Download as PDF, PPTX
























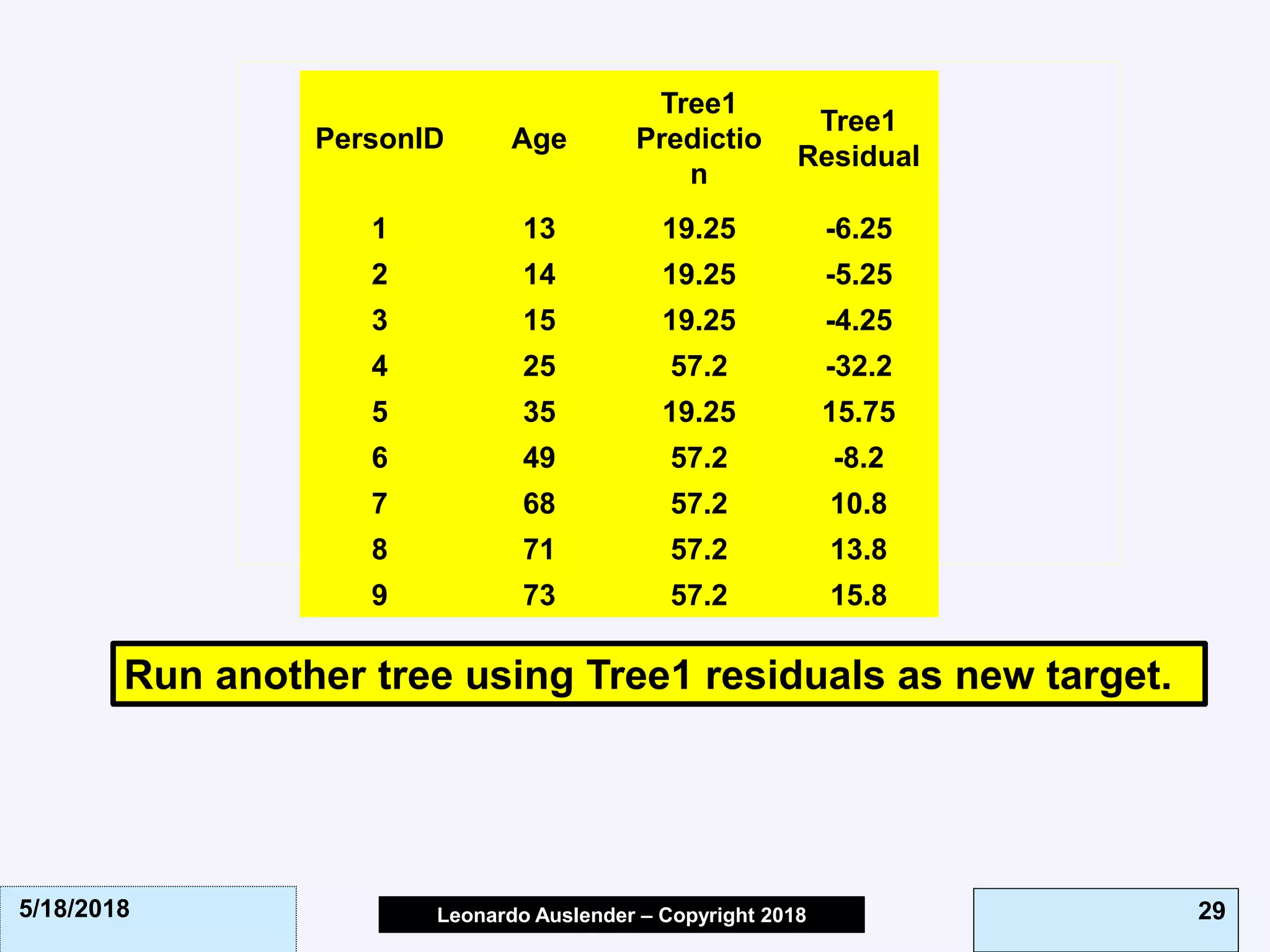
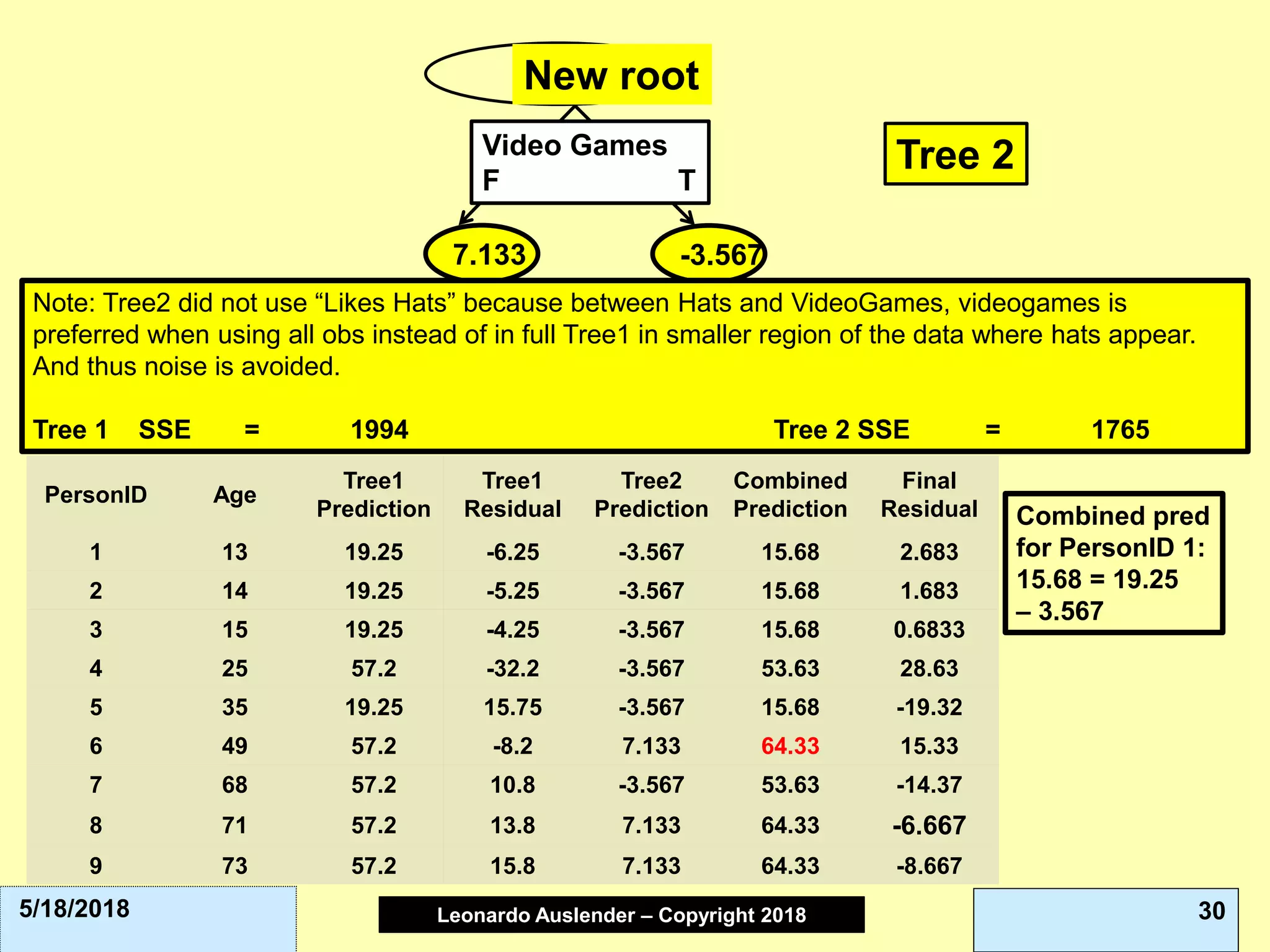
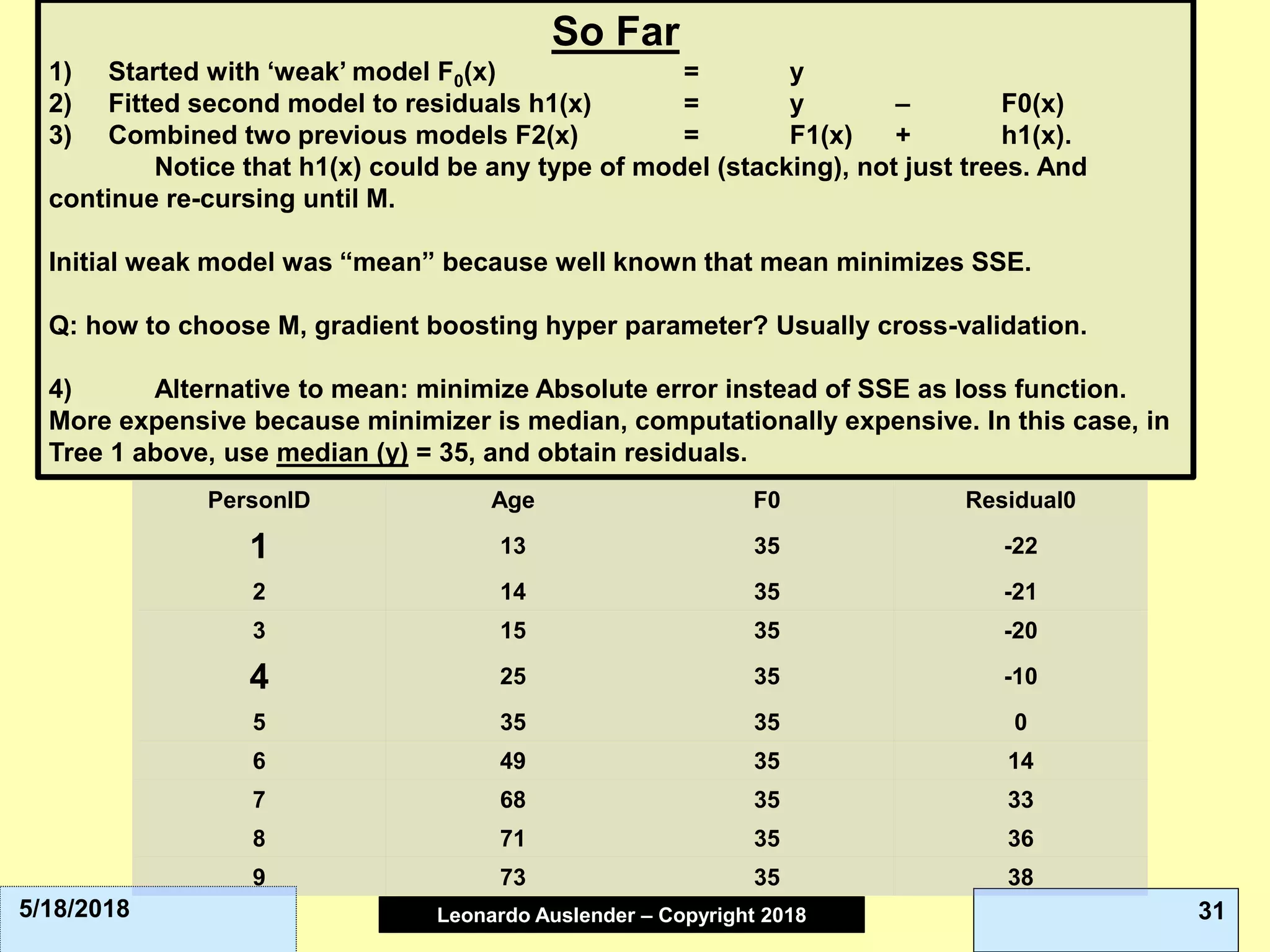

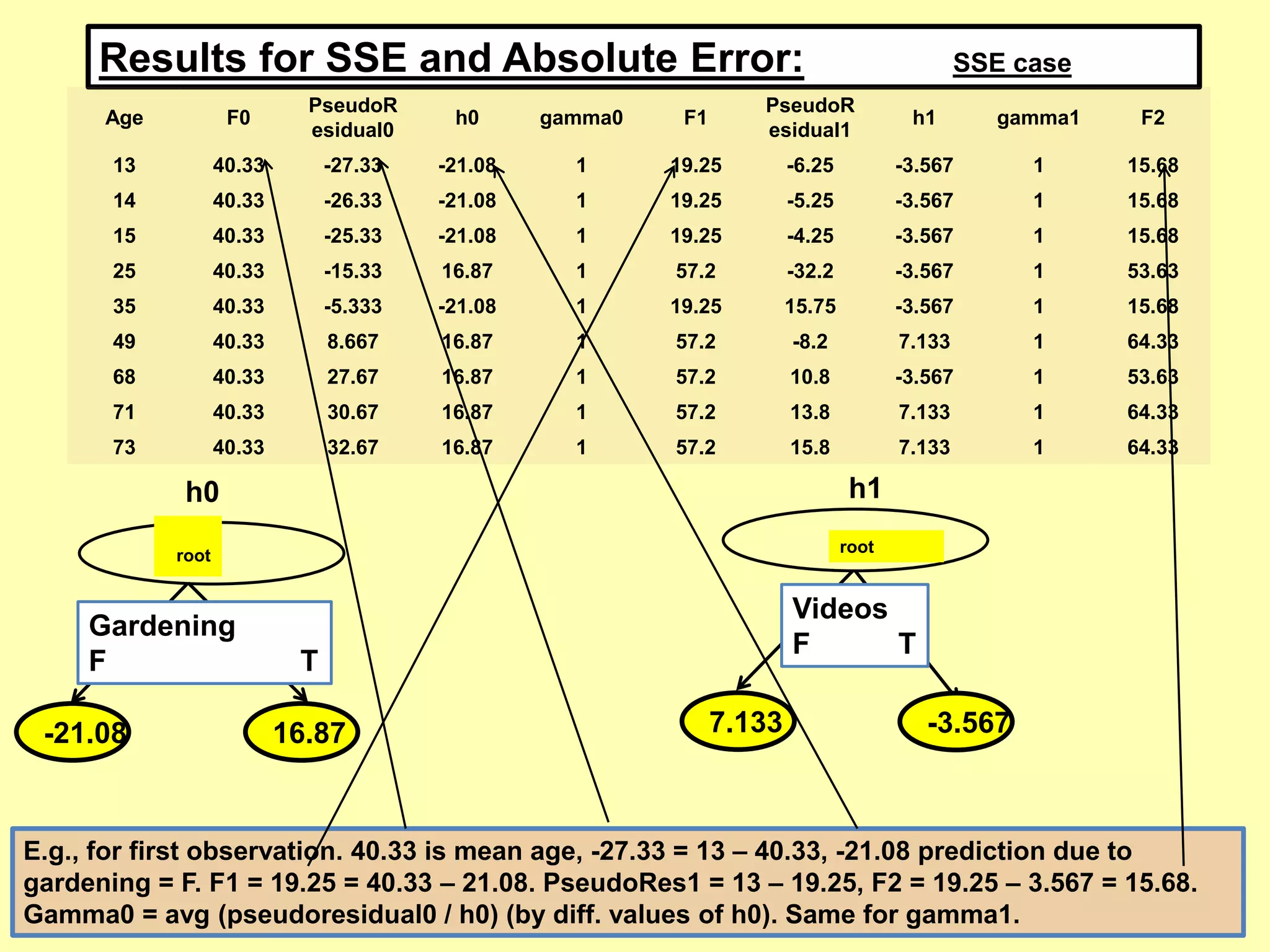
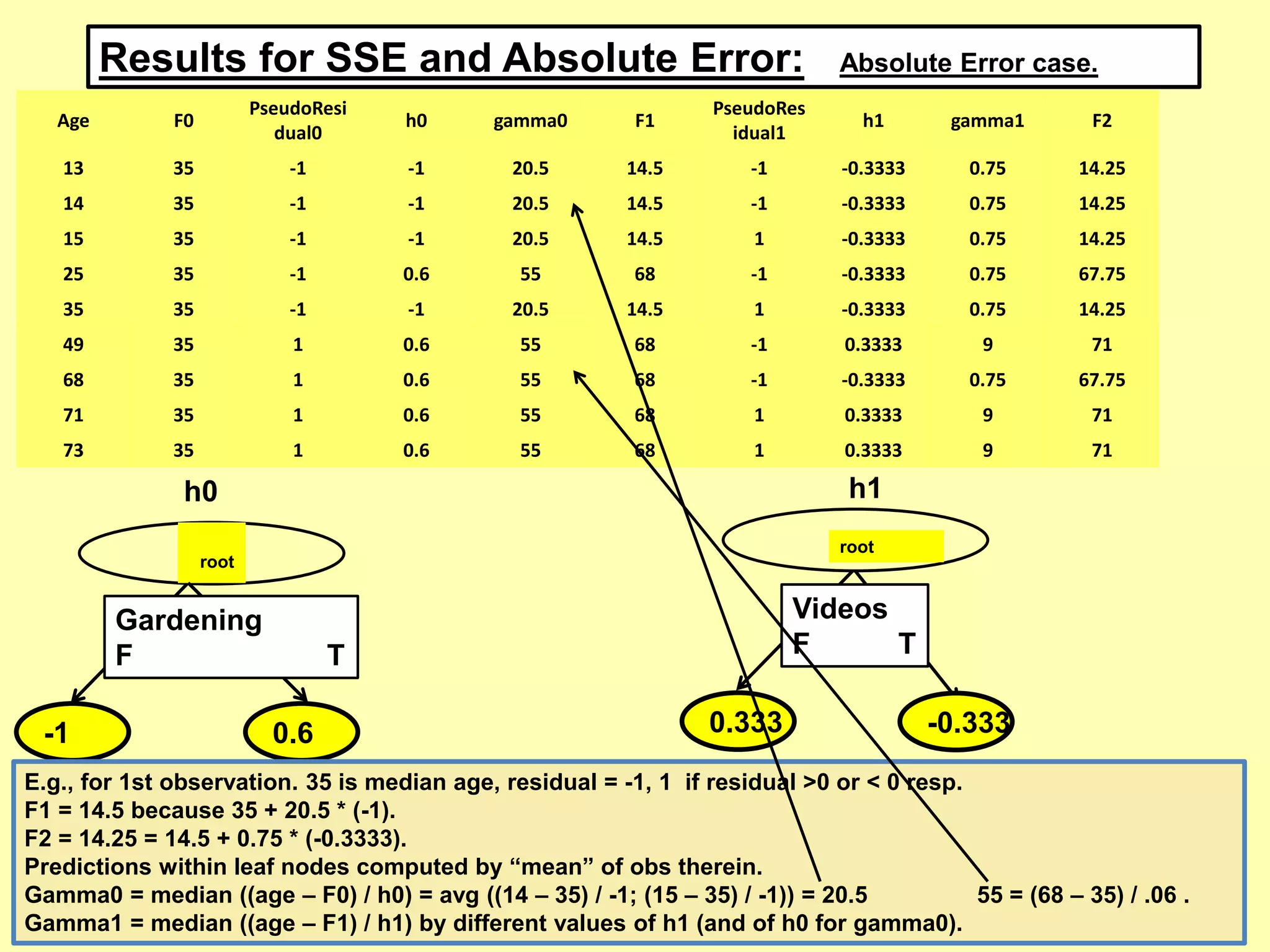








