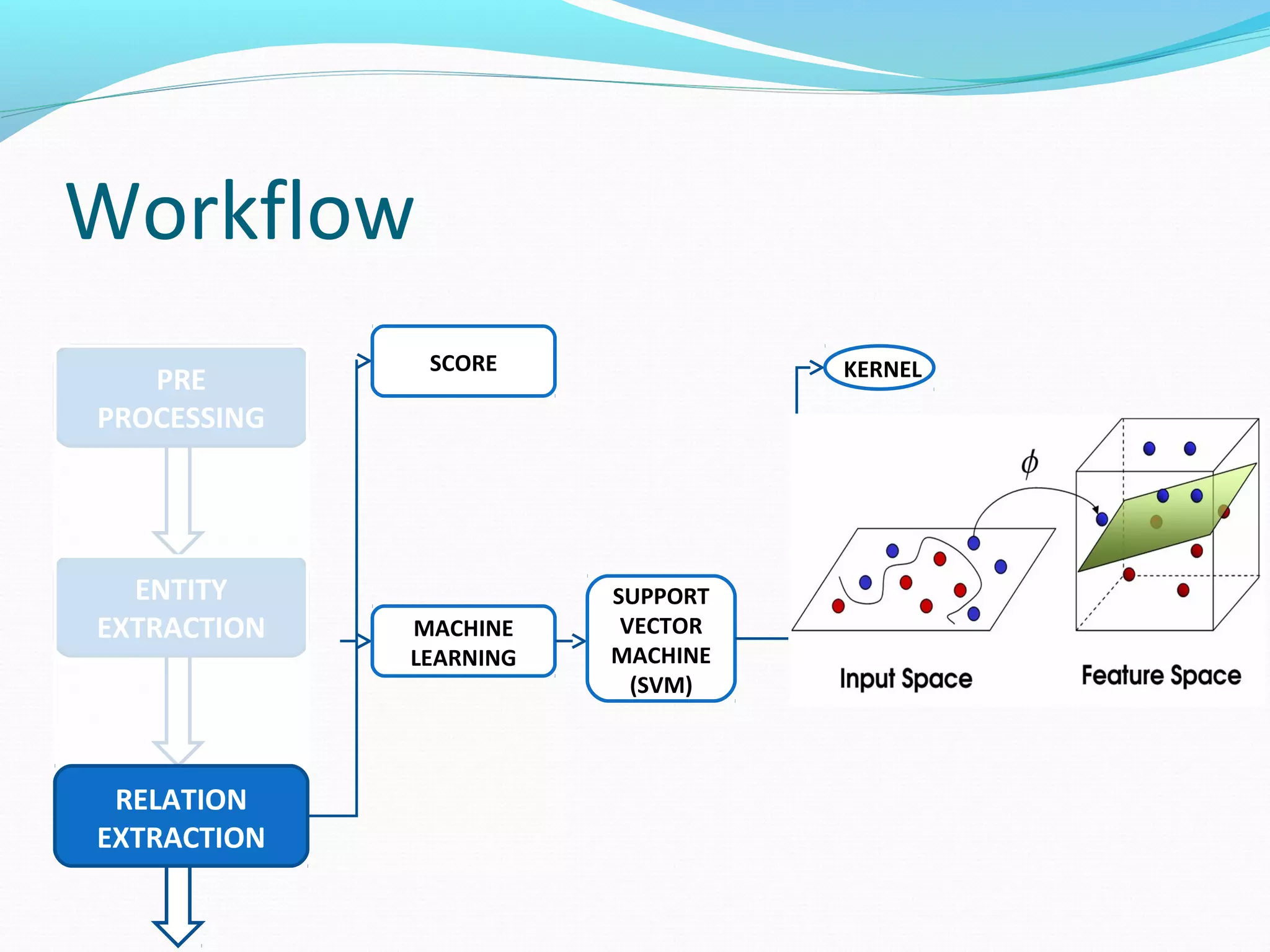
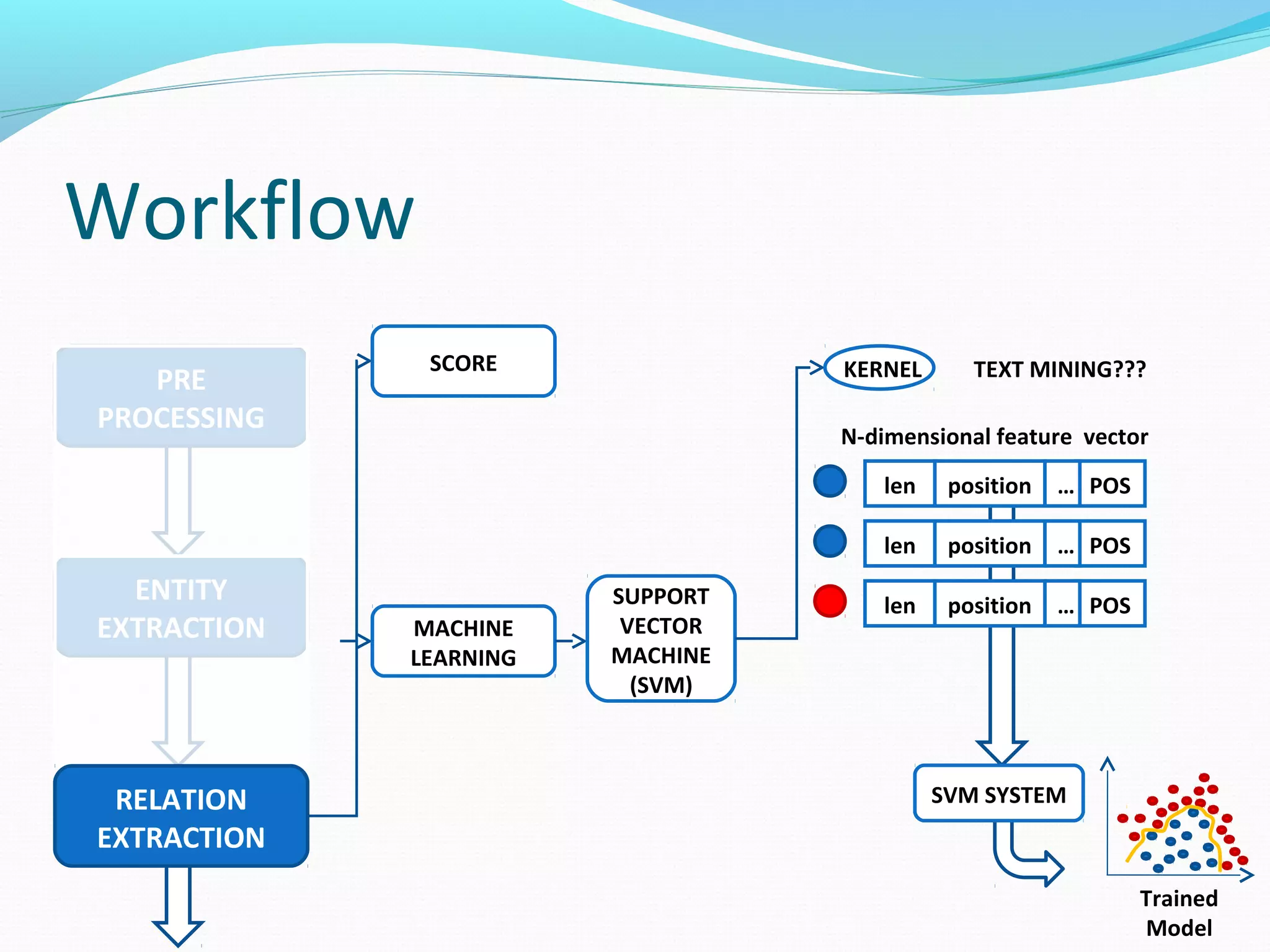
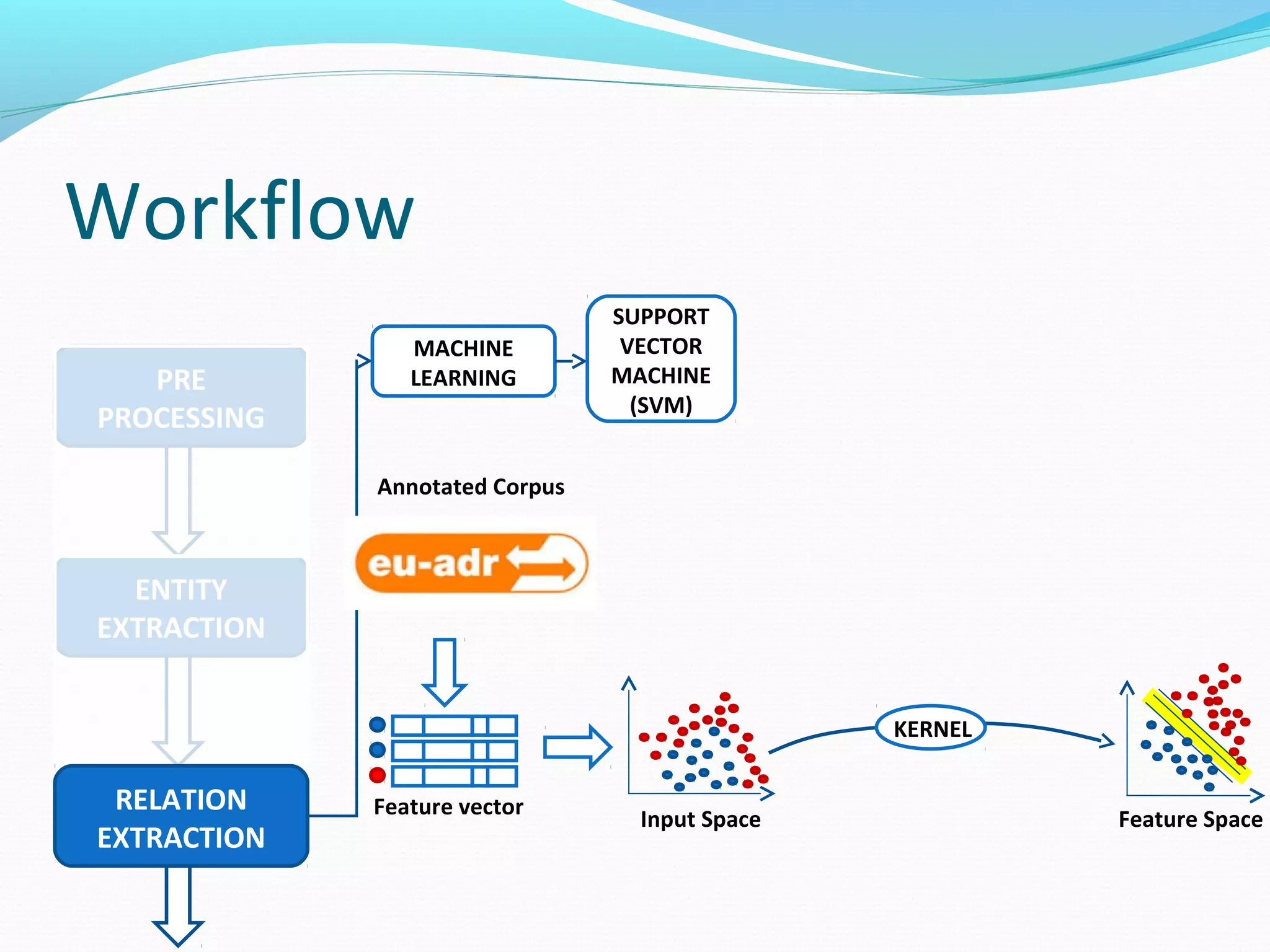
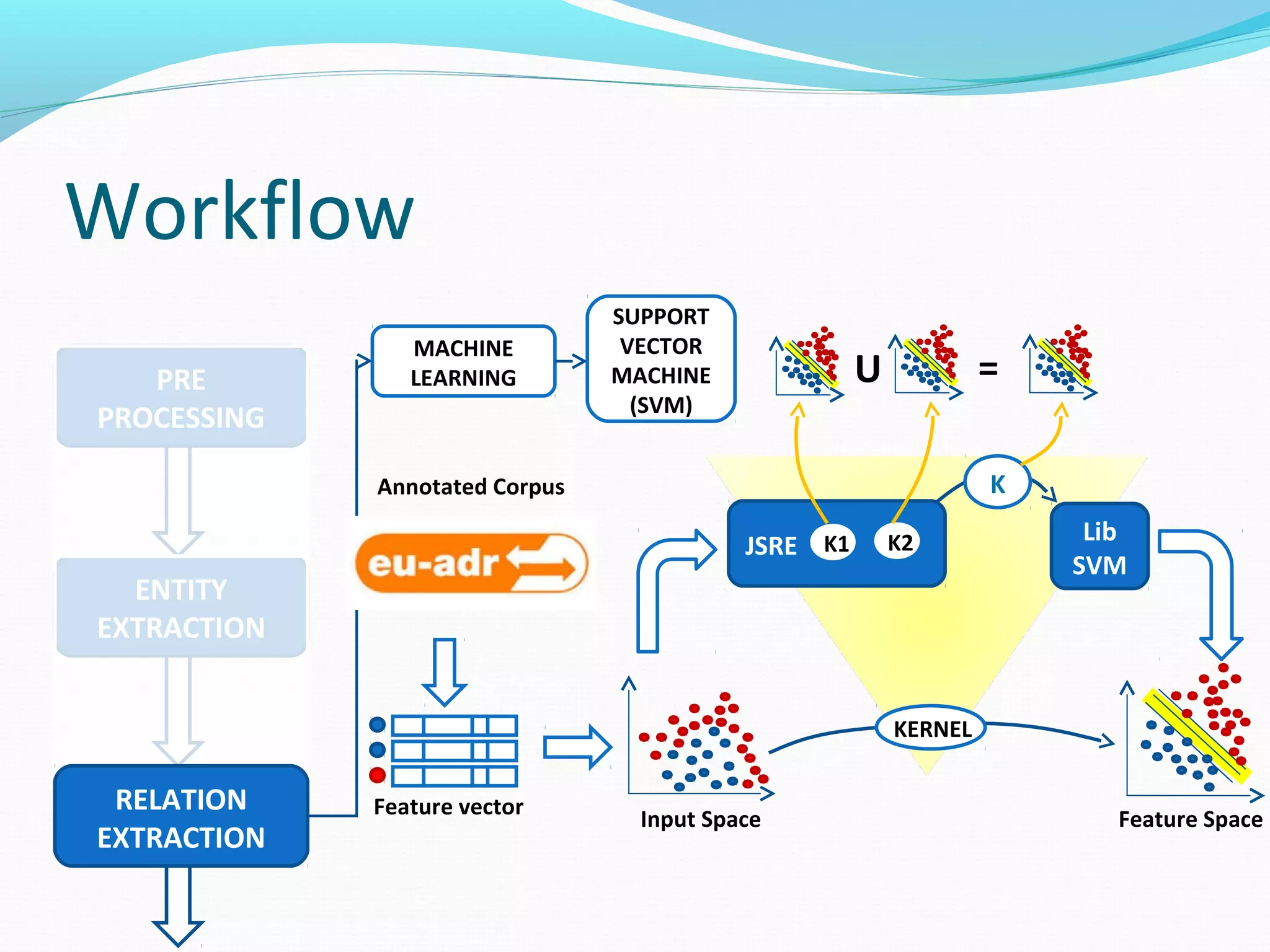
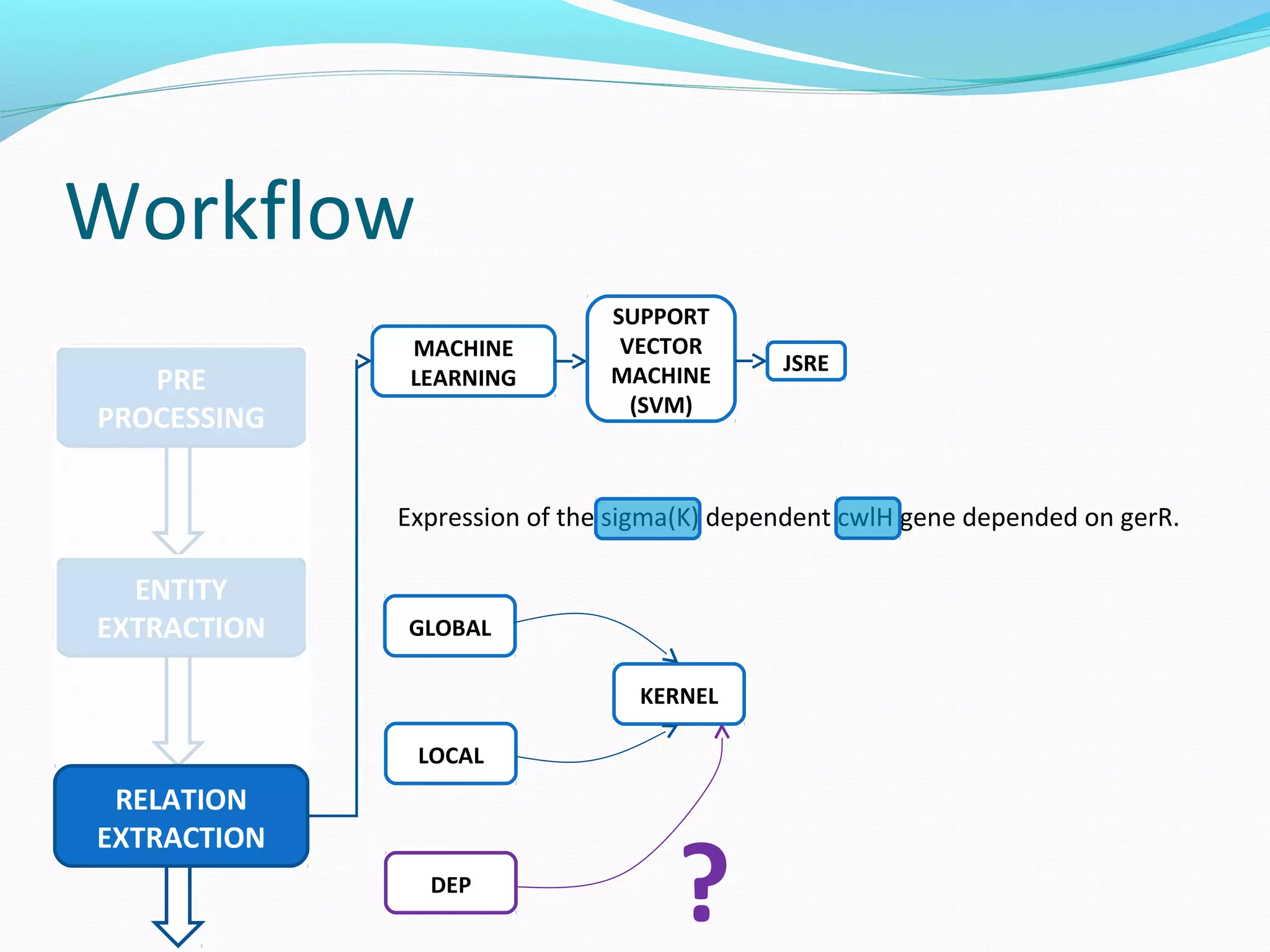
![Workflow
ENTITY
EXTRACTION
PRE
PROCESSING
RELATION
EXTRACTION
MACHINE
LEARNING
SUPPORT
VECTOR
MACHINE
(SVM)
JSRE
Expression of the sigma(K) dependent cwlH gene depended on gerR.
