Download as PDF, PPTX


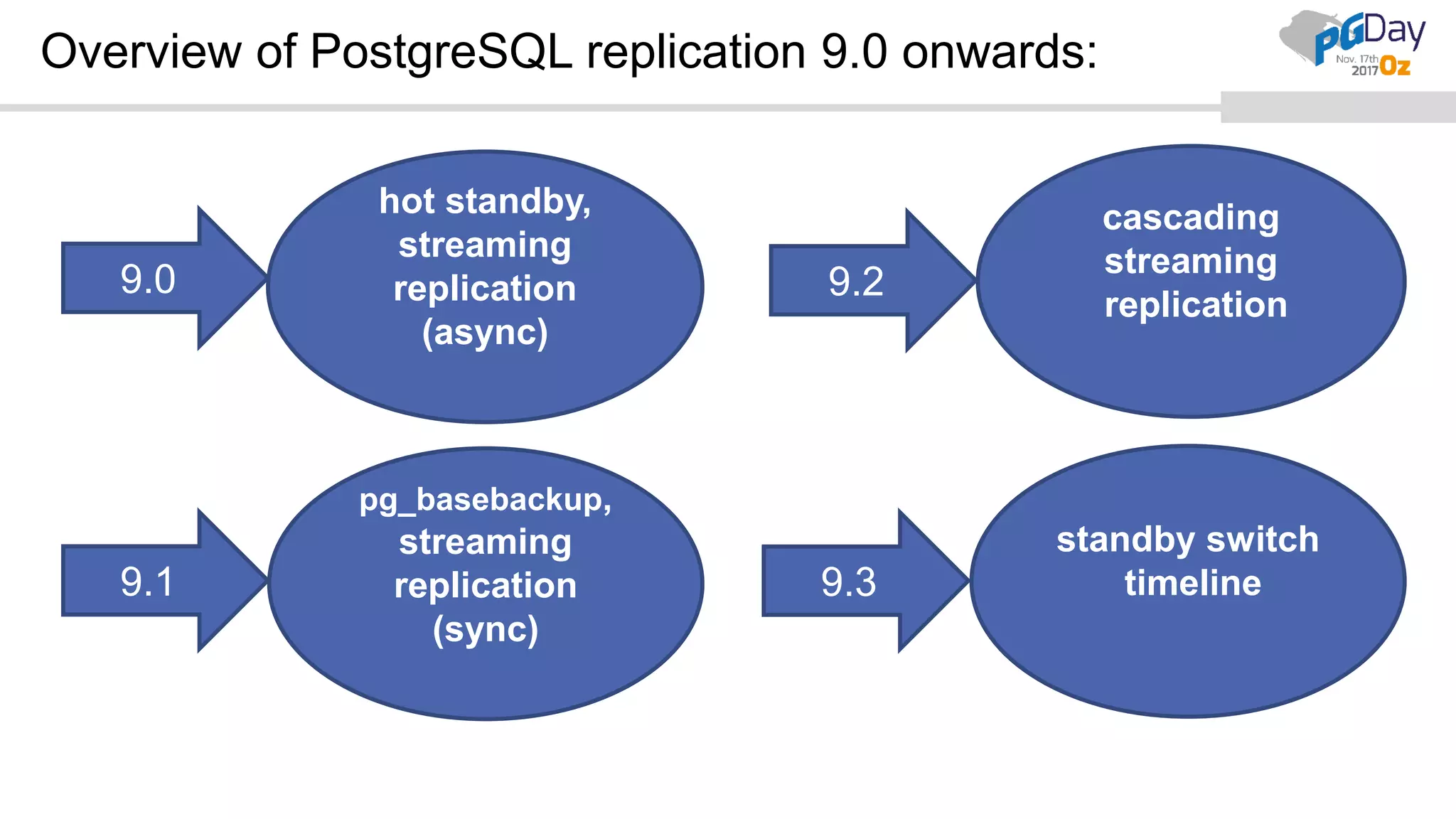
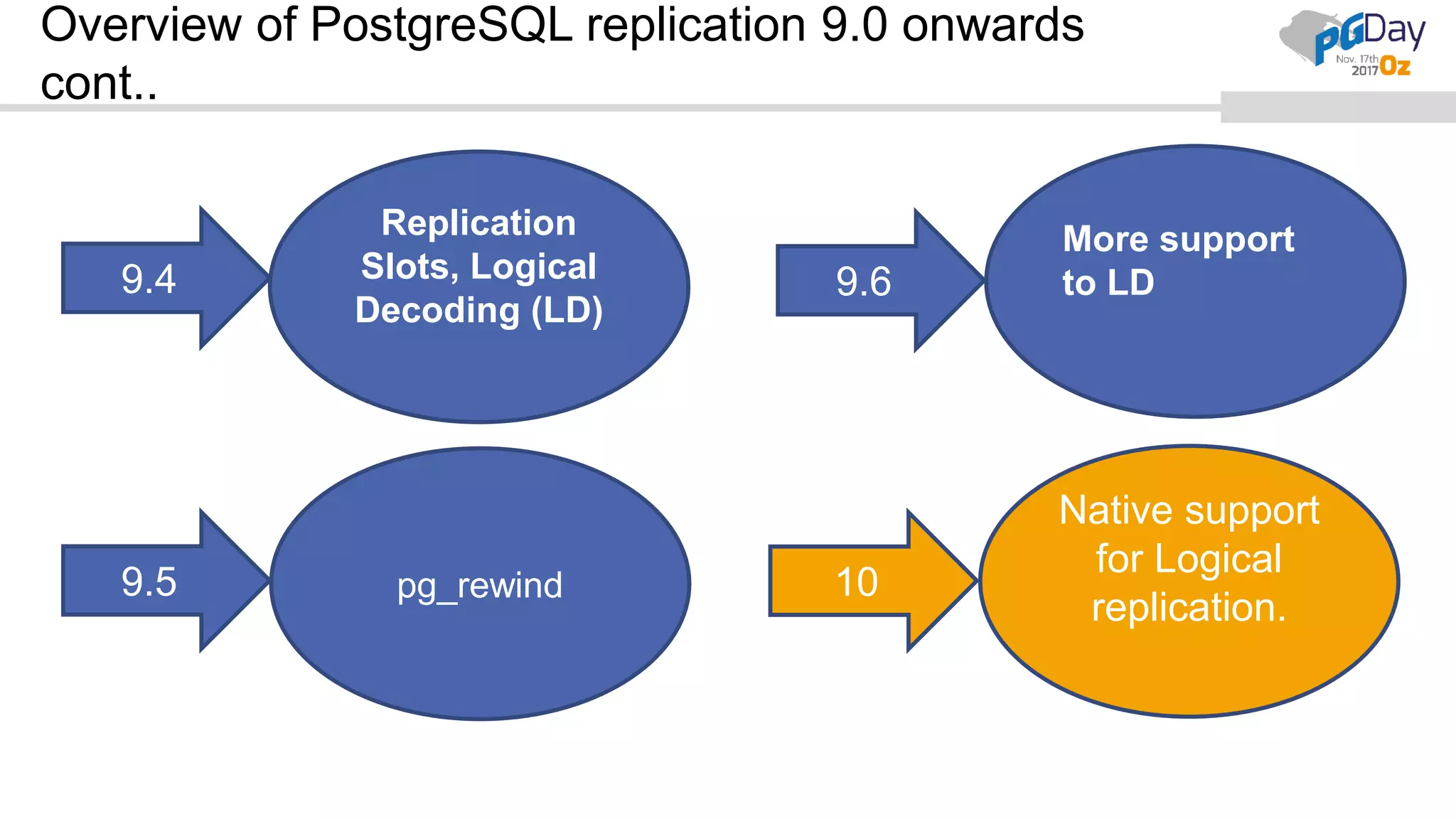


