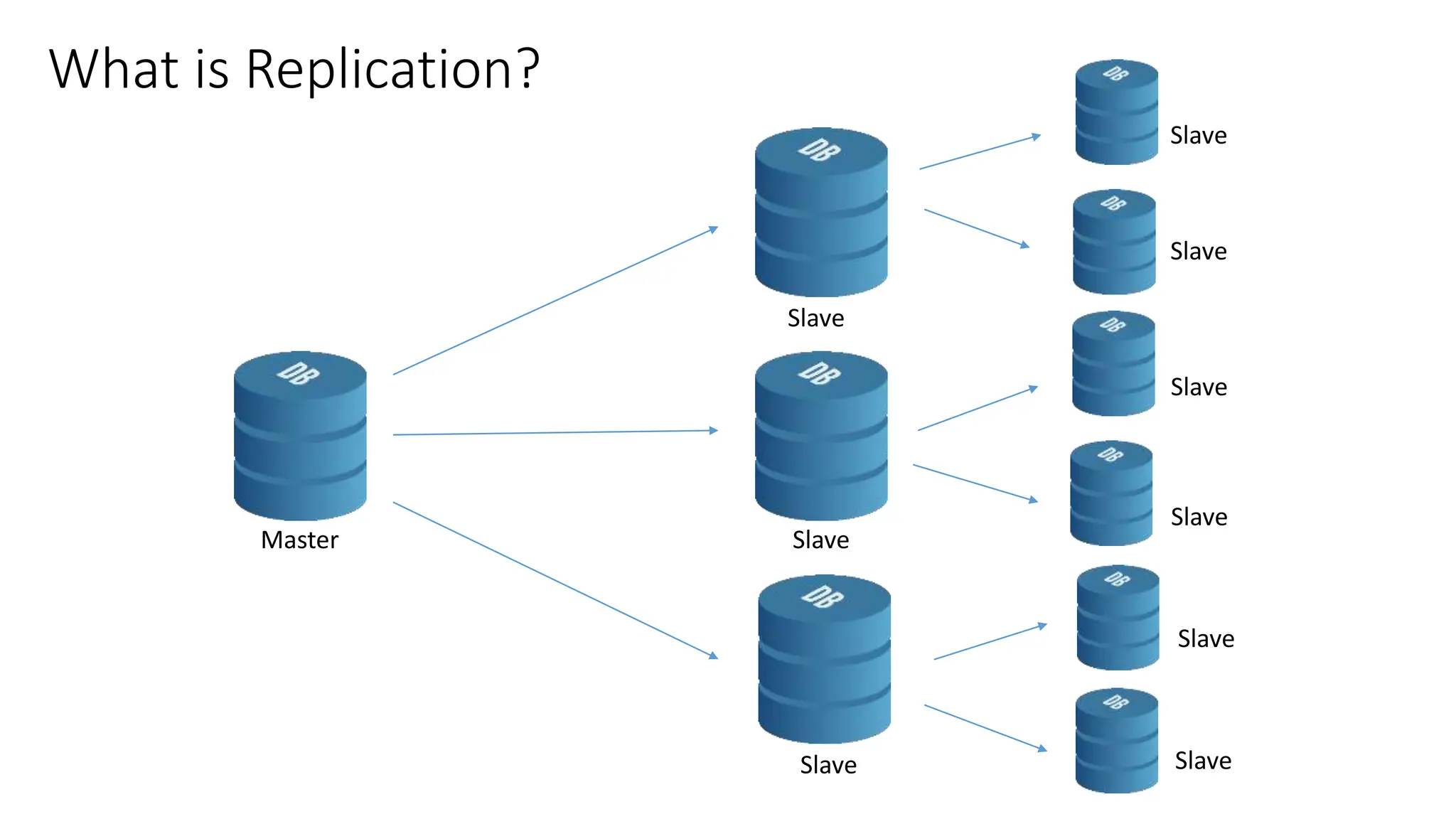
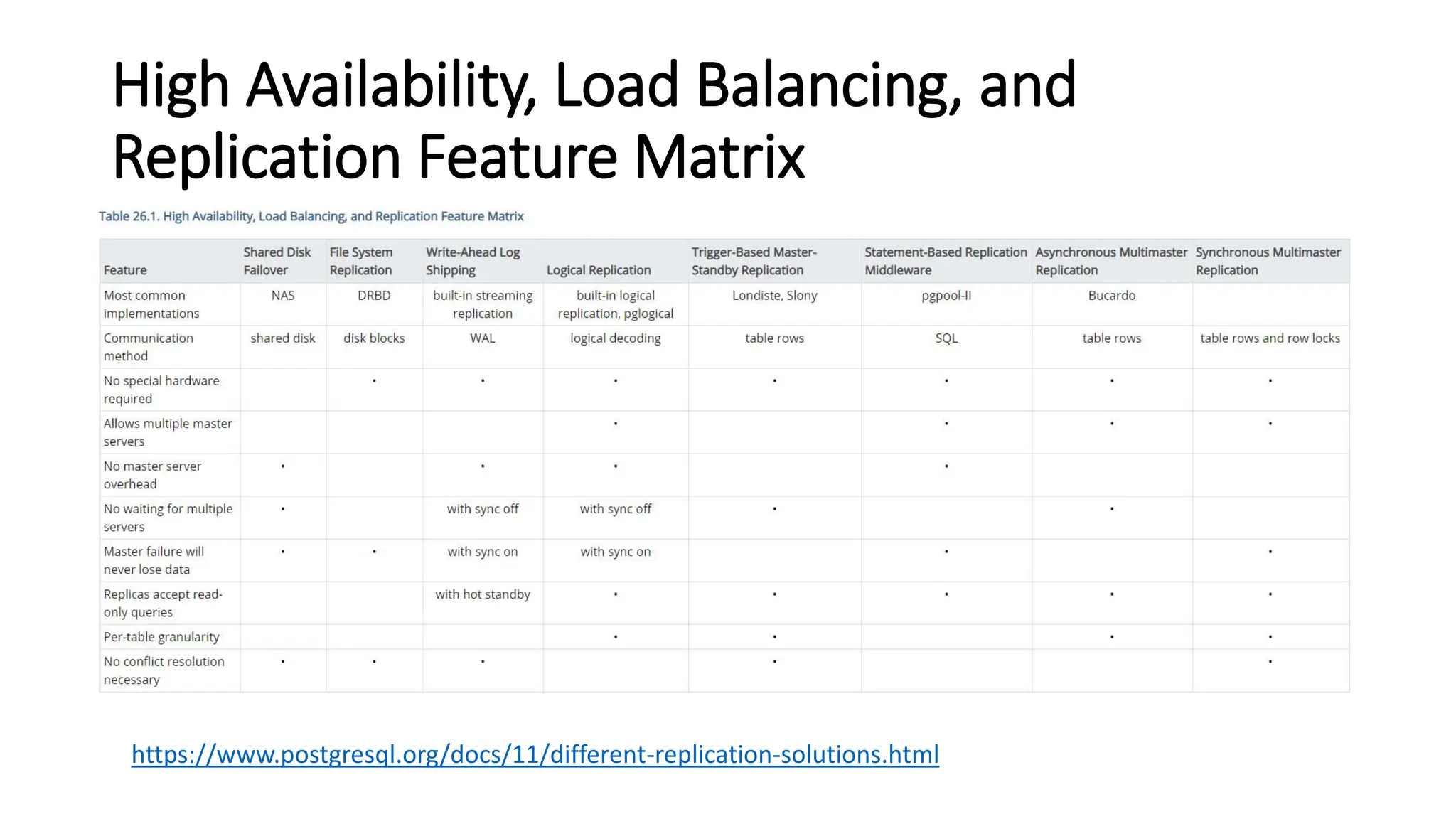