BETWEEN AFTERFORE [1] [2]
GLOBAL](https://image.slidesharecdn.com/groupmeeting2012121-141009084418-conversion-gate02/75/Relation-Extraction-54-2048.jpg)
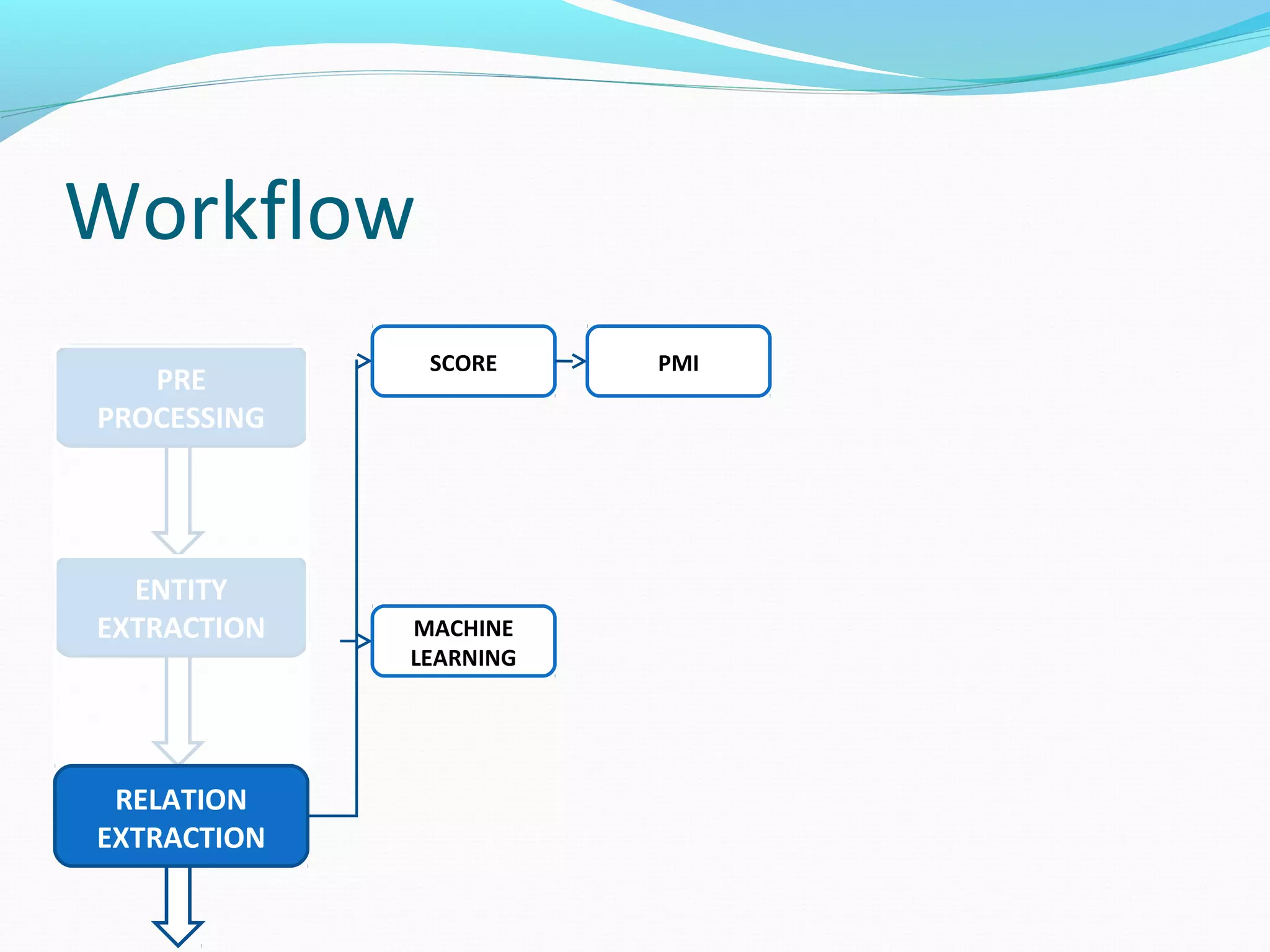
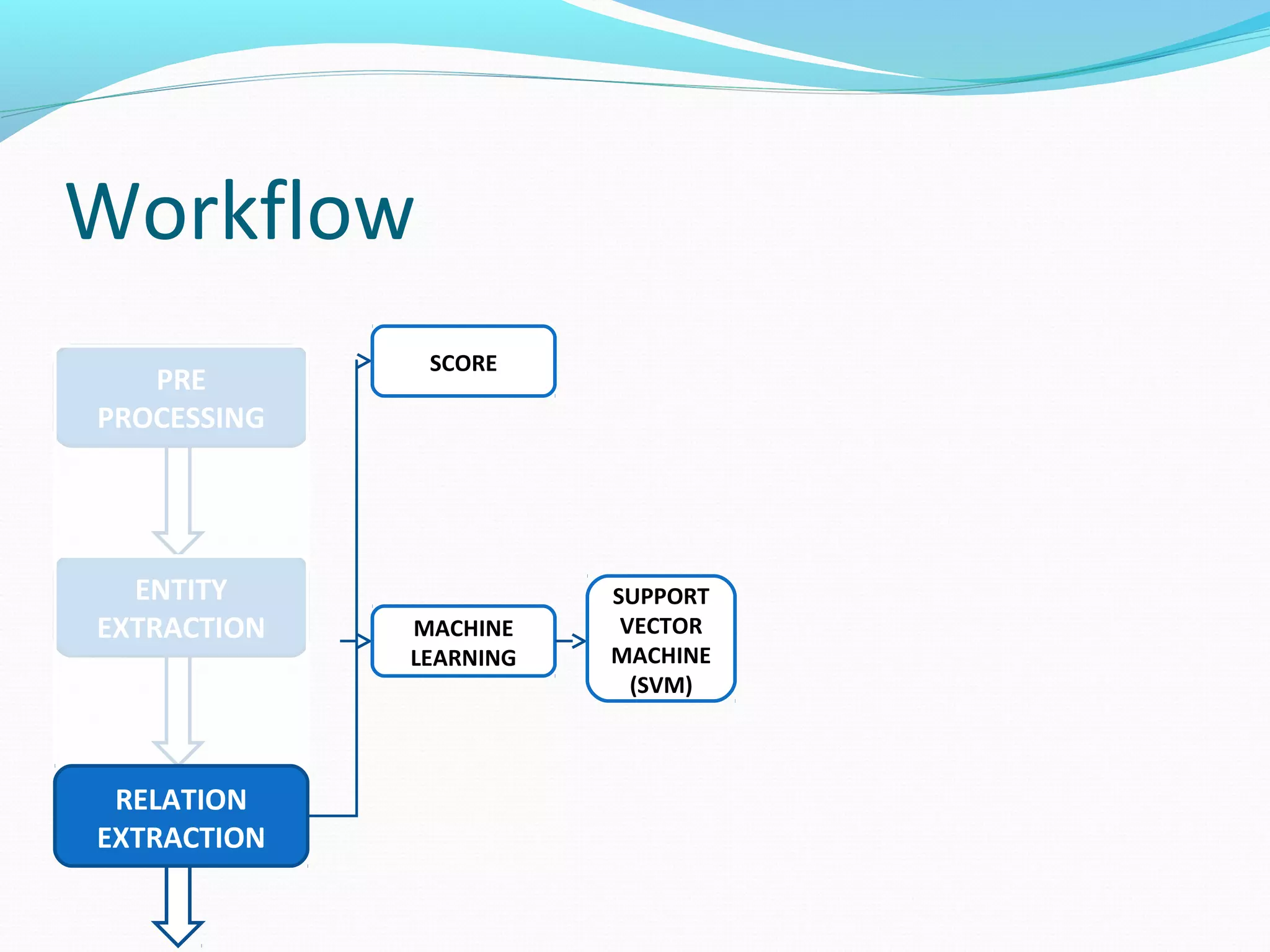
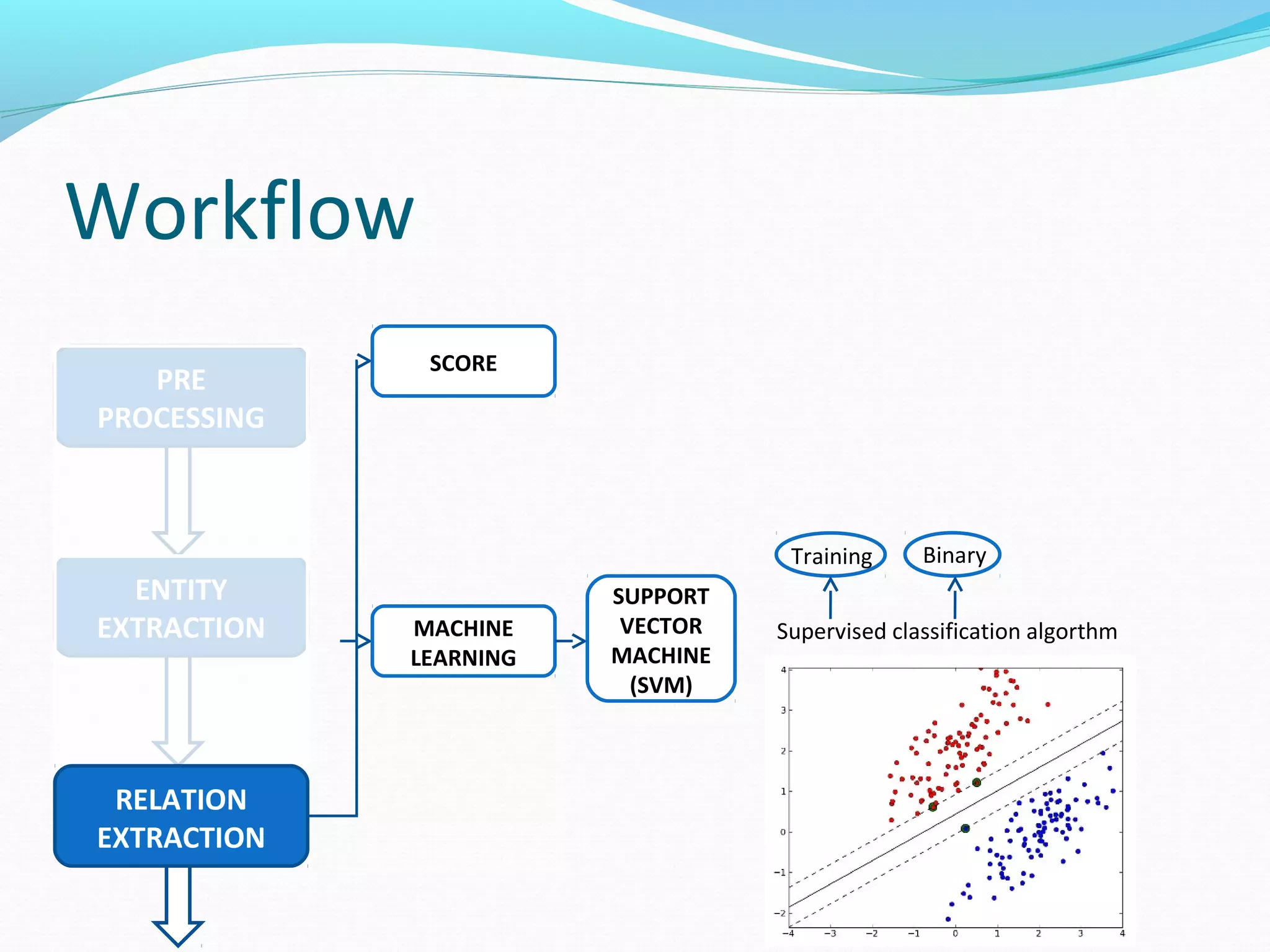
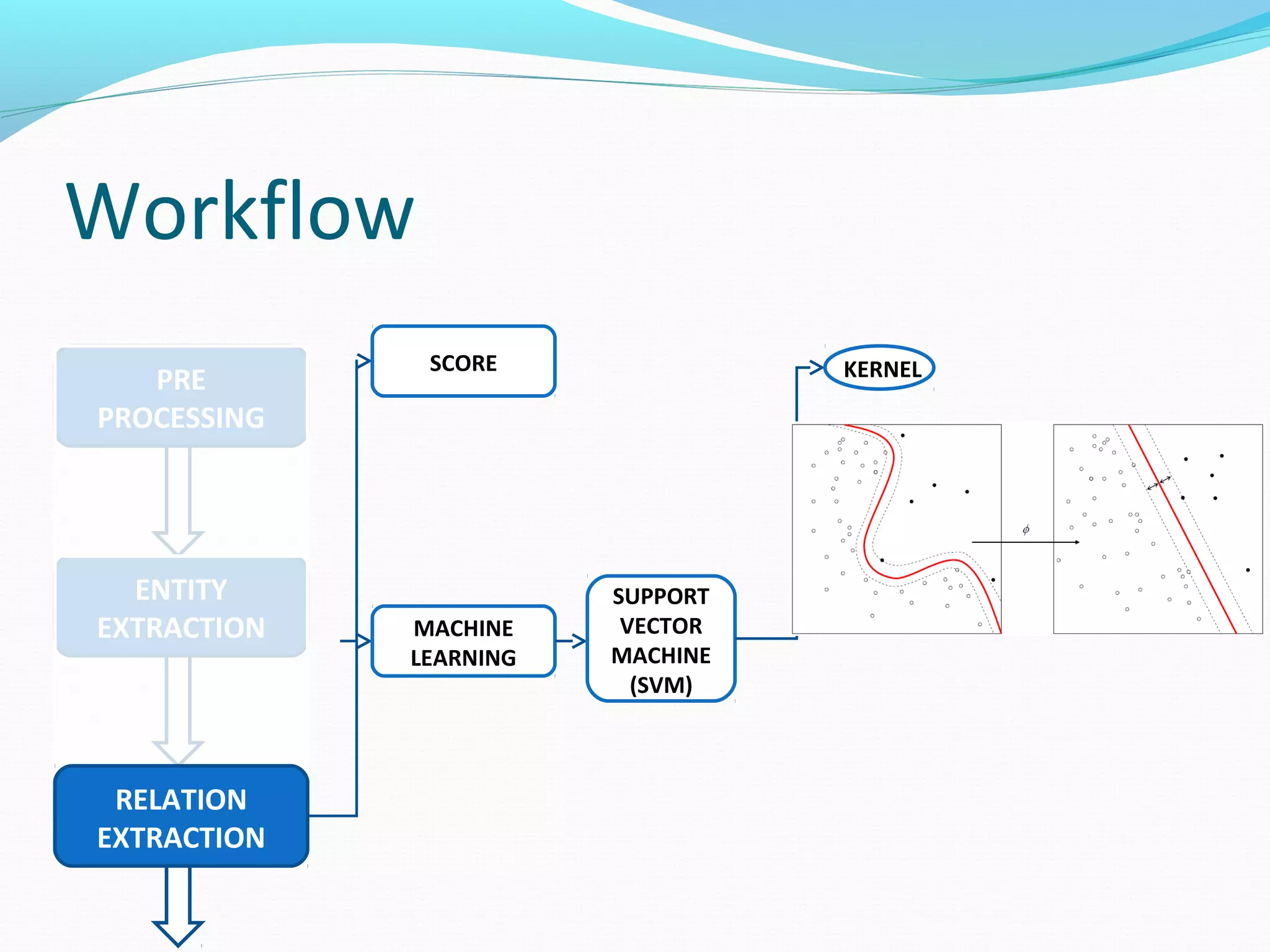
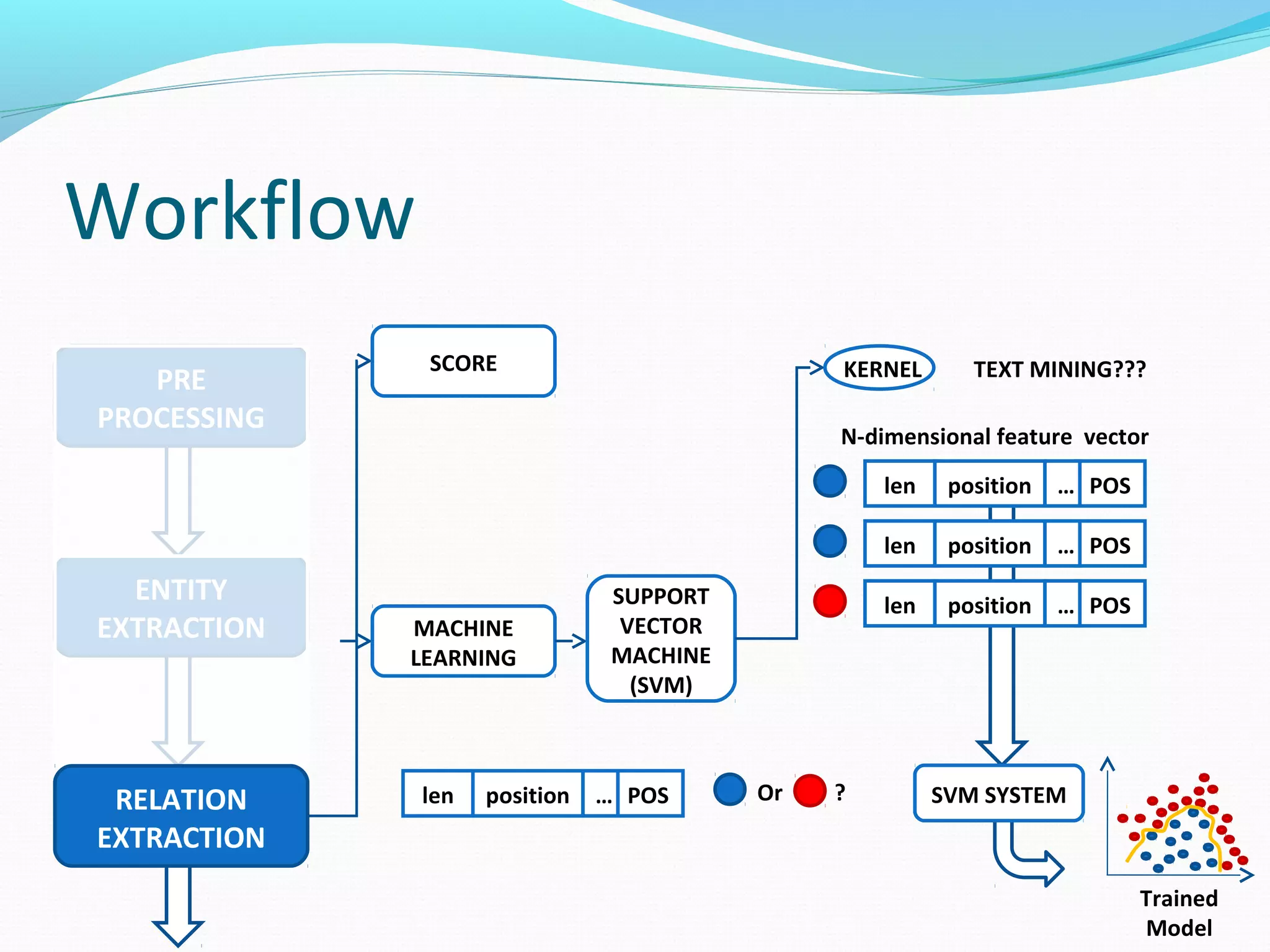
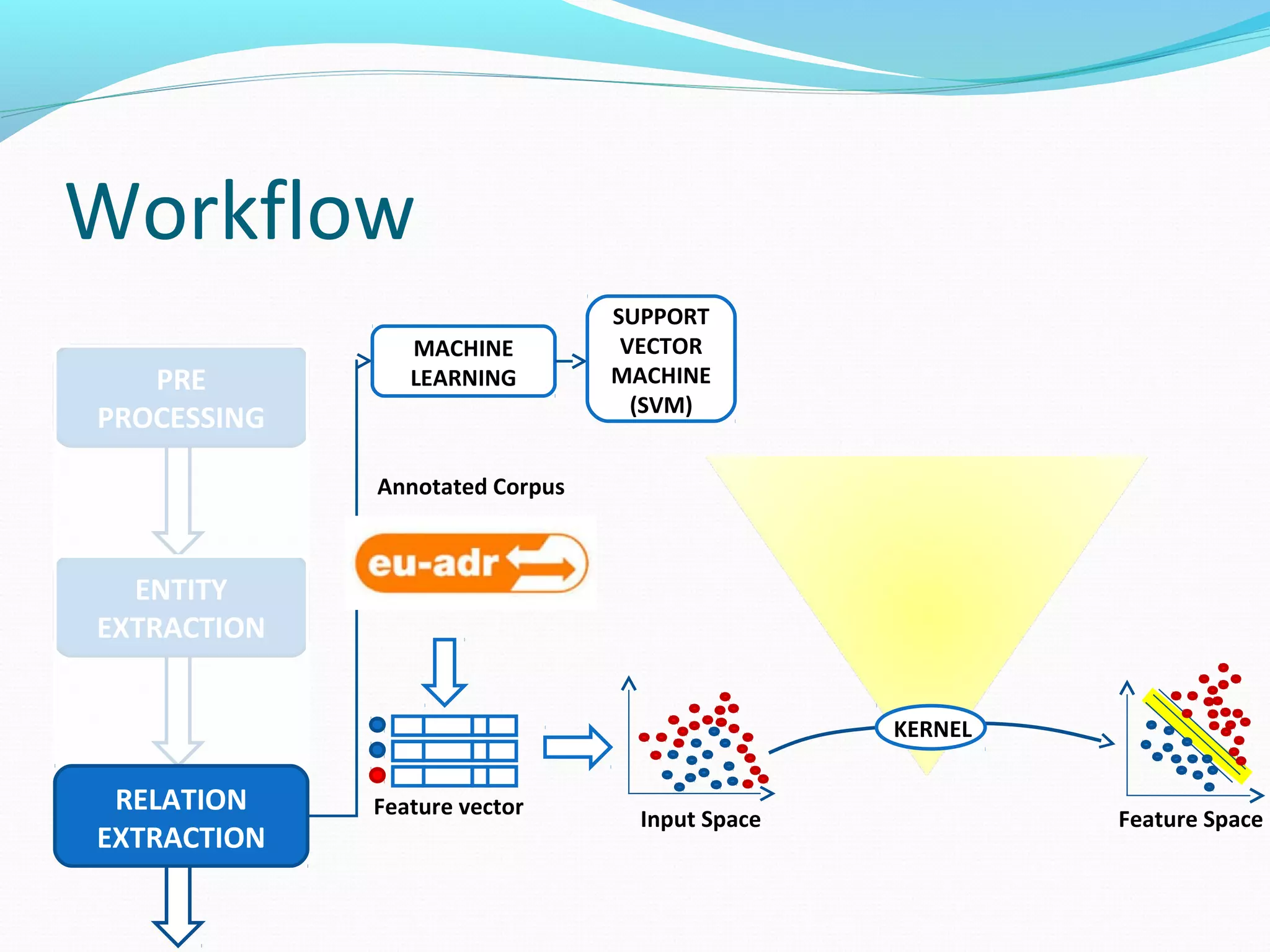
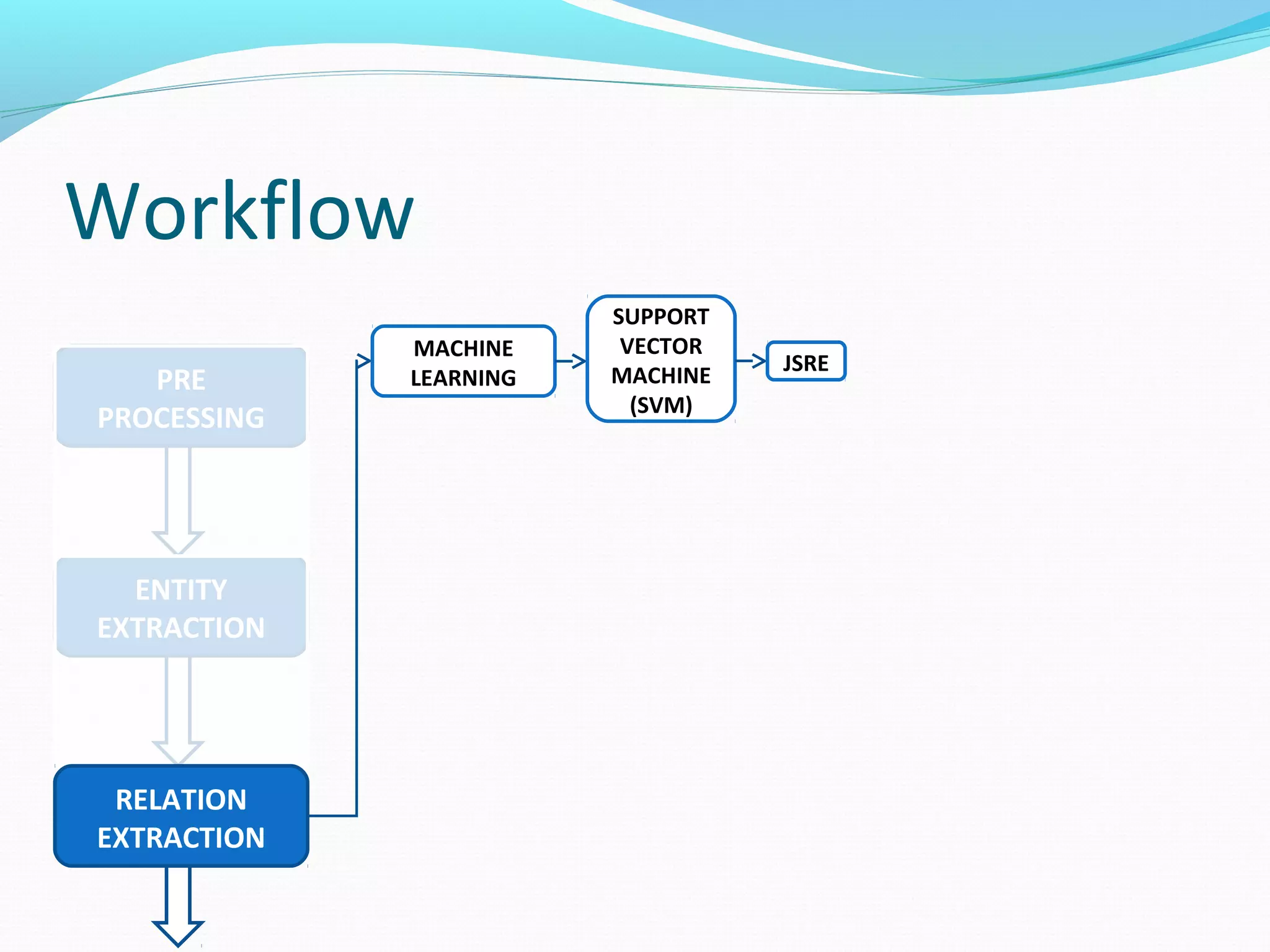
![Workflow
ENTITY
EXTRACTION
PRE
PROCESSING
RELATION
EXTRACTION
MACHINE
LEARNING
SUPPORT
VECTOR
MACHINE
(SVM)
JSRE
Expression of the sigma(K) dependent cwlH gene depended on gerR.