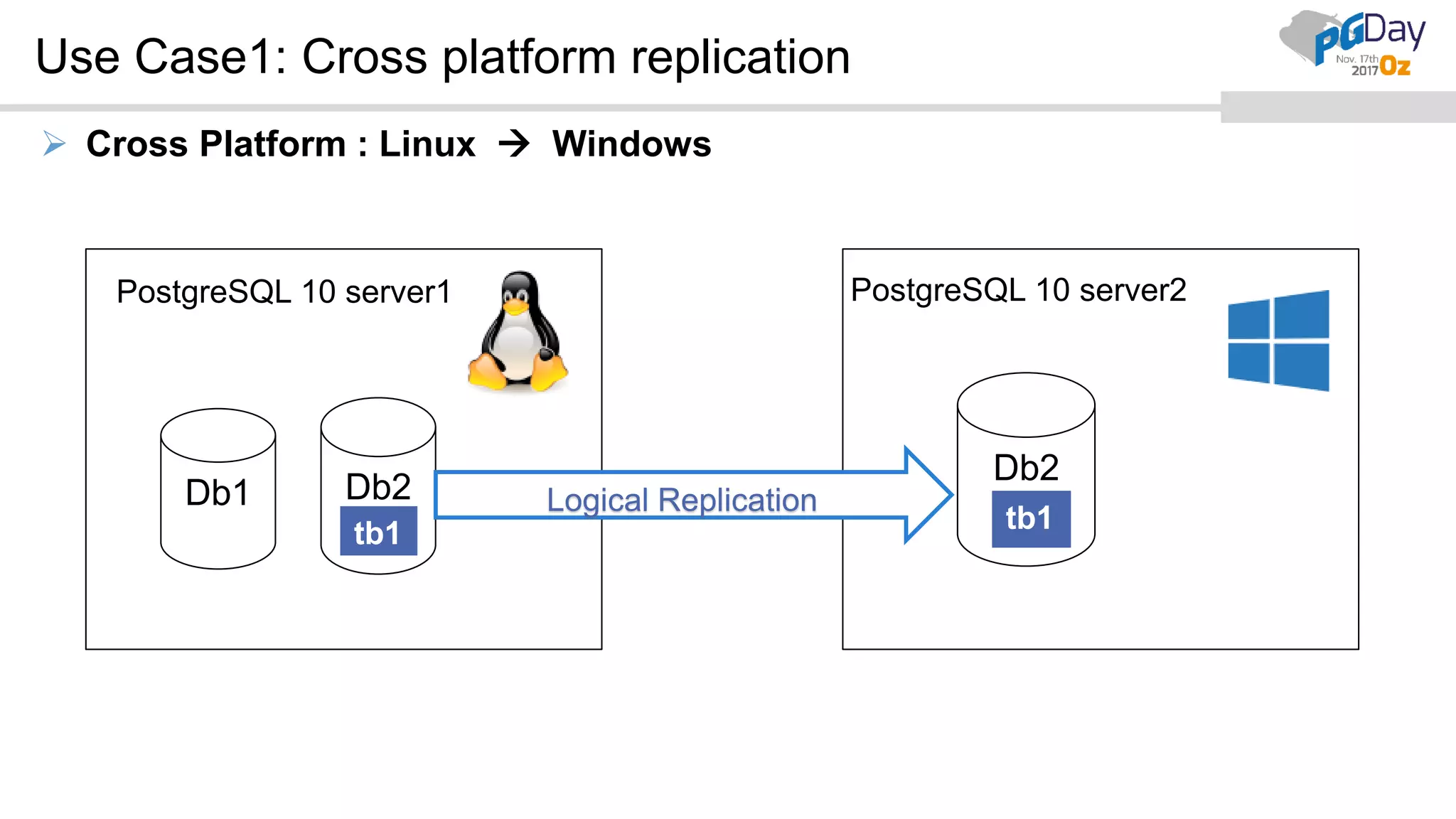
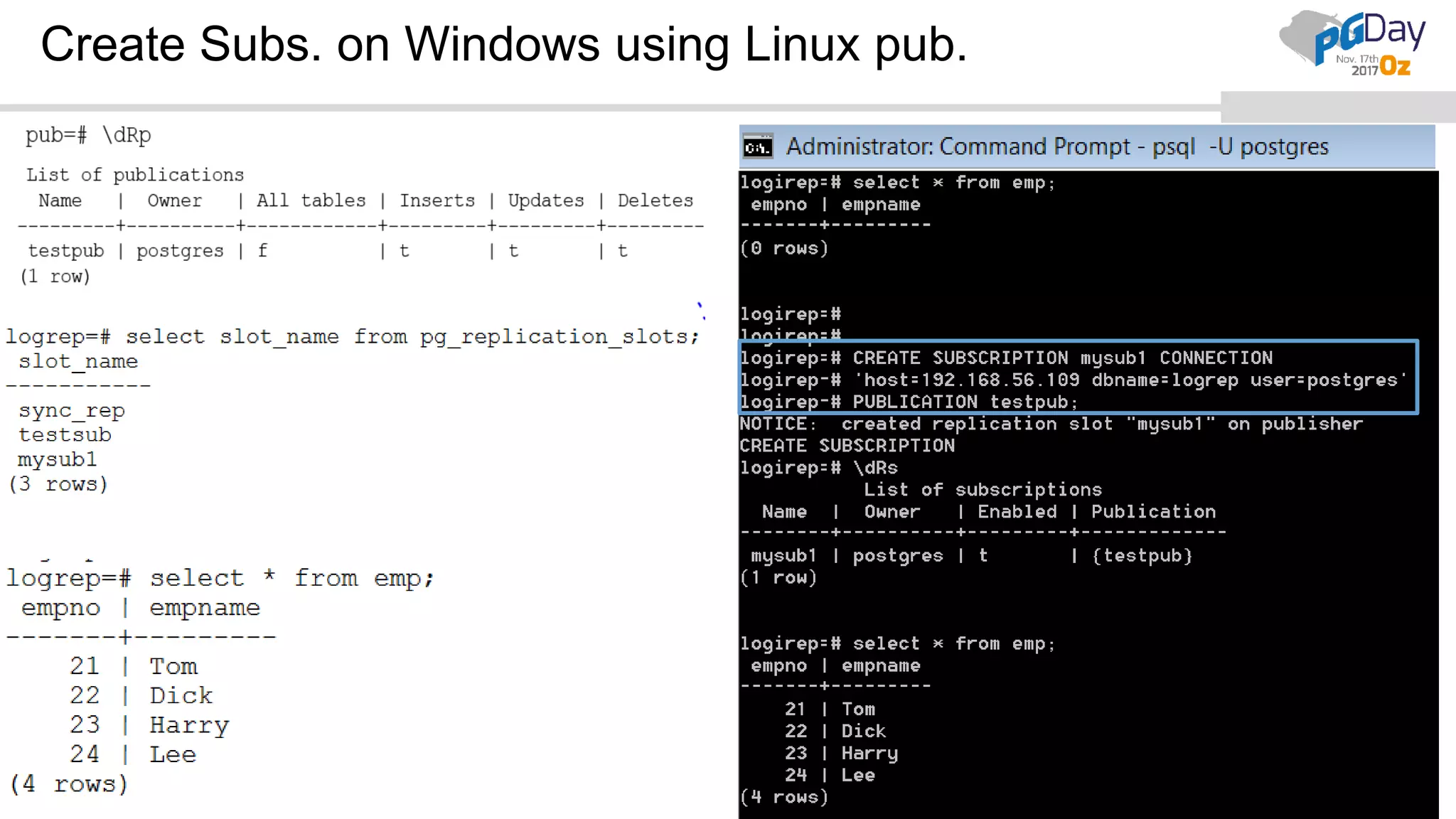
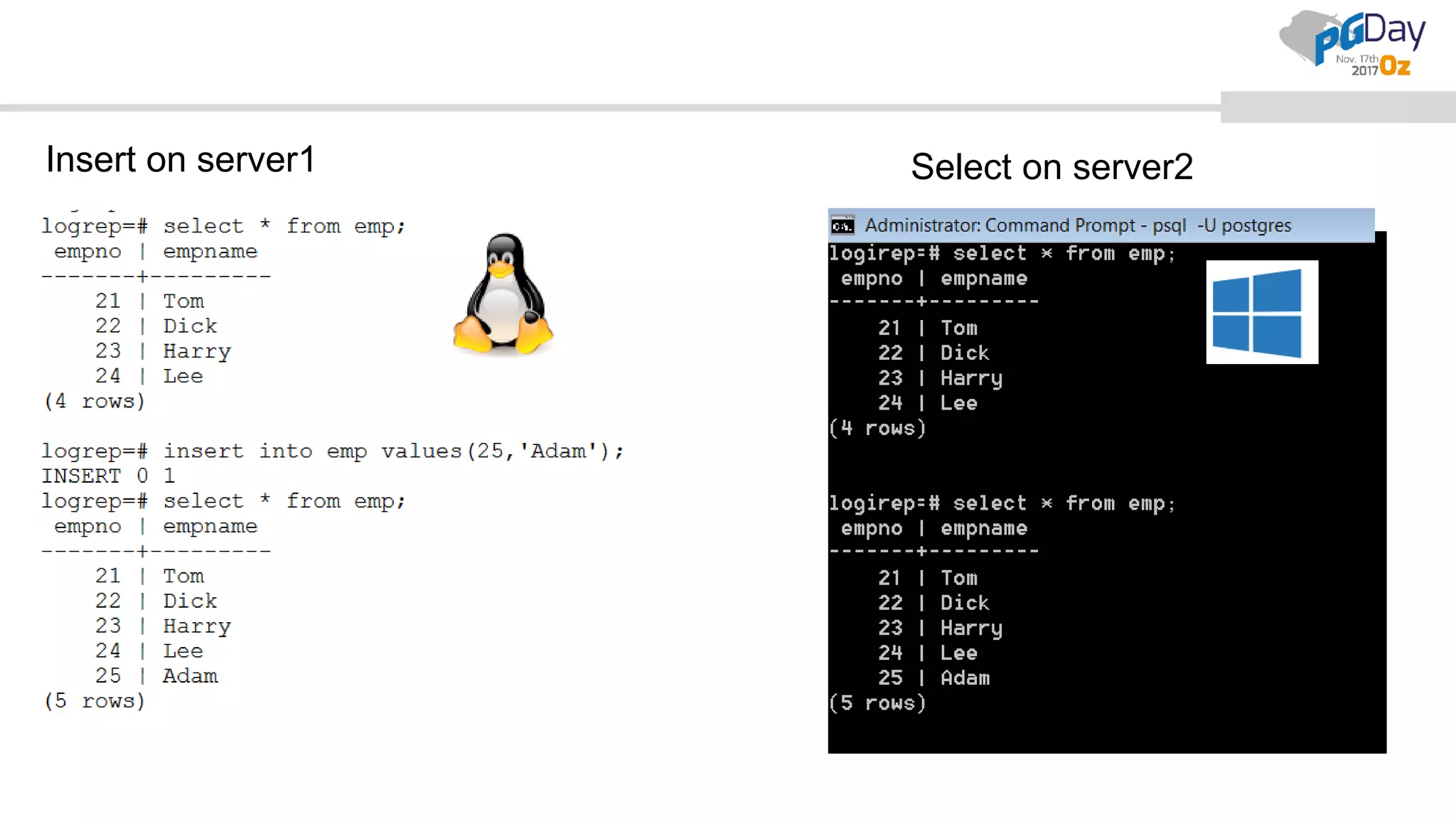