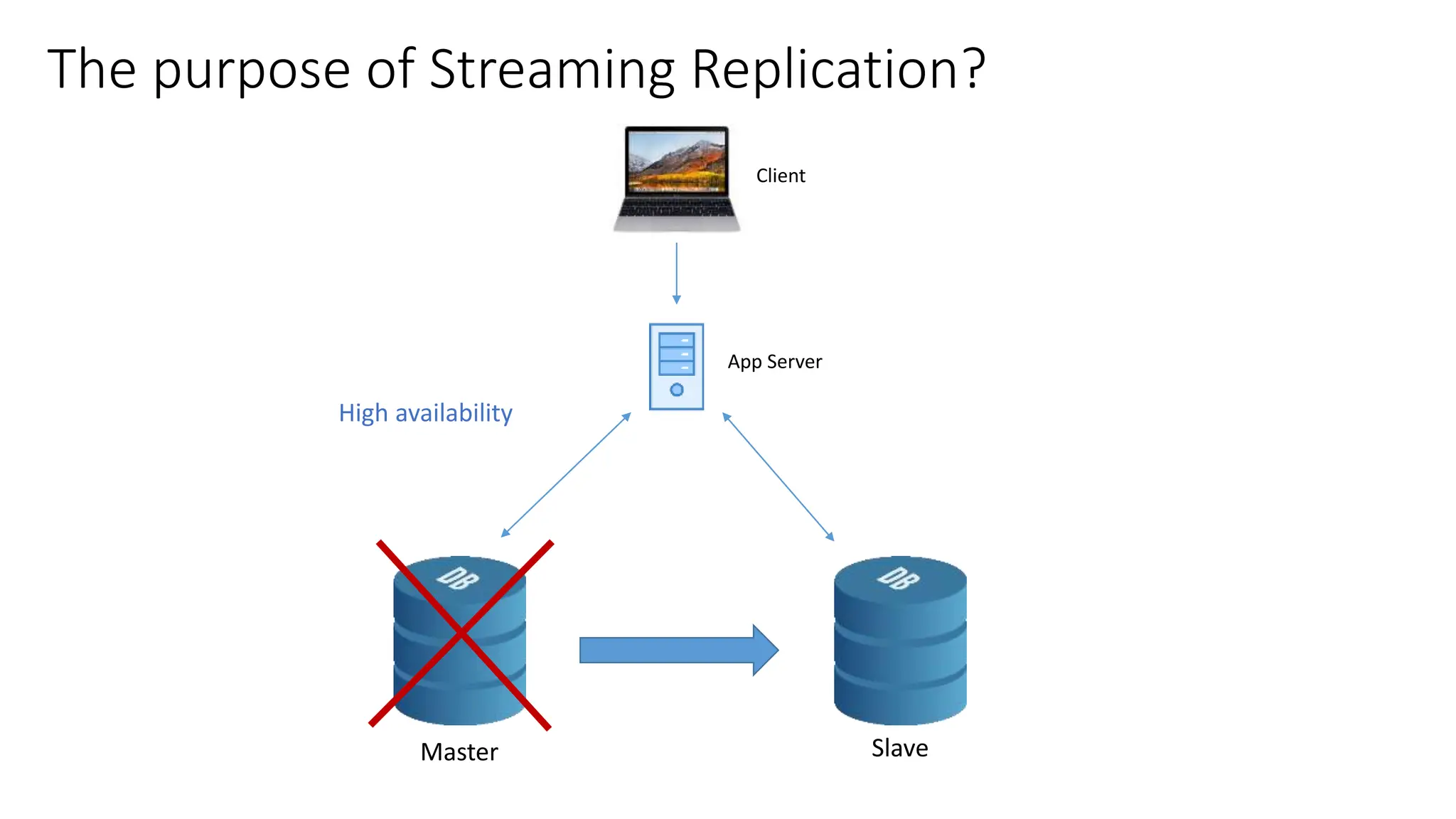
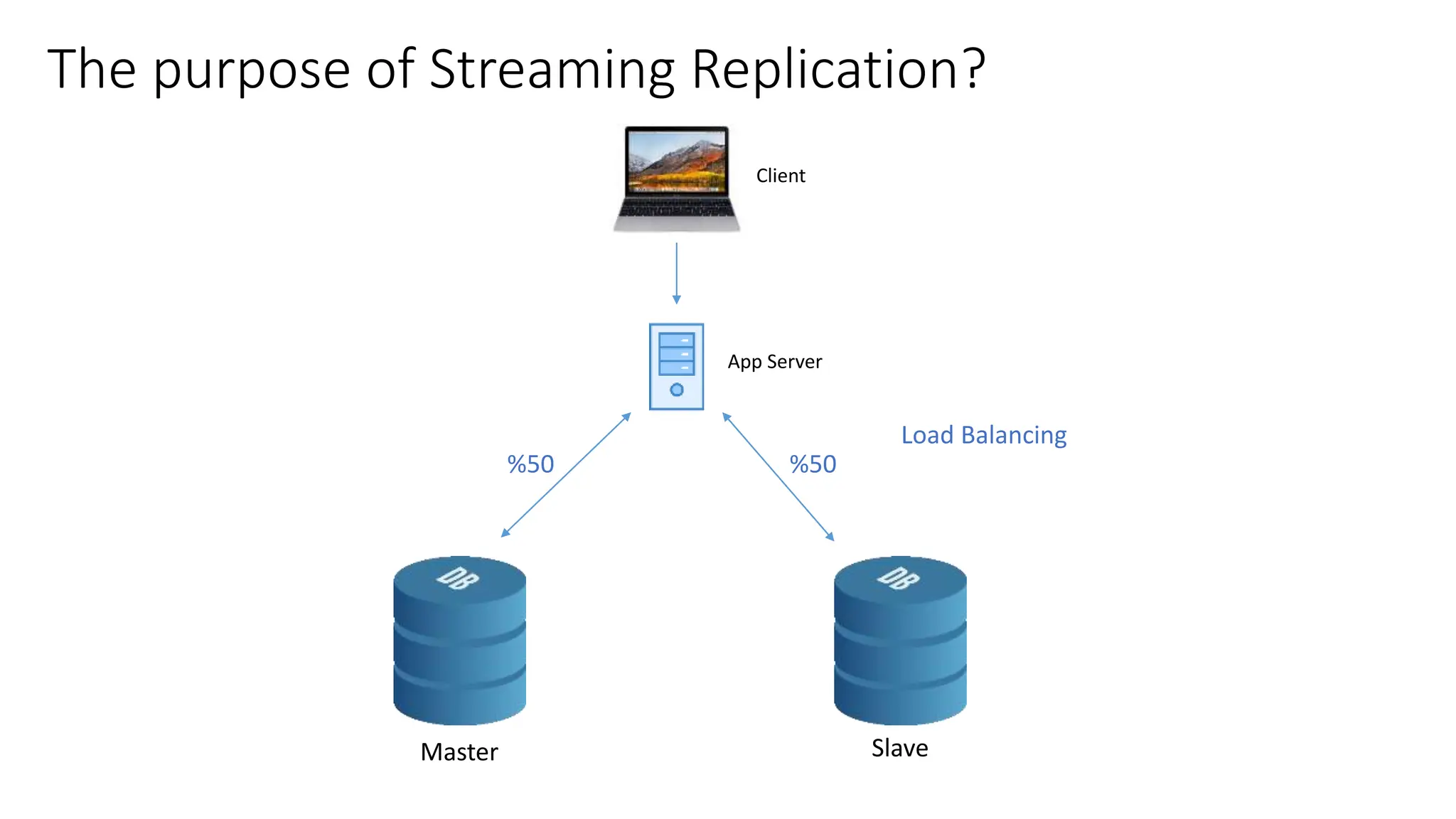