![Leonardo Auslender Copyright 2004Leonardo Auslender – Copyright 2018 435/18/2018
L2-error penalizes symmetrically away from 0, Huber penalizes less than OLS
away from [-1, 1], Bernoulli and Adaboost are very similar. Note that Y ε [-1, 1]
in 0-1 case here.](https://image.slidesharecdn.com/42ensemblemodelsandgradboostpart1-180618192506/75/4-2-ensemble-models-and-grad-boost-part-1-43-2048.jpg)

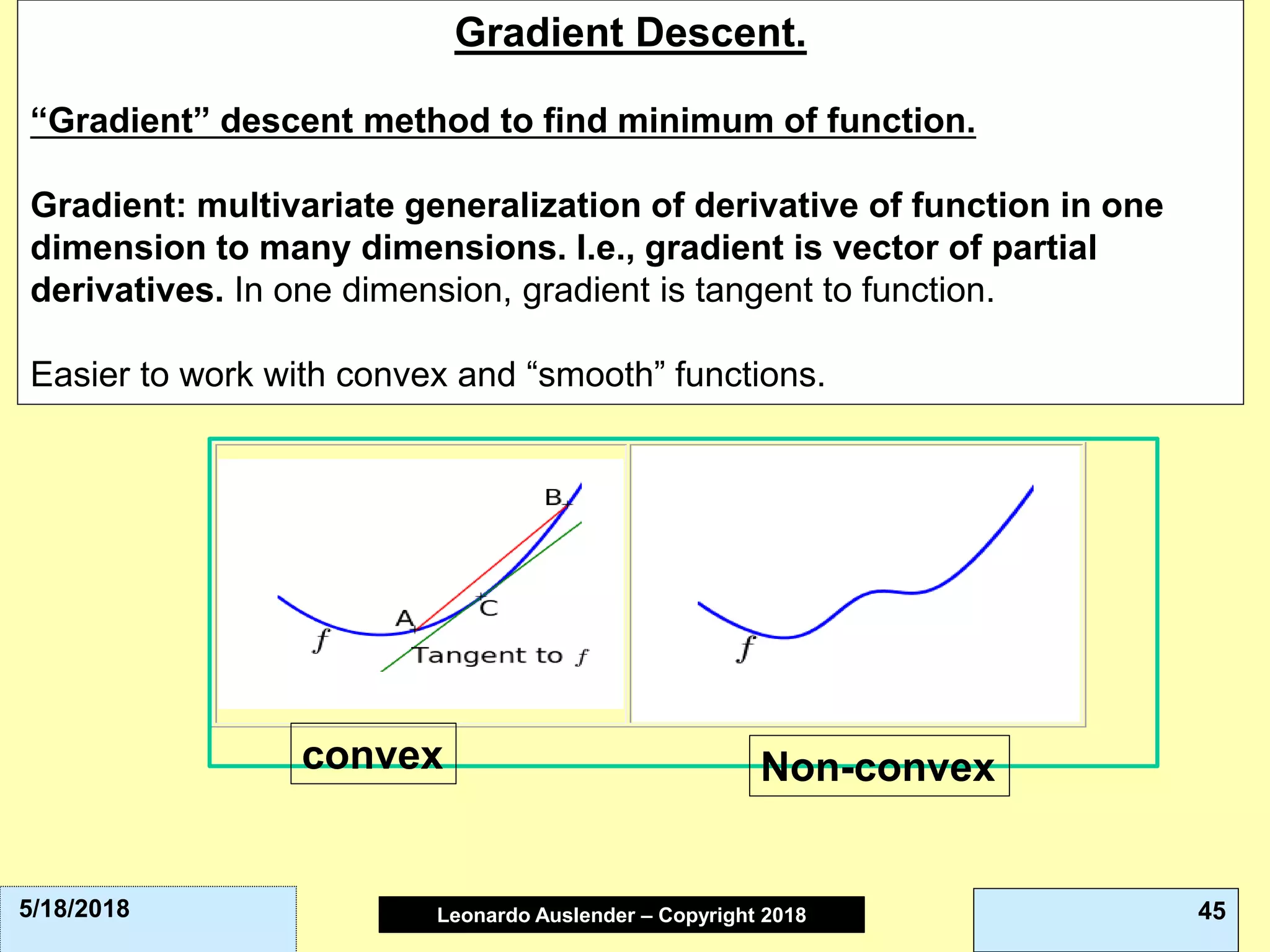

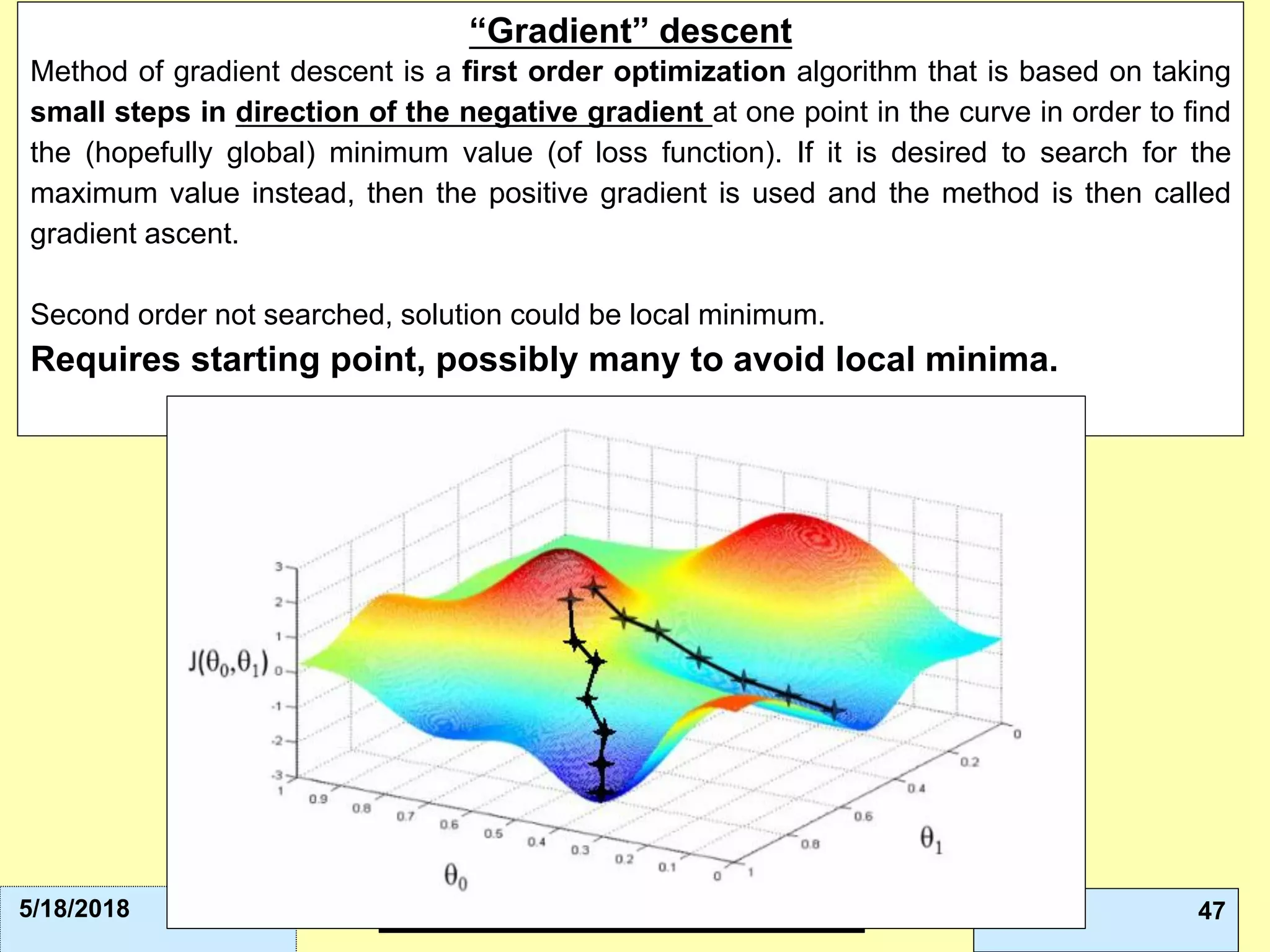

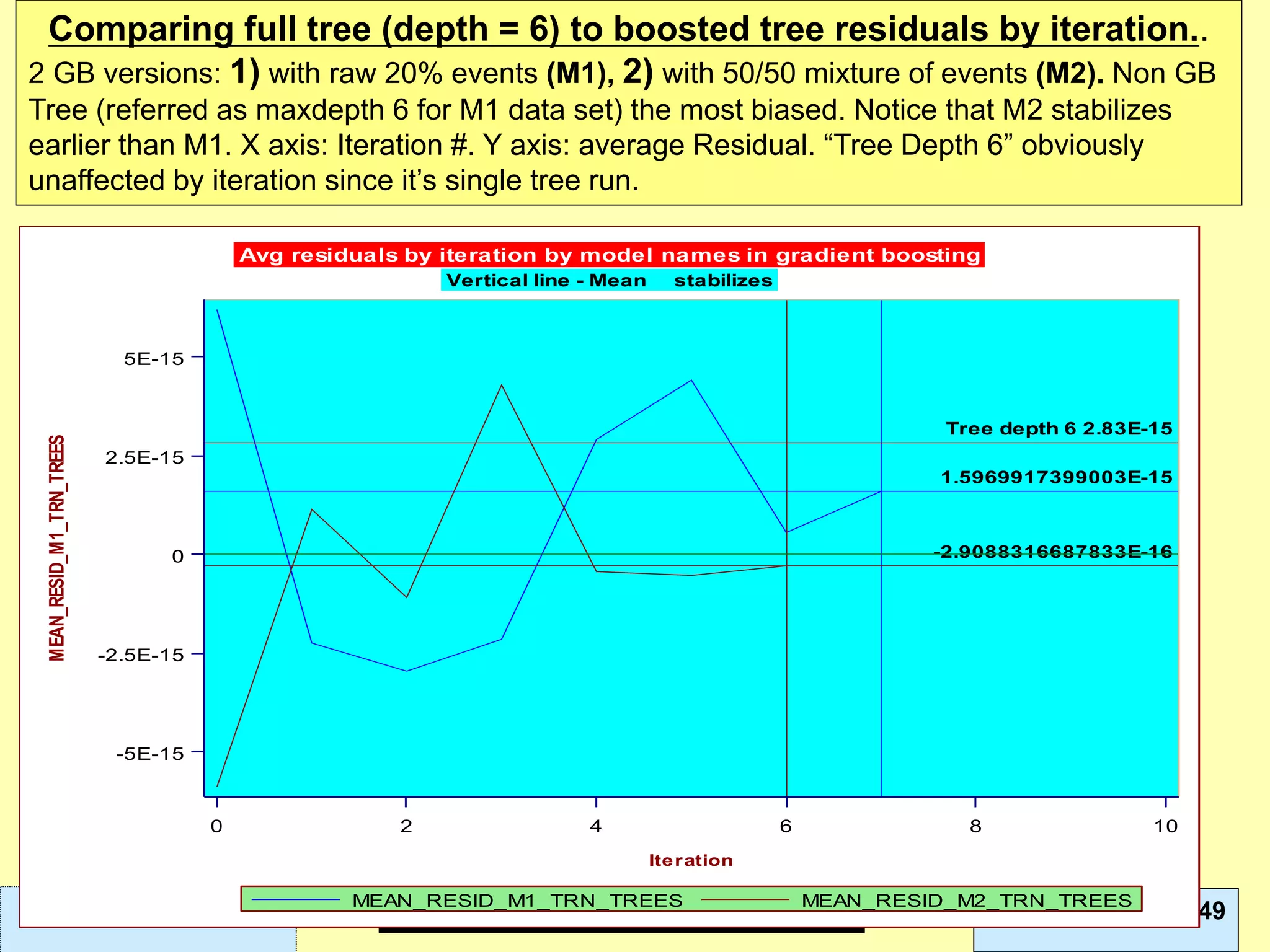