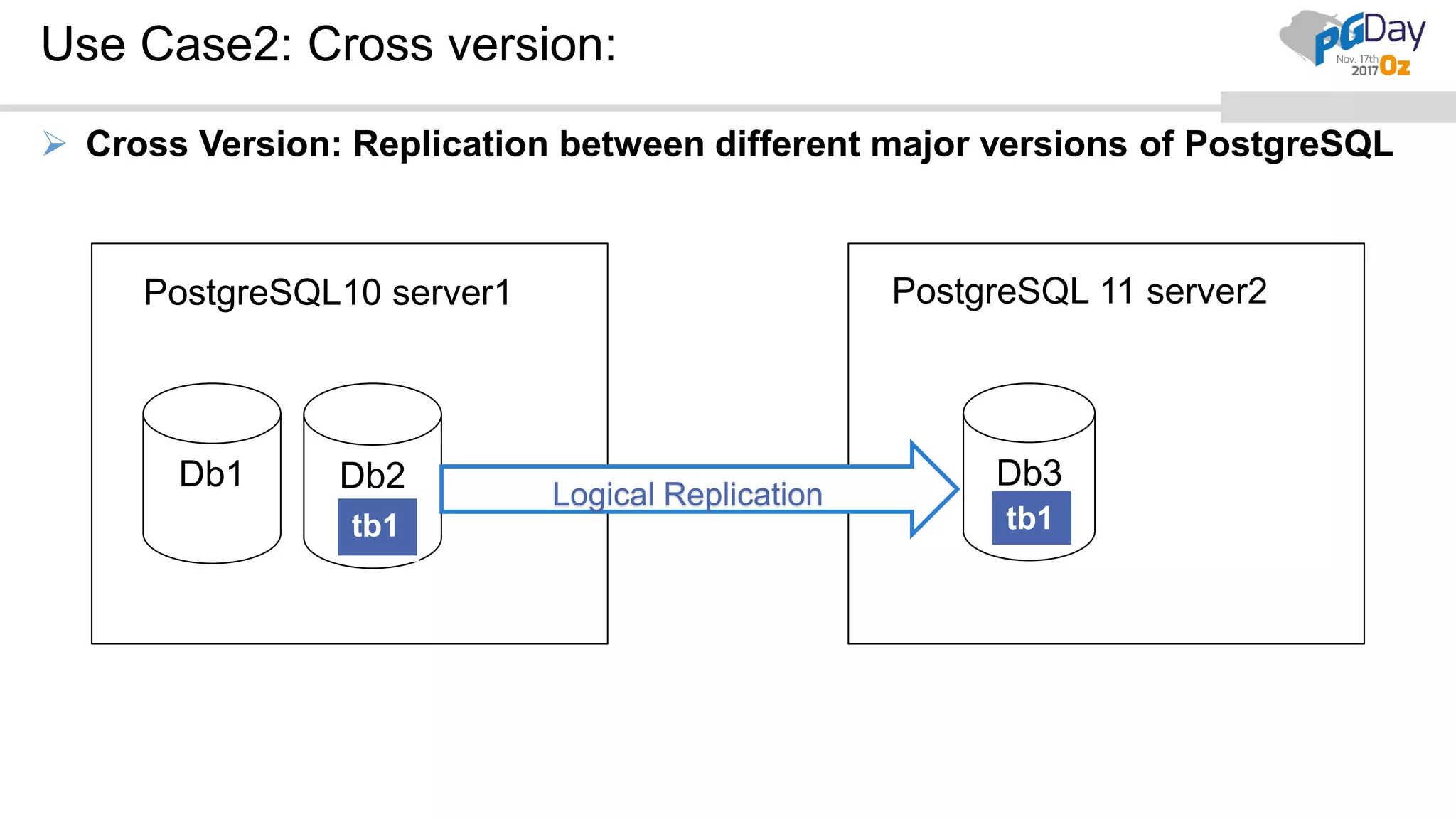
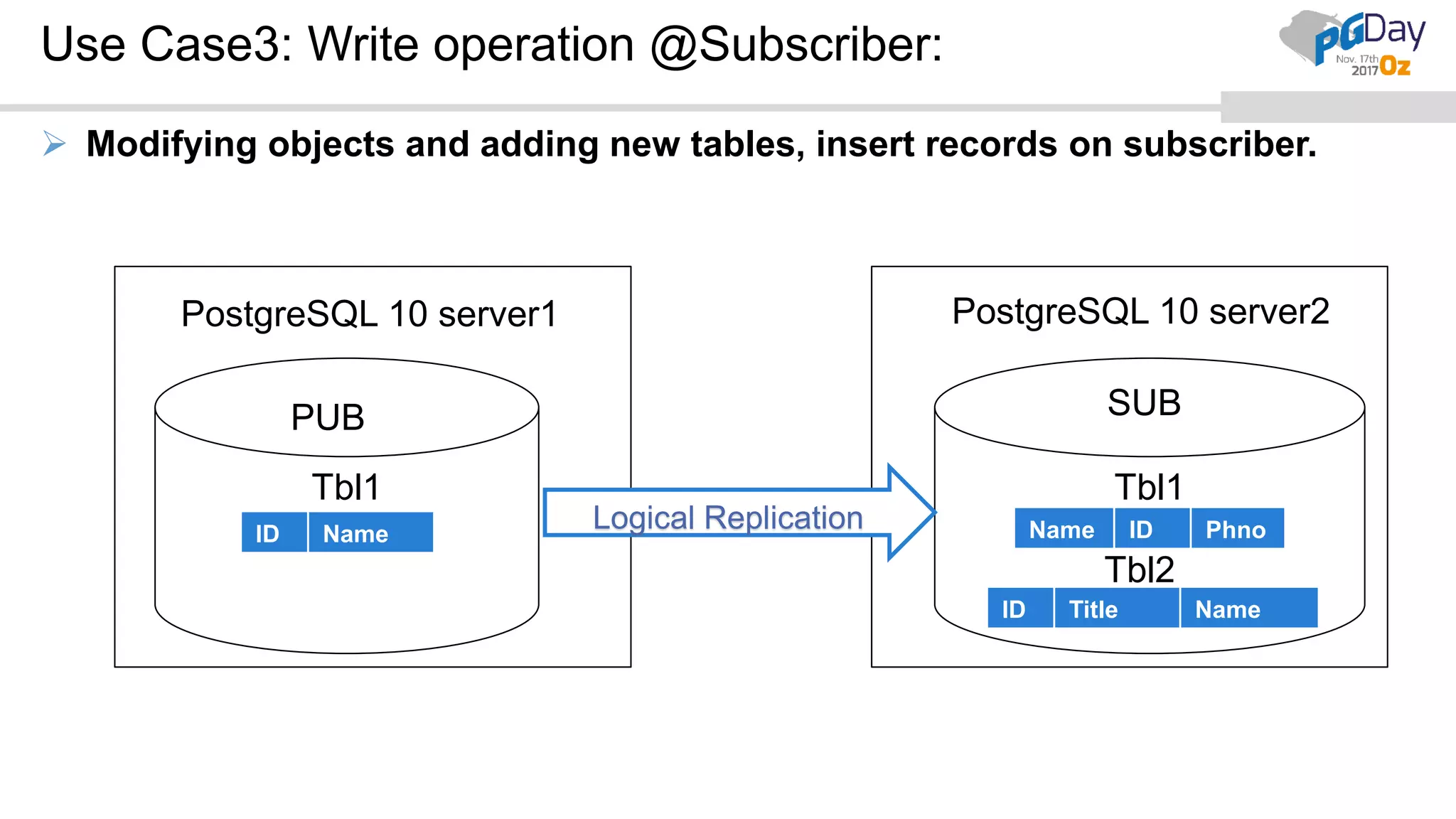
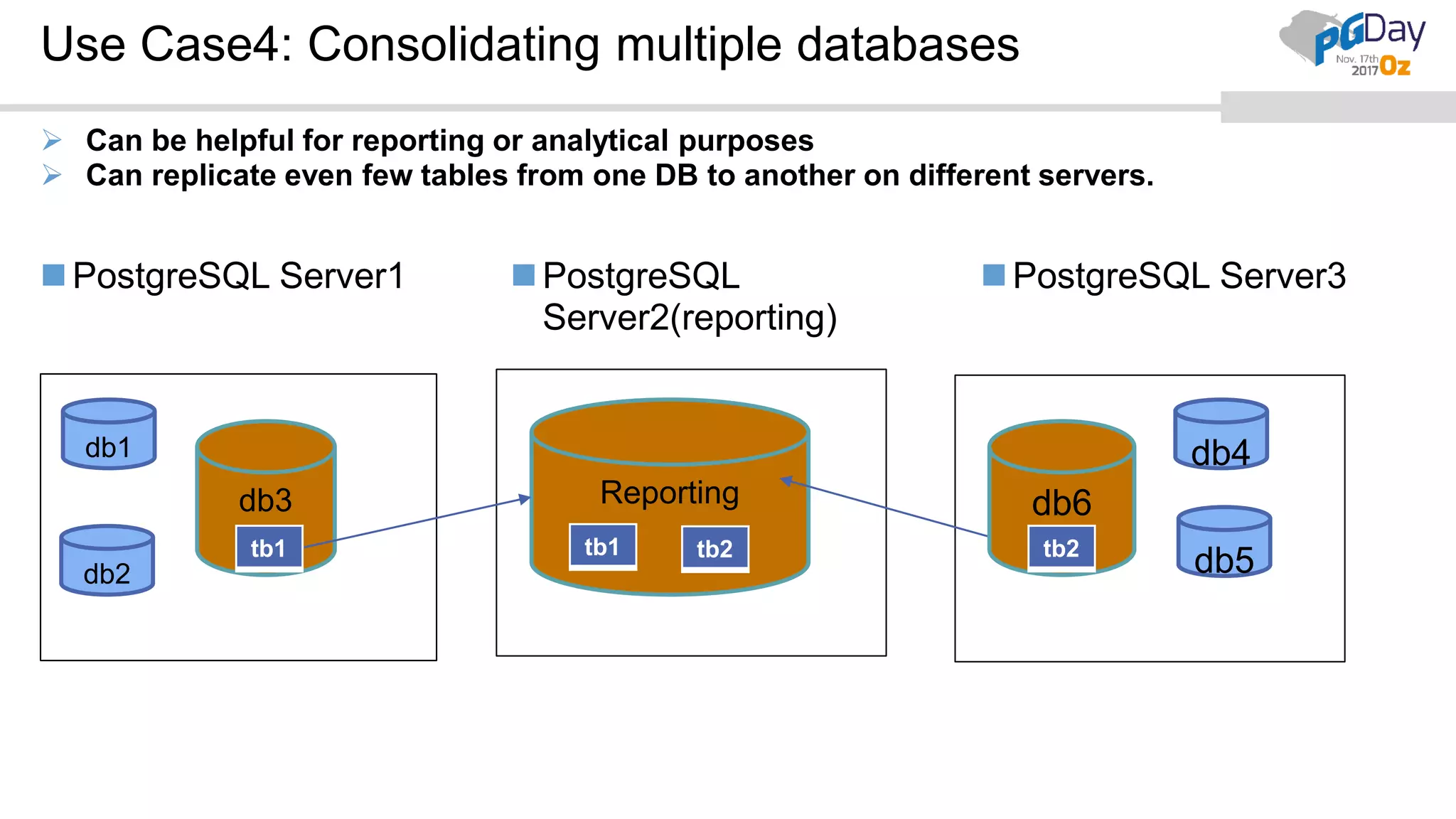