BETWEEN AFTERFORE [1] [2]
GLOBAL](https://image.slidesharecdn.com/groupmeeting2012121-141009084418-conversion-gate02/75/Relation-Extraction-55-2048.jpg)
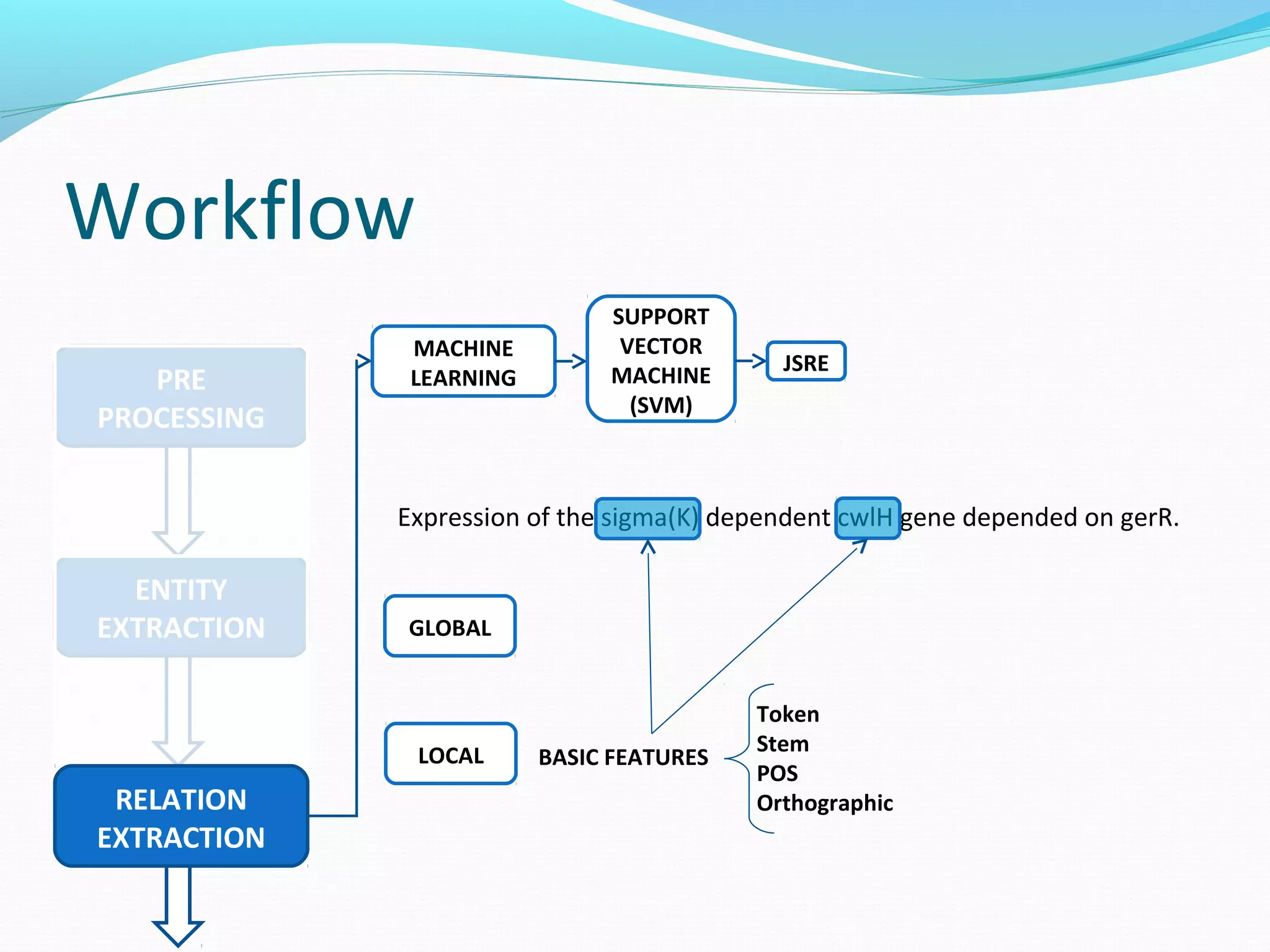
![Workflow
ENTITY
EXTRACTION
PRE
PROCESSING
RELATION
EXTRACTION
MACHINE
LEARNING
SUPPORT
VECTOR
MACHINE
(SVM)
JSRE
Expression of the sigma(K) dependent cwlH gene depended on gerR.
GLOBAL
BETWEEN AFTERFORE [1] [2]
FEATURES 3-GRAM
Expression_of_the