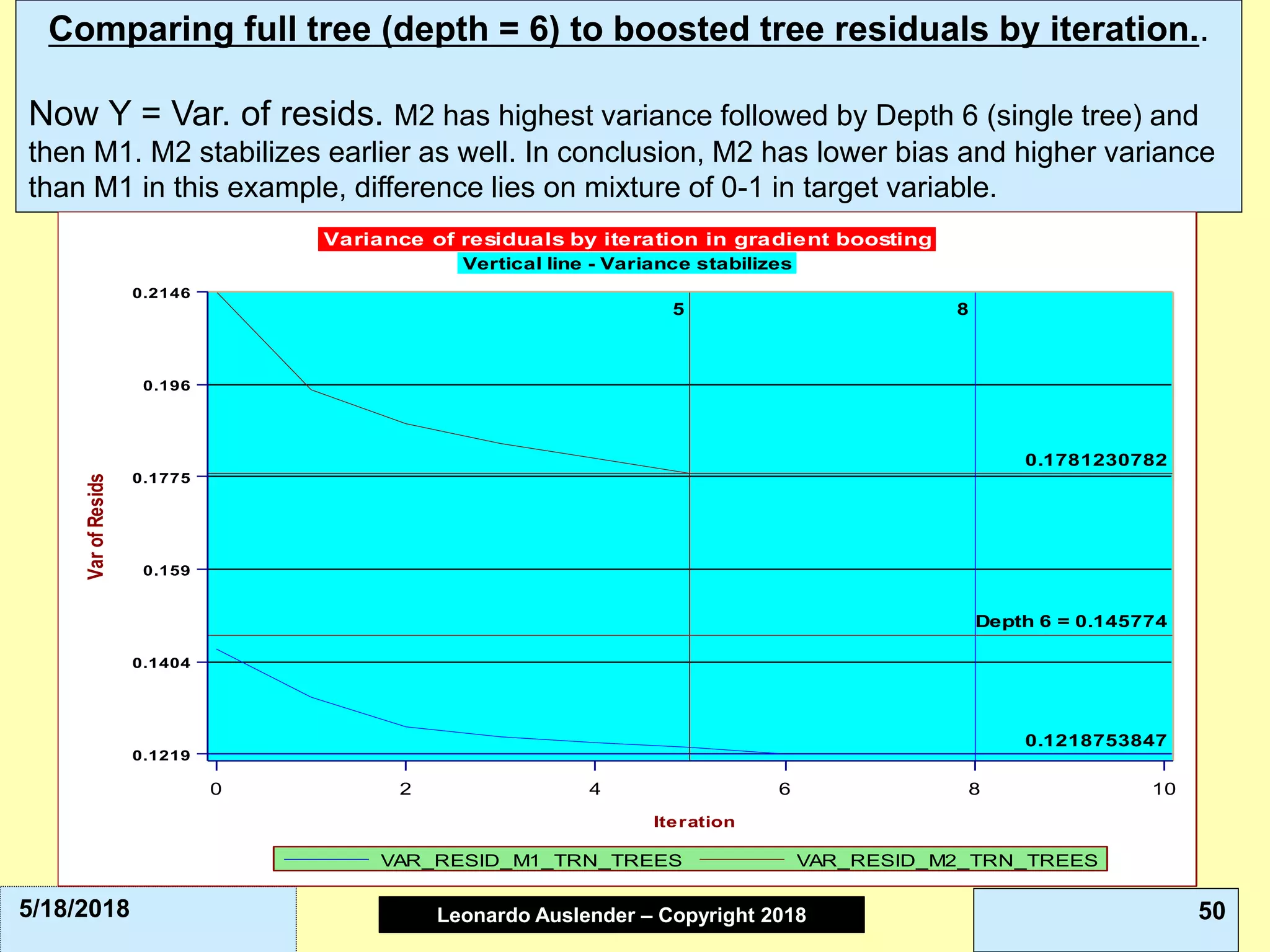



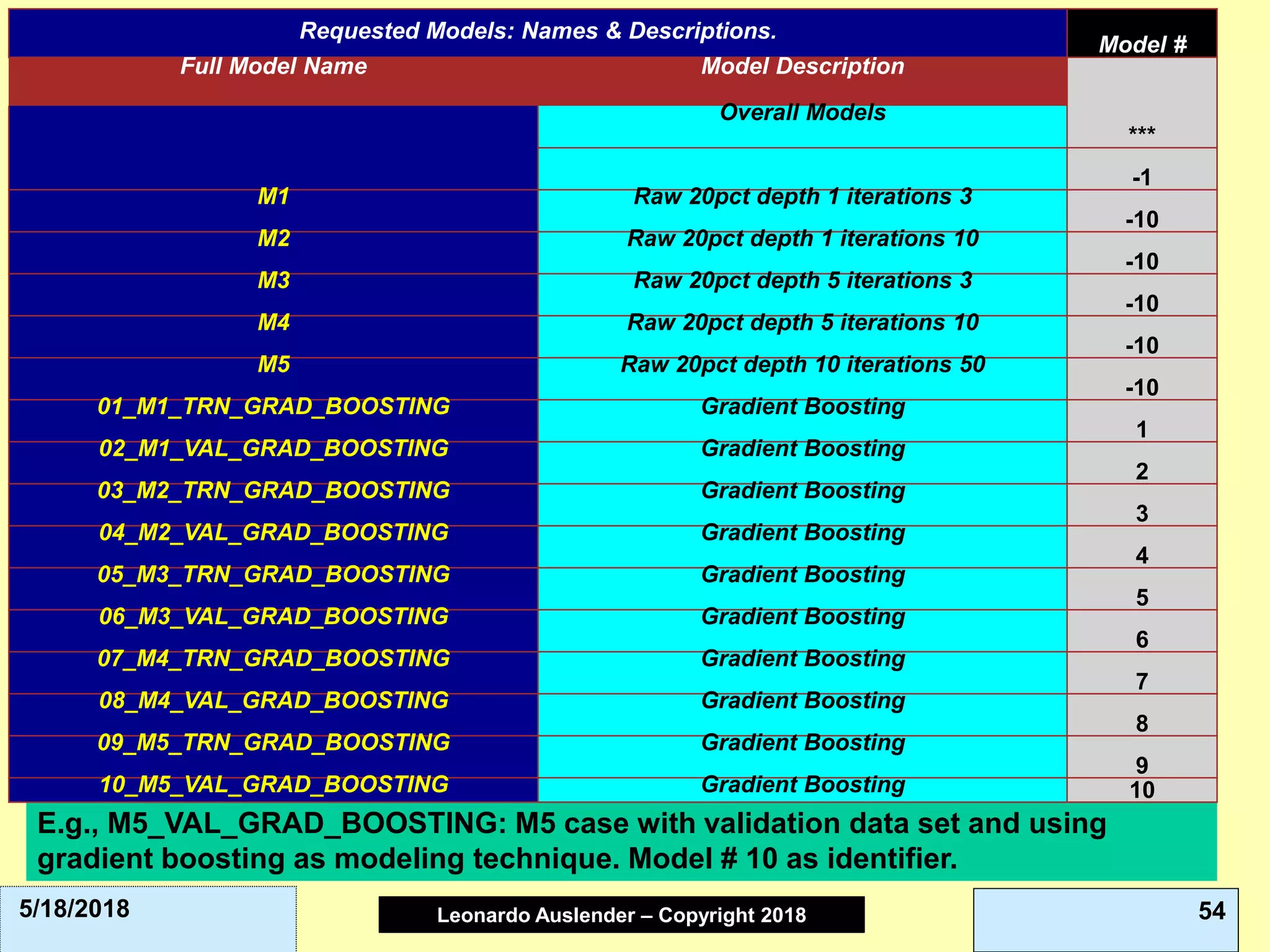

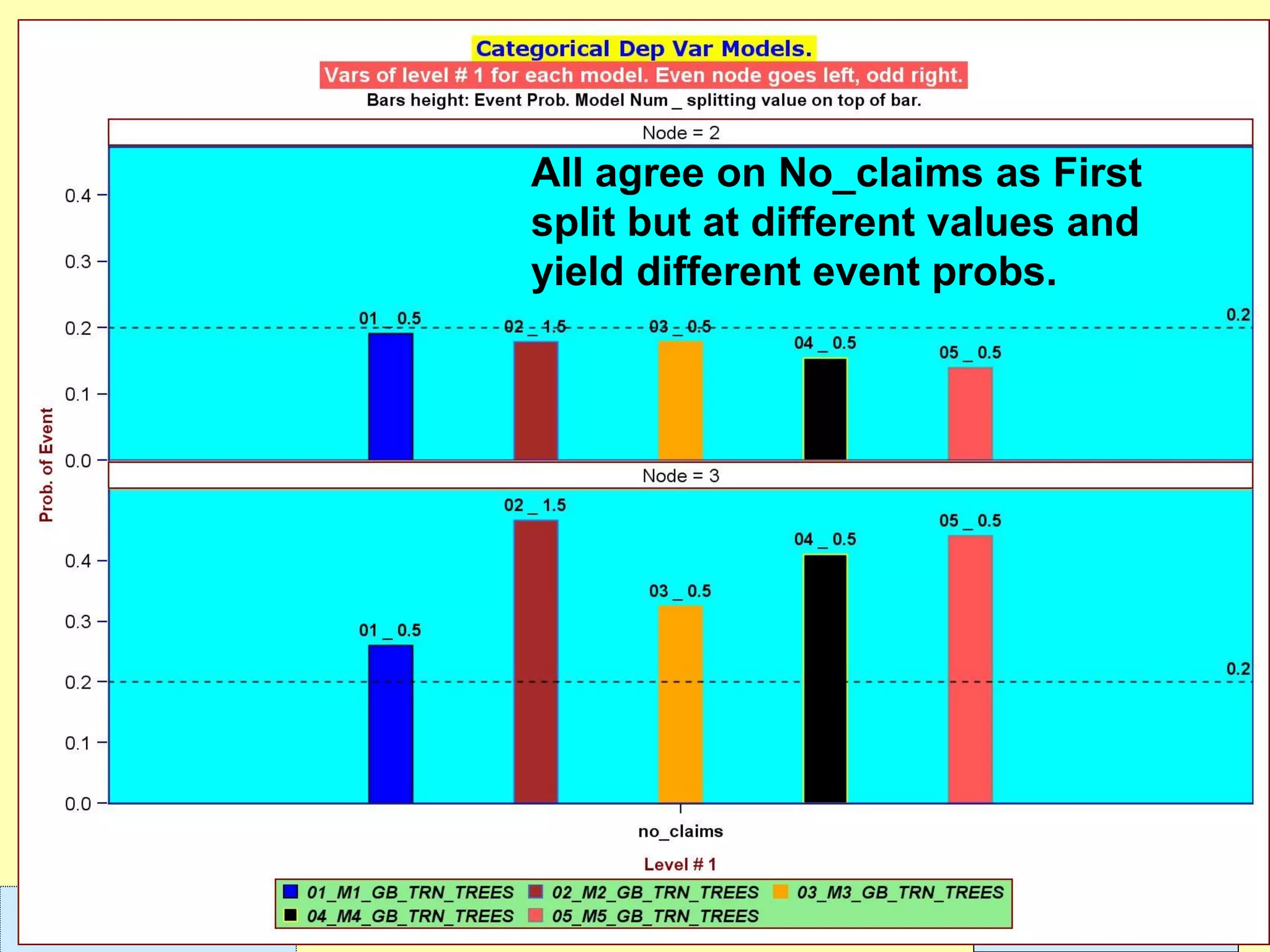
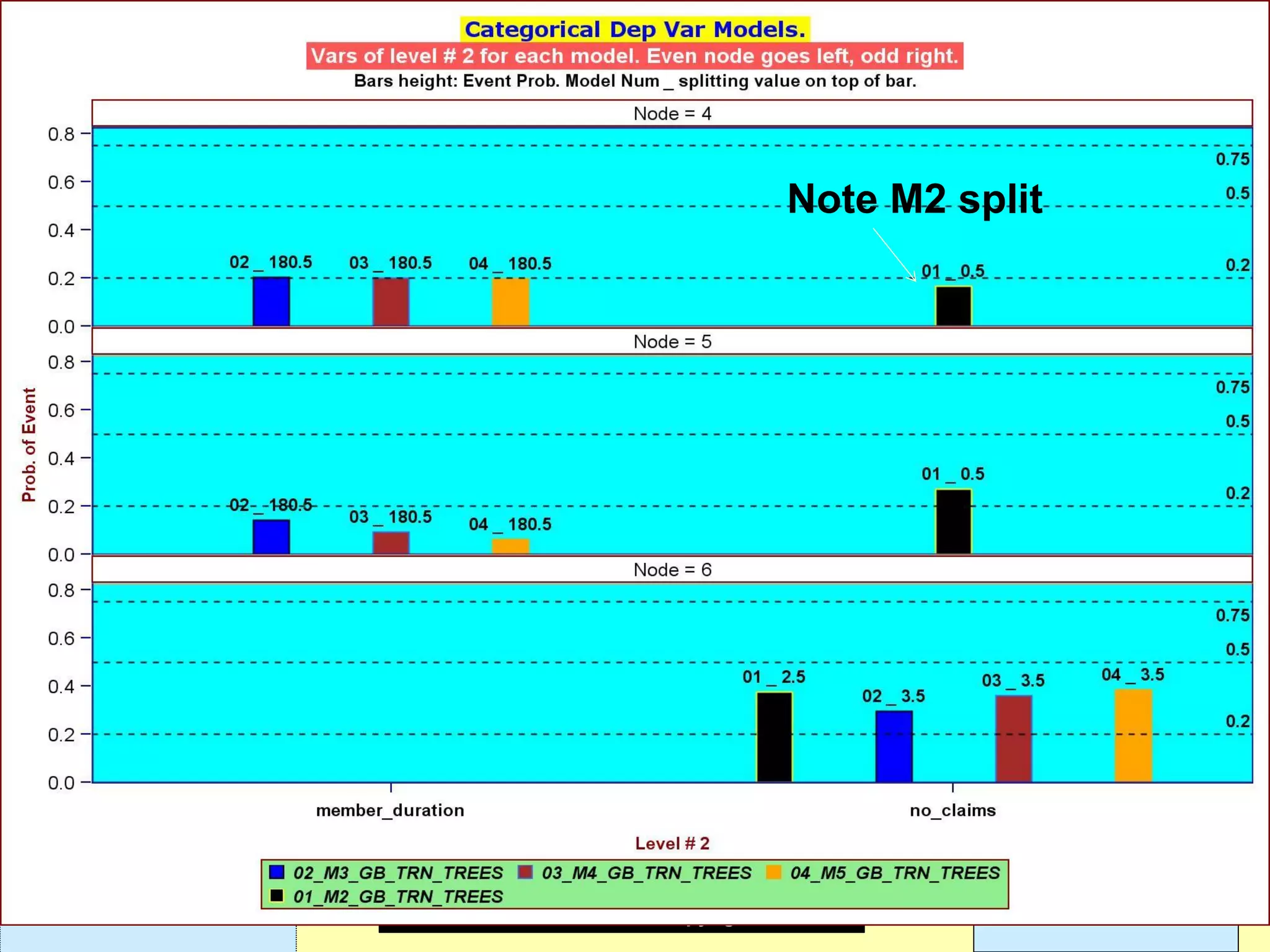


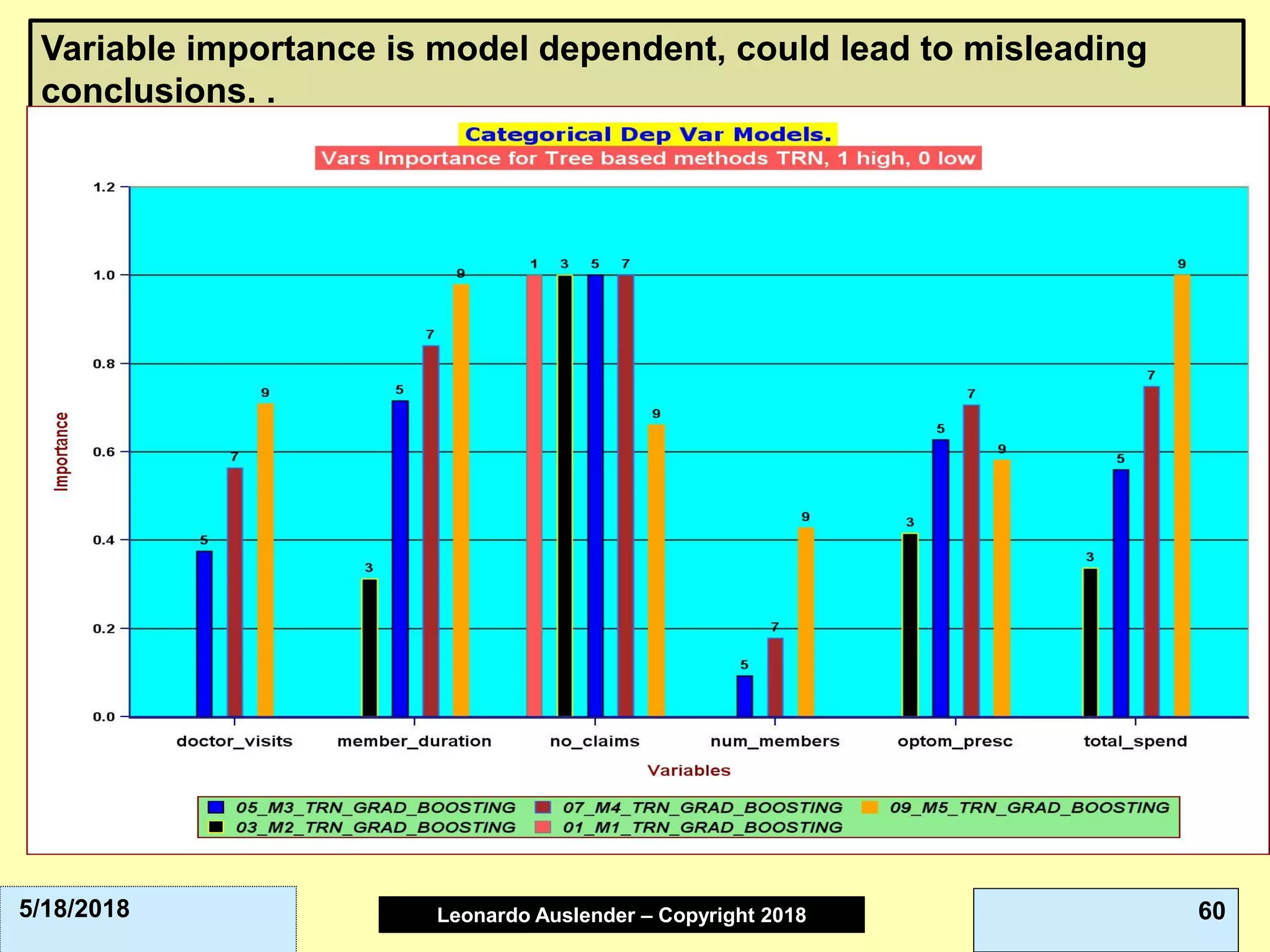
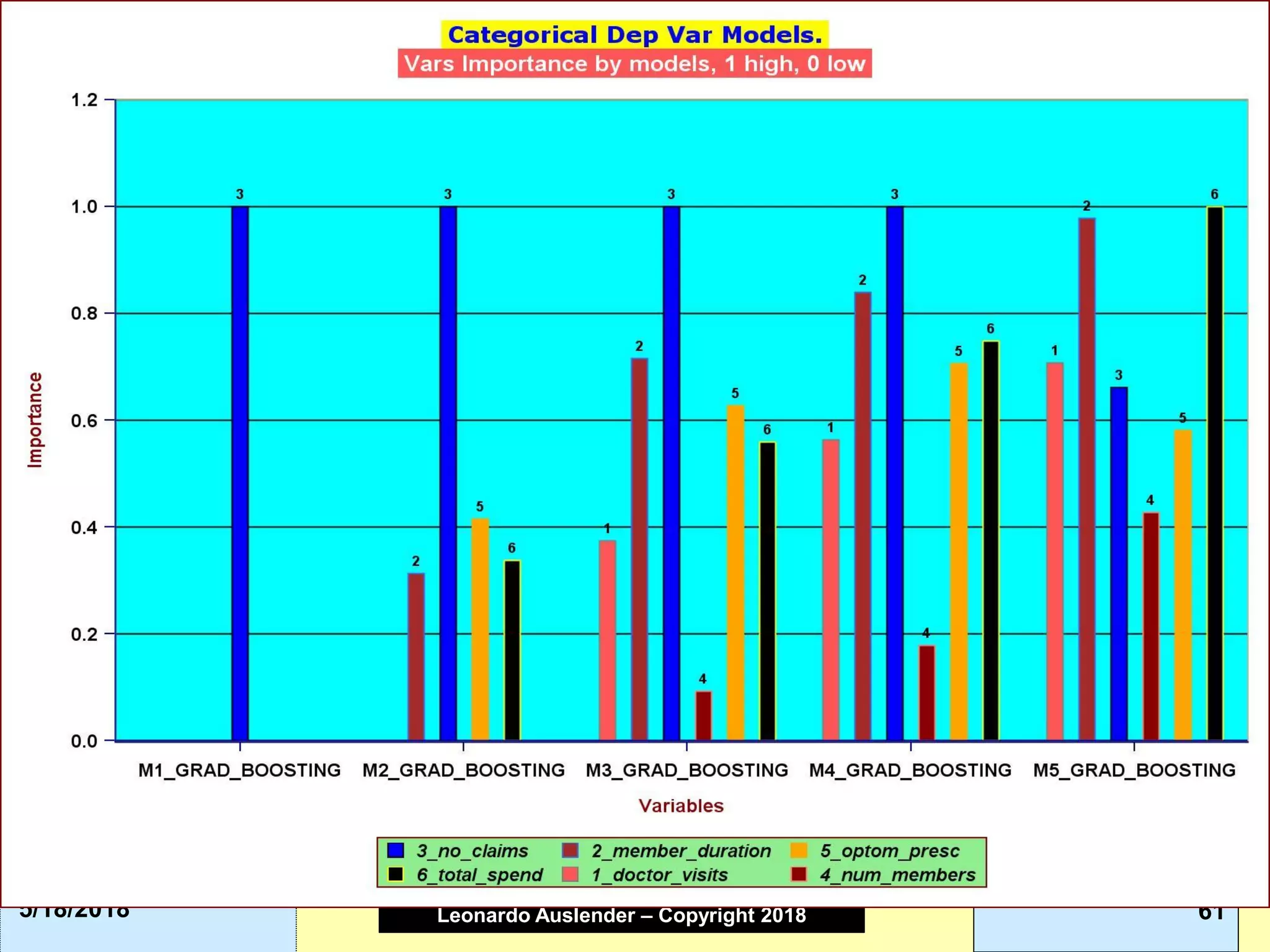