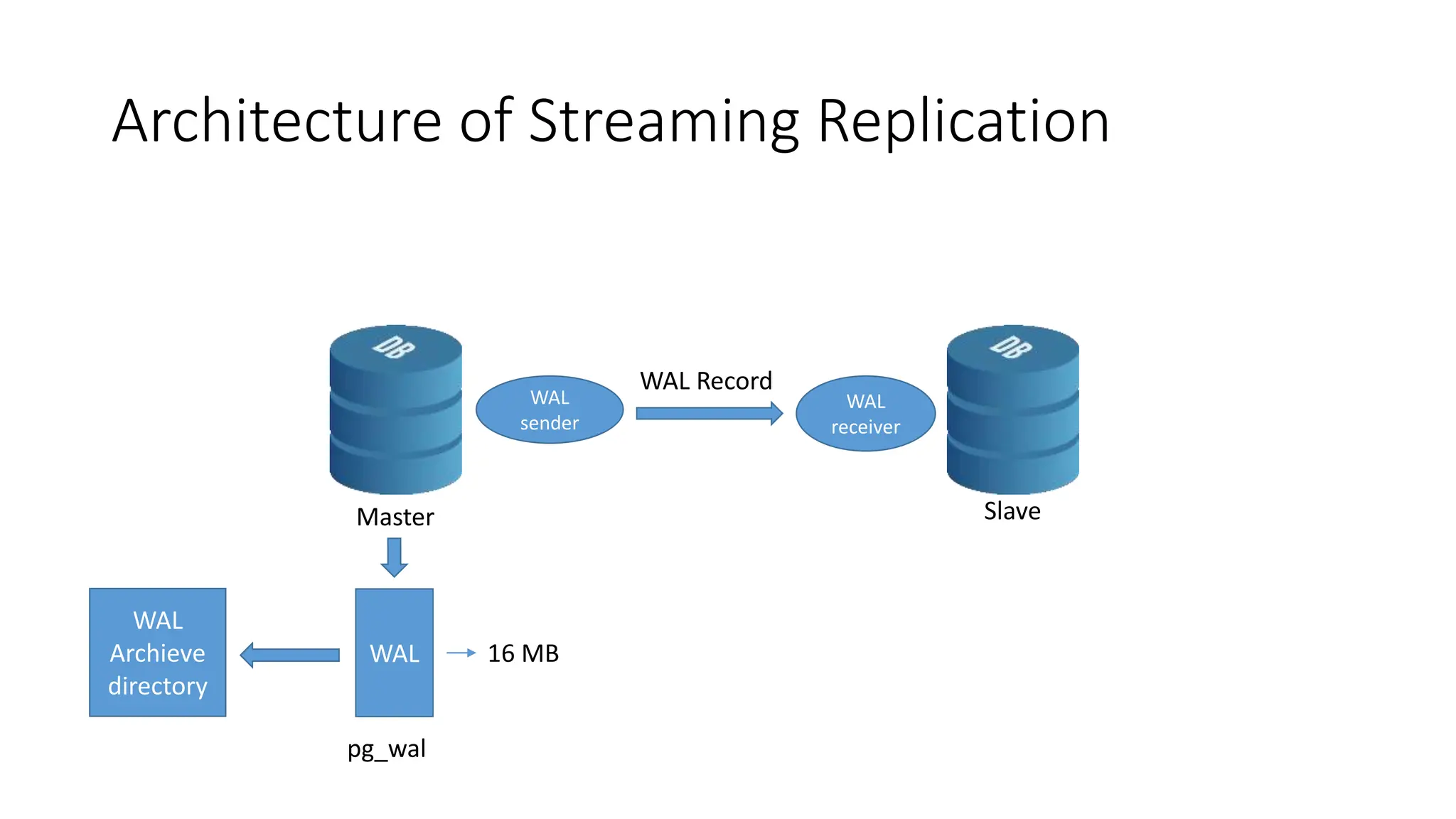
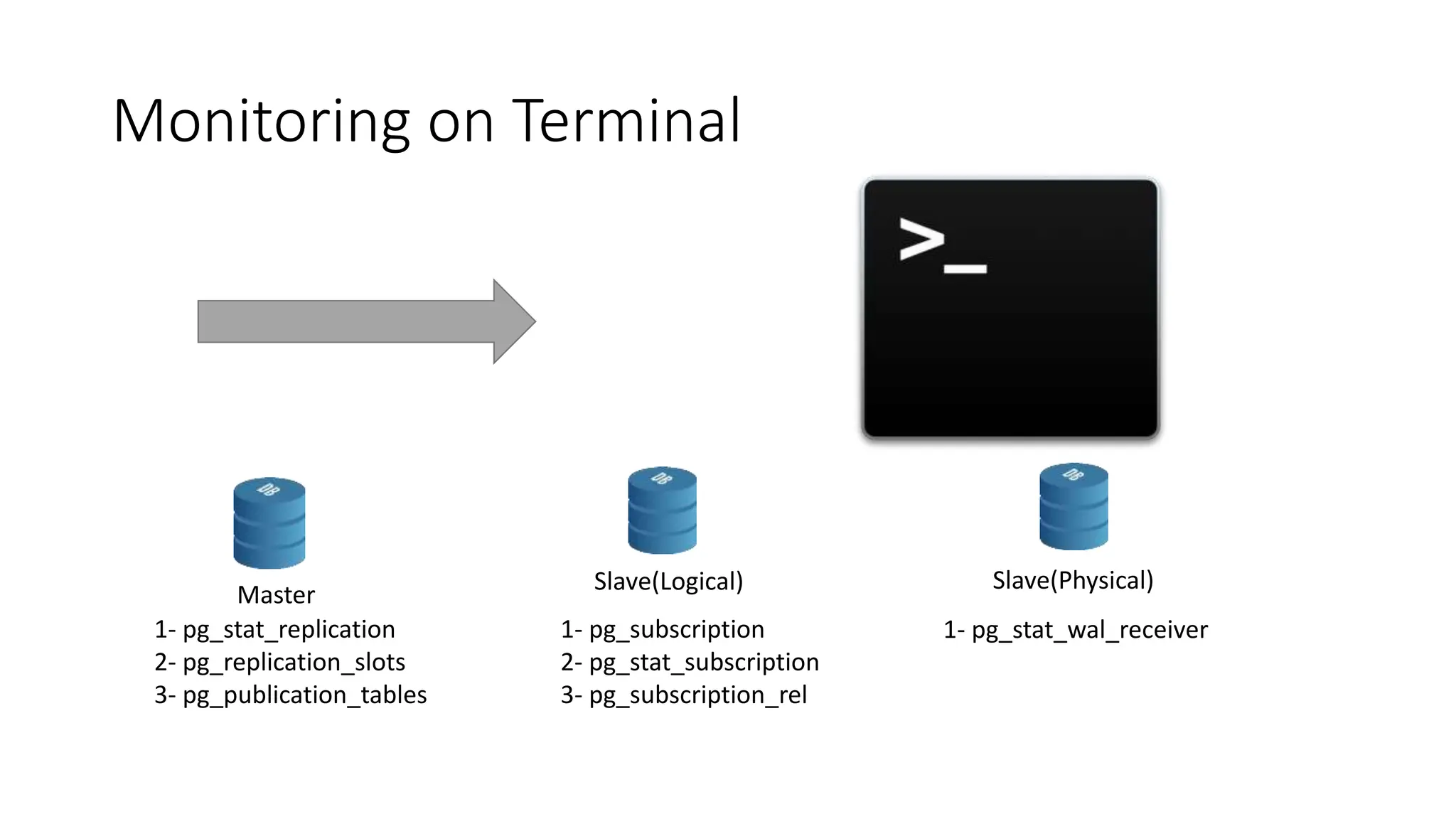
This document provides