of_the_sigma(k)
the_sigma(k)_dependent
sigma(k)_dependent_cwlH dependent_cwlH_gene
cwlJ_gene_depended
gene_depended_on
depended_on_gerB
FORE-BETWEEN BETWEEN BETWEEN-AFTER](https://image.slidesharecdn.com/groupmeeting2012121-141009084418-conversion-gate02/75/Relation-Extraction-56-2048.jpg)

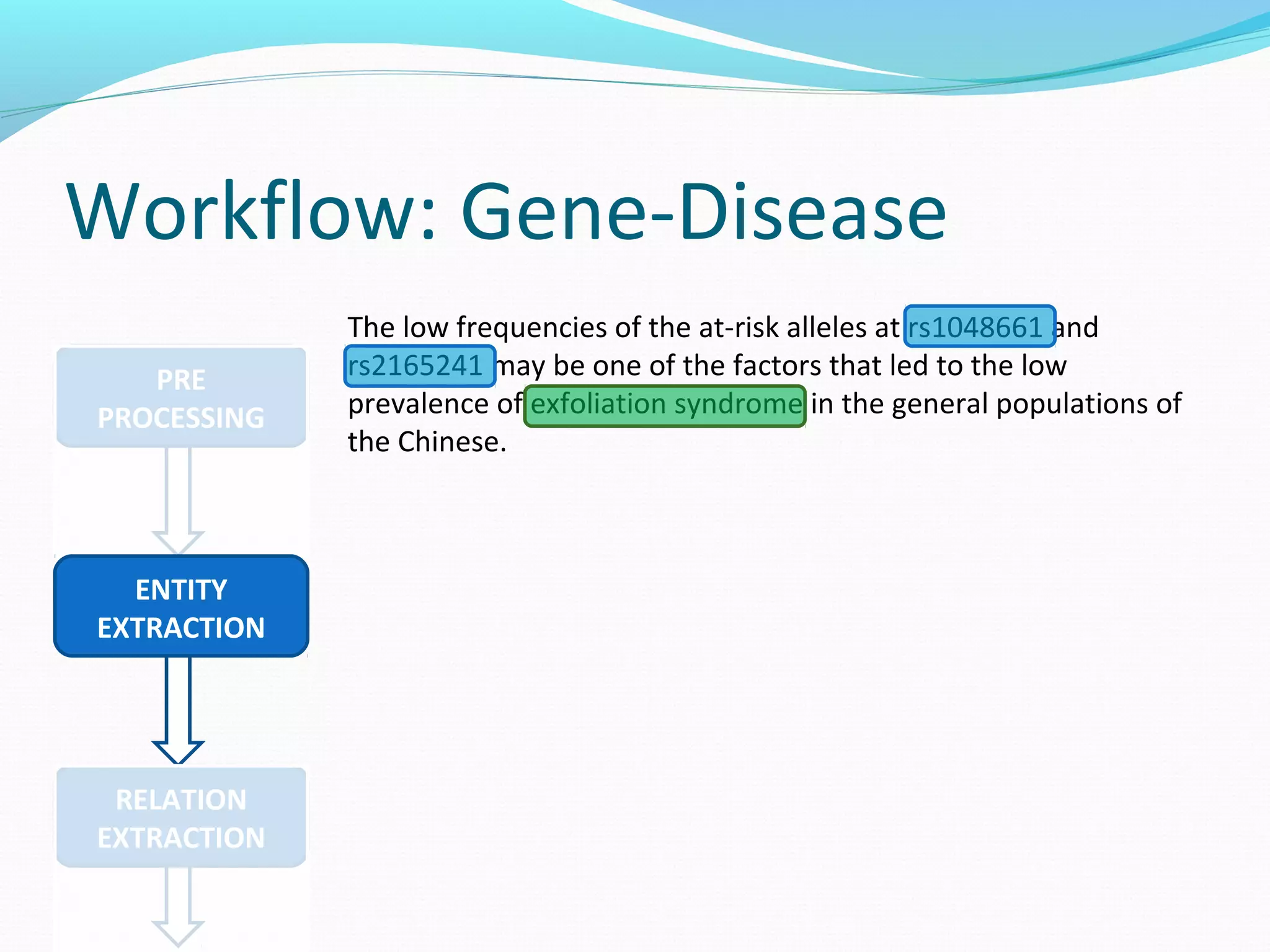
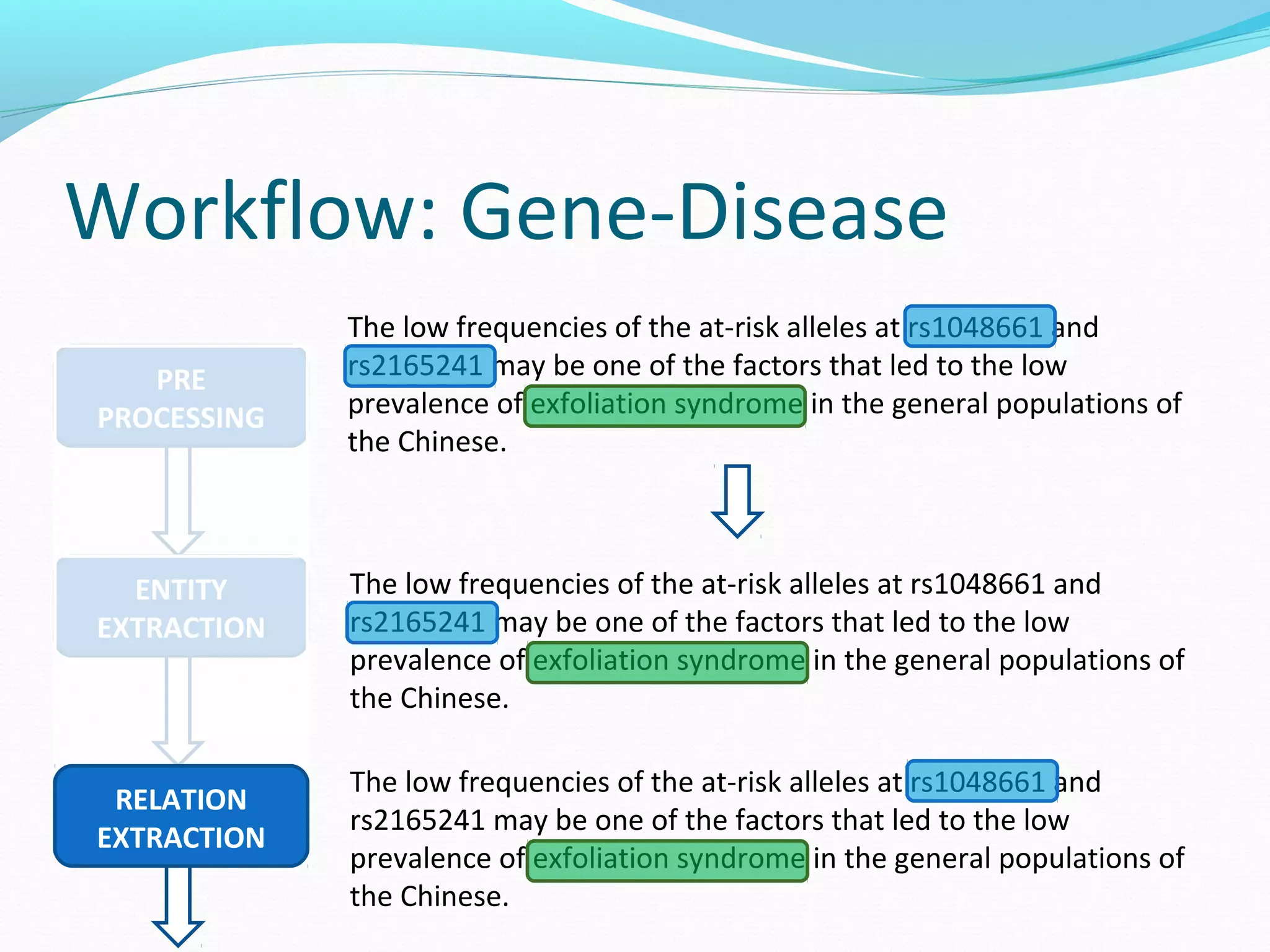

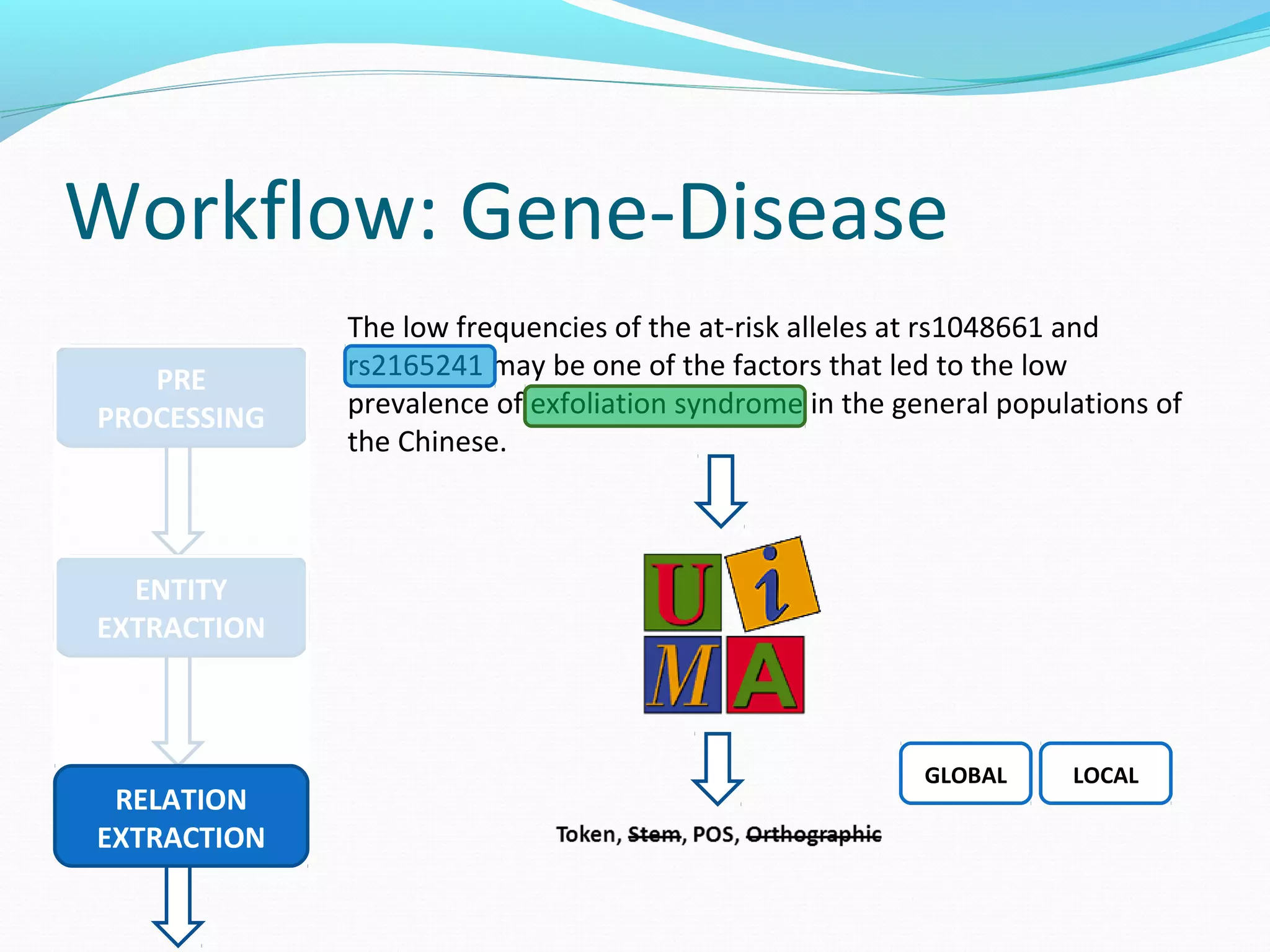
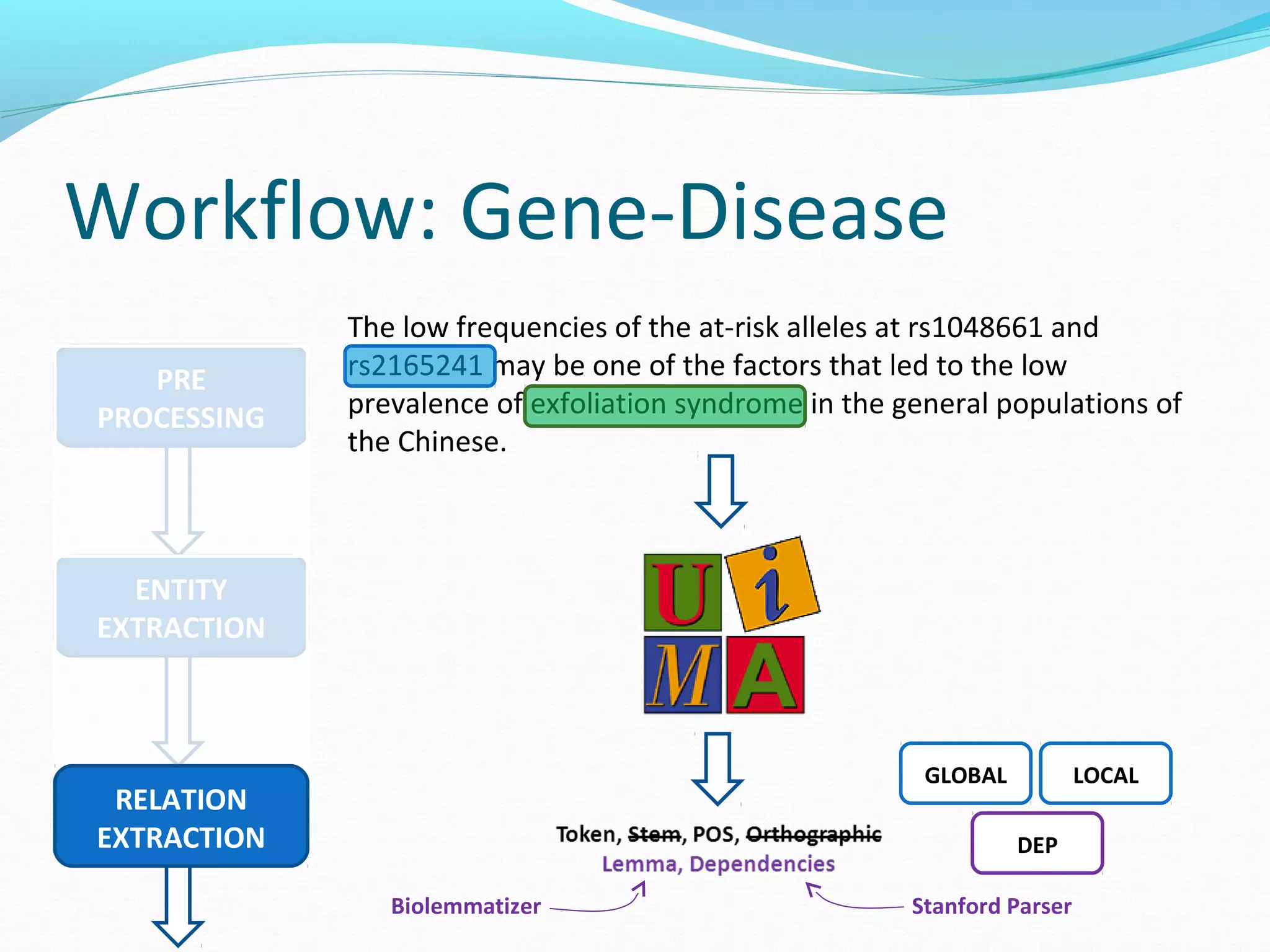
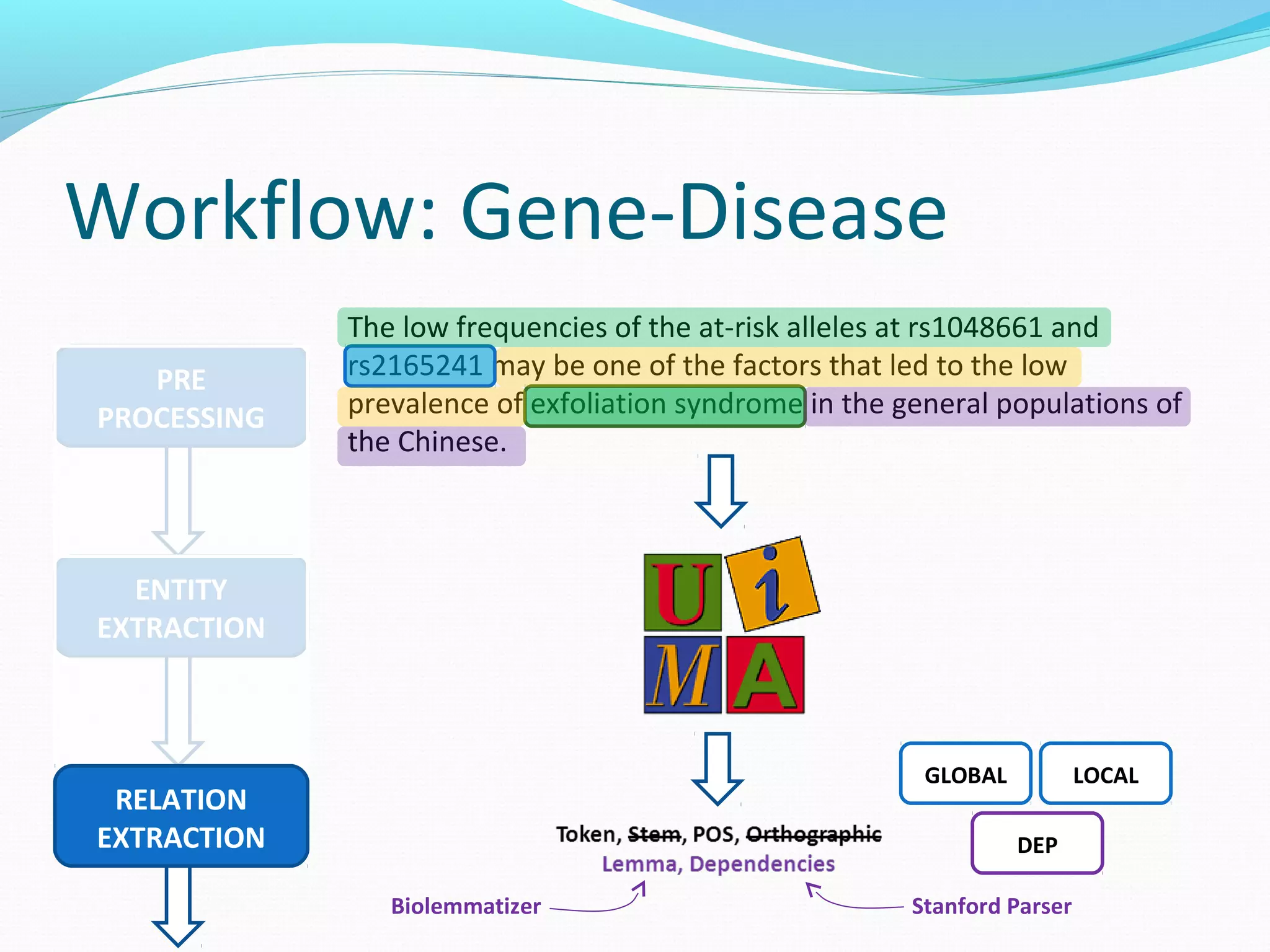
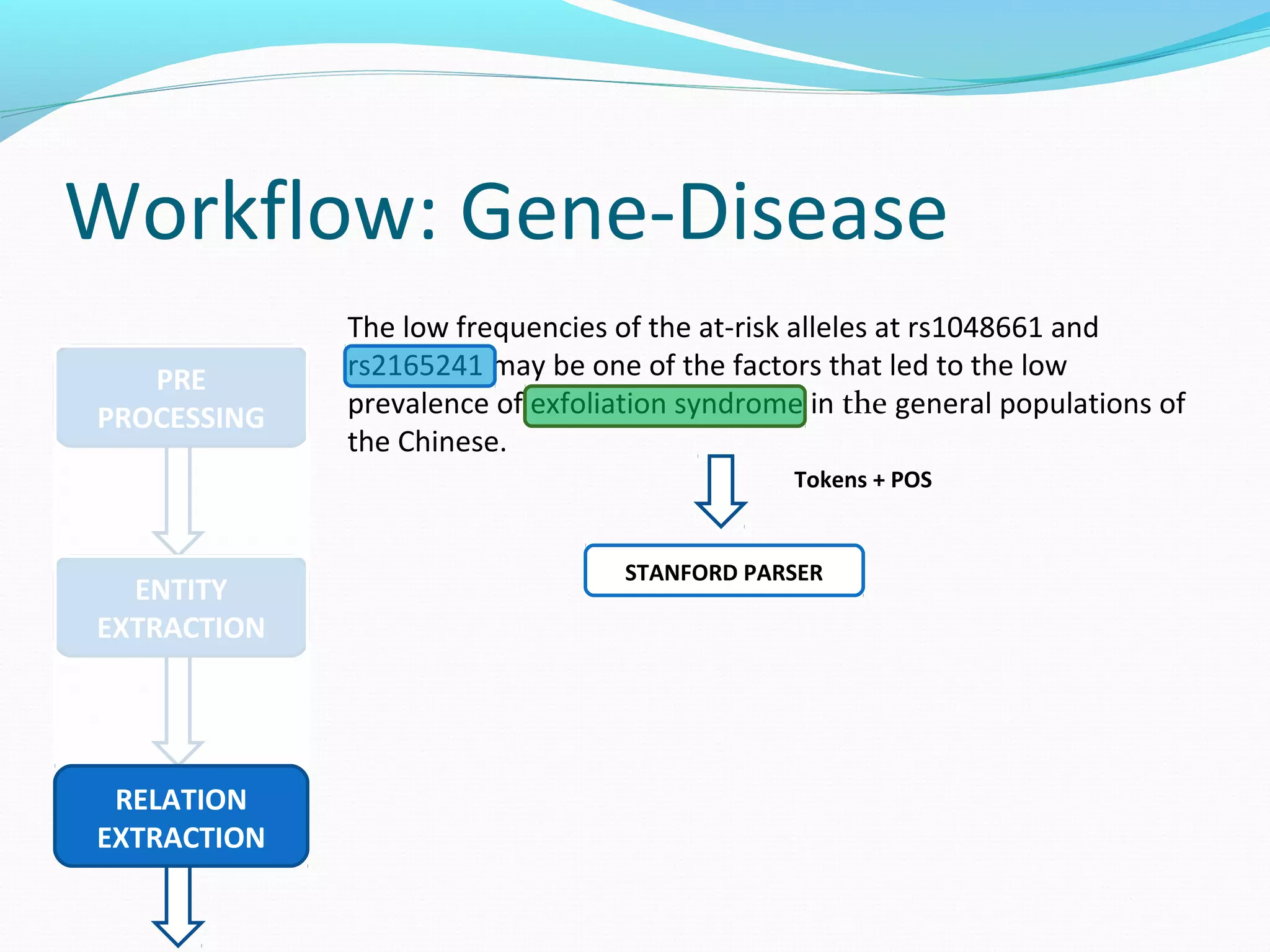
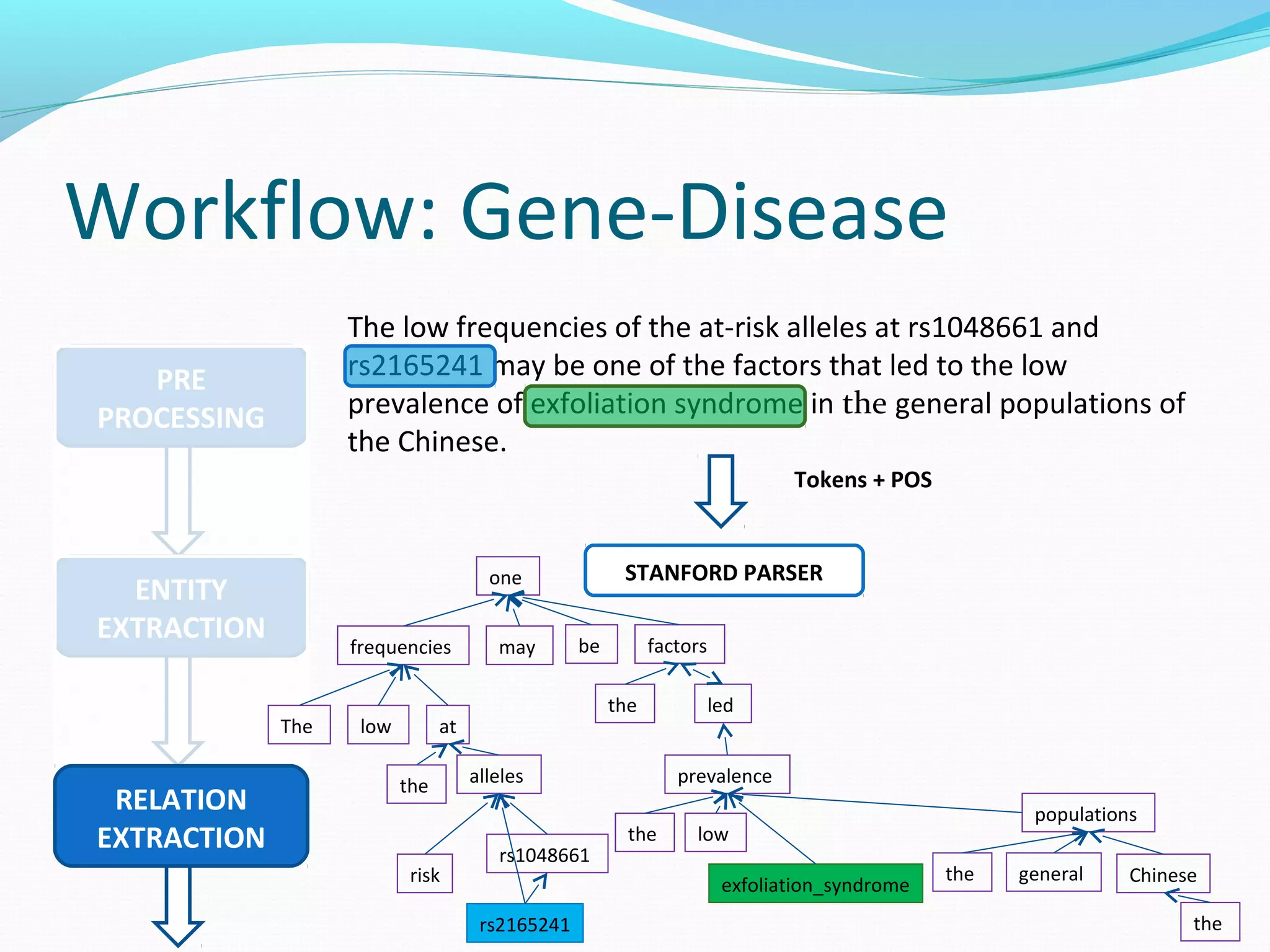
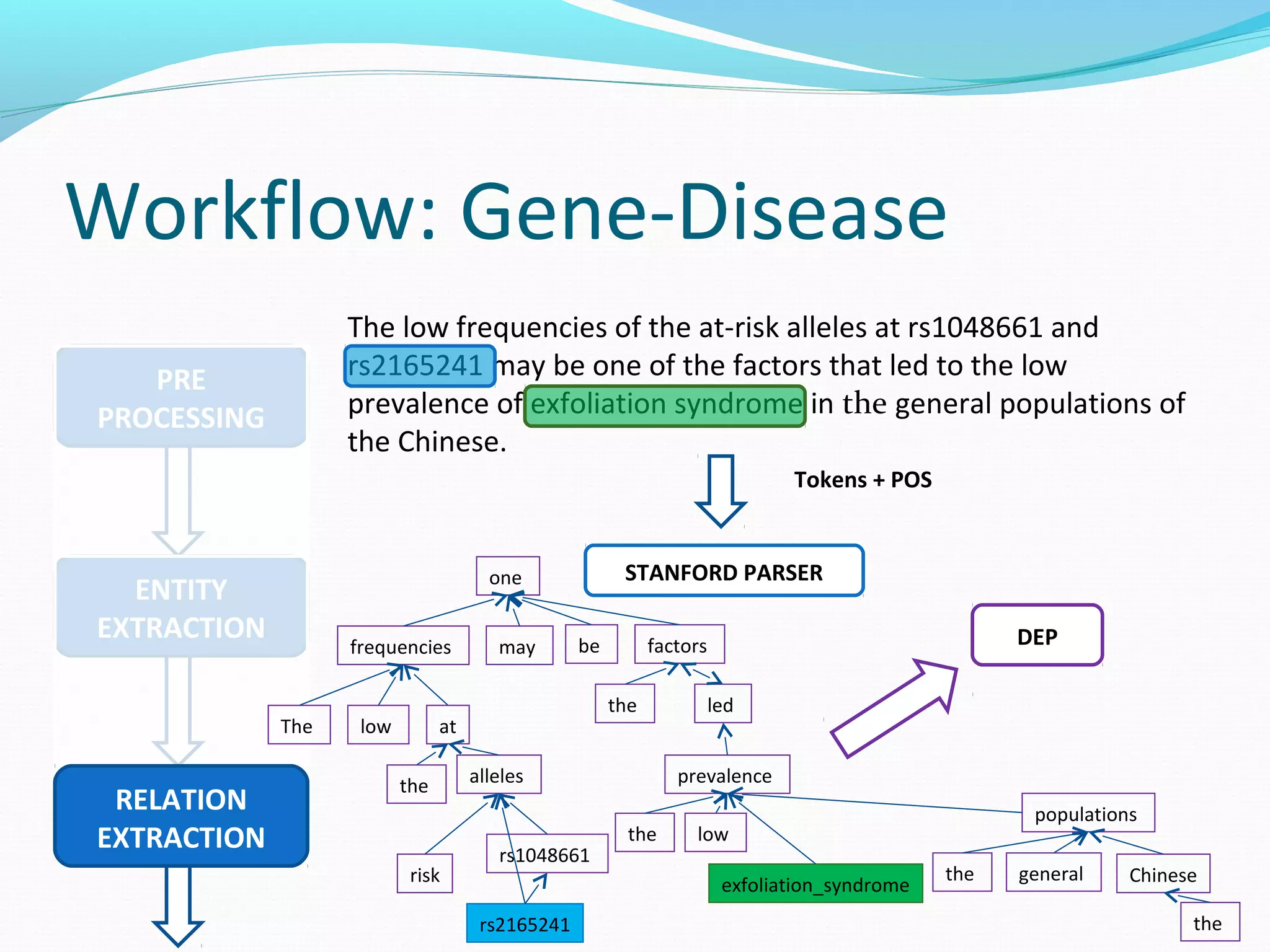
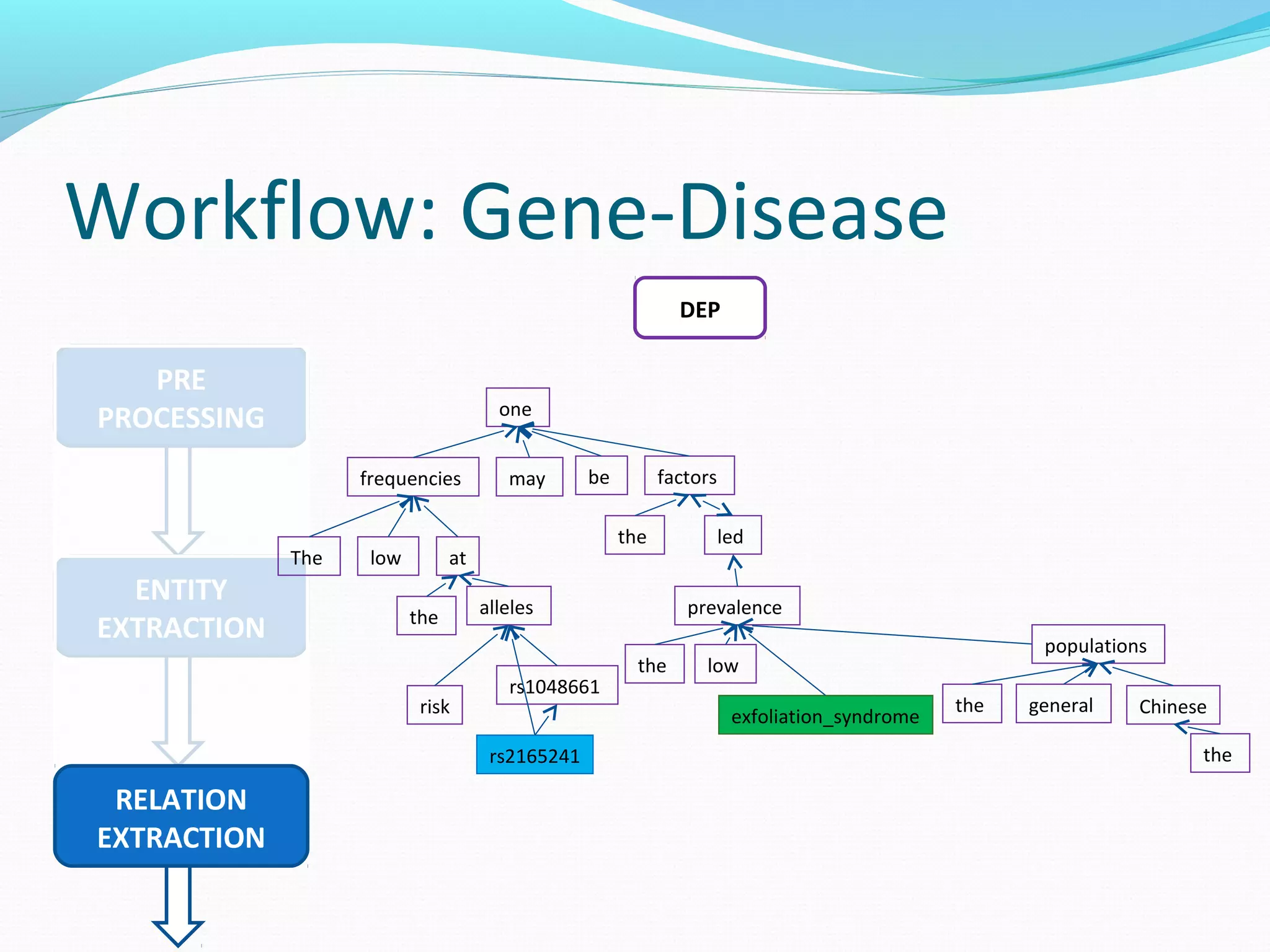
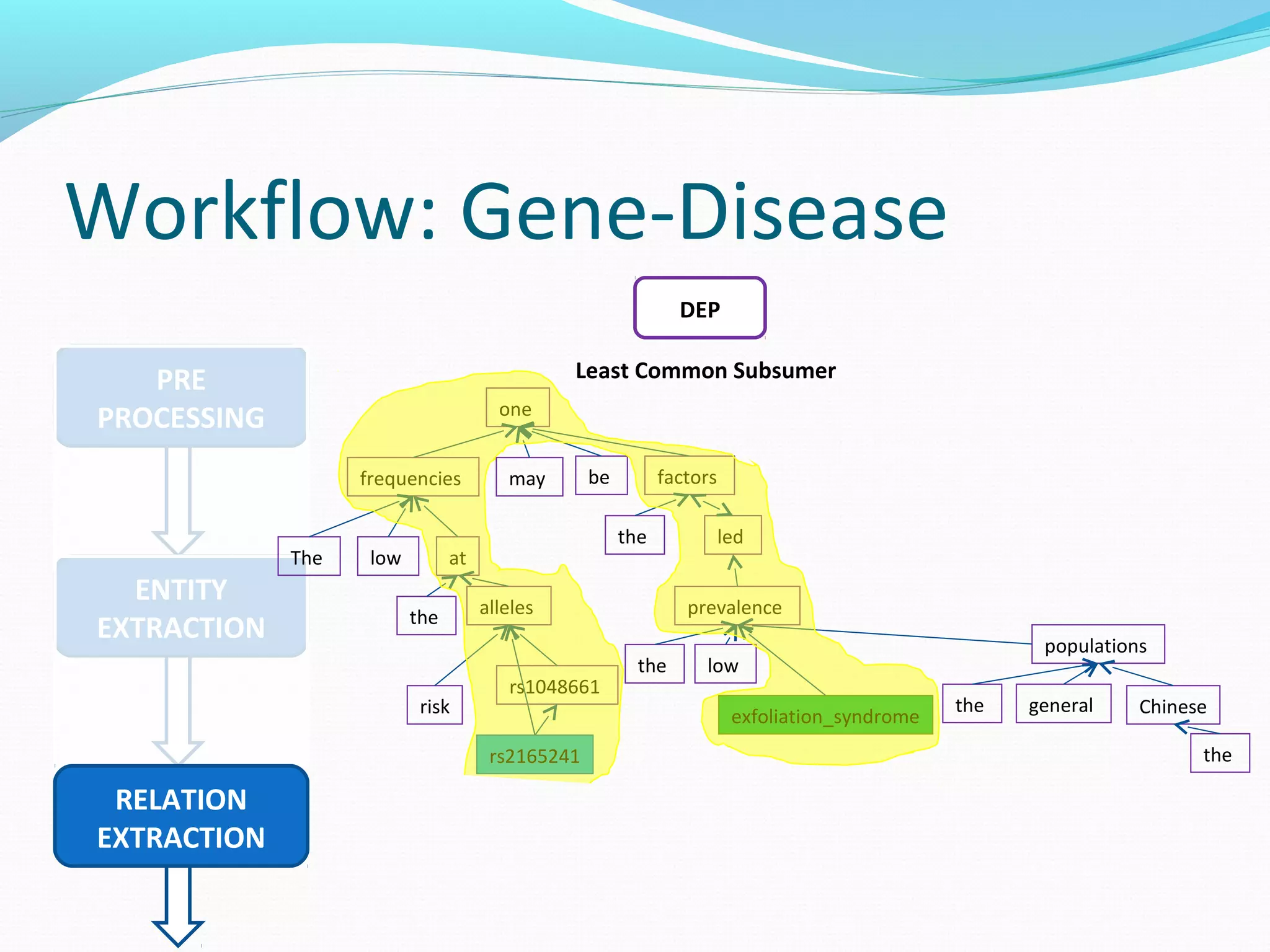
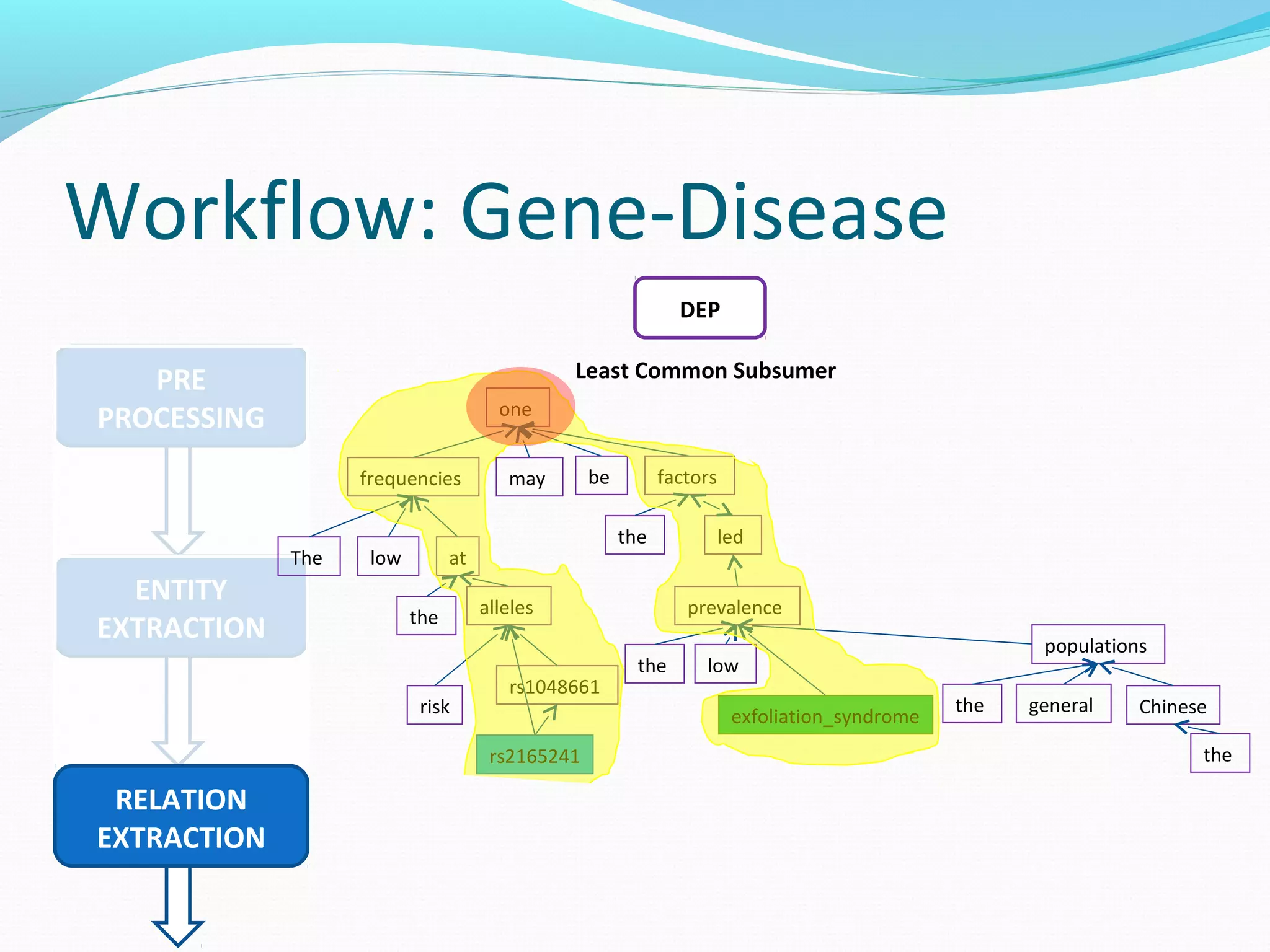
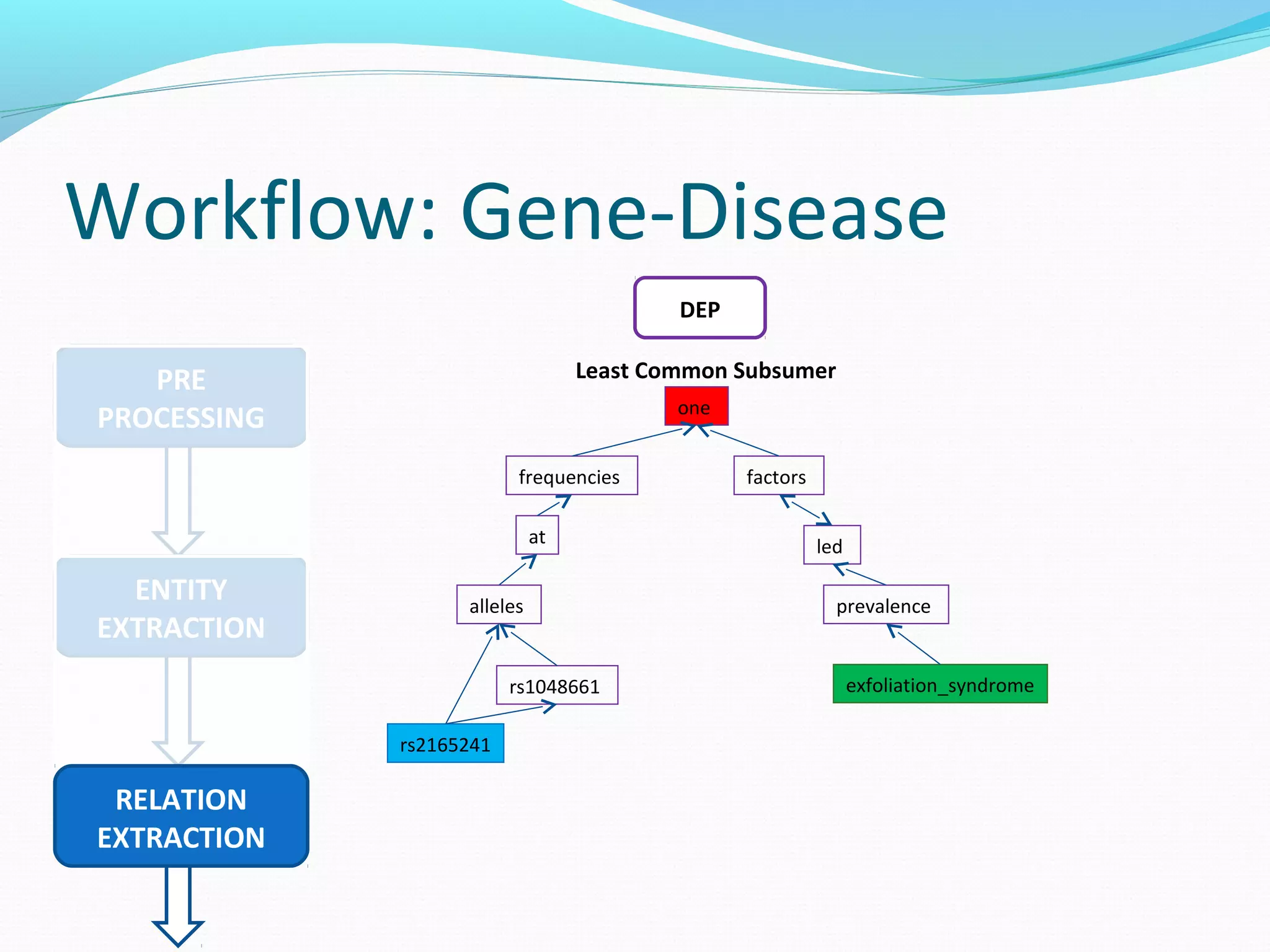
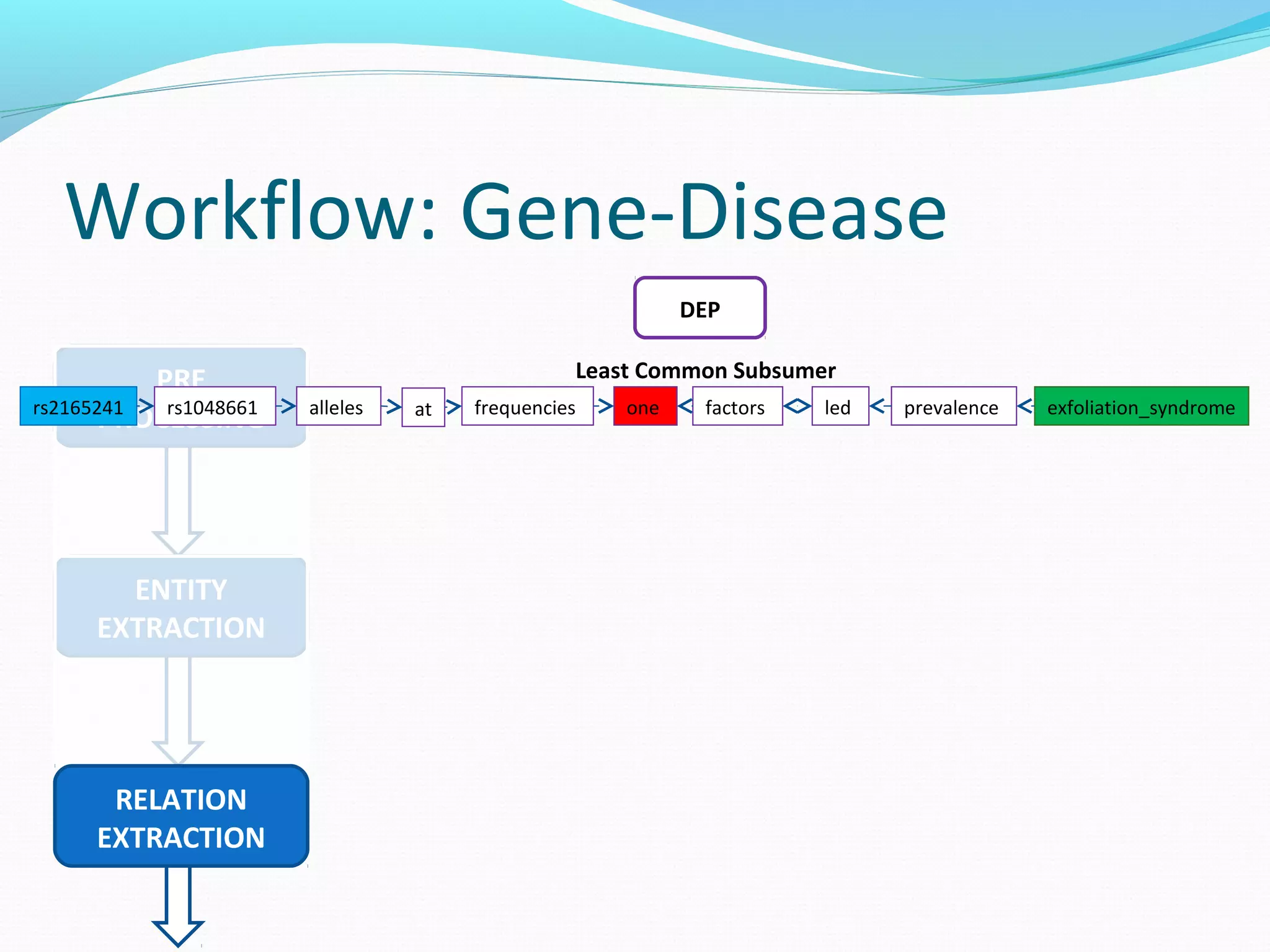
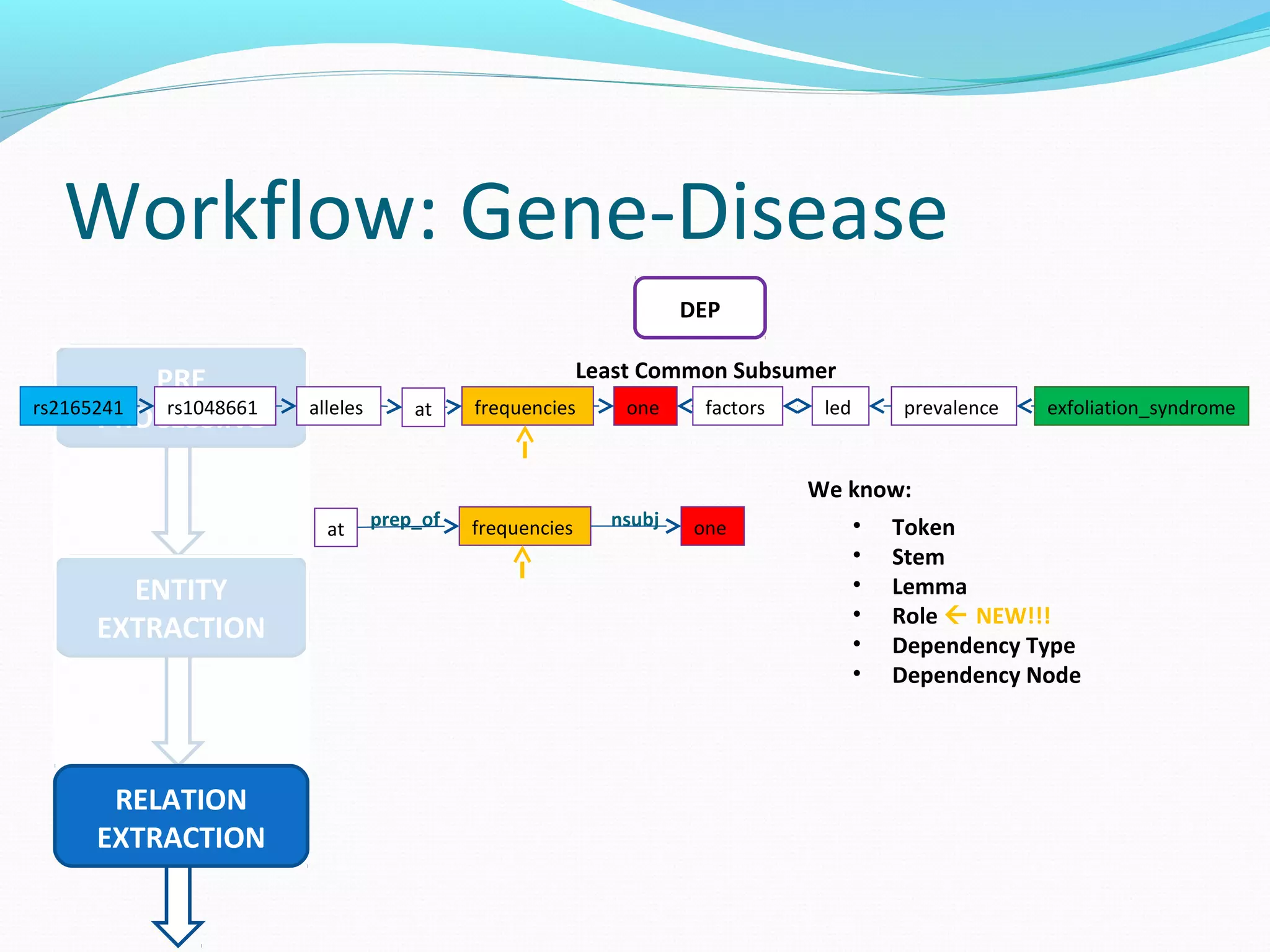
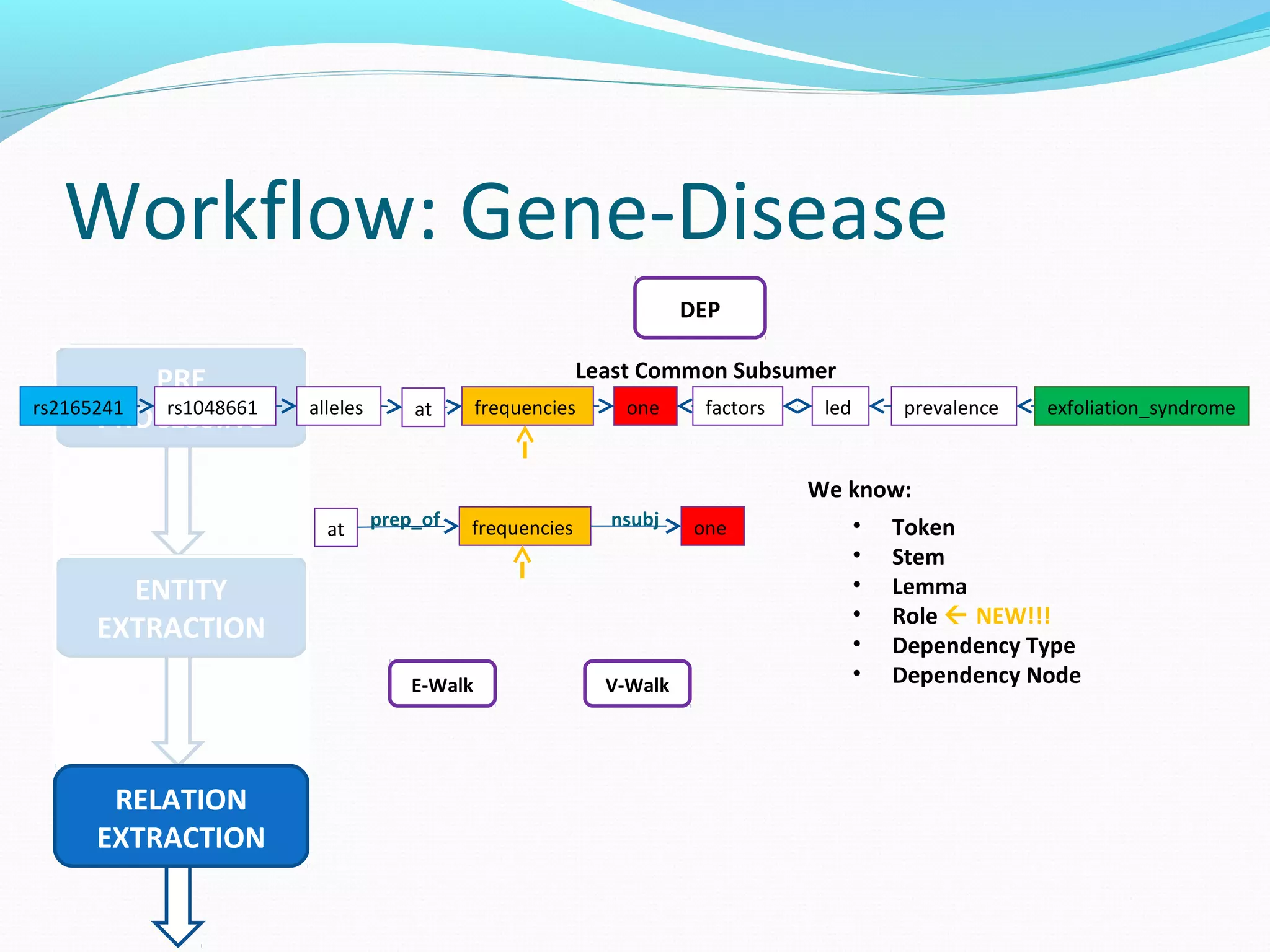
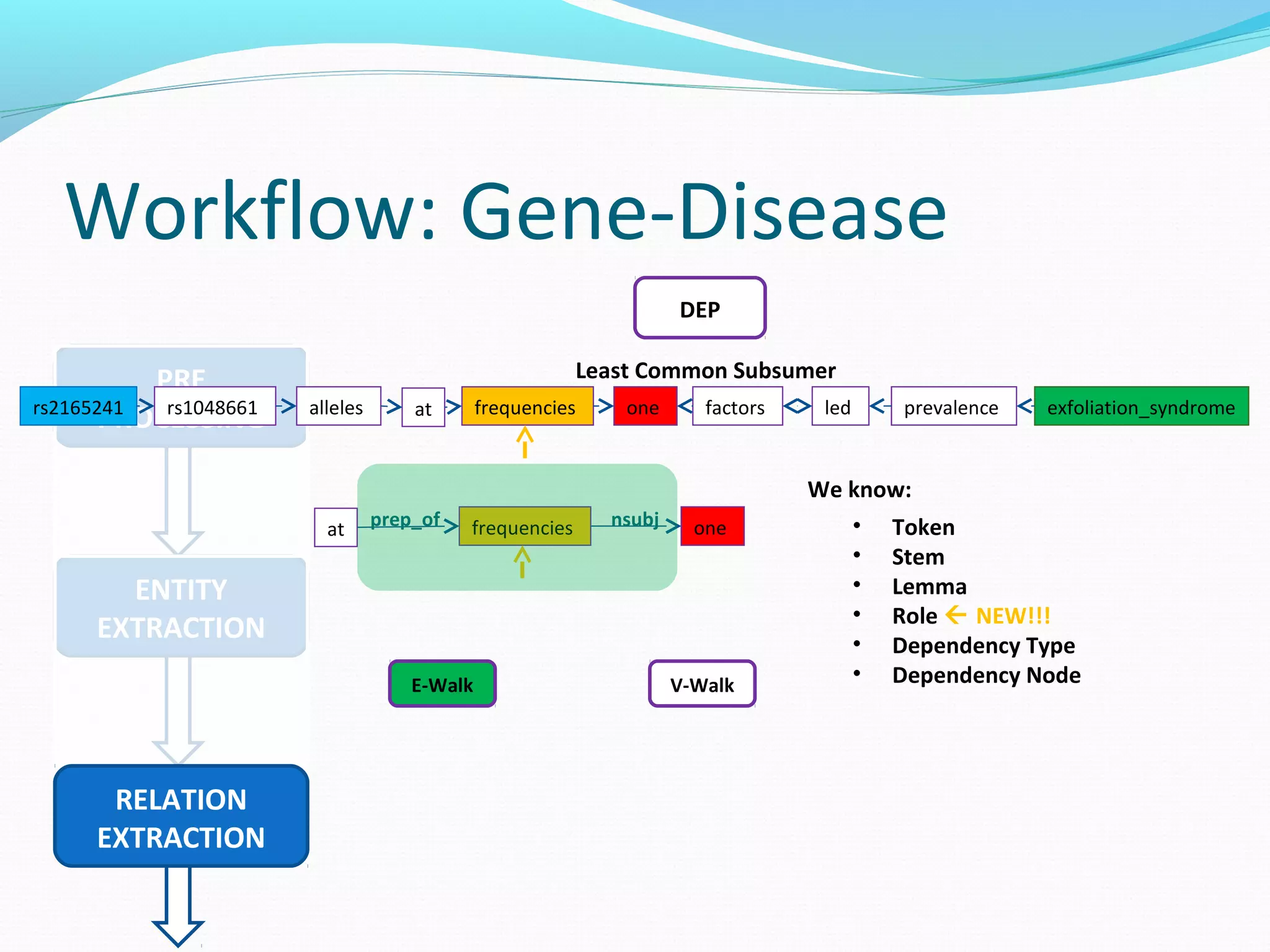
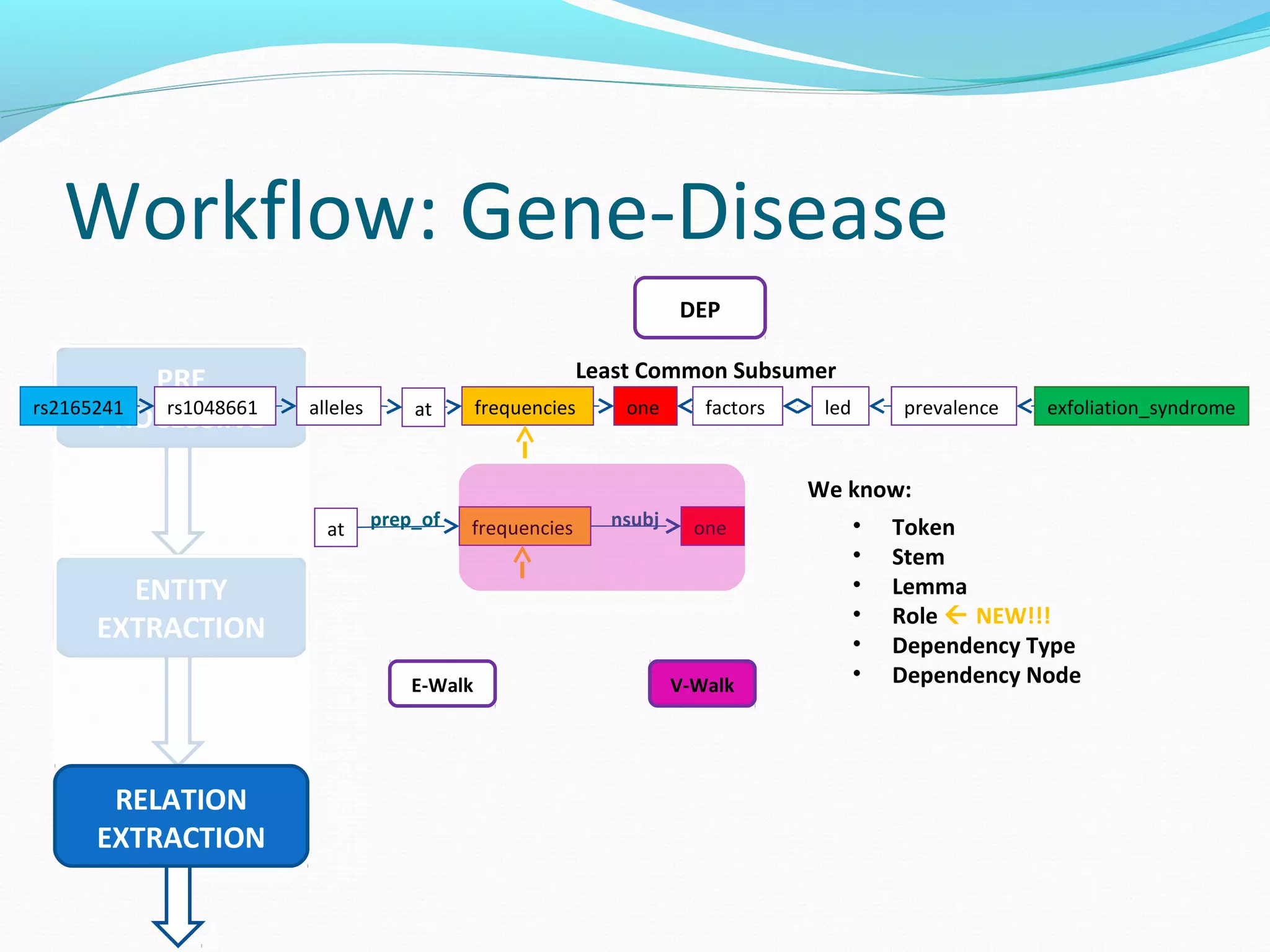
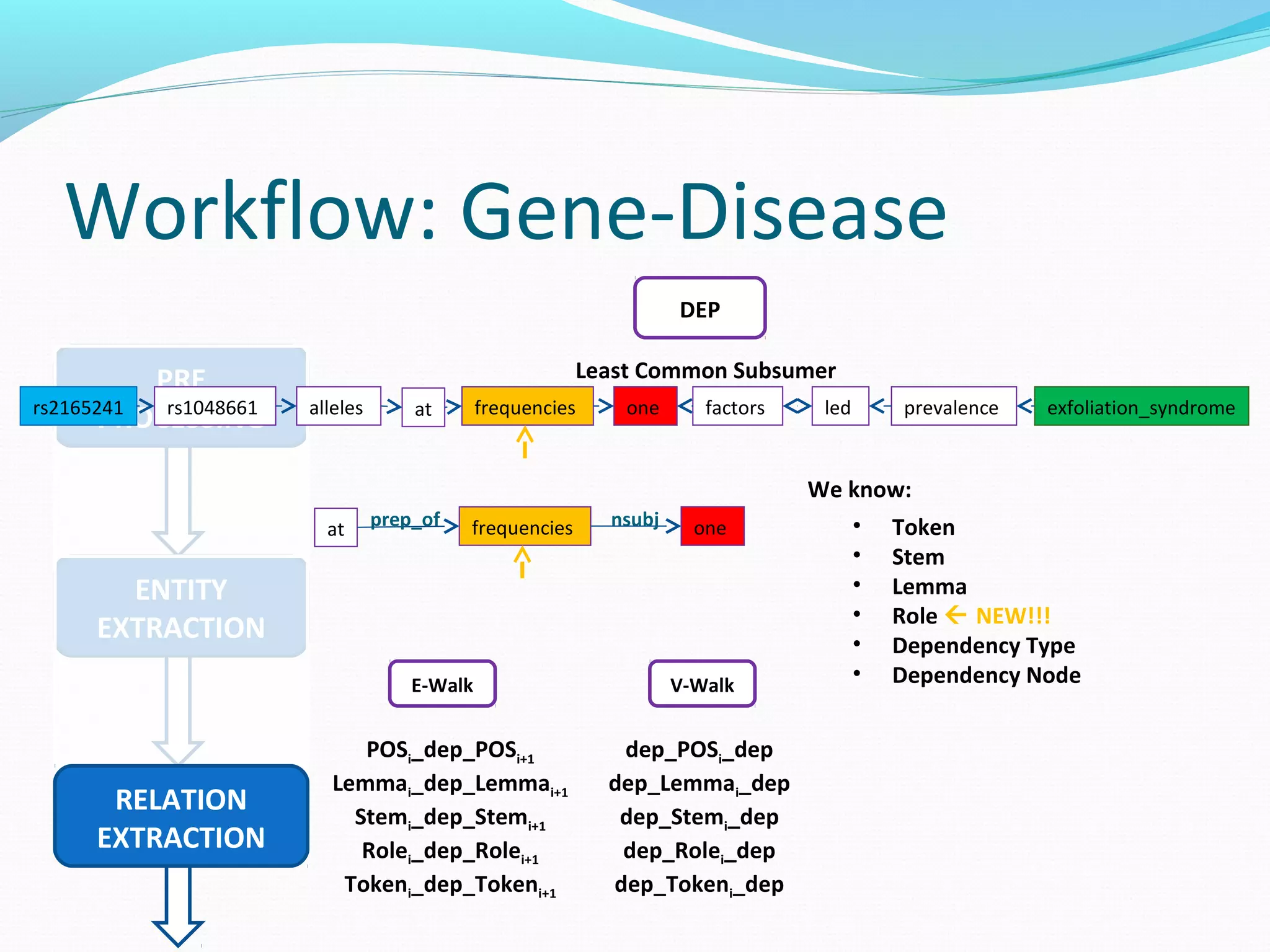
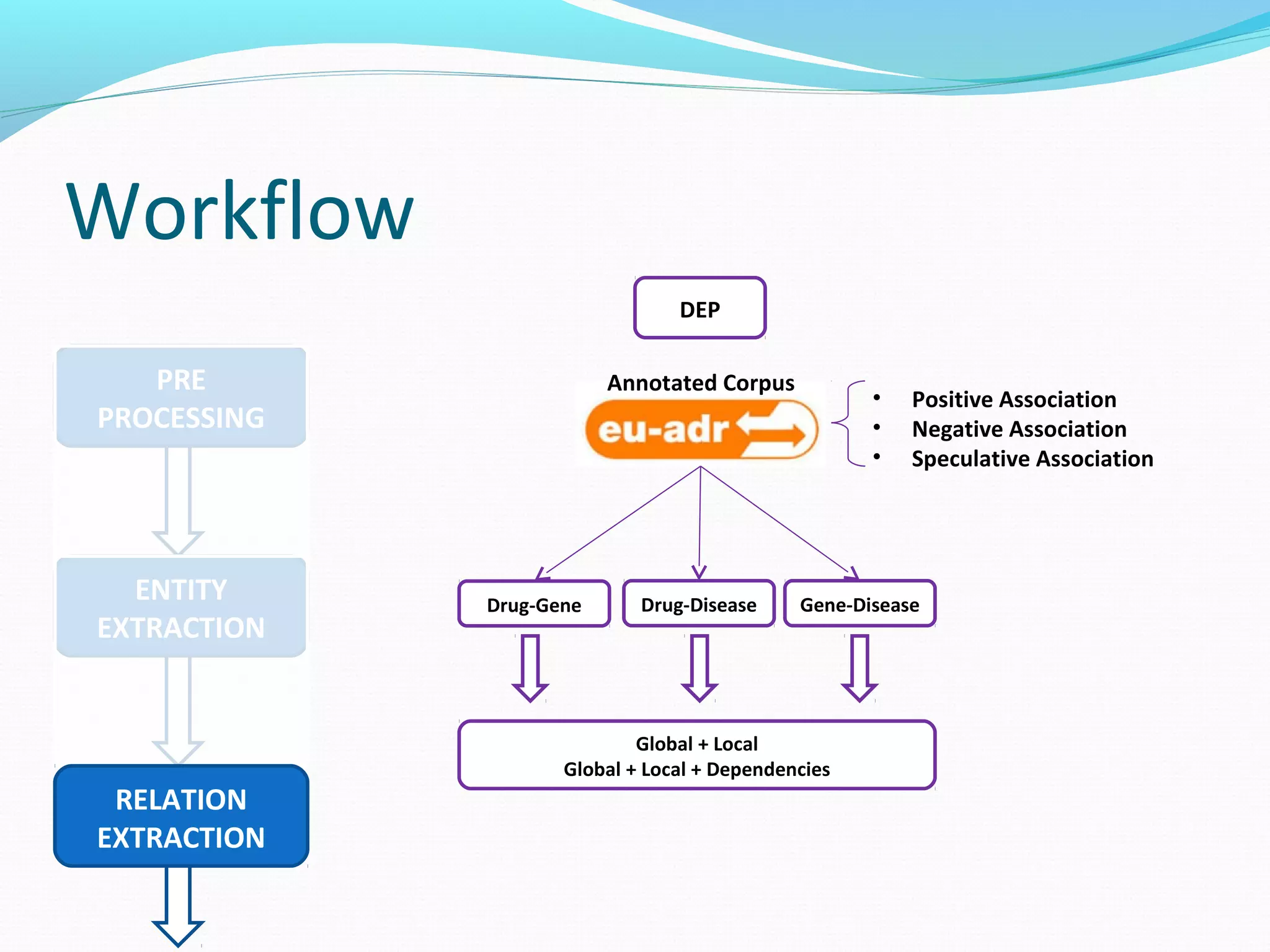


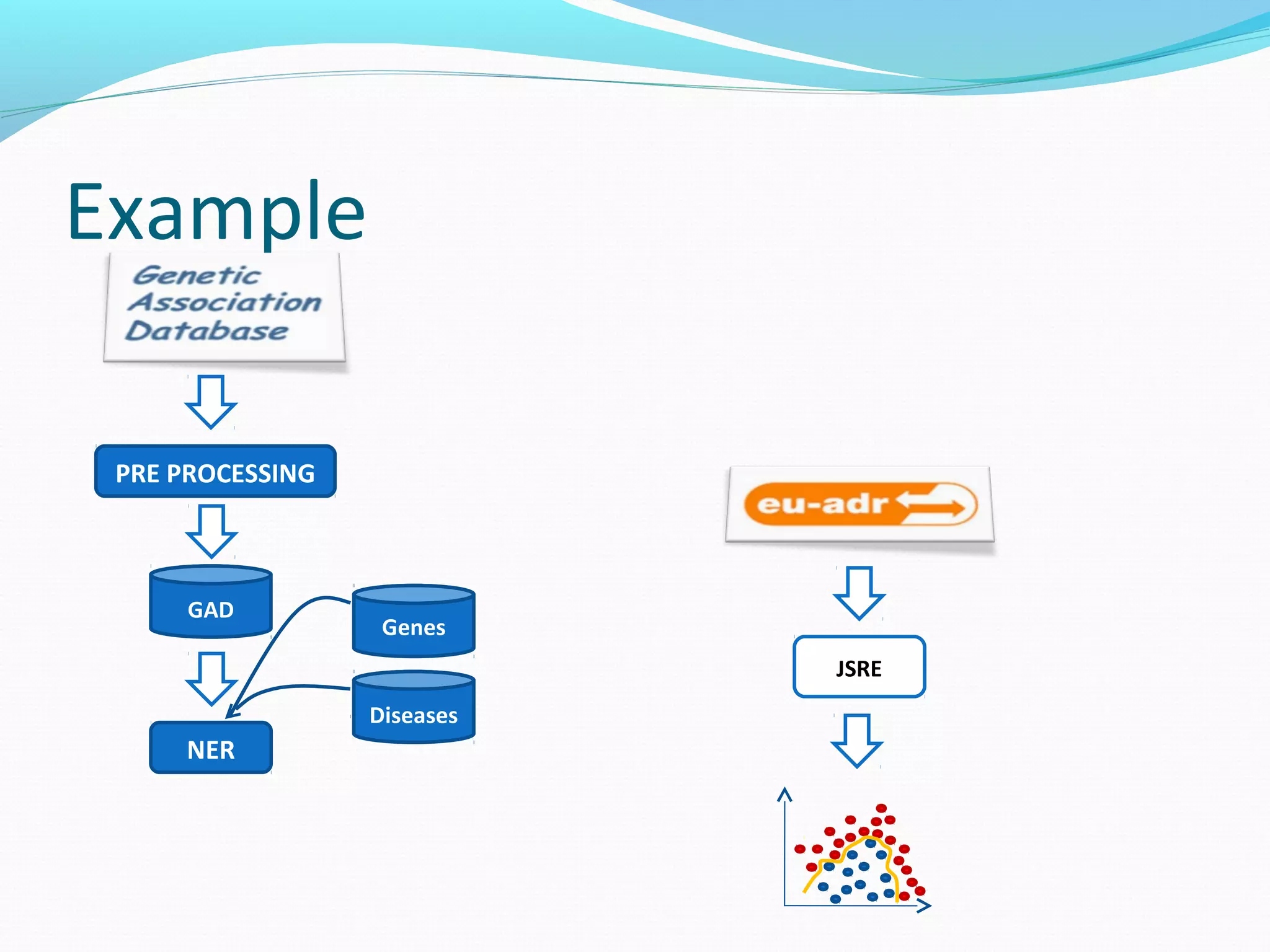
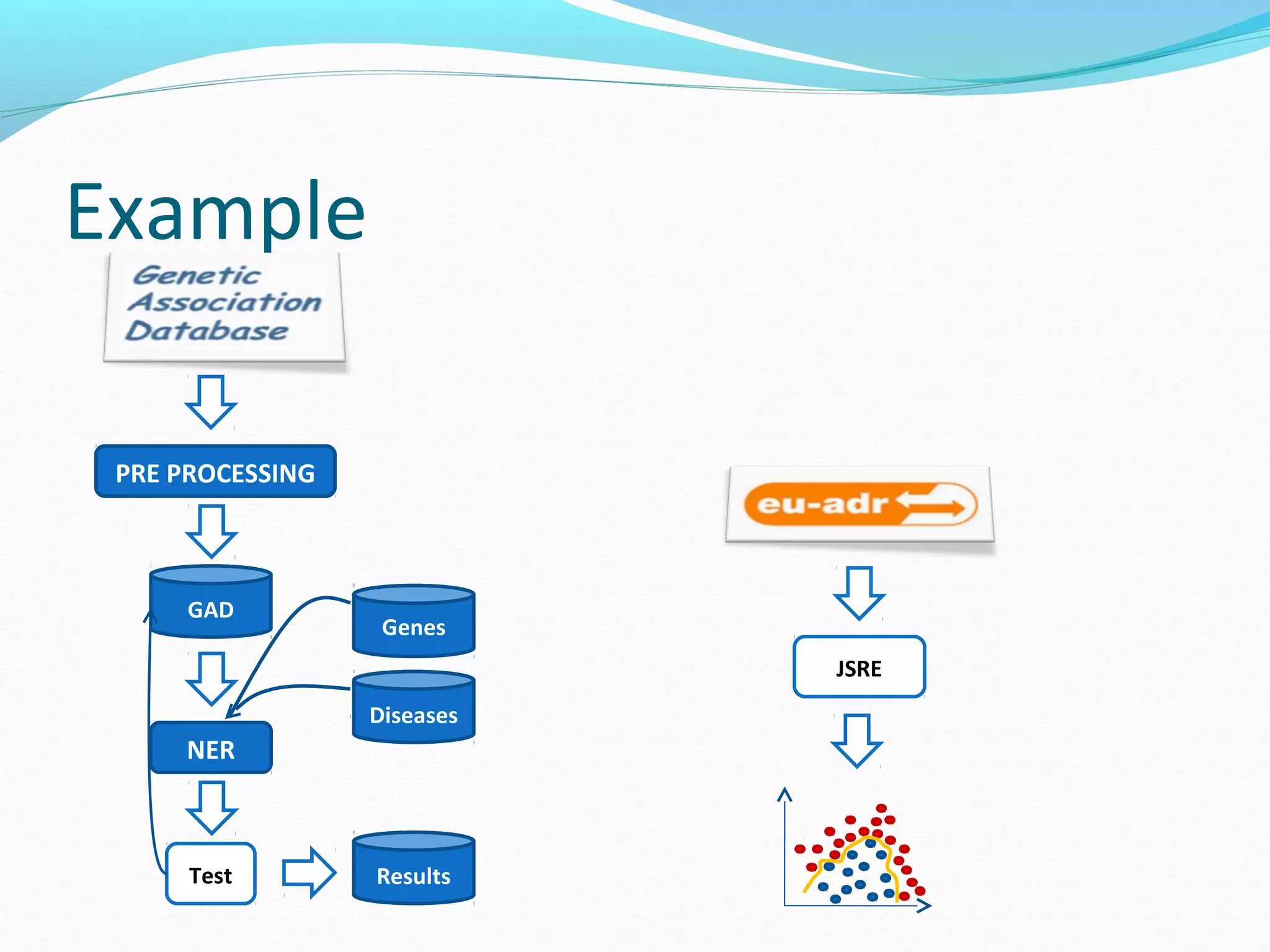
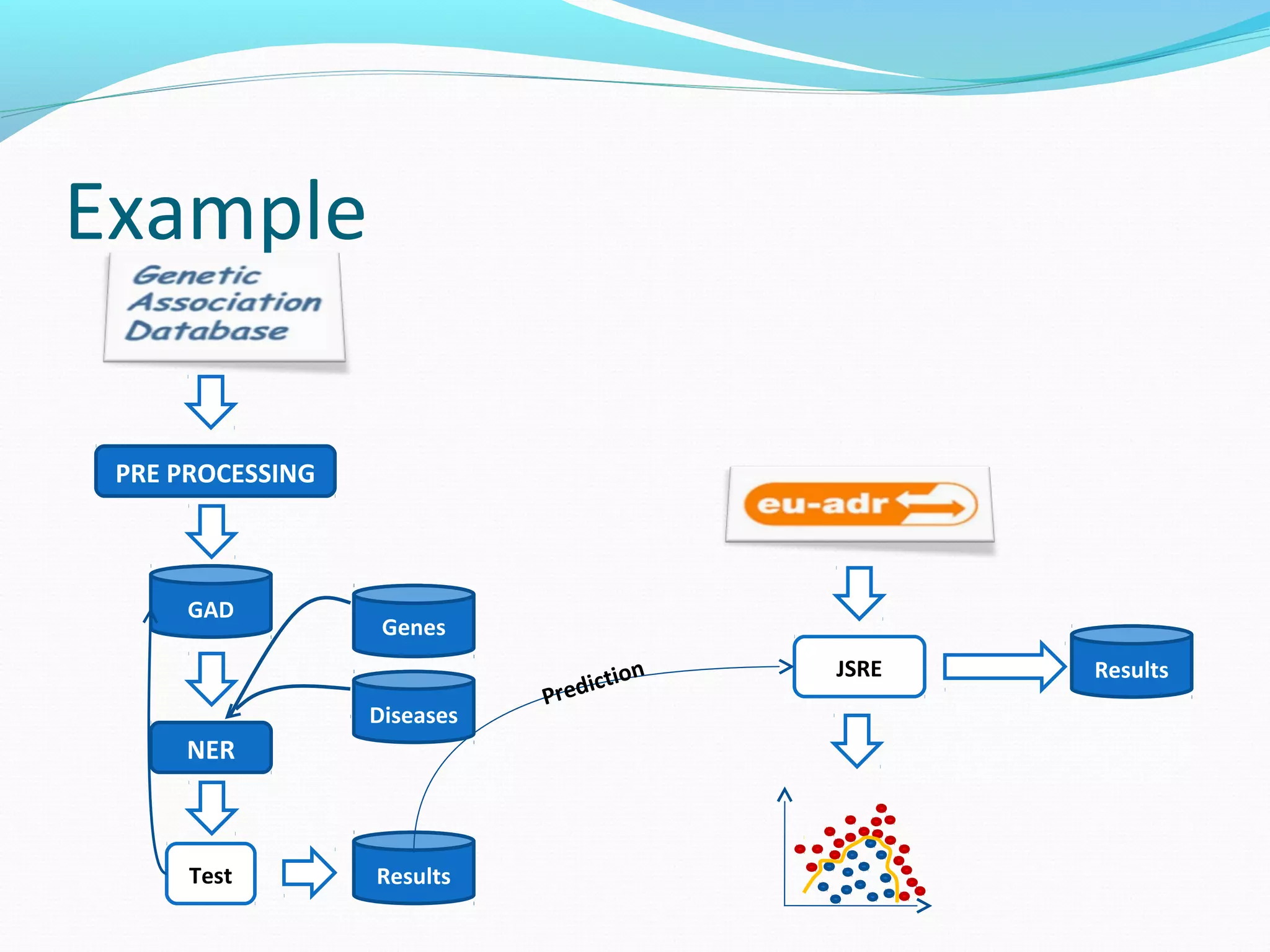


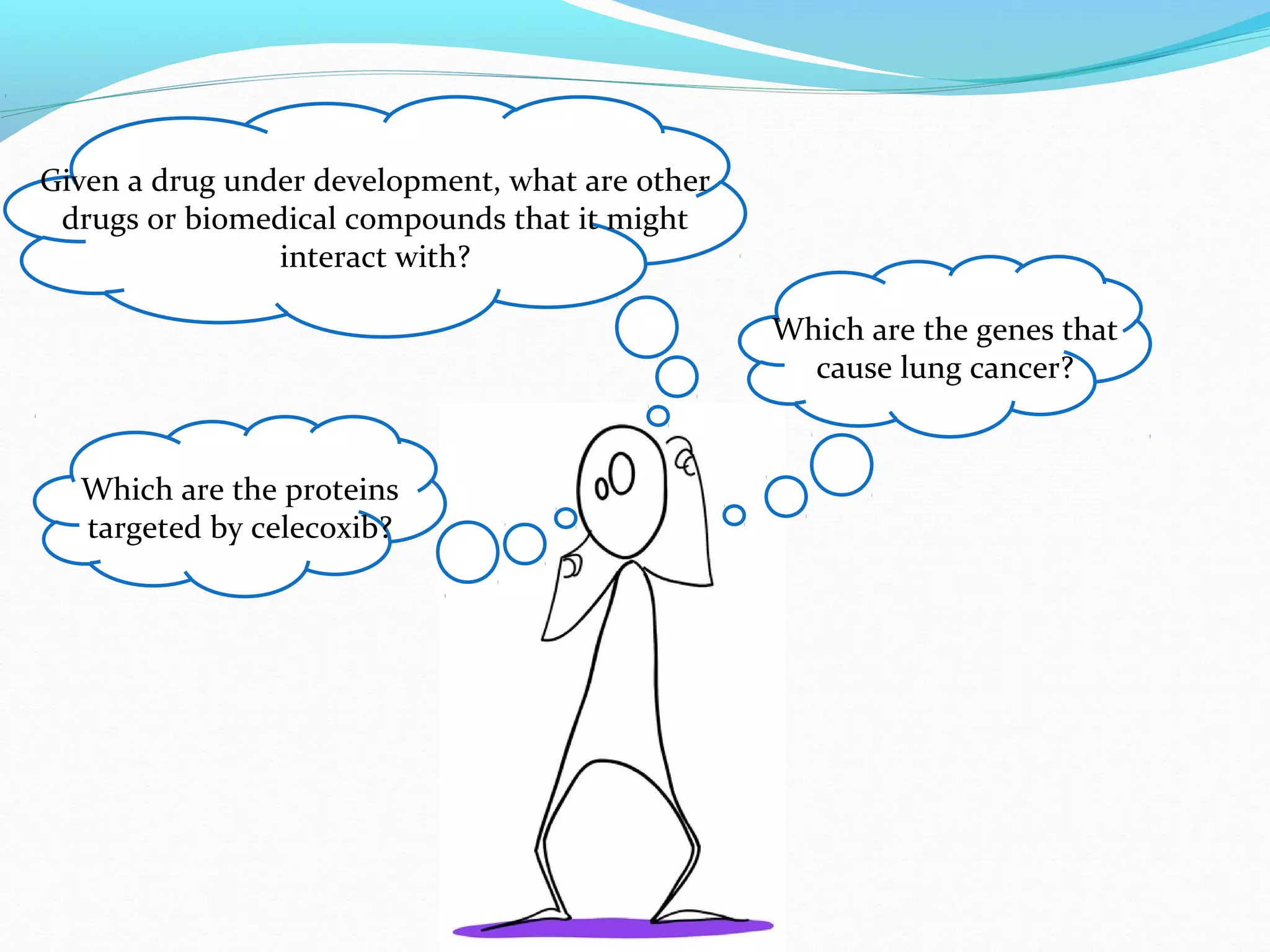
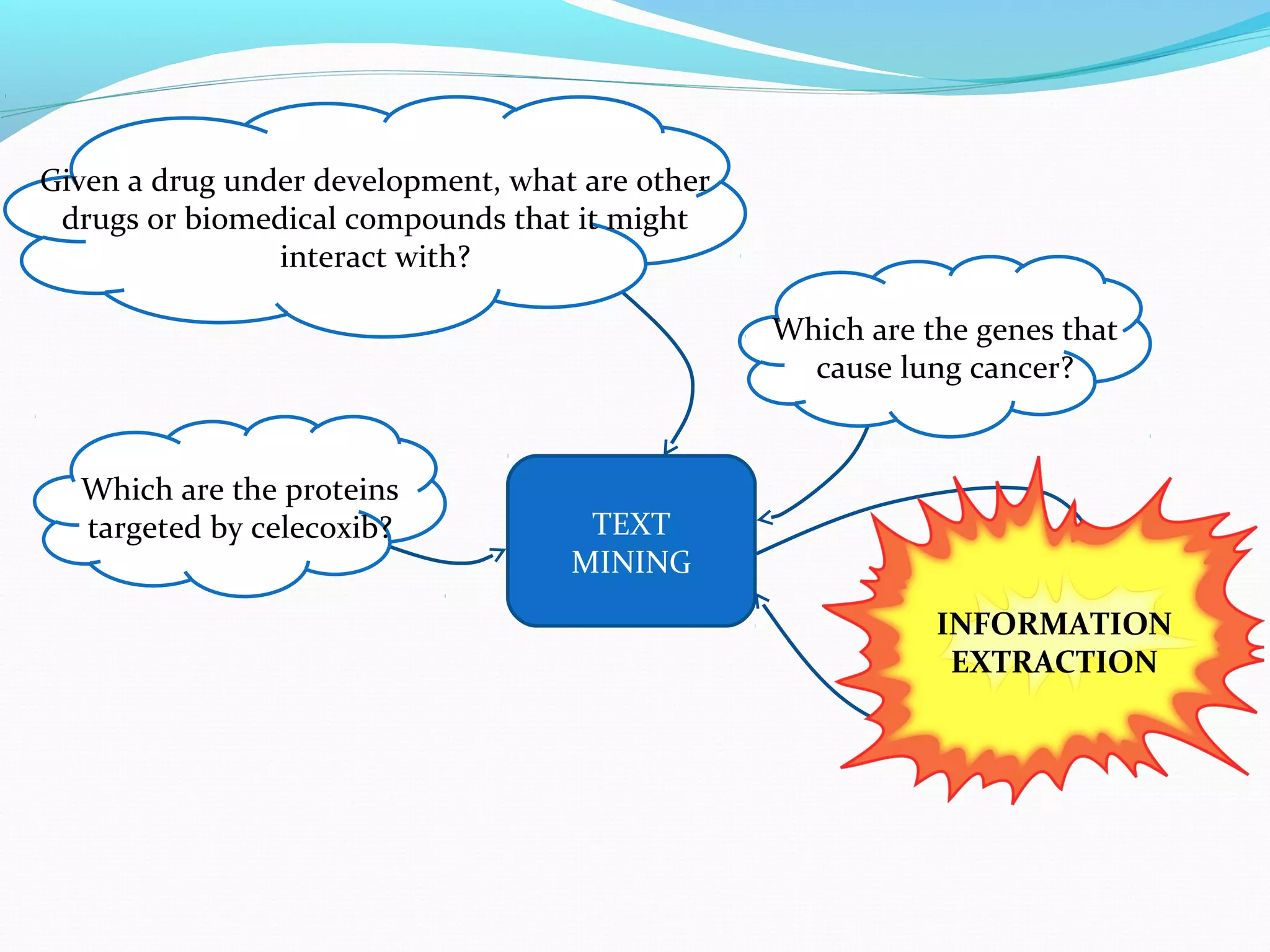
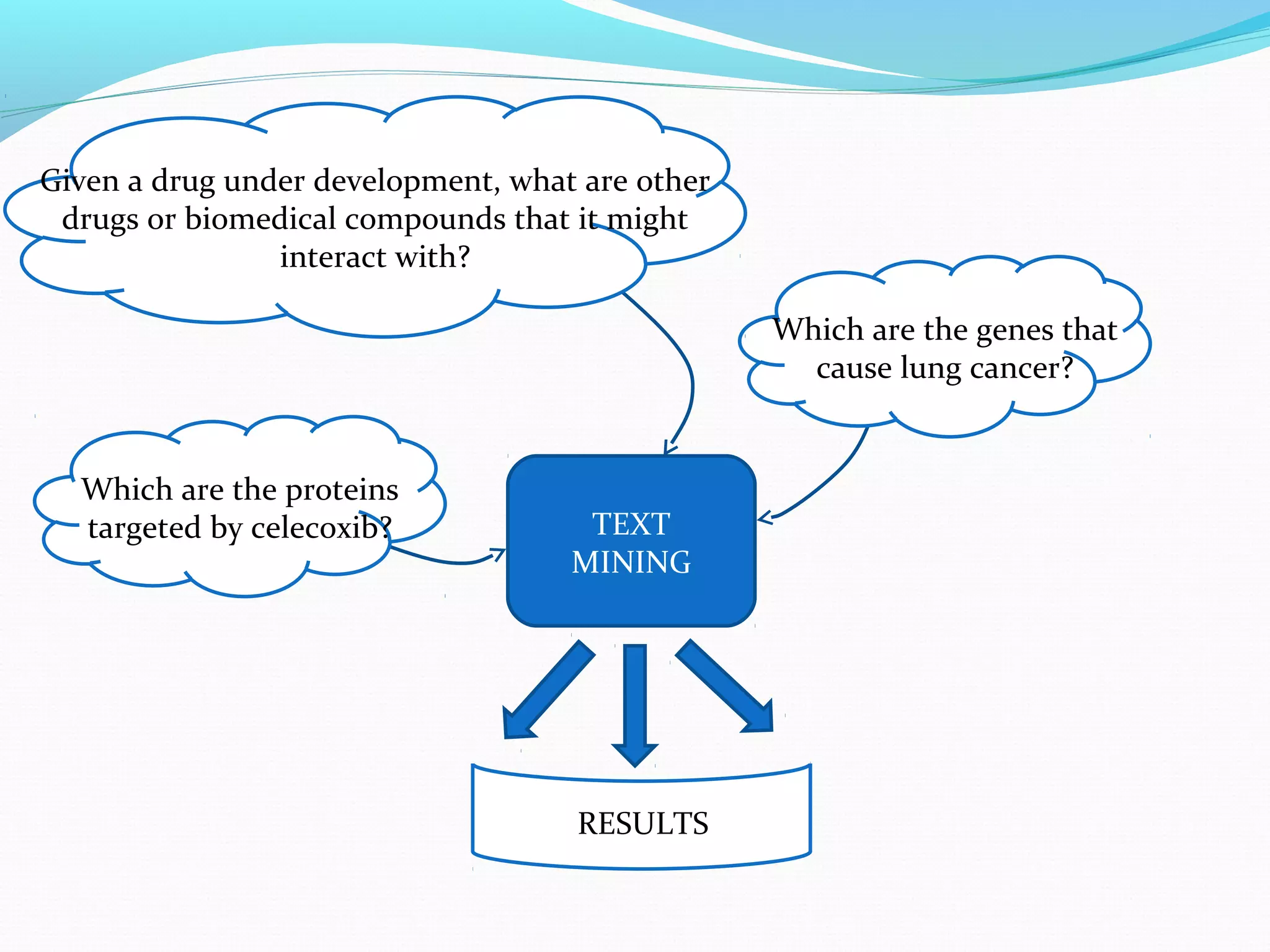
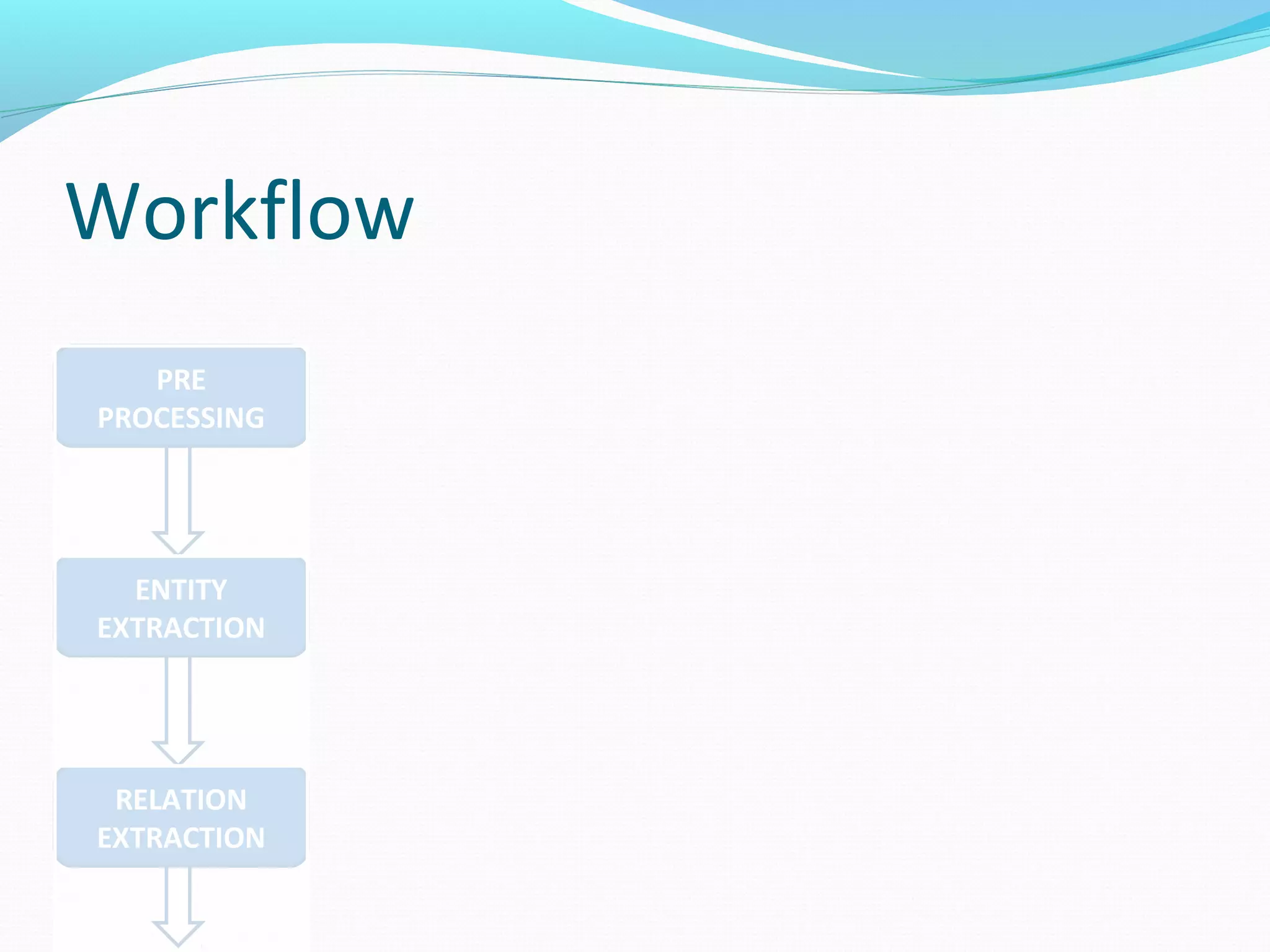