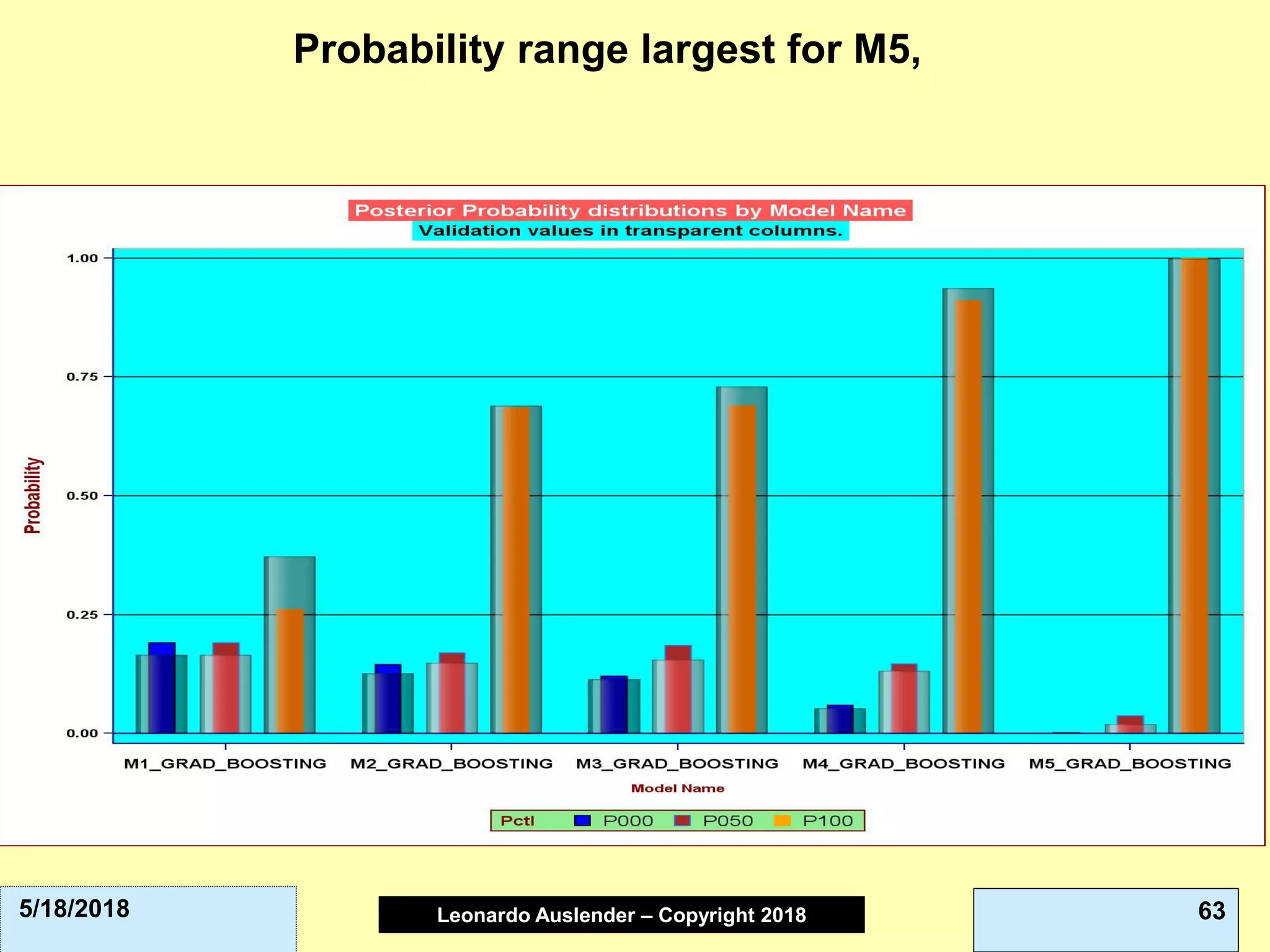
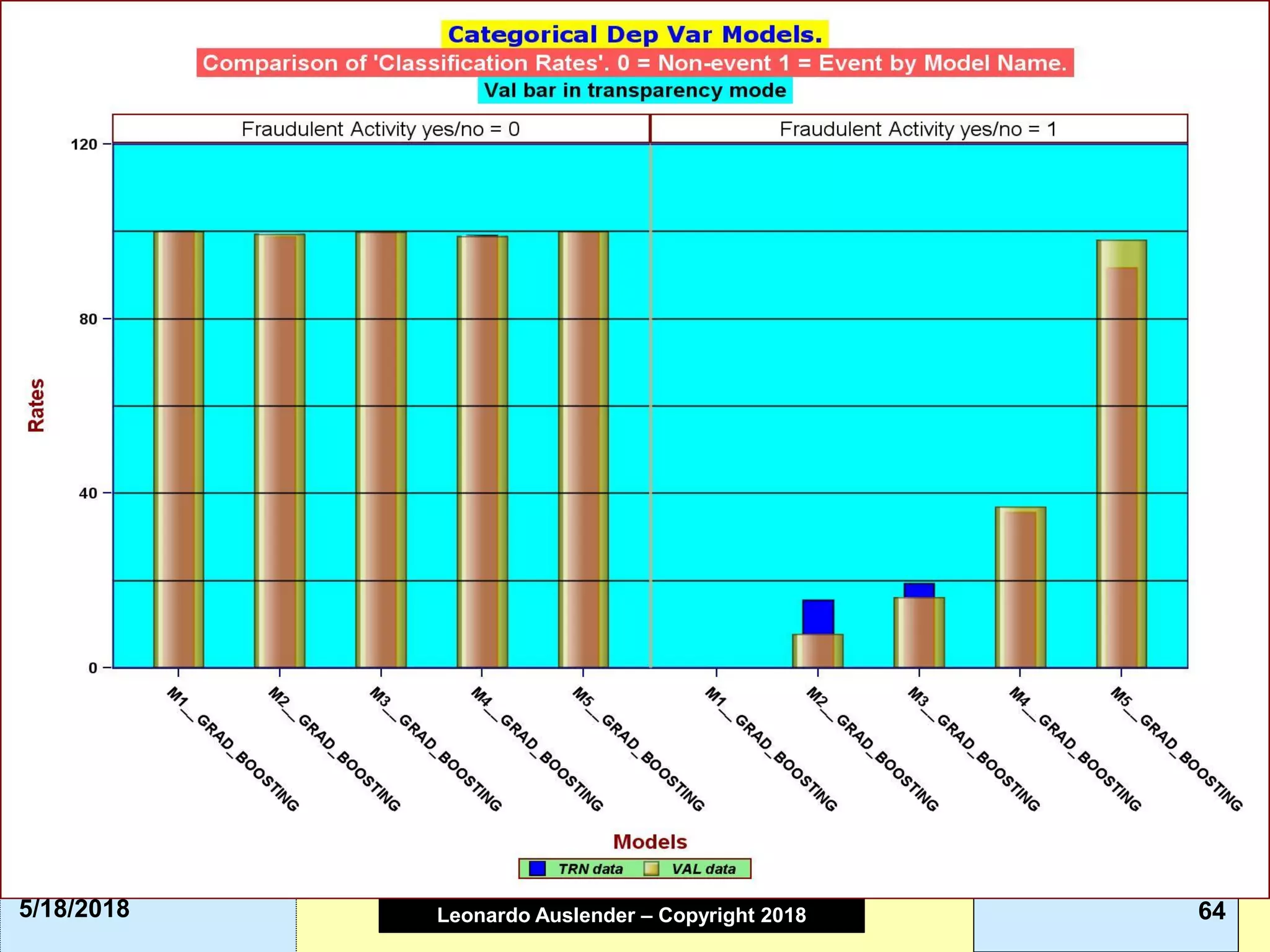
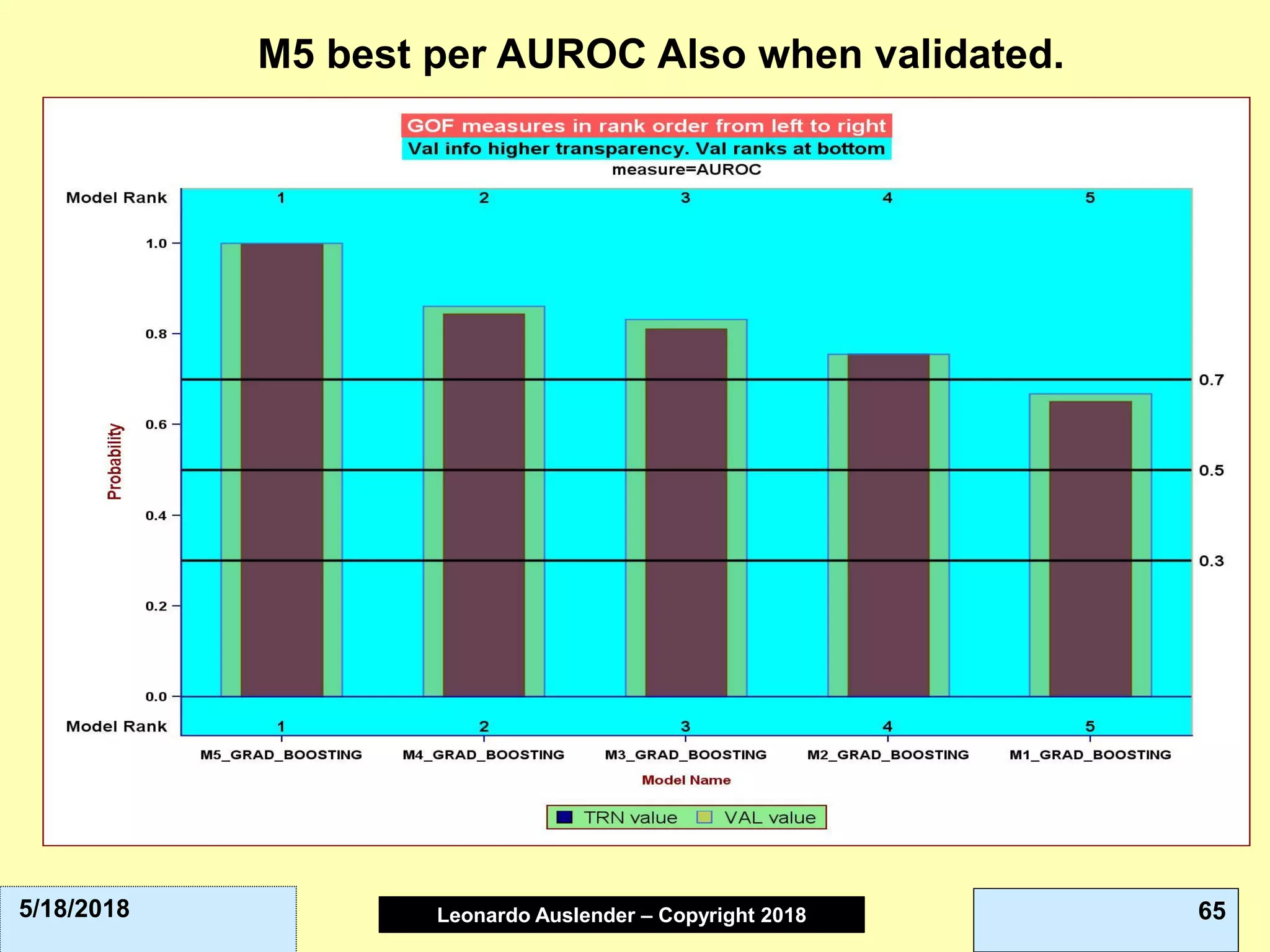
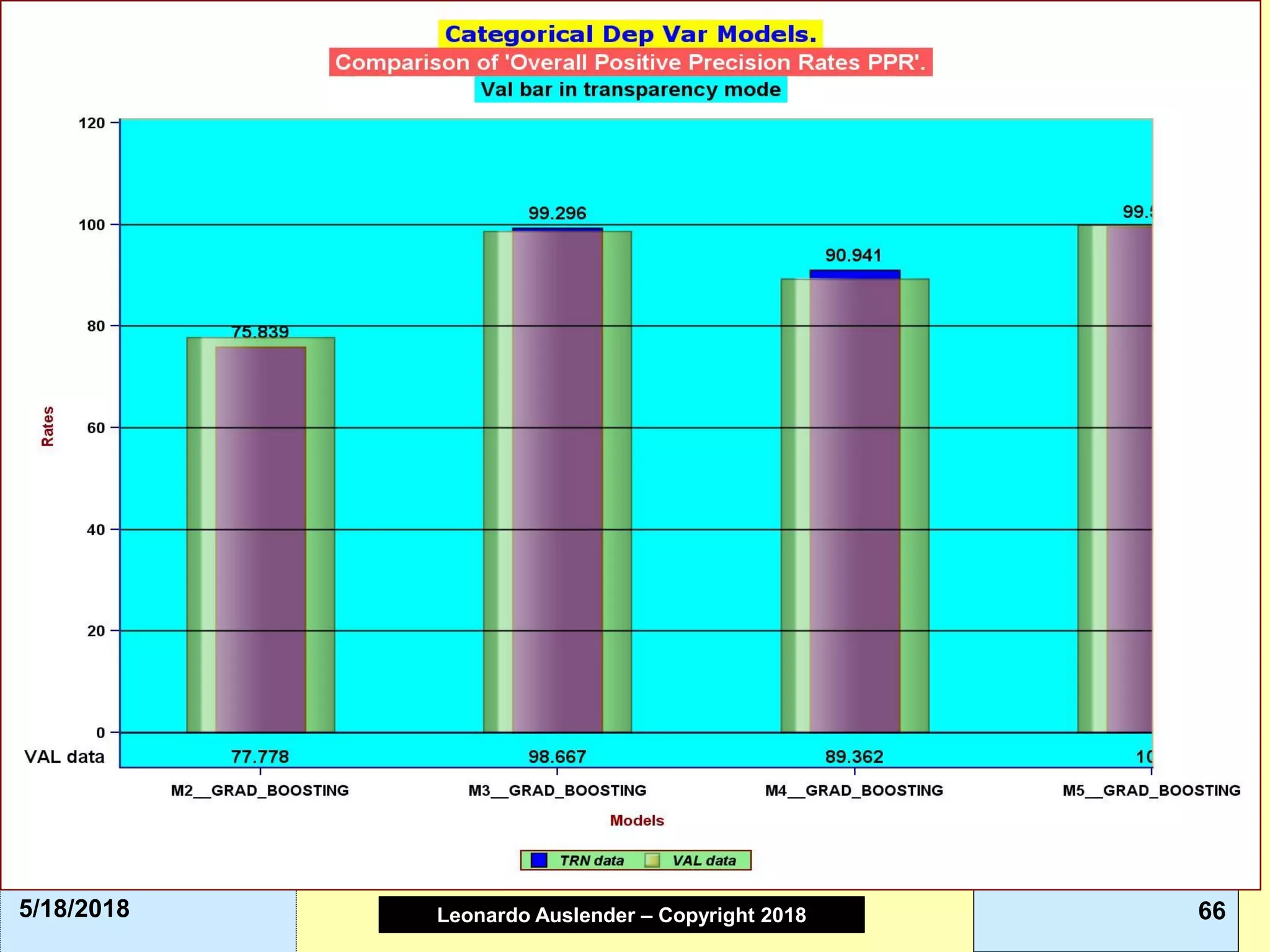
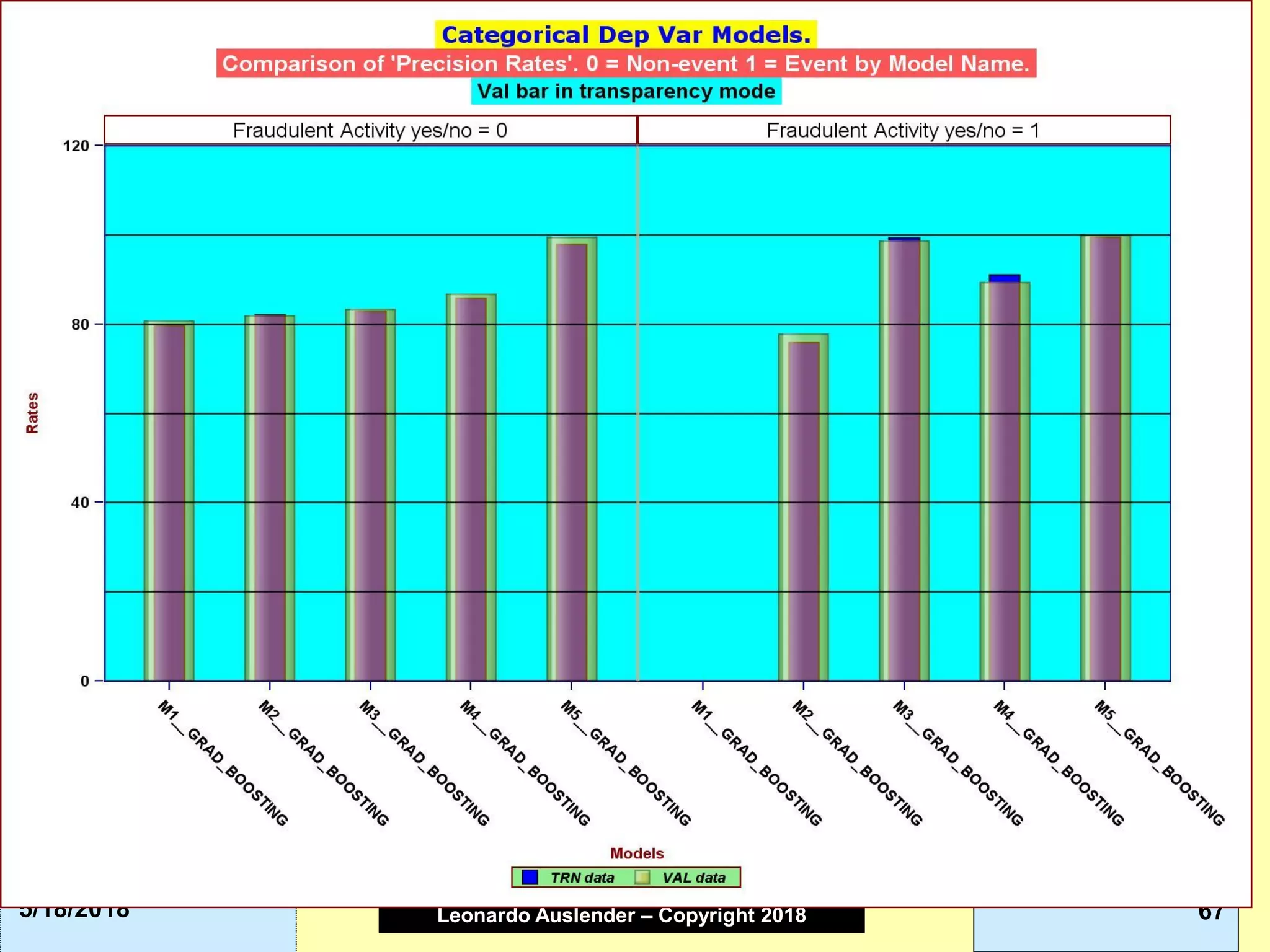

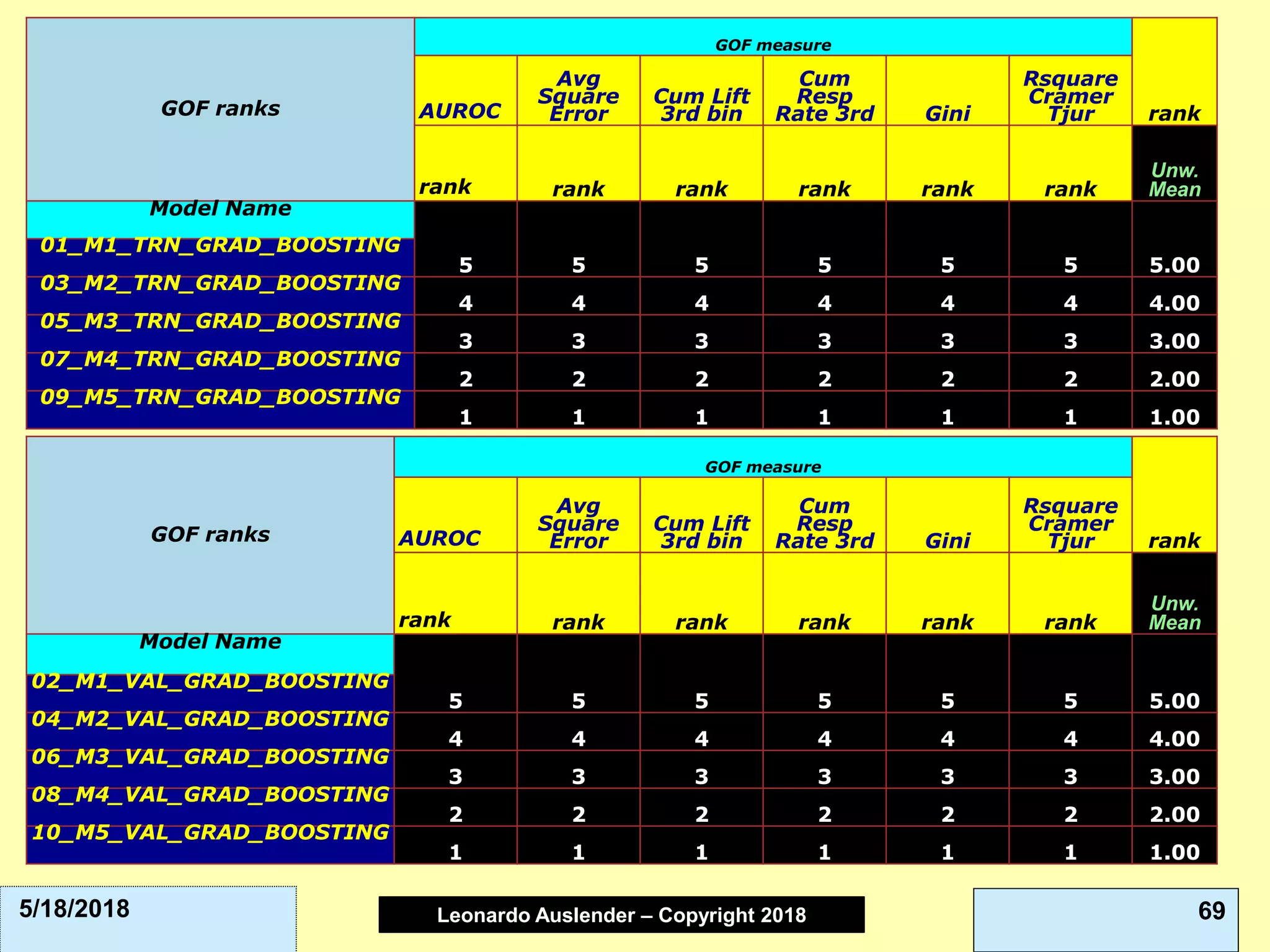