an overview of built-in physical and logical replication in PostgreSQL. It discusses:
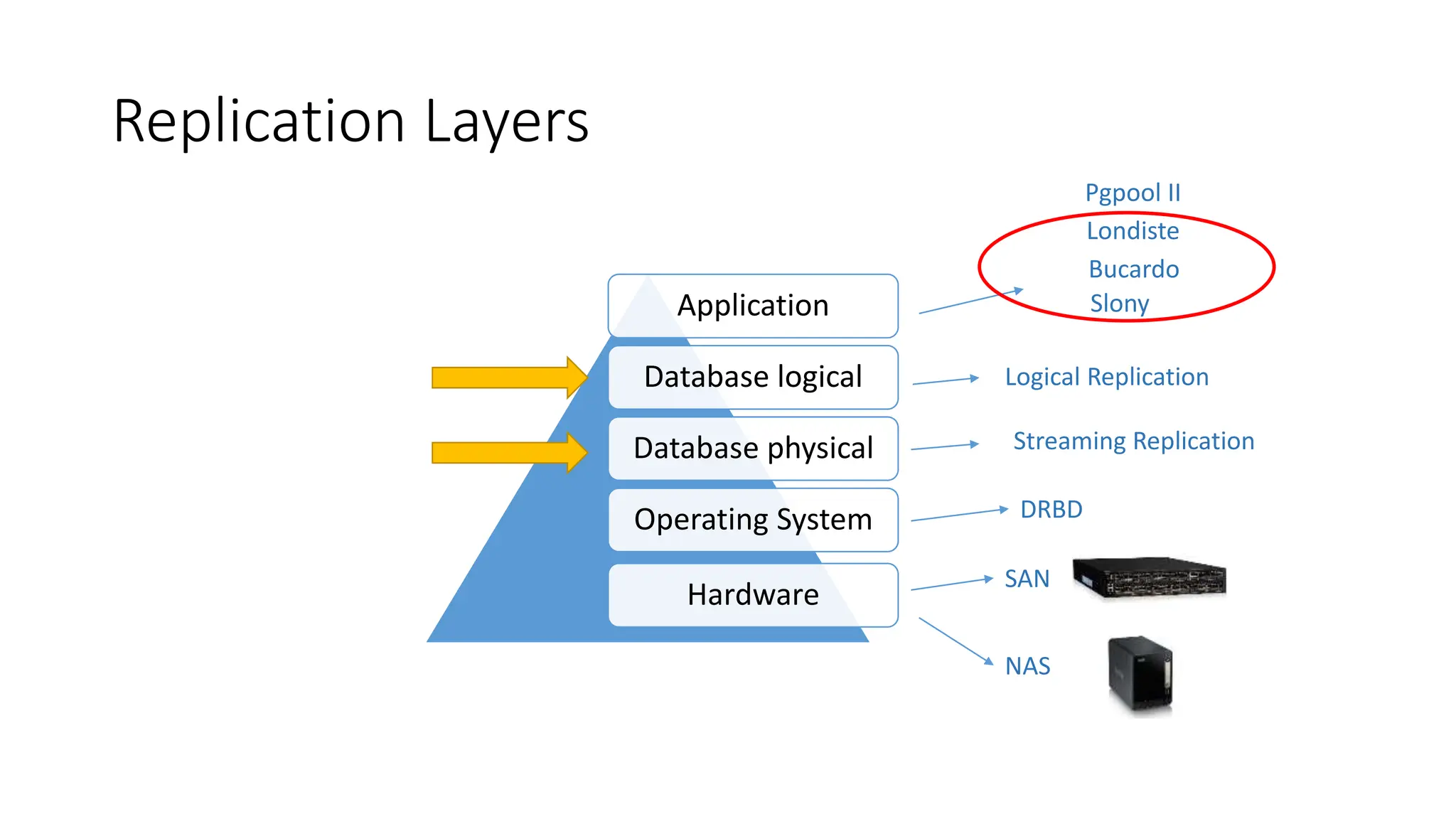
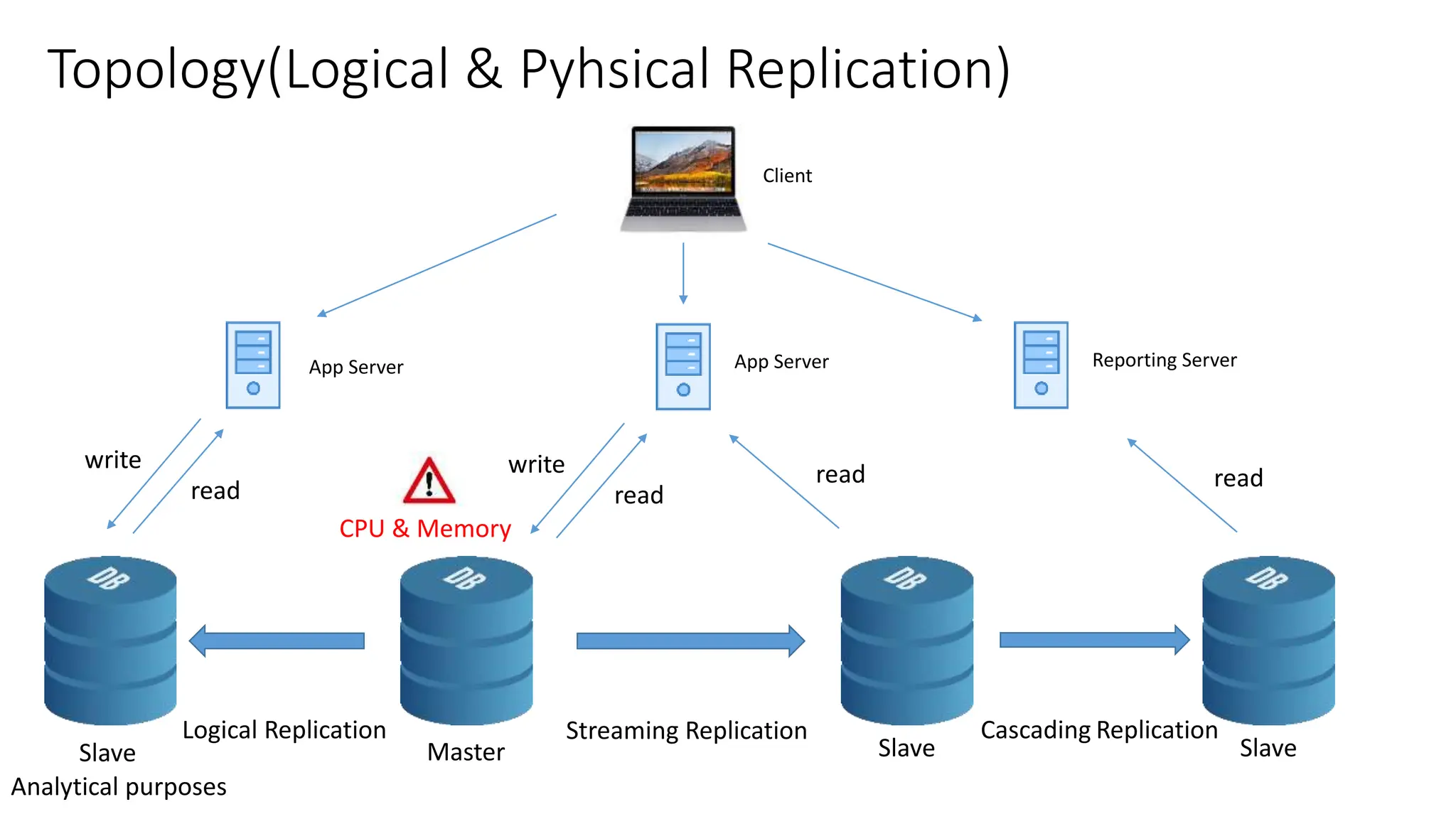