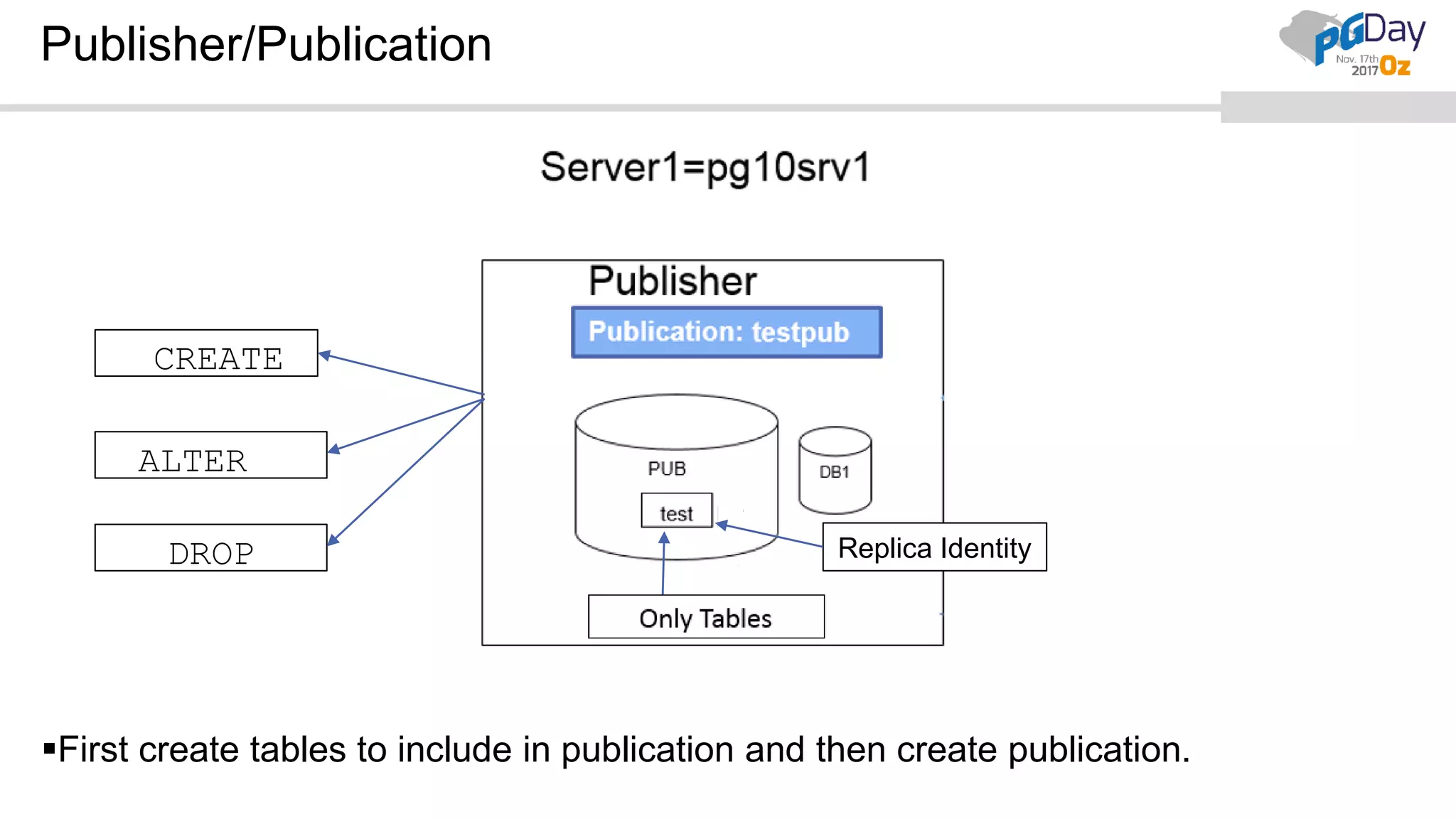


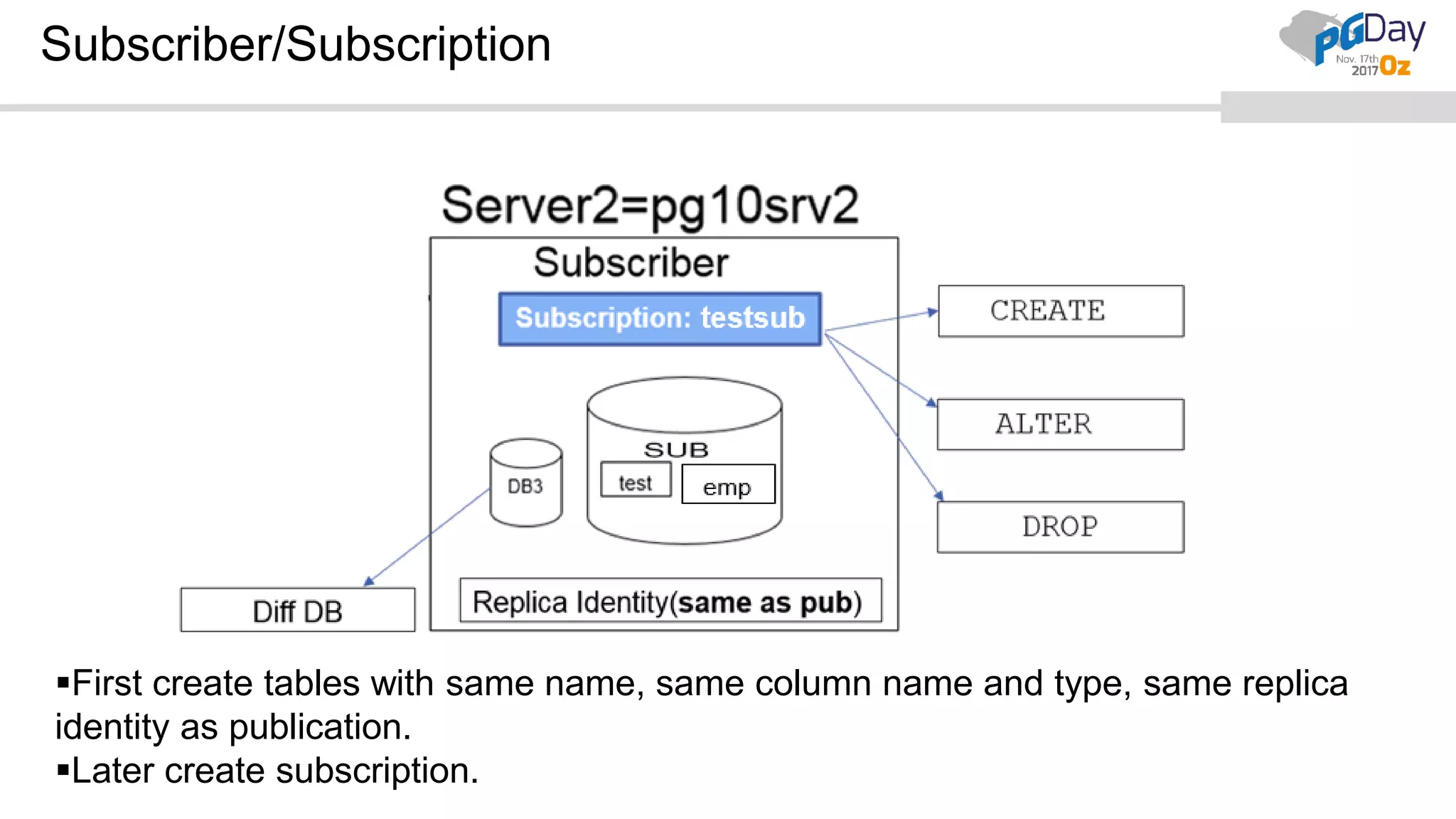

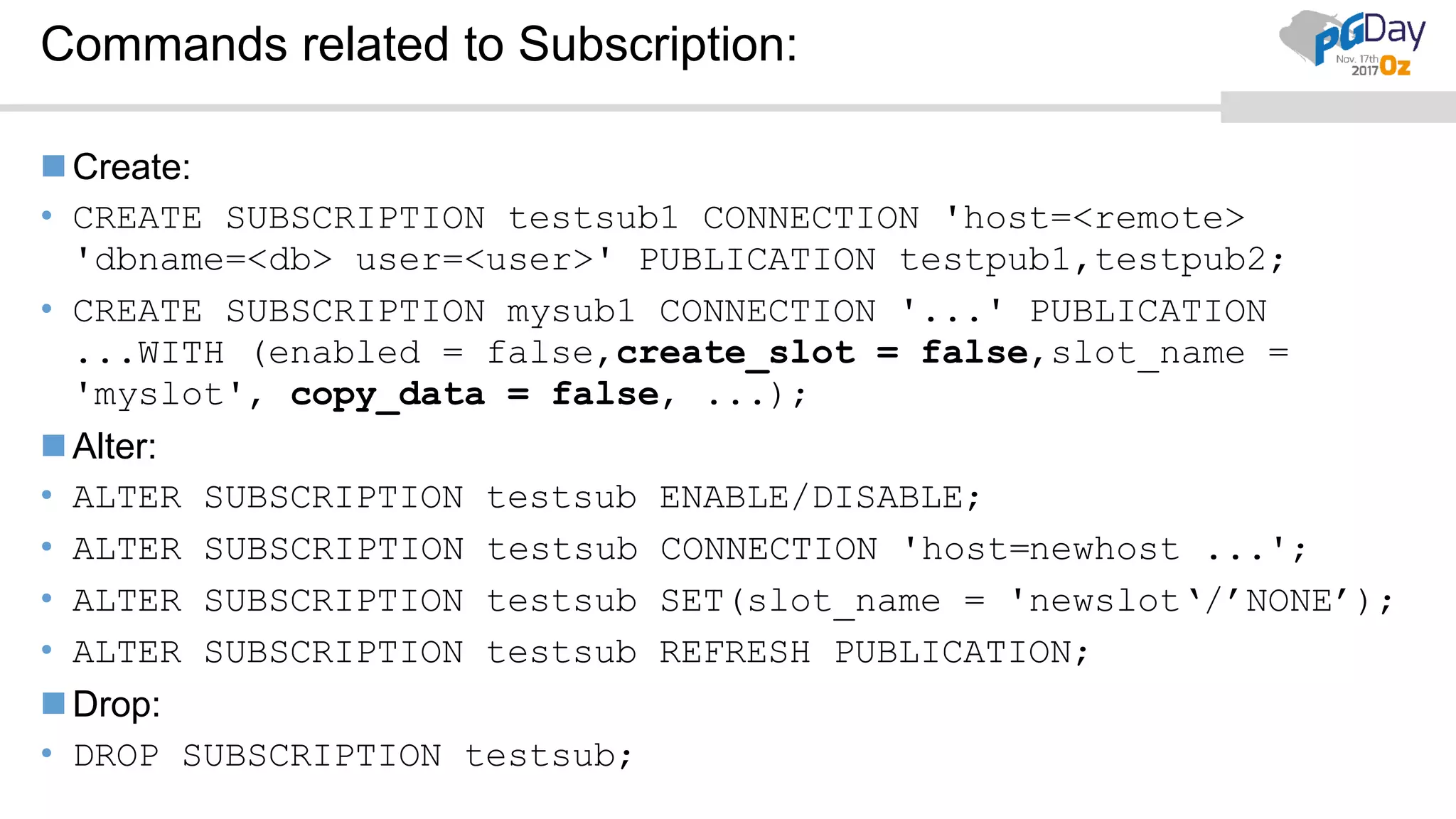