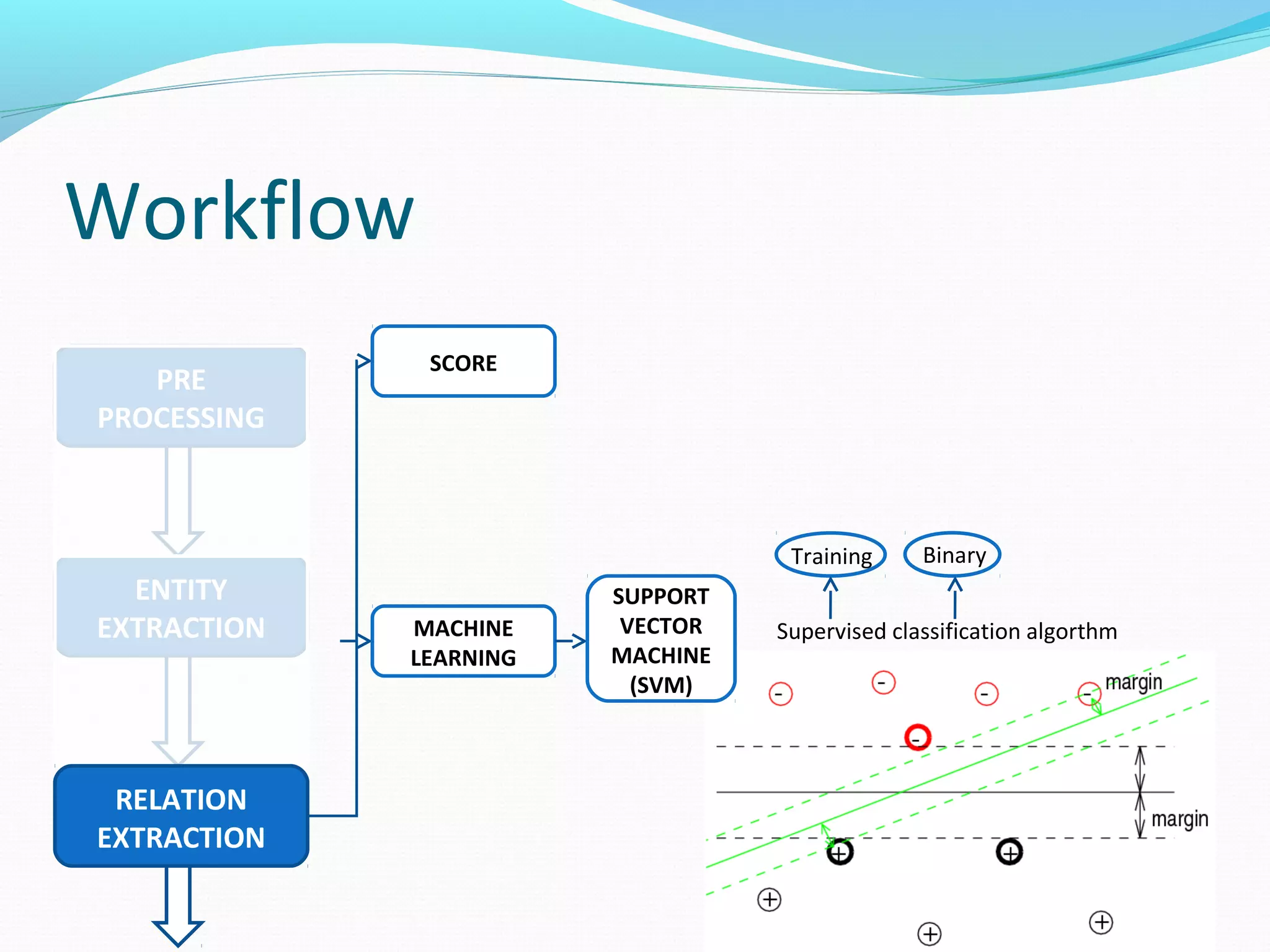
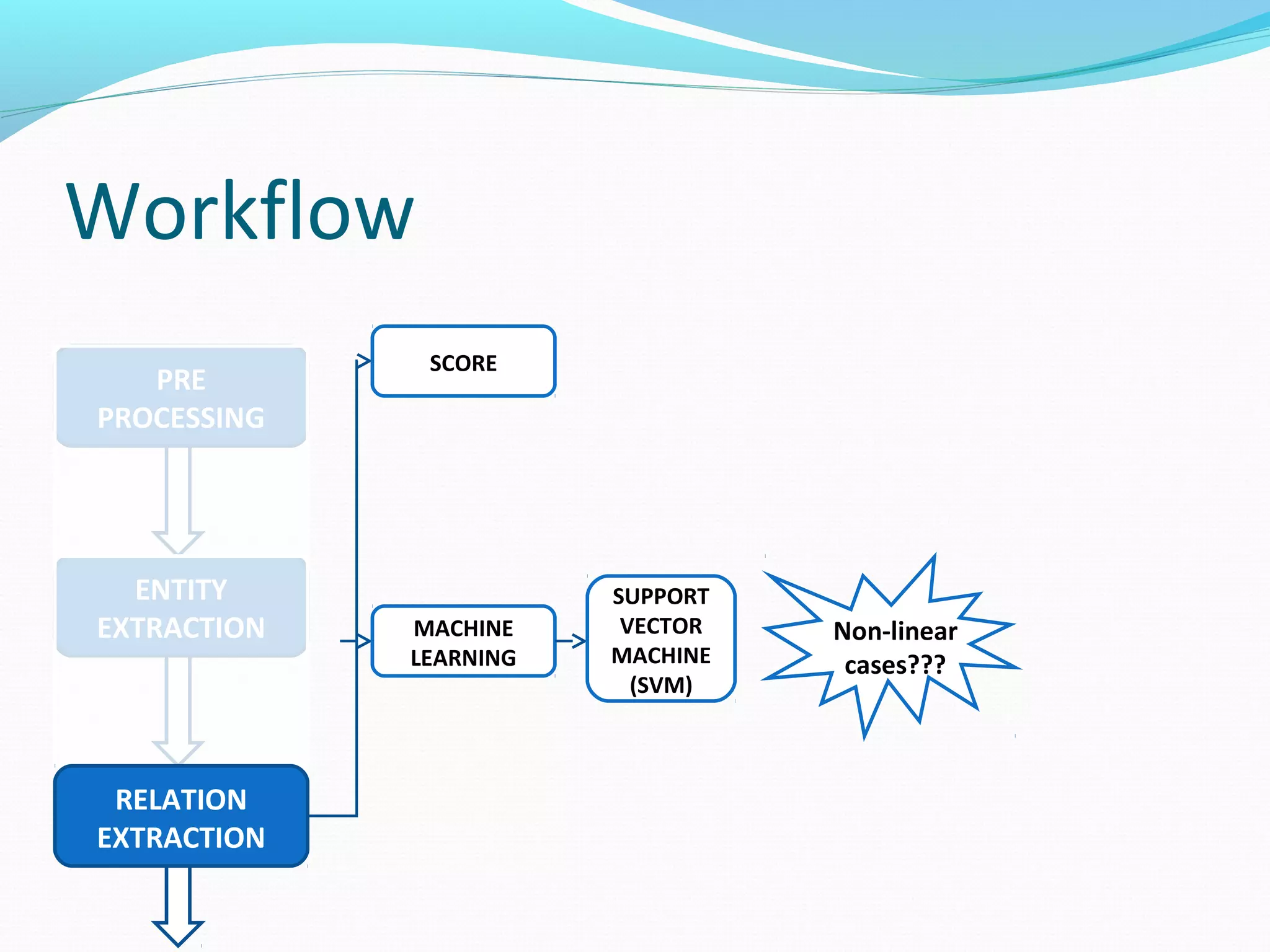
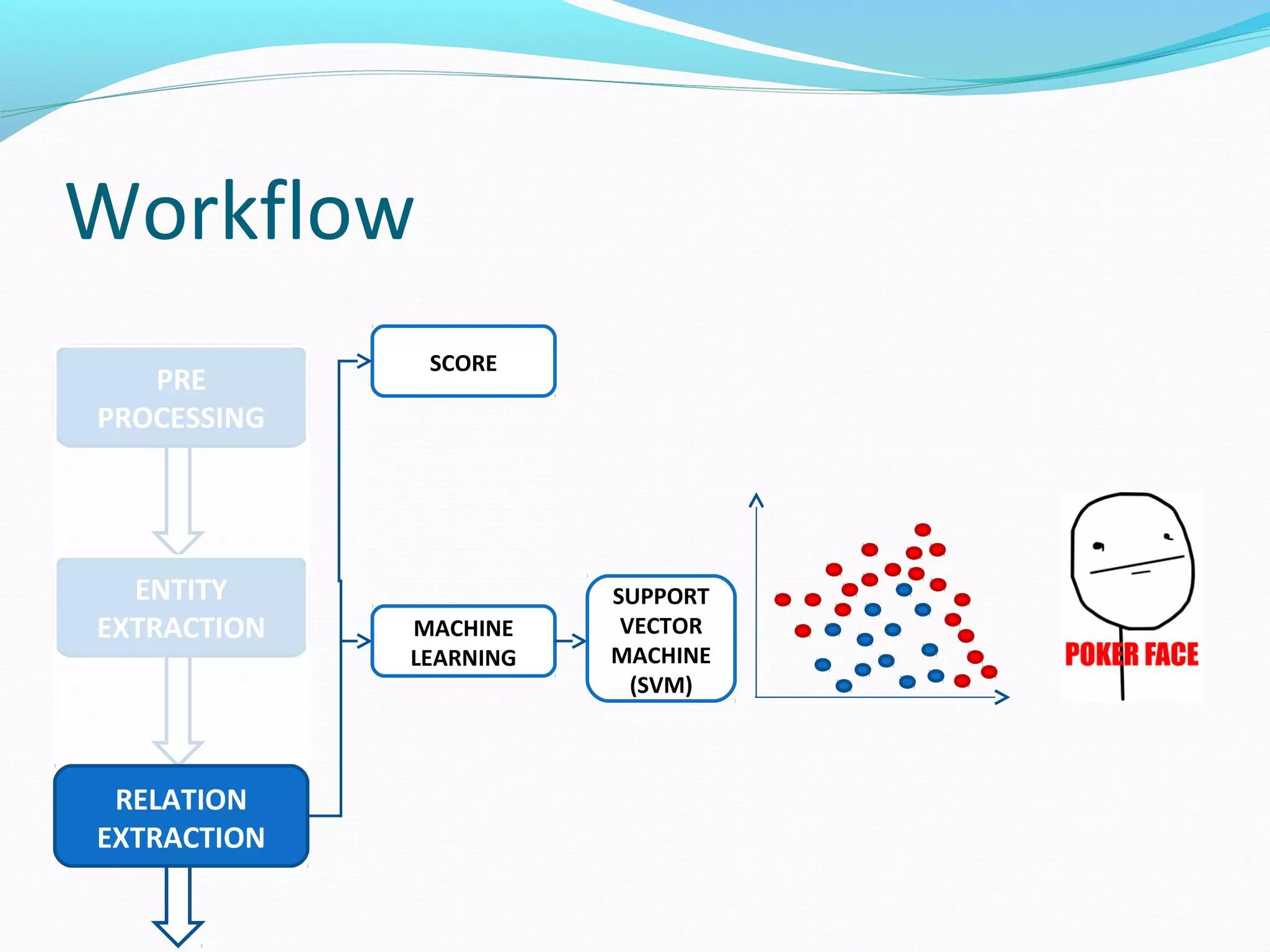
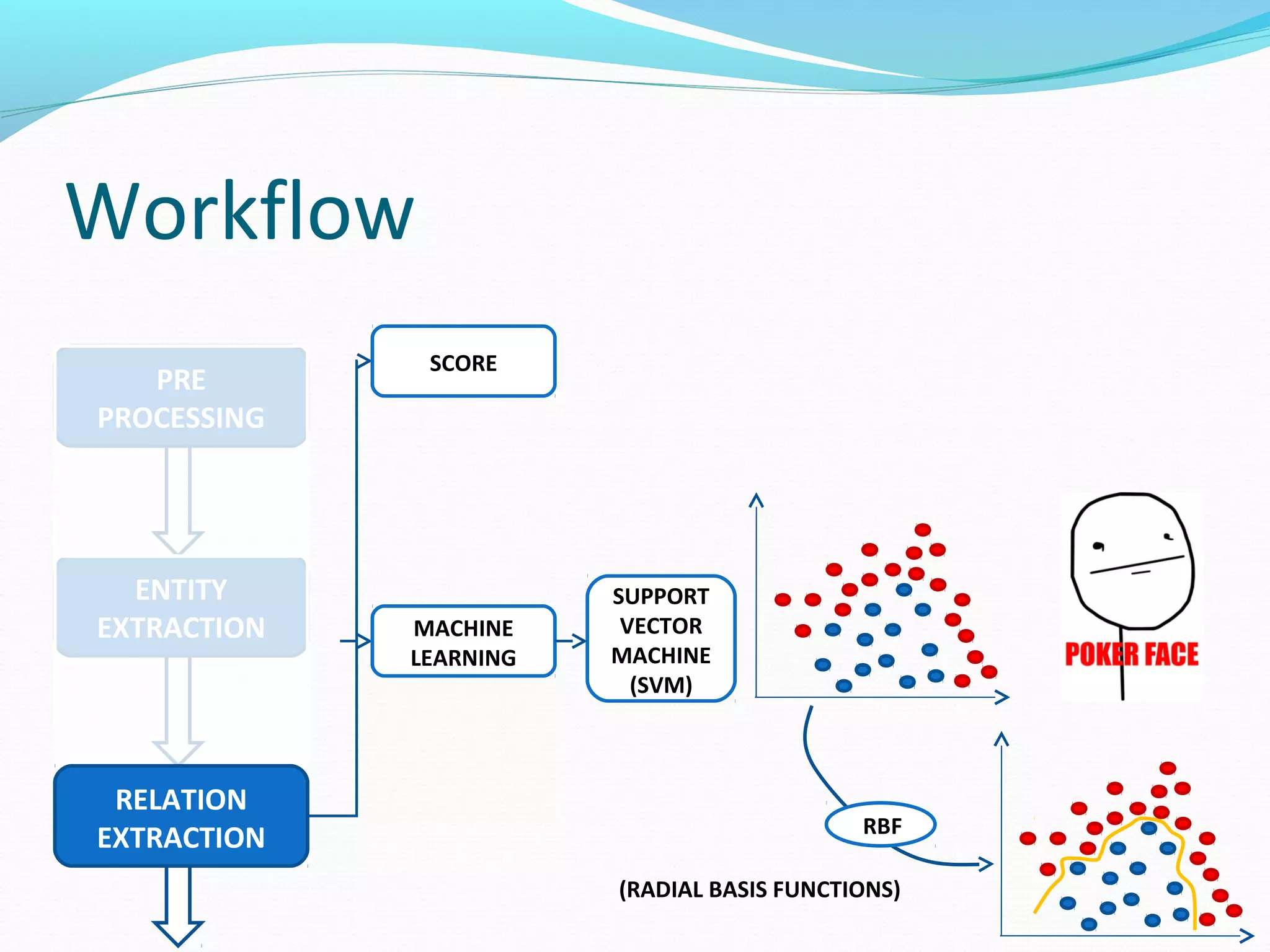
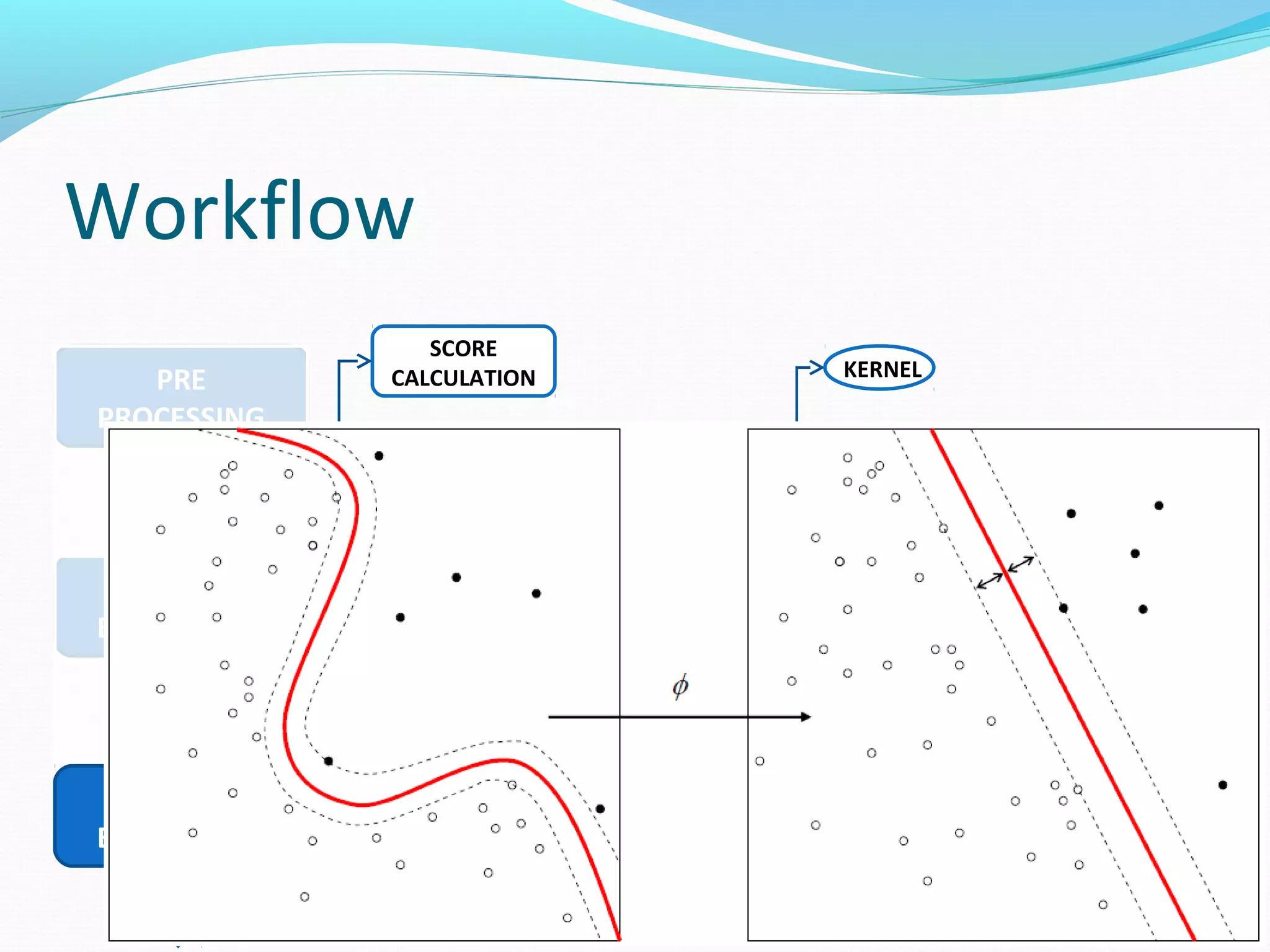
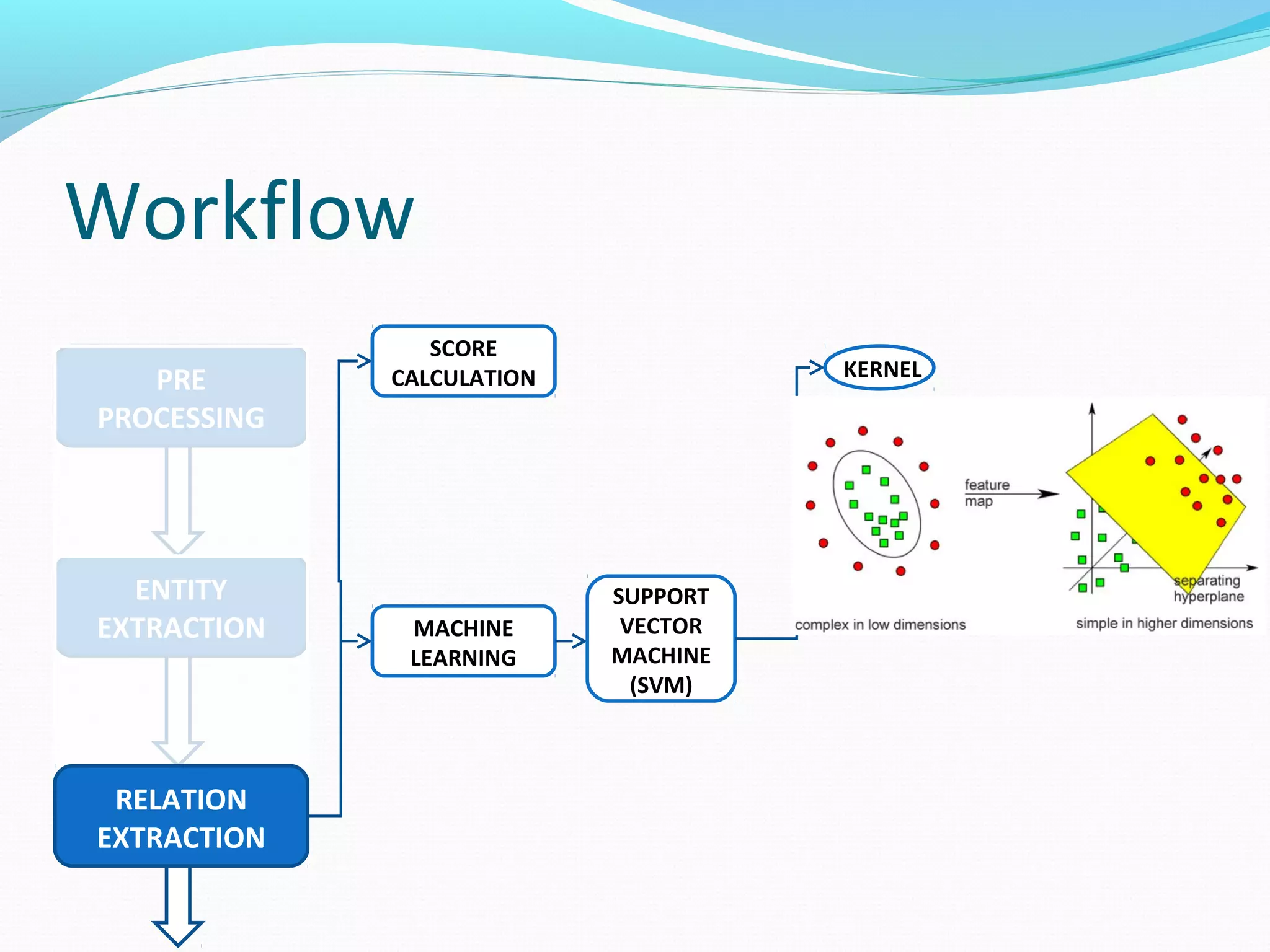
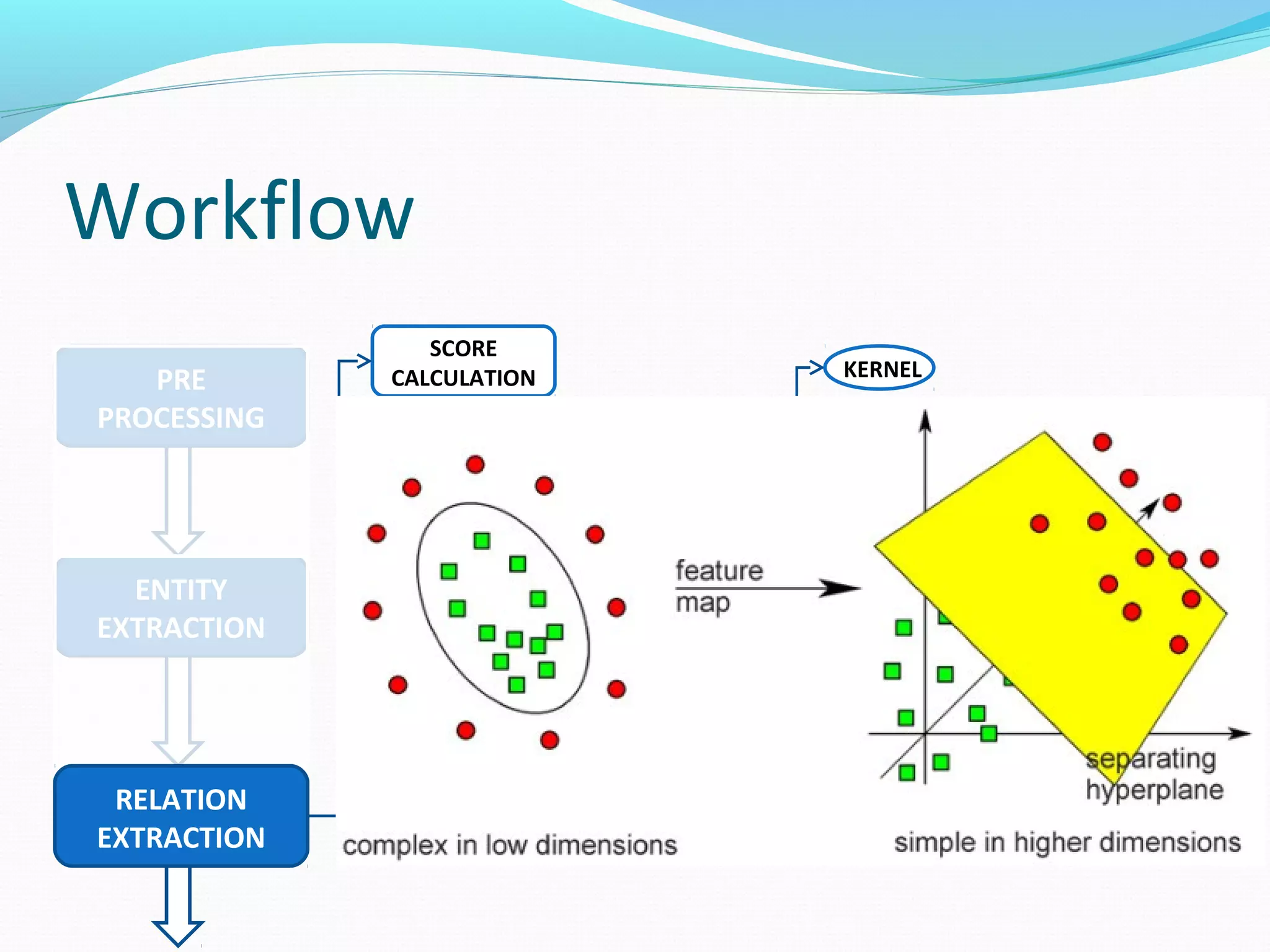
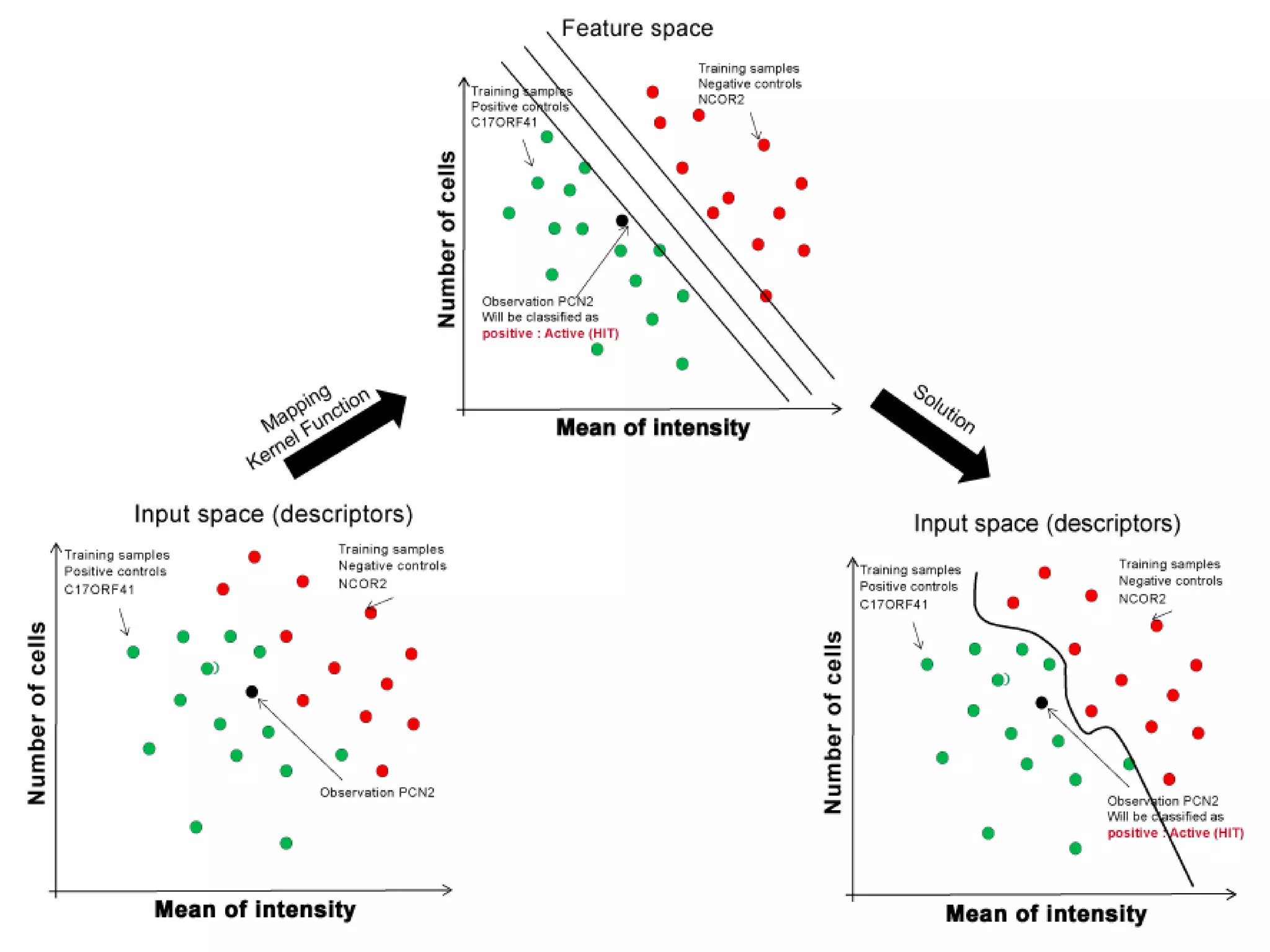
The document describes a workflow for extracting biomedical entities and relations from text using machine learning techniques. The workflow involves preprocessing text, extracting entities, extracting relations between entities, and using support vector machines and kernel methods to classify relations with a global and local feature space. Key aspects include named entity recognition to identify genes and diseases, and using the JSRE tool to extract relations between extracted entities.





















