- The different layers of replication including database physical, database logical, and operating system layers.
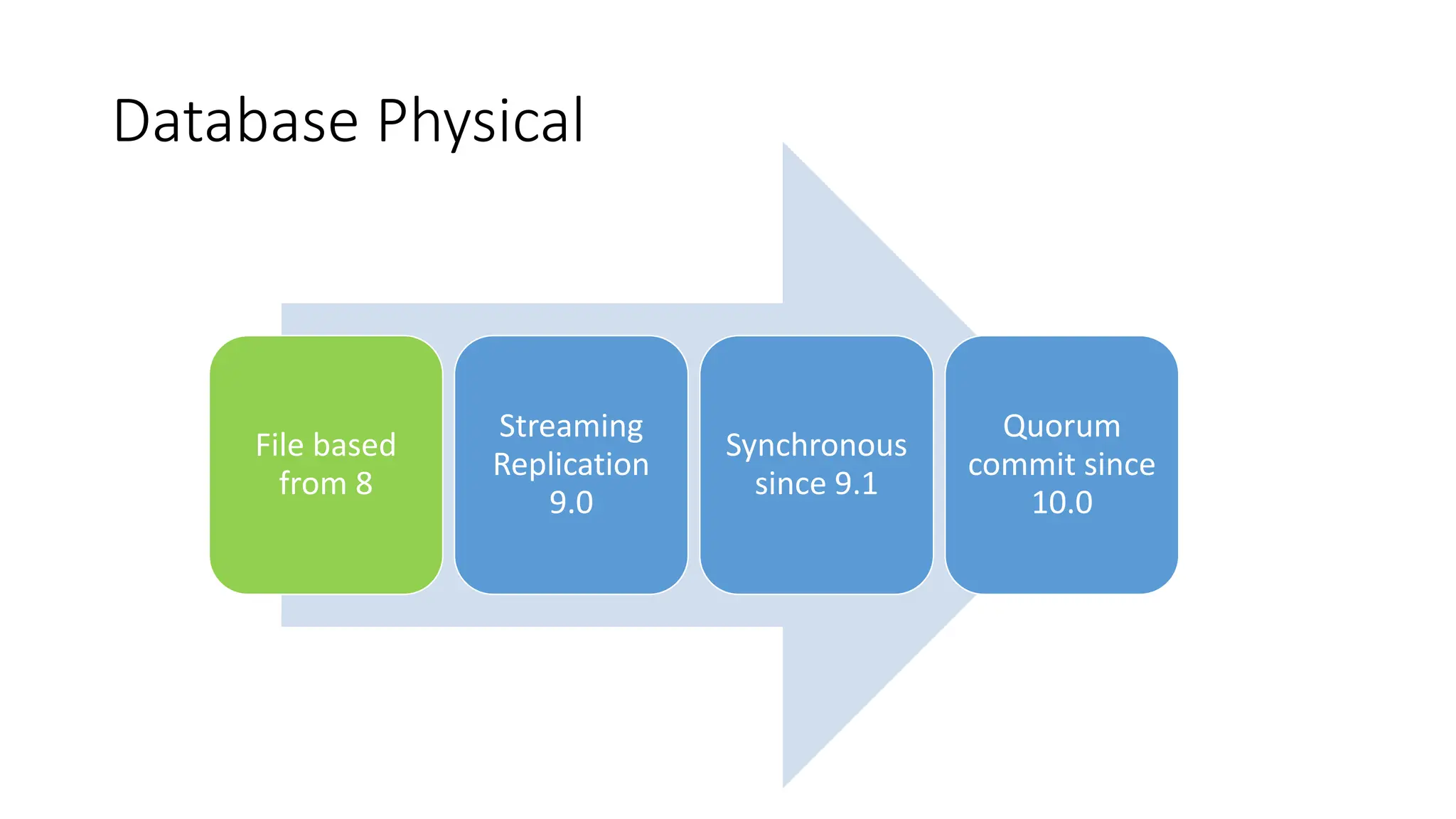
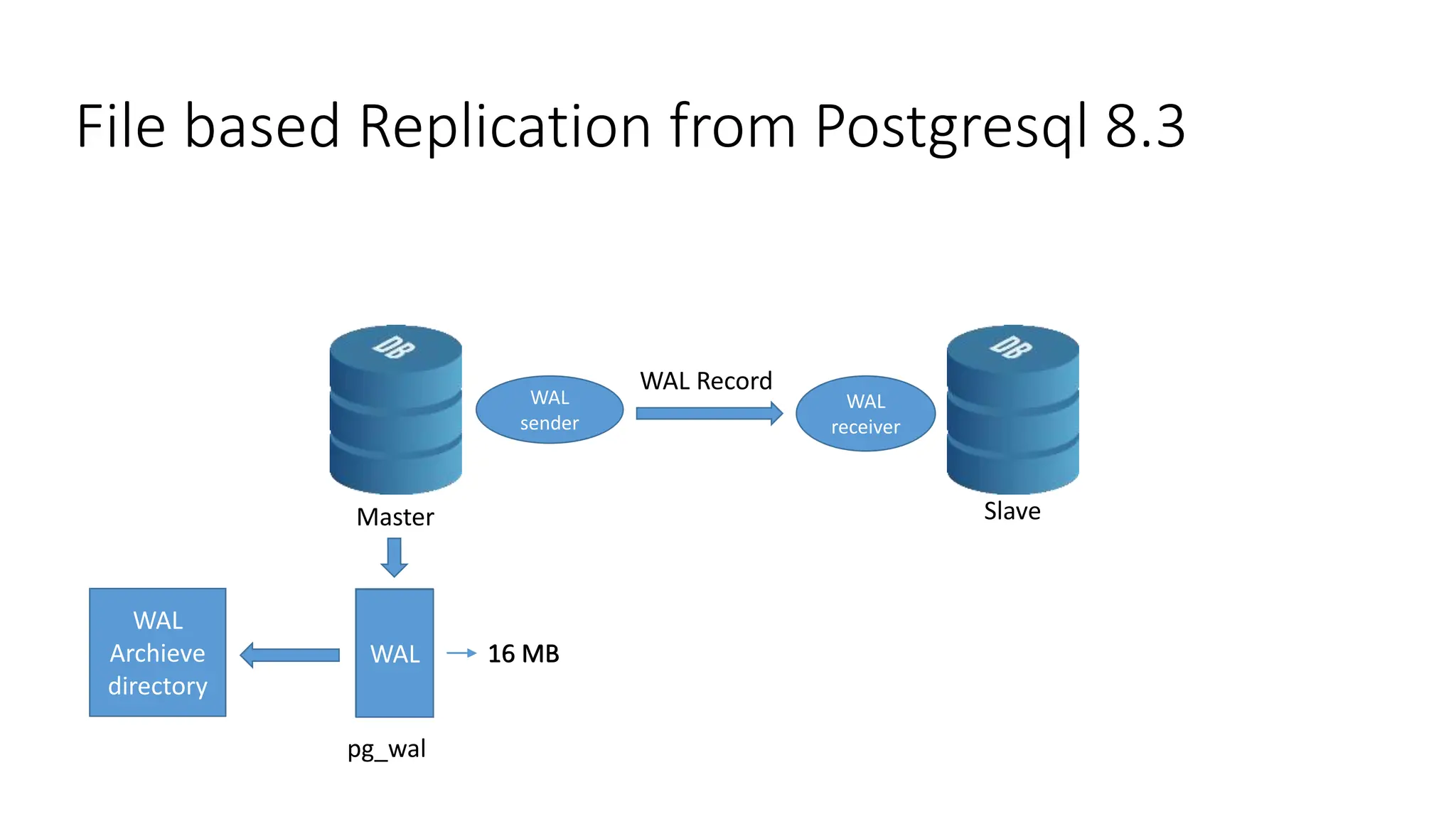