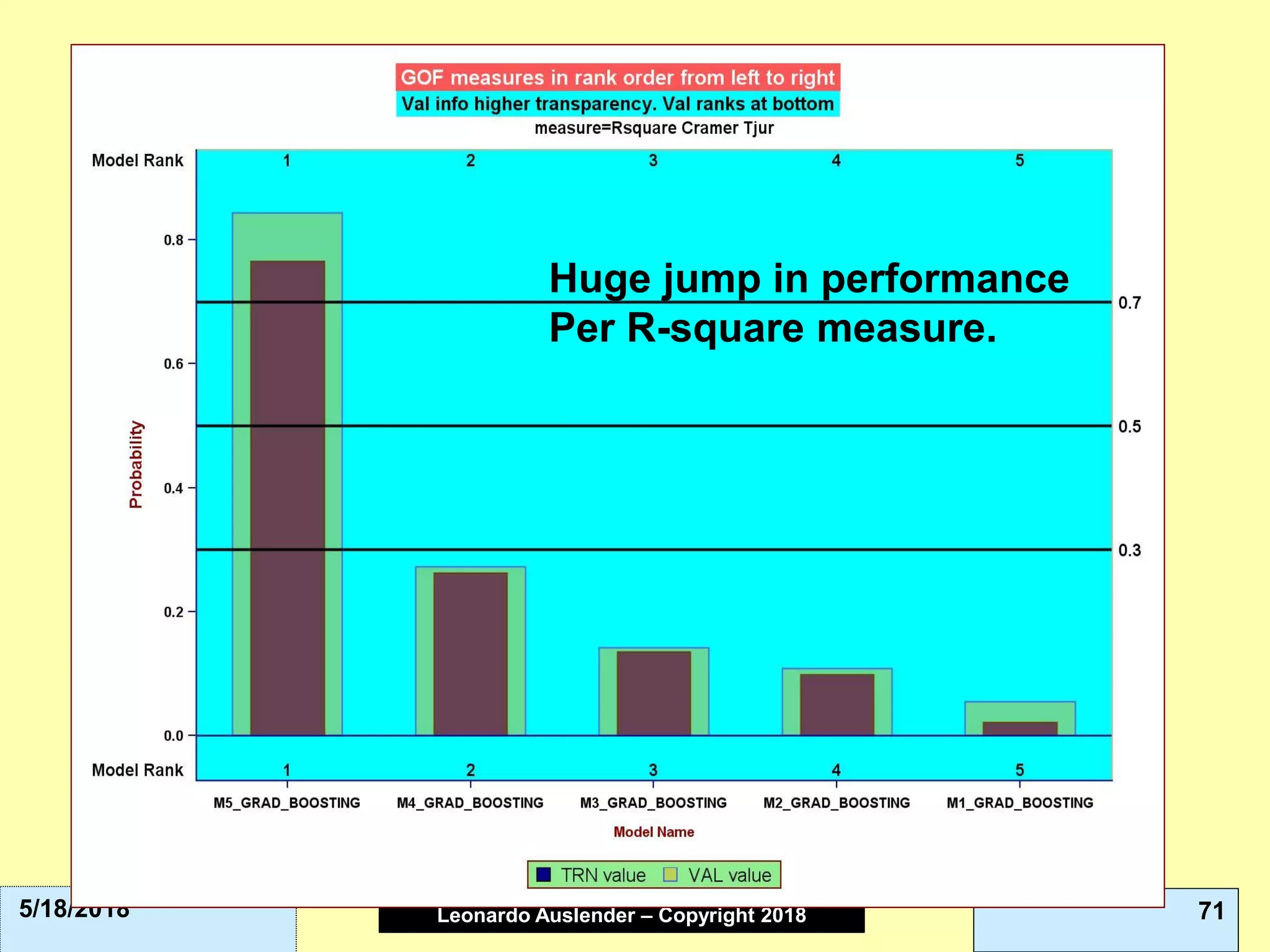
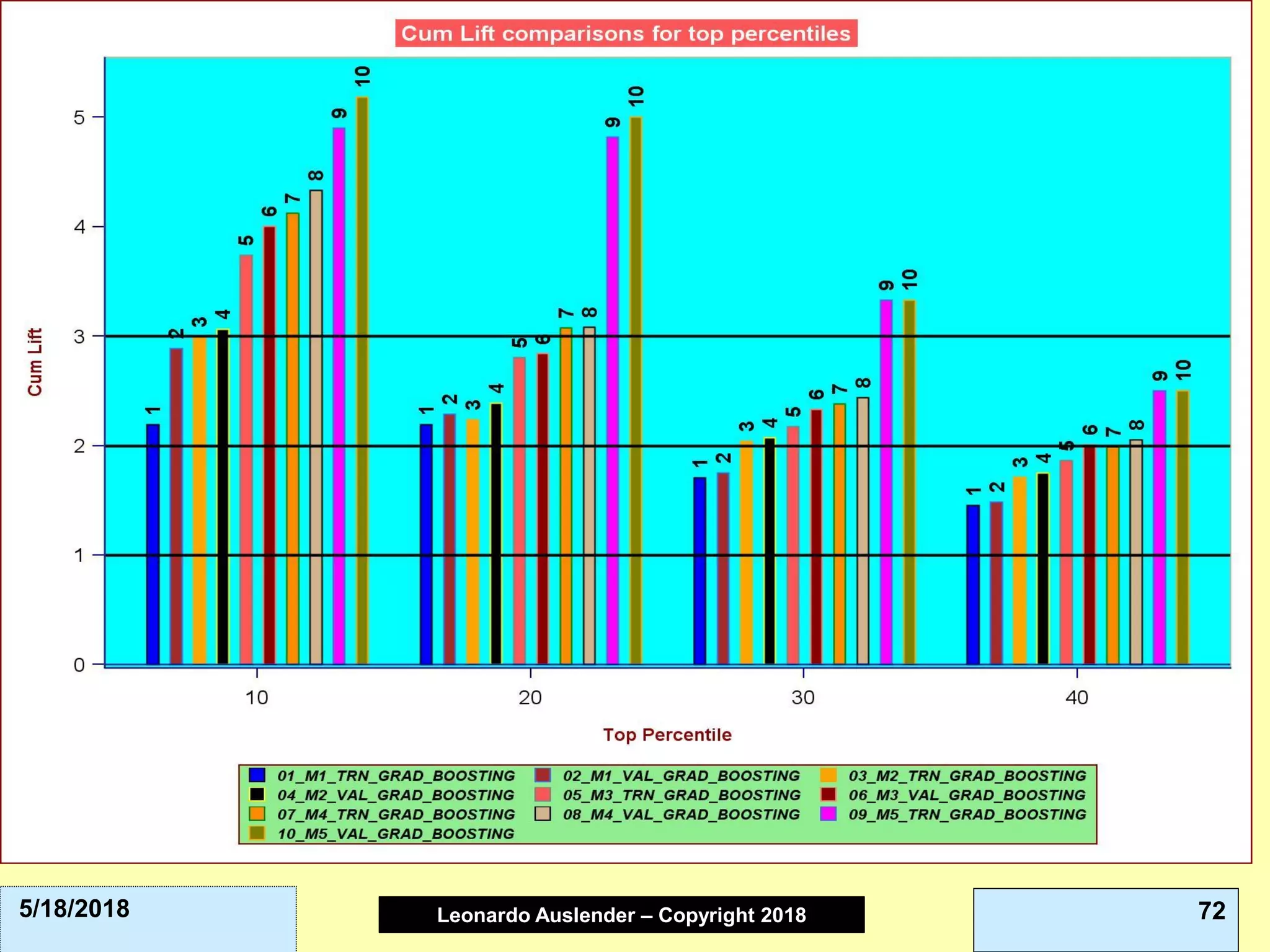







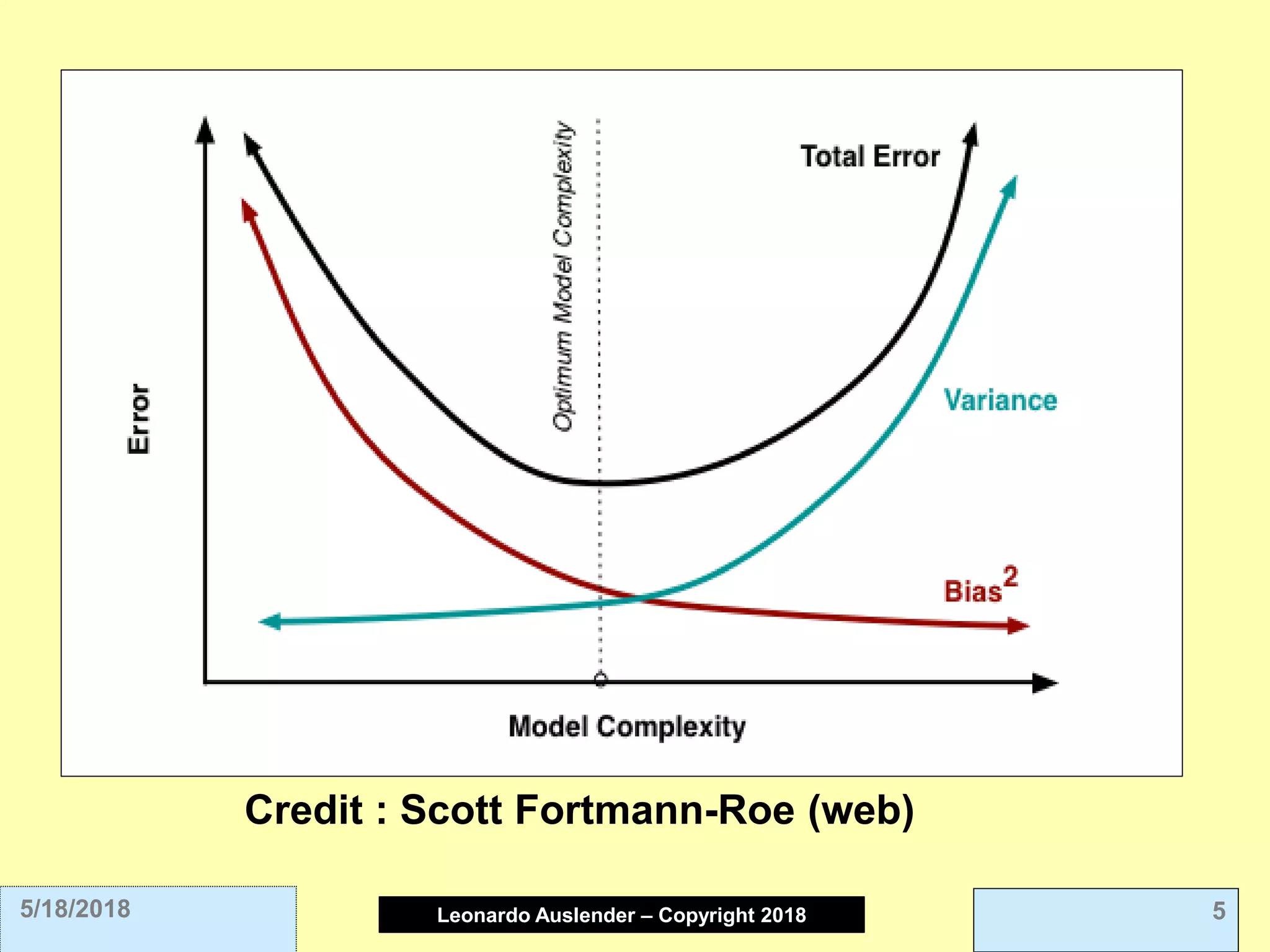
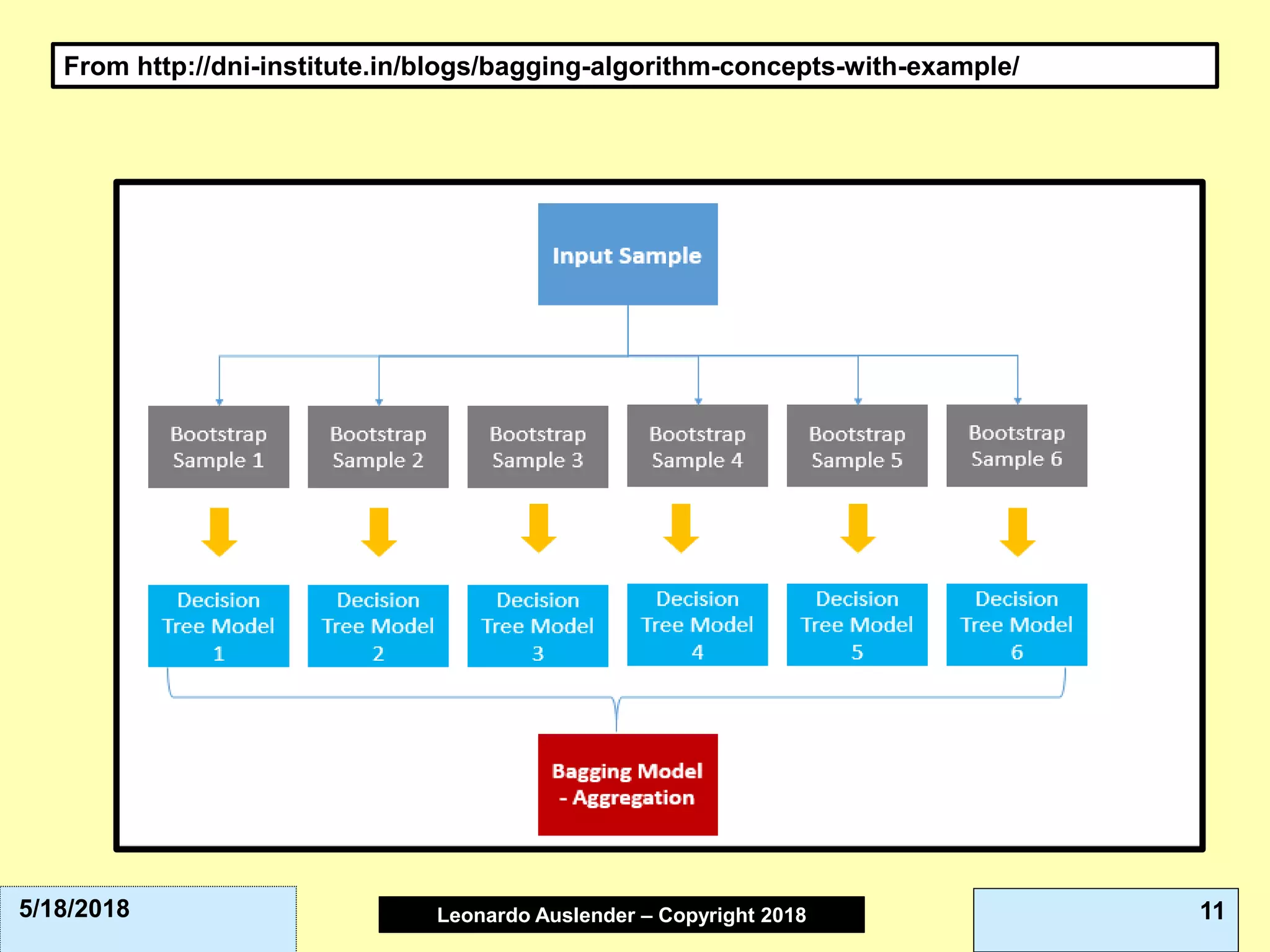
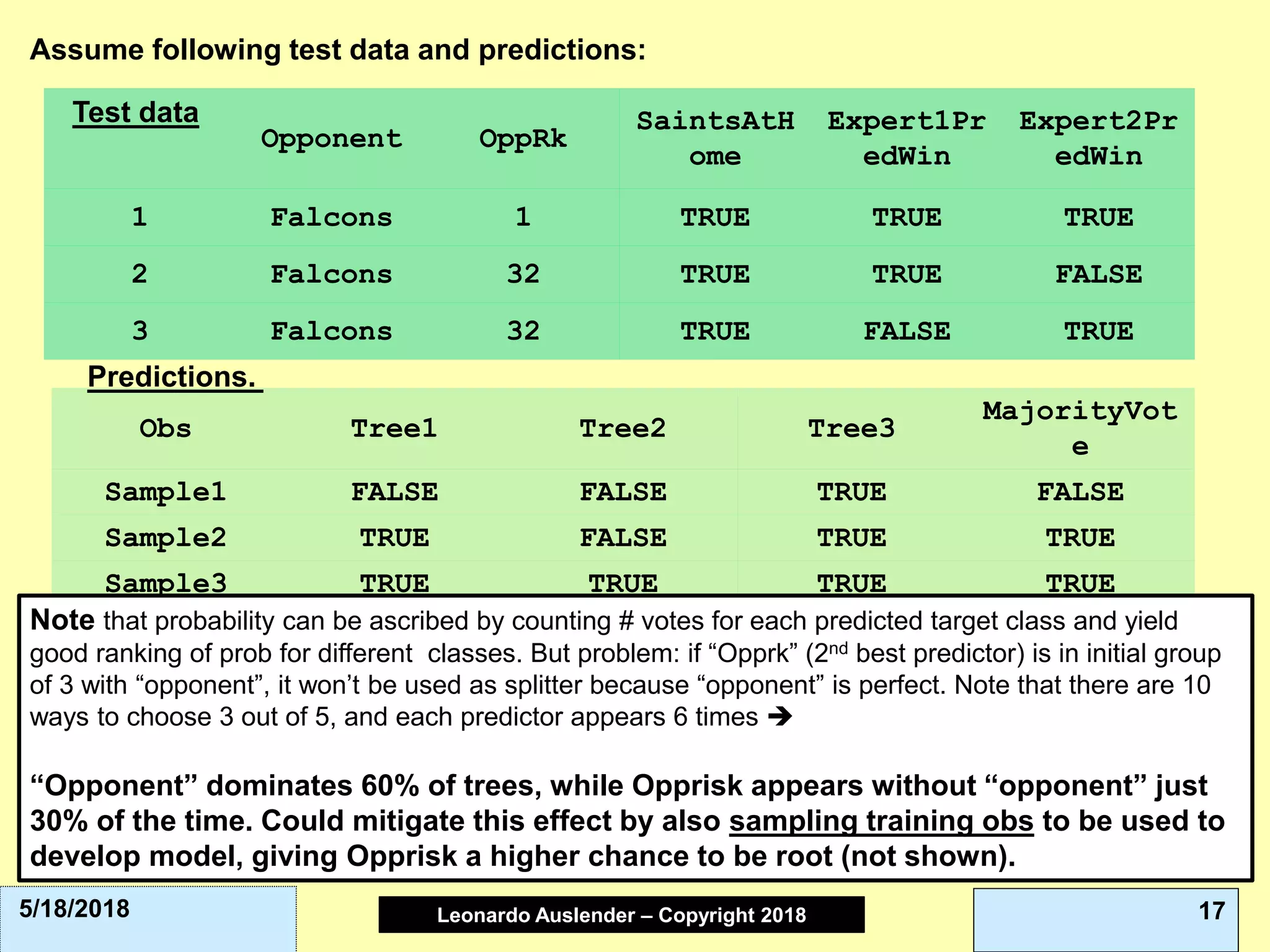
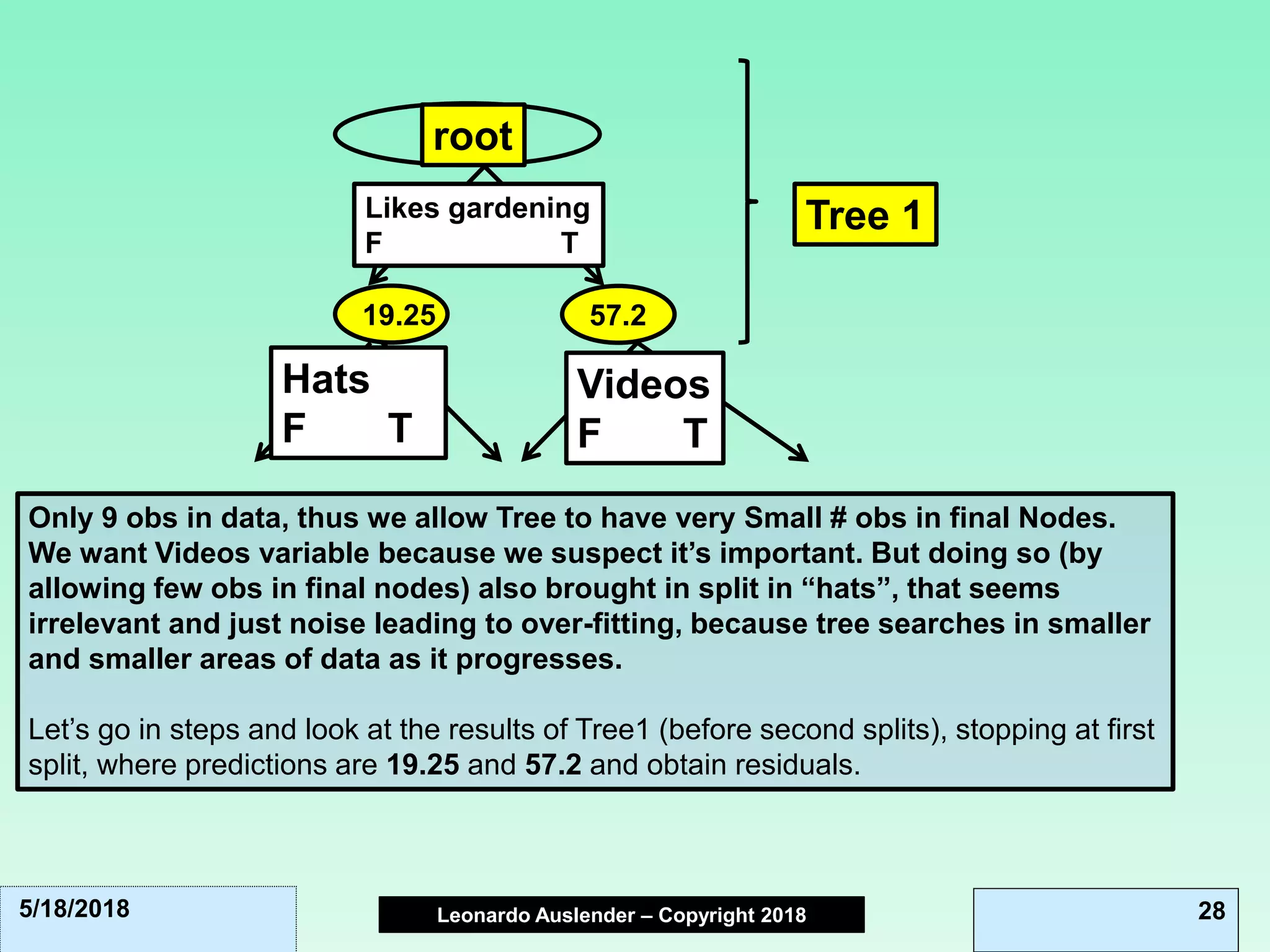
This document discusses ensemble methods and gradient boosting. It covers topics such as the bias-variance tradeoff, bagging, stacking, random forests, gradient boosting, and XGBoost. For random forests, it explains how they work by growing many decision trees on randomly sampled data and combining their predictions. It also discusses how random forests avoid overfitting and use out-of-bag samples to estimate generalization error.



































