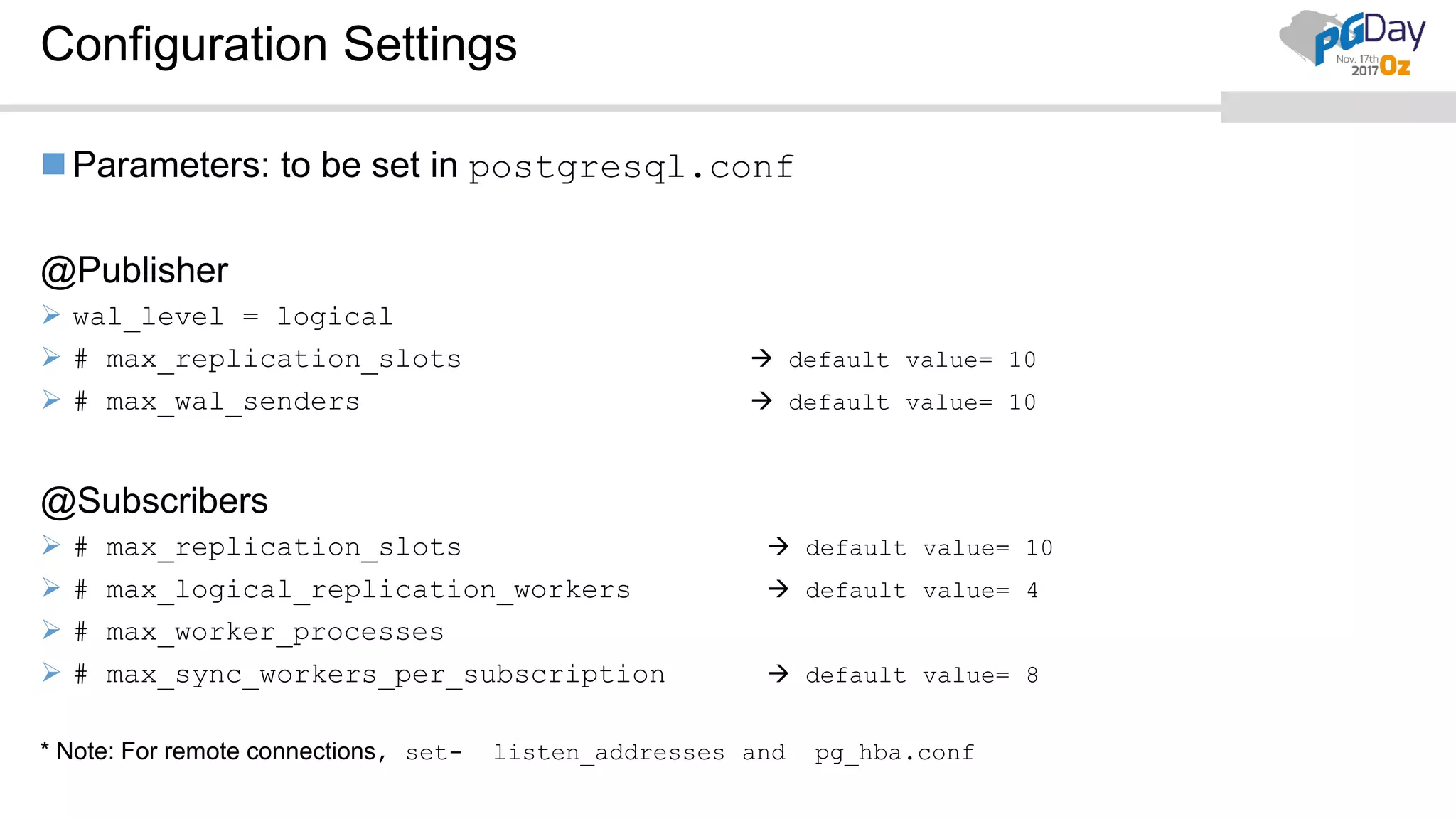

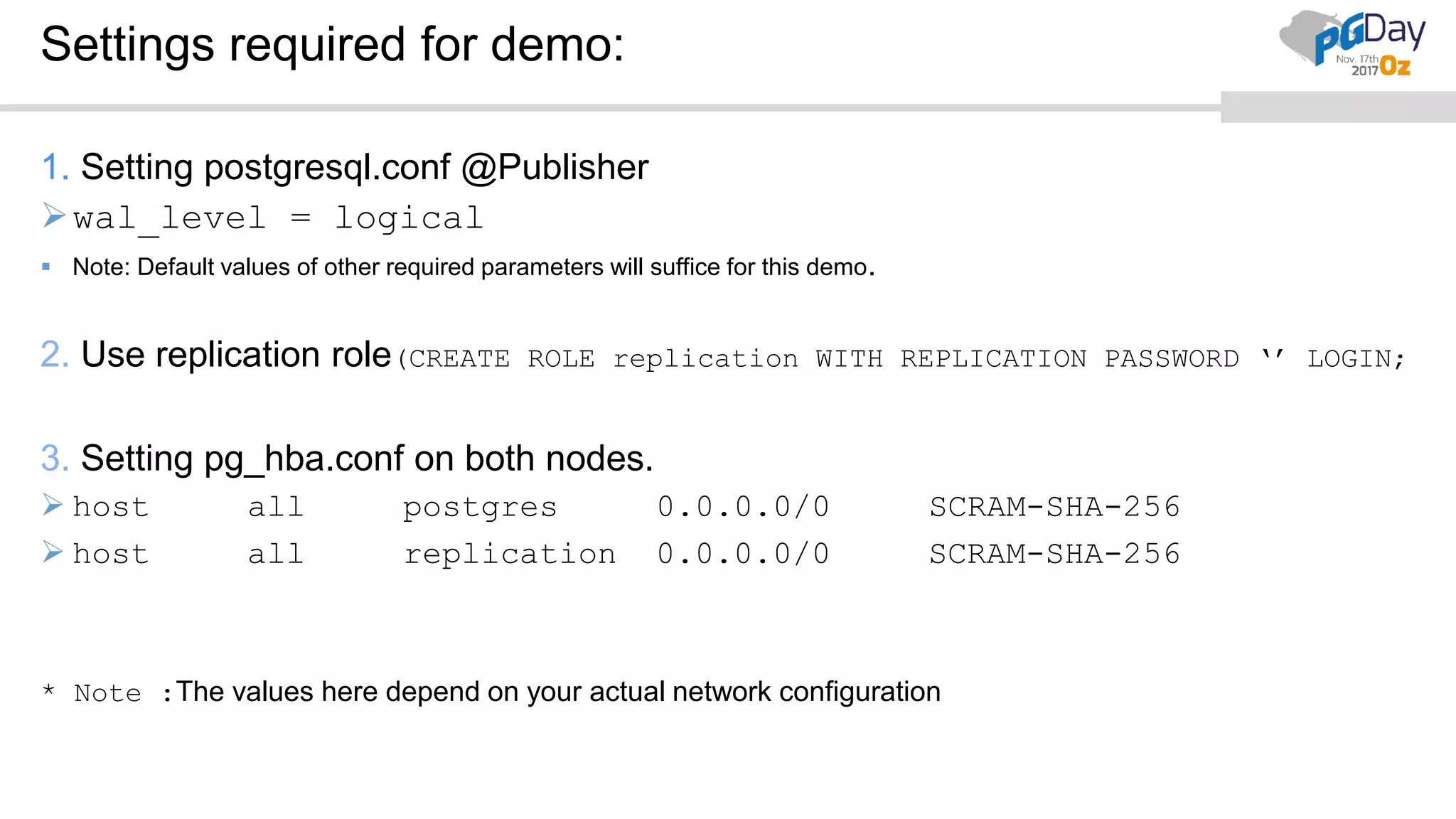
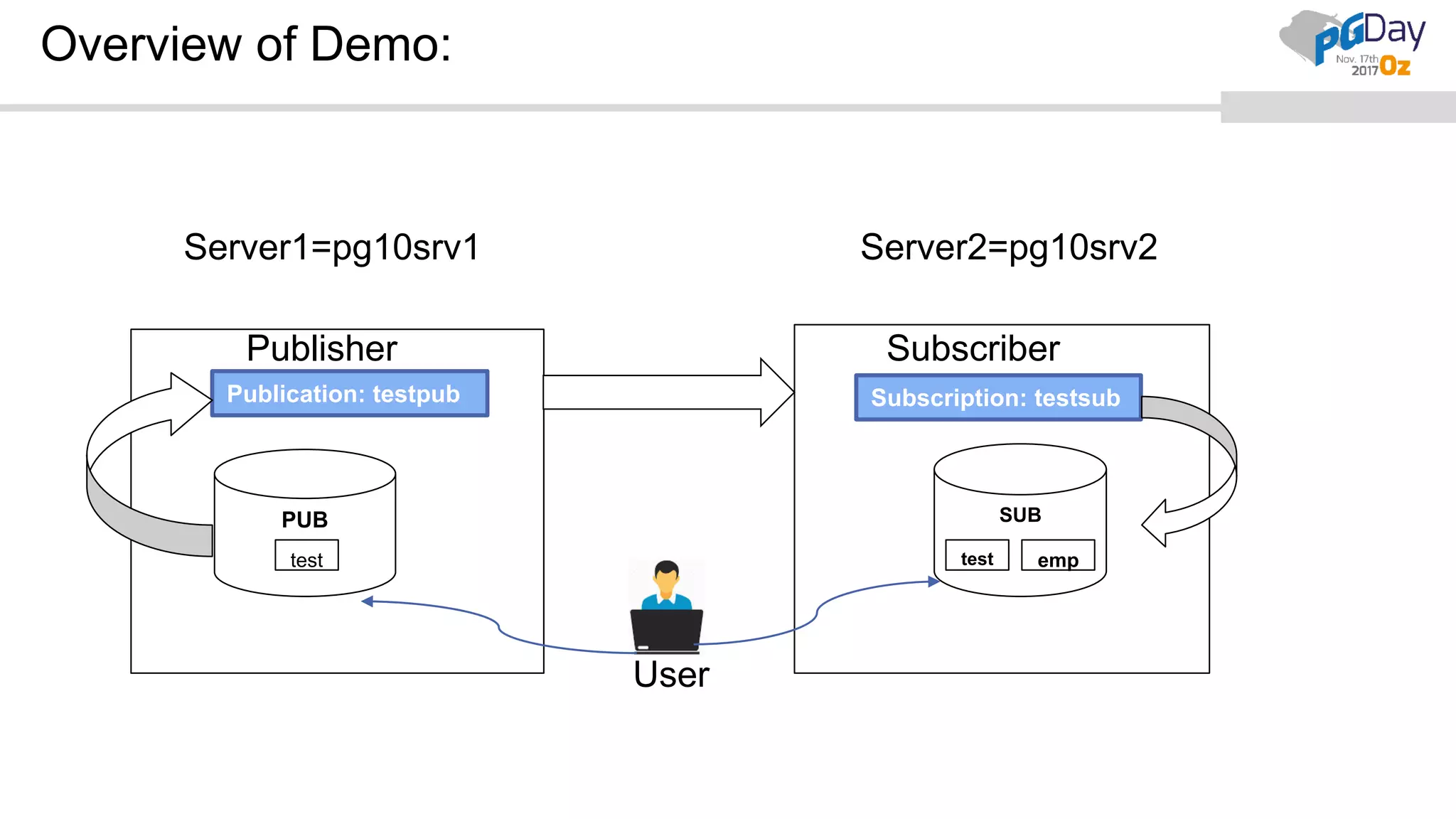