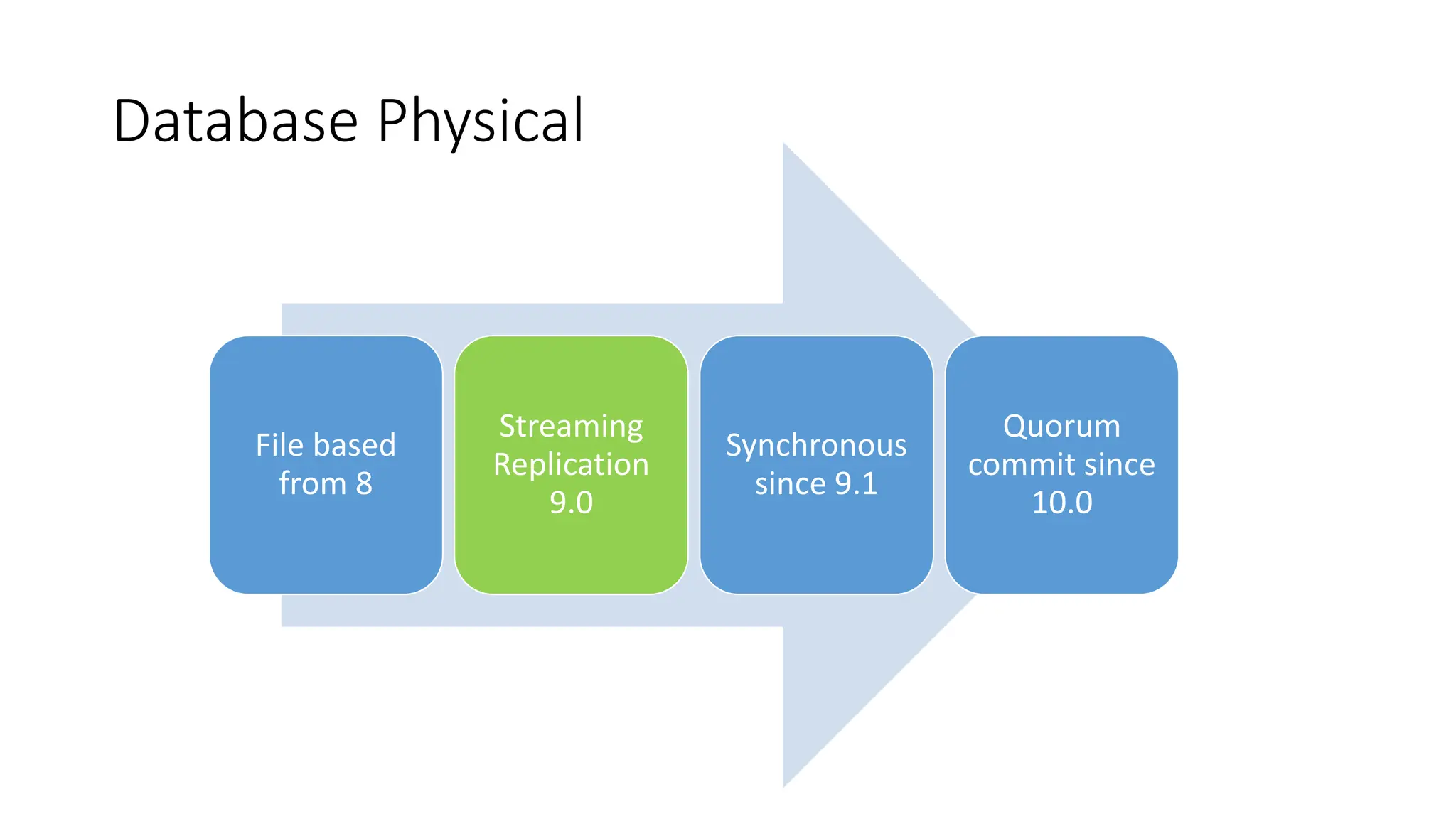
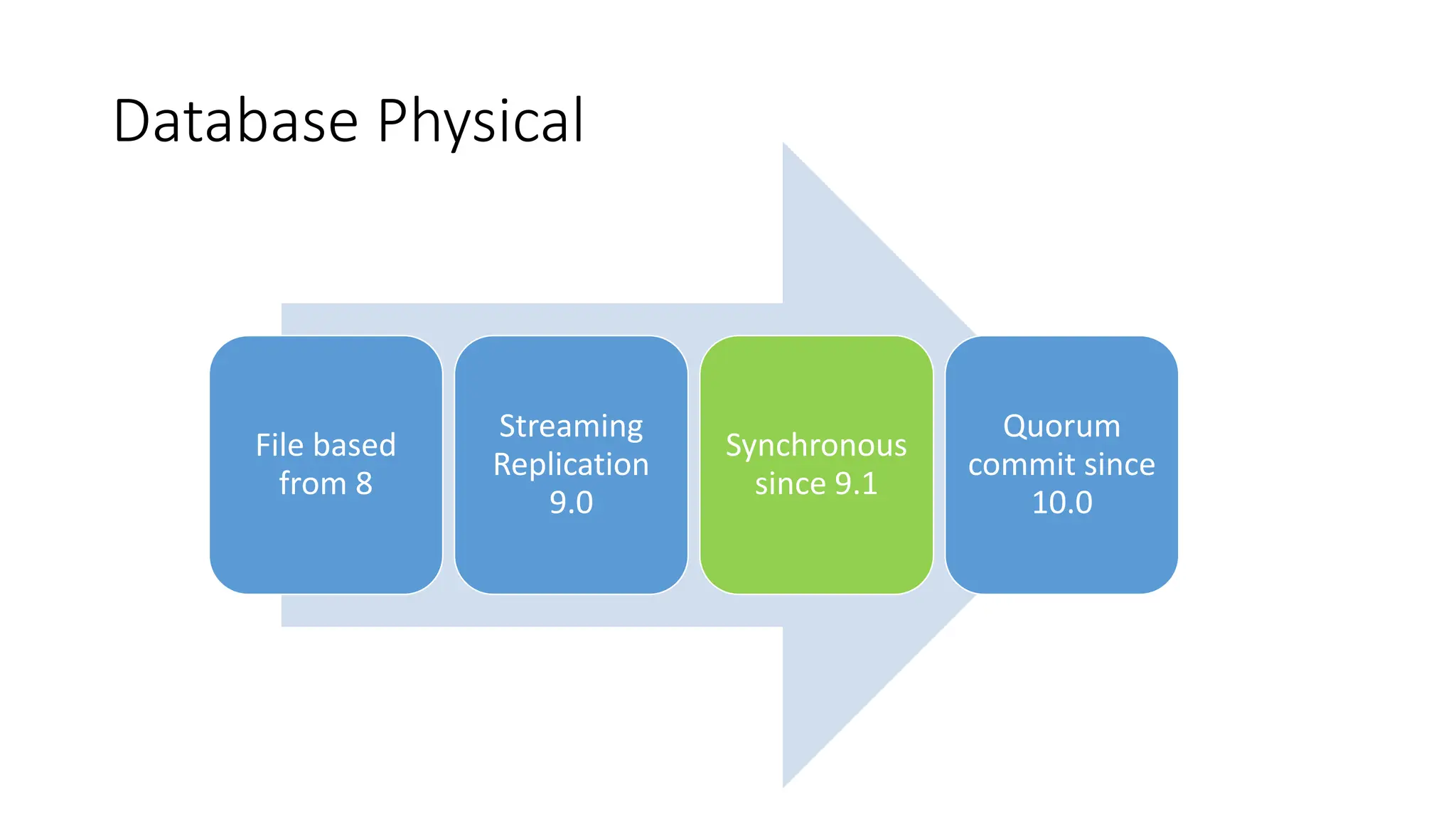