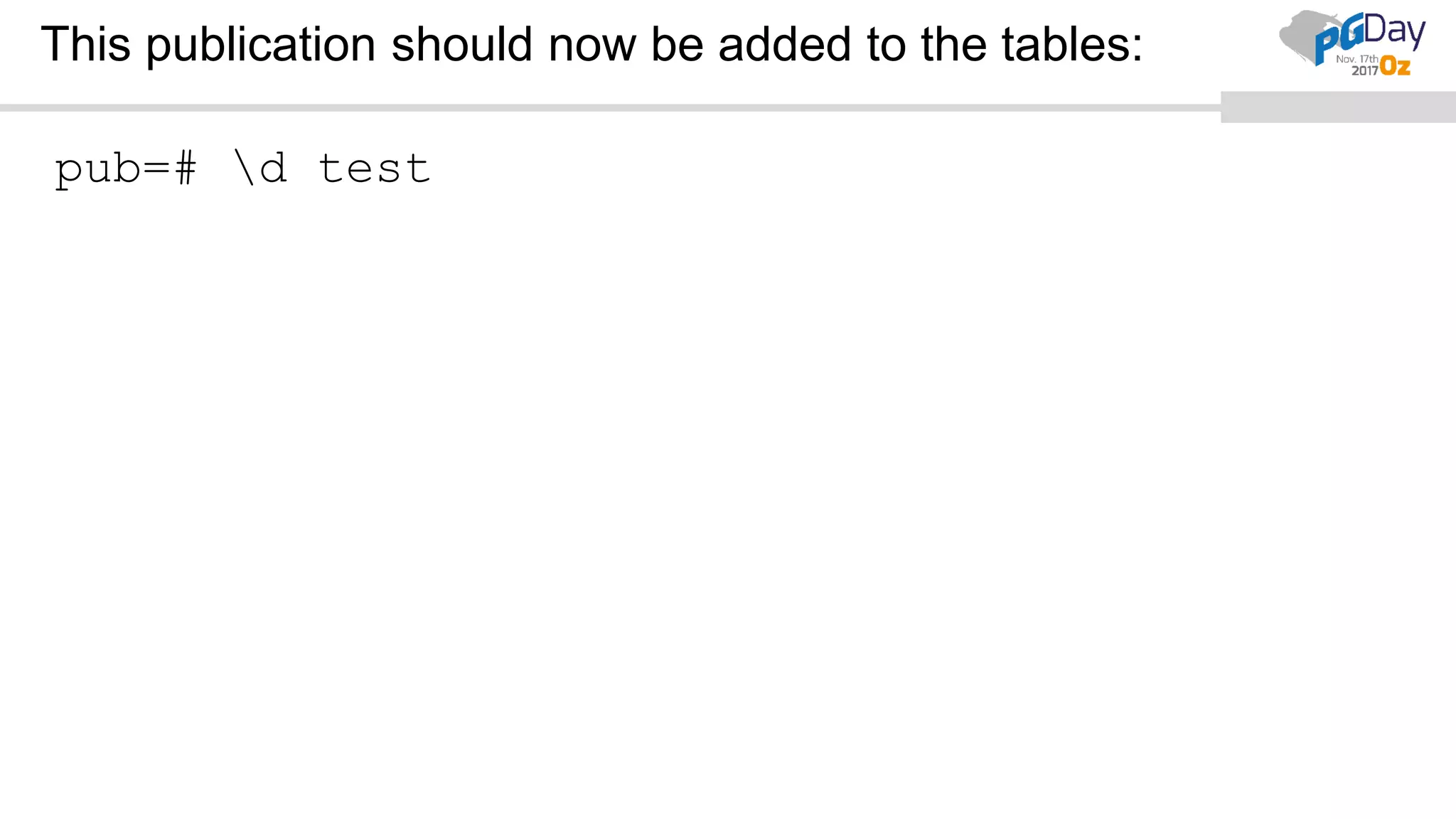


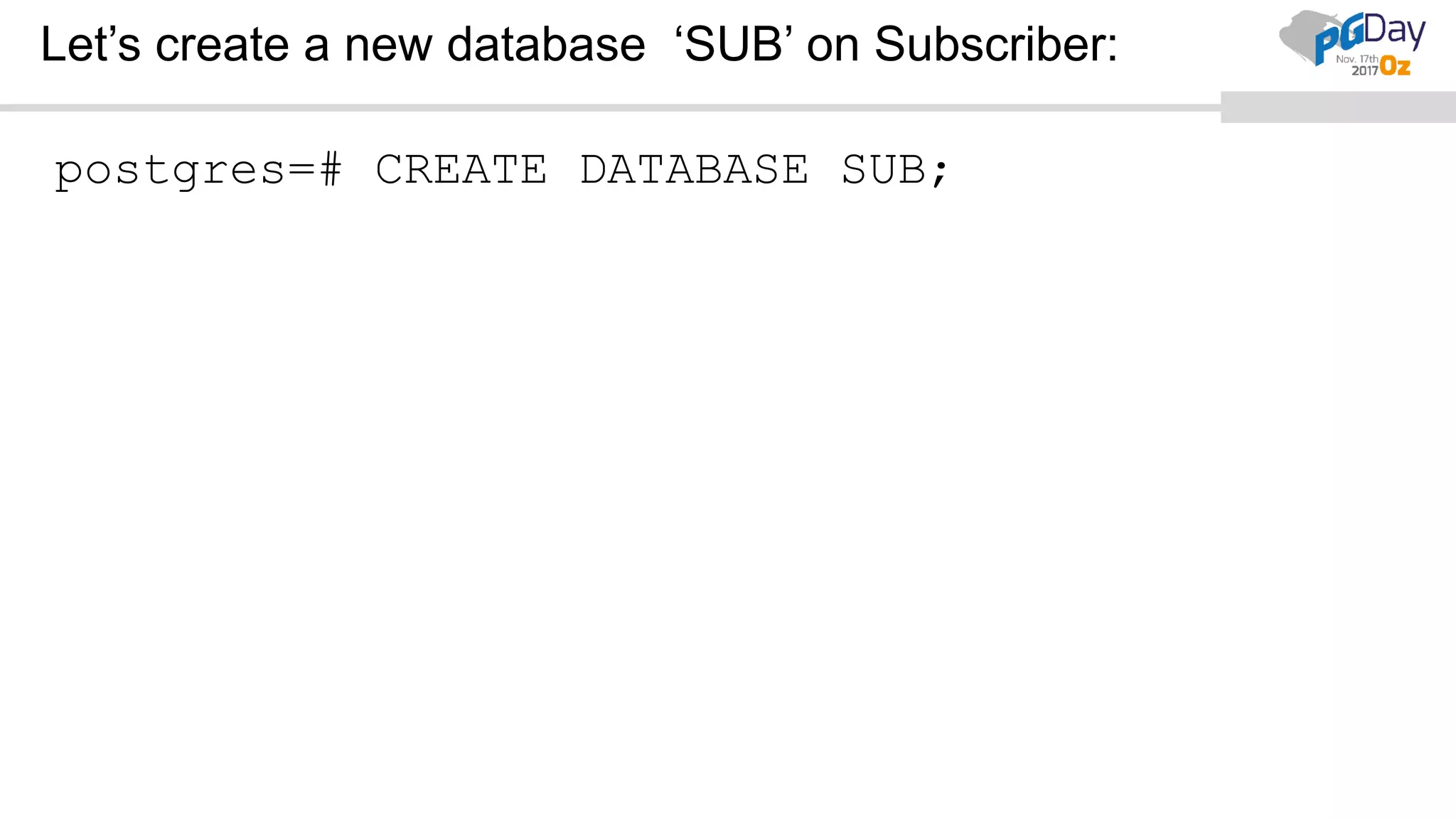




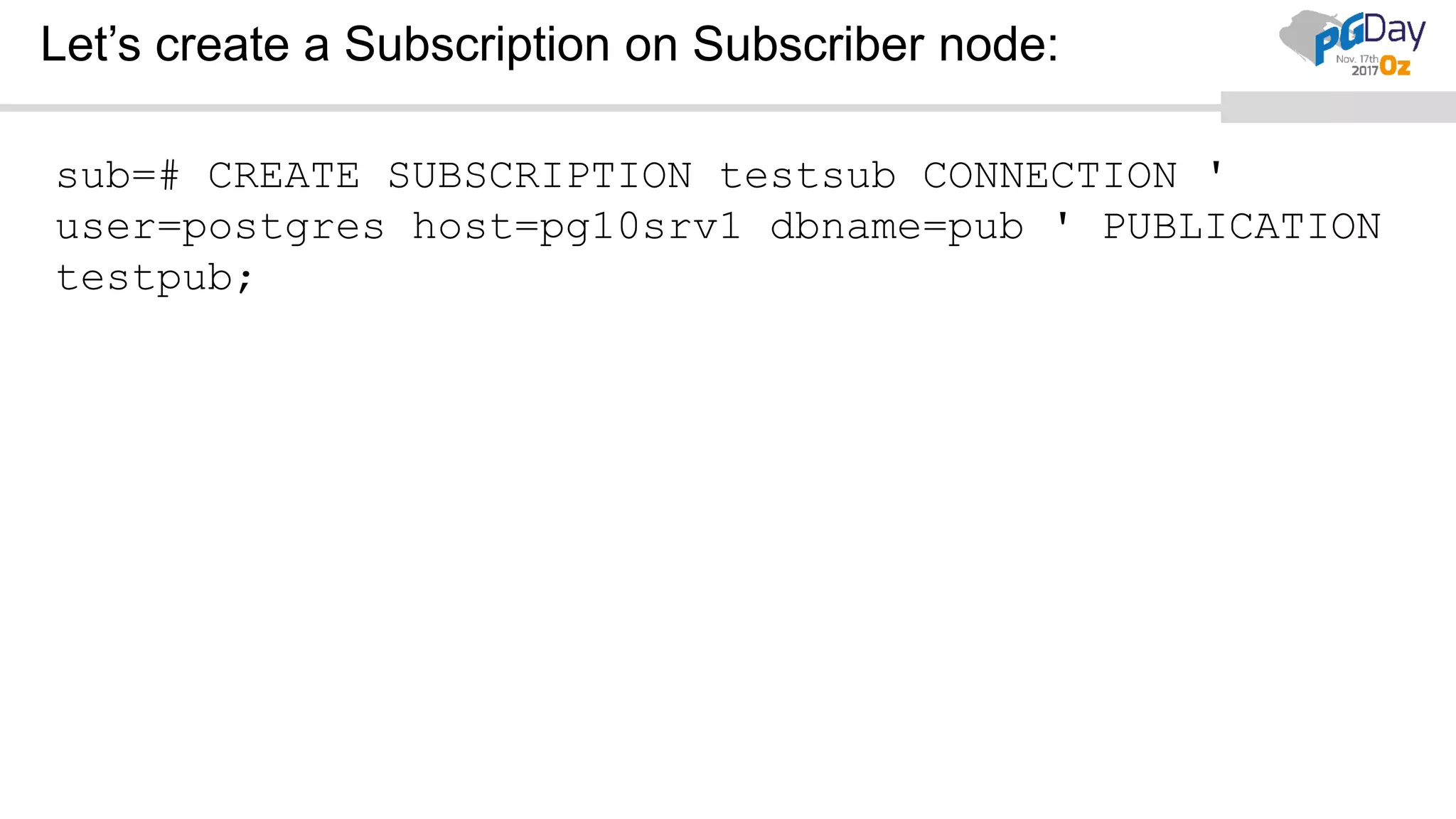

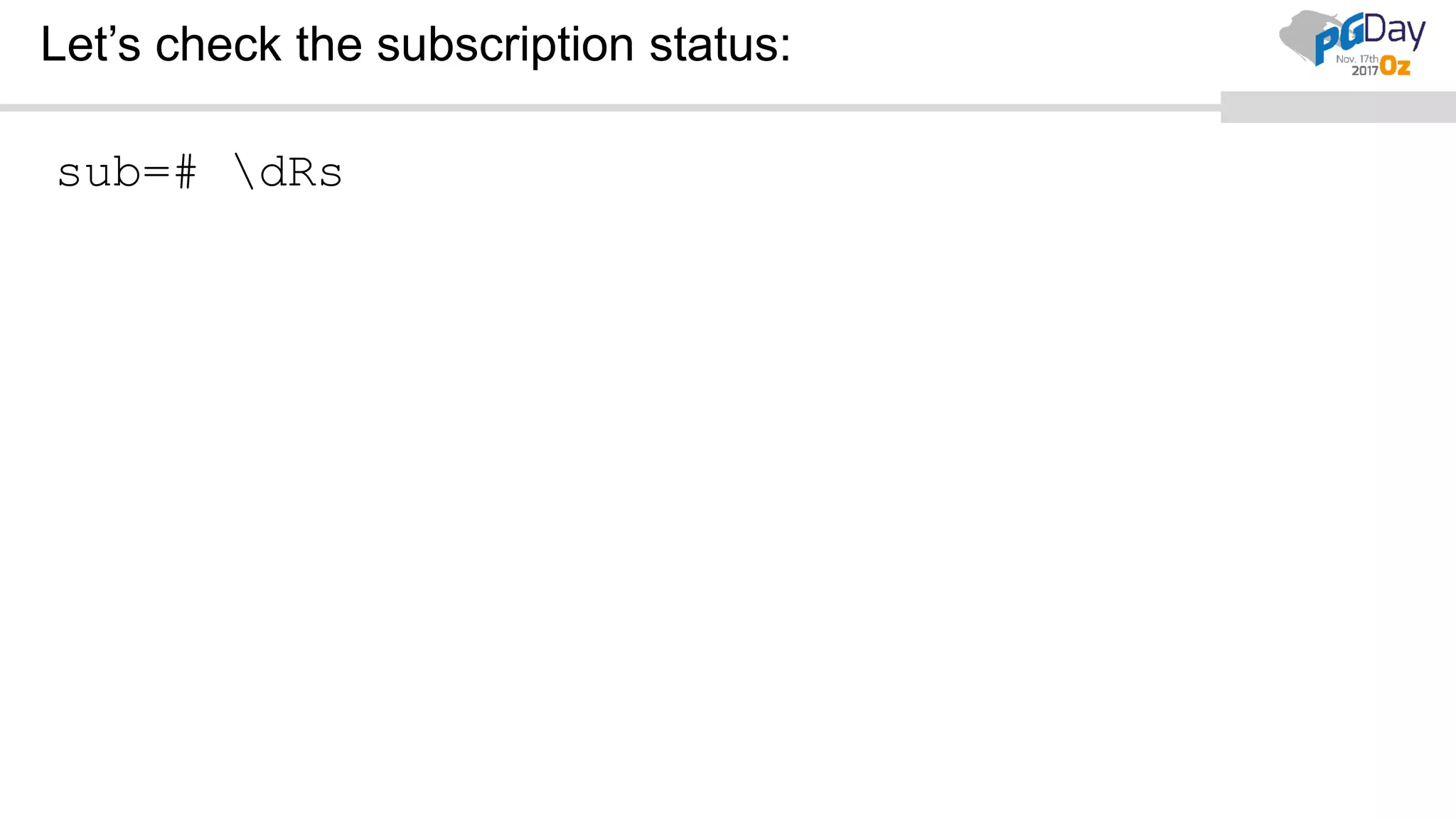








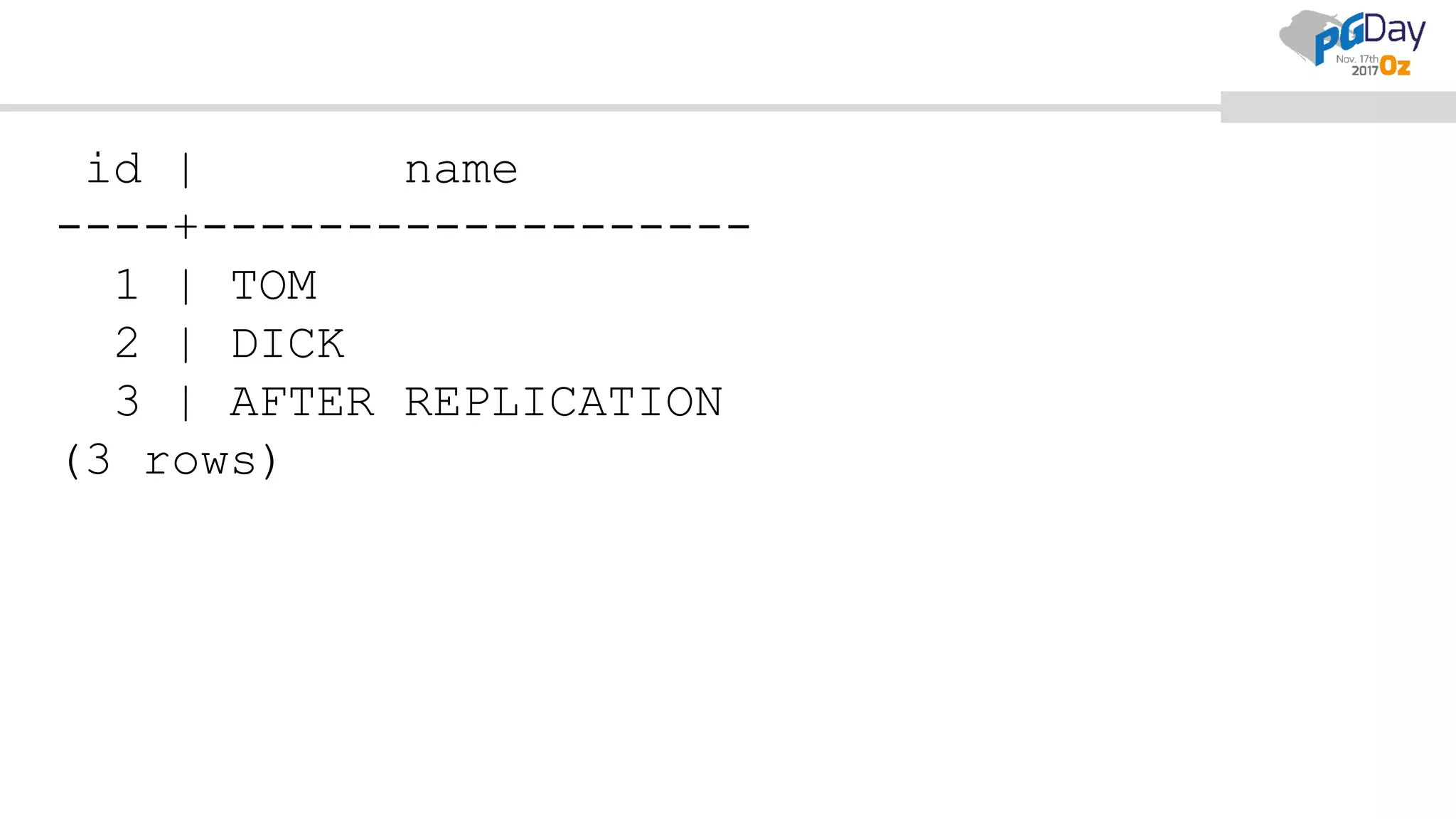



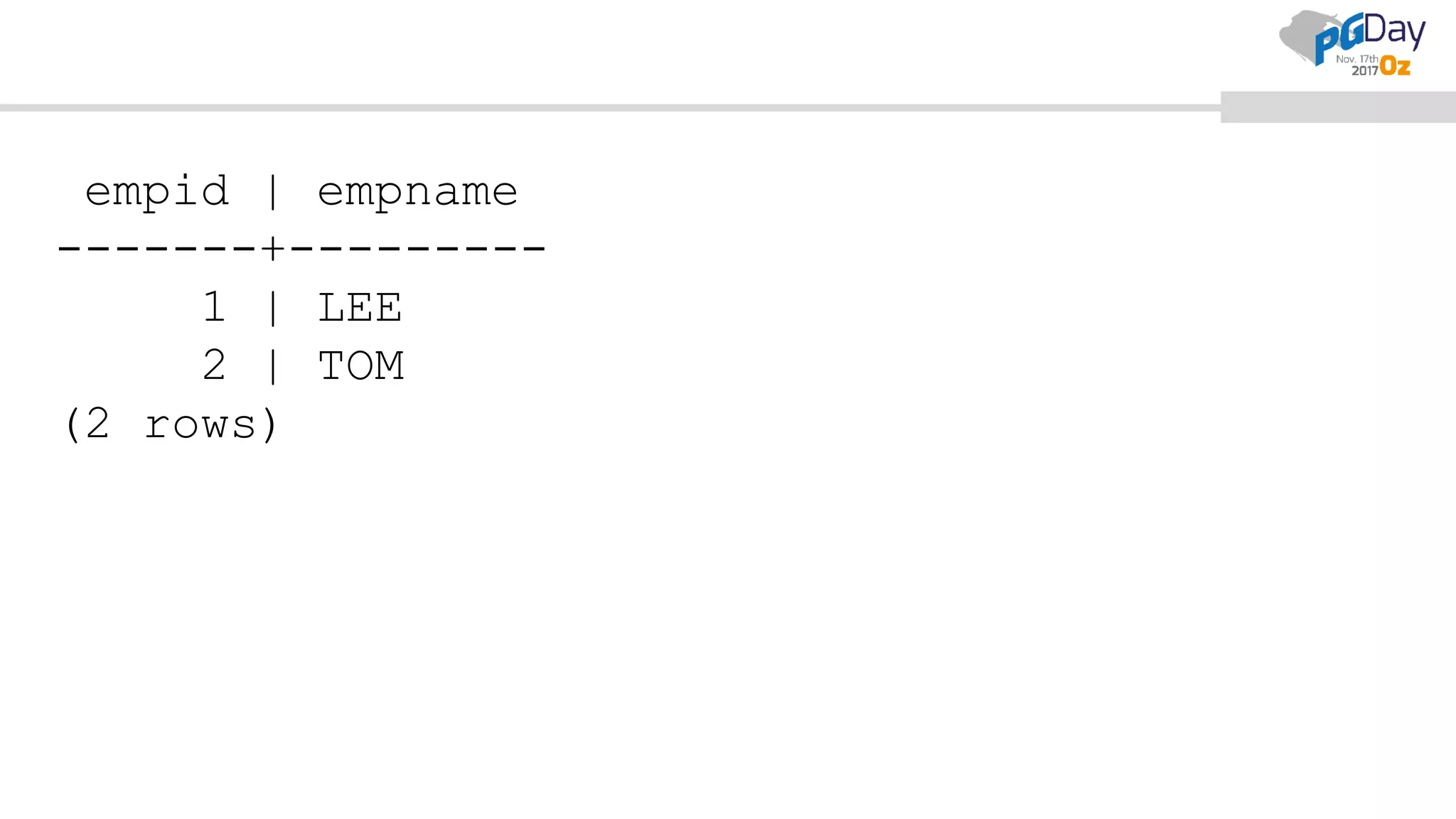


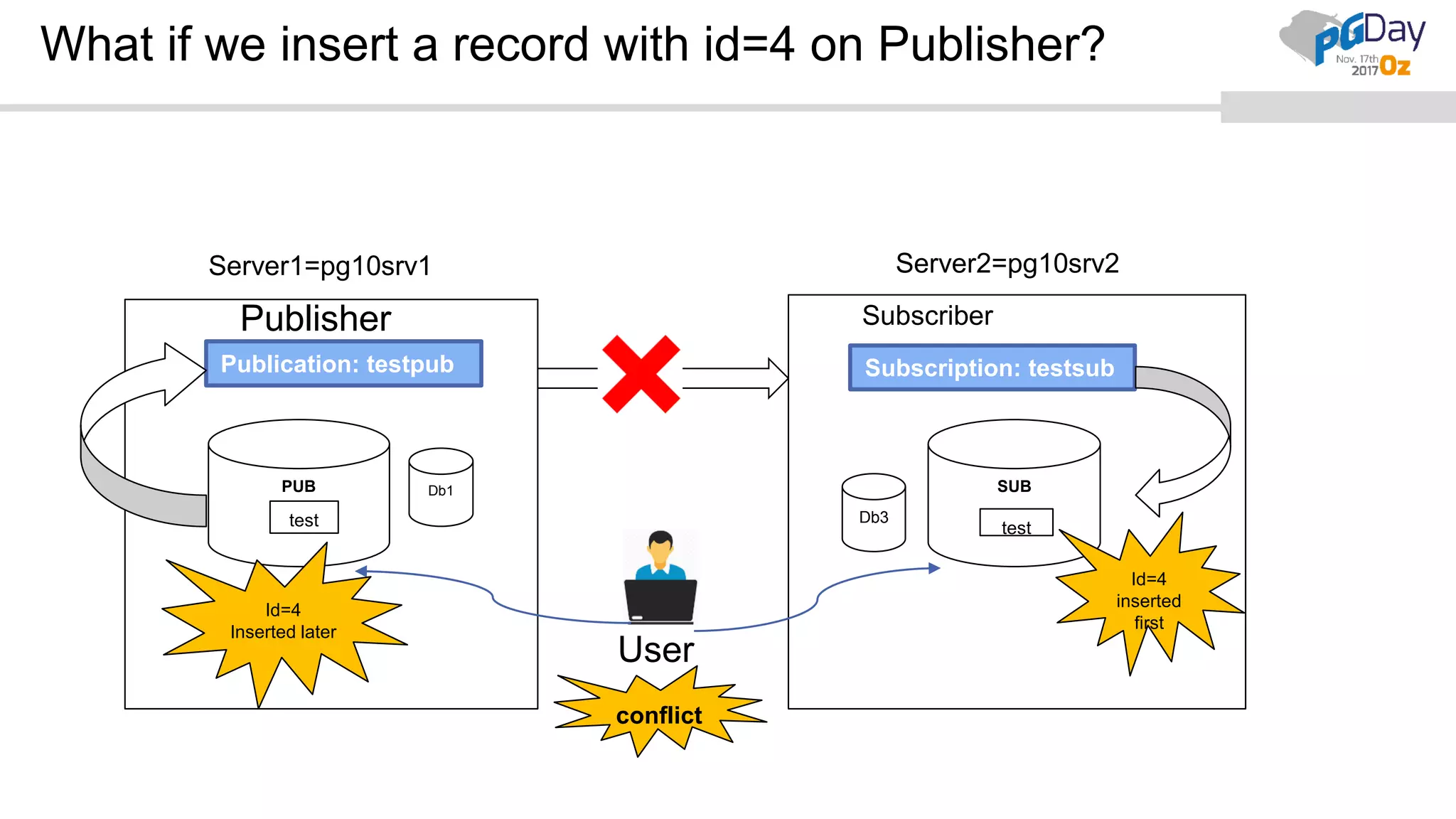

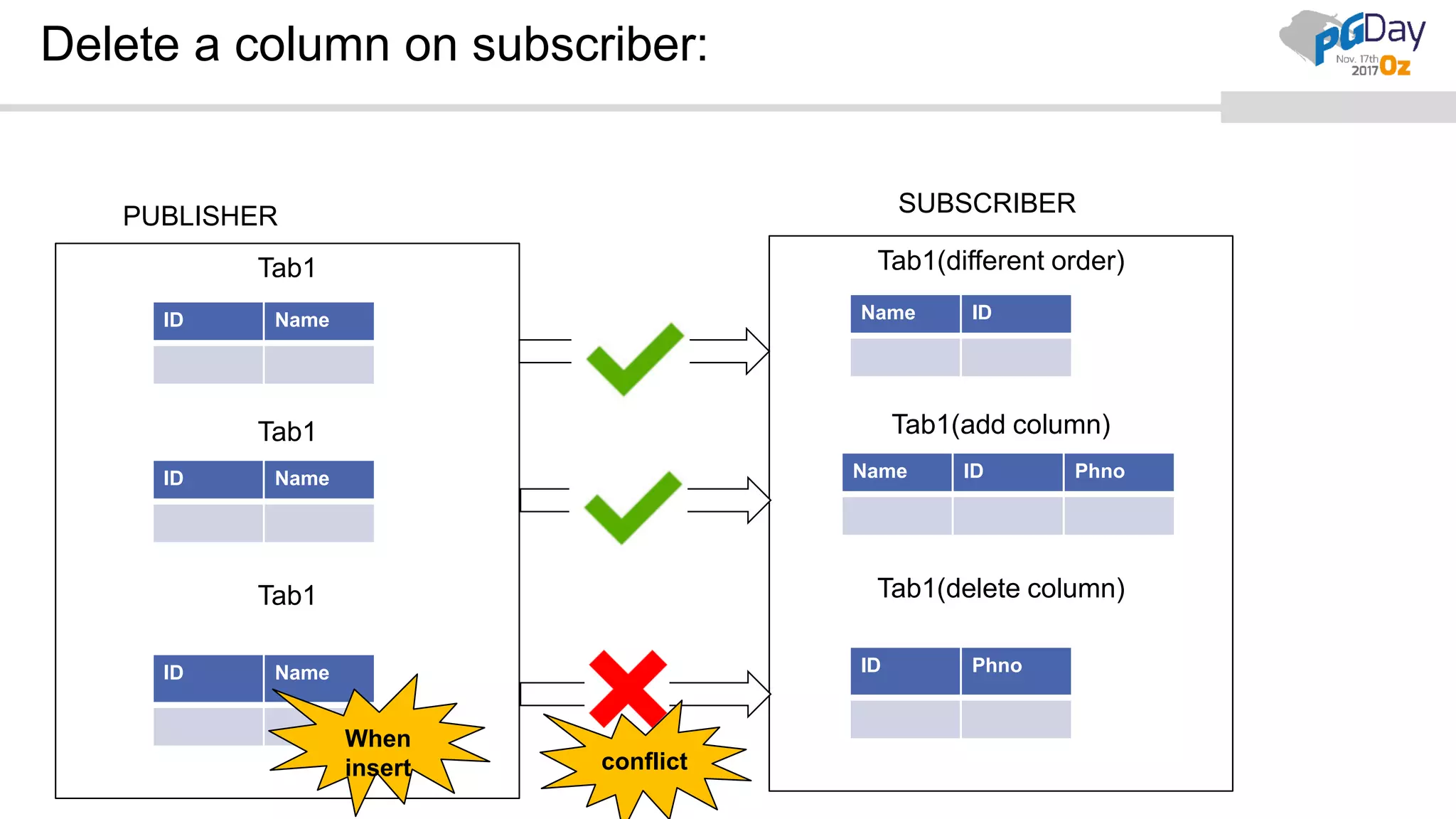







This document provides an overview of logical replication in PostgreSQL 10. It discusses the history of PostgreSQL replication, the key concepts of logical replication including publications, subscriptions, and replication slots. It presents several use cases for logical replication such as cross-platform, cross-version, and write operations at the subscriber. The document also covers configuration settings, a quick setup demonstration, monitoring, resolving conflicts, and limitations of logical replication.





















![[Cloud OnAir] BigQuery へデータを読み込む 2019年3月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0314-190314100128-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Altibase] 9 replication part2 (methods and controls)](https://cdn.slidesharecdn.com/ss_thumbnails/altibase9replicationpart2methodsandcontrols-160126071813-thumbnail.jpg?width=640&height=640&fit=bounds)







![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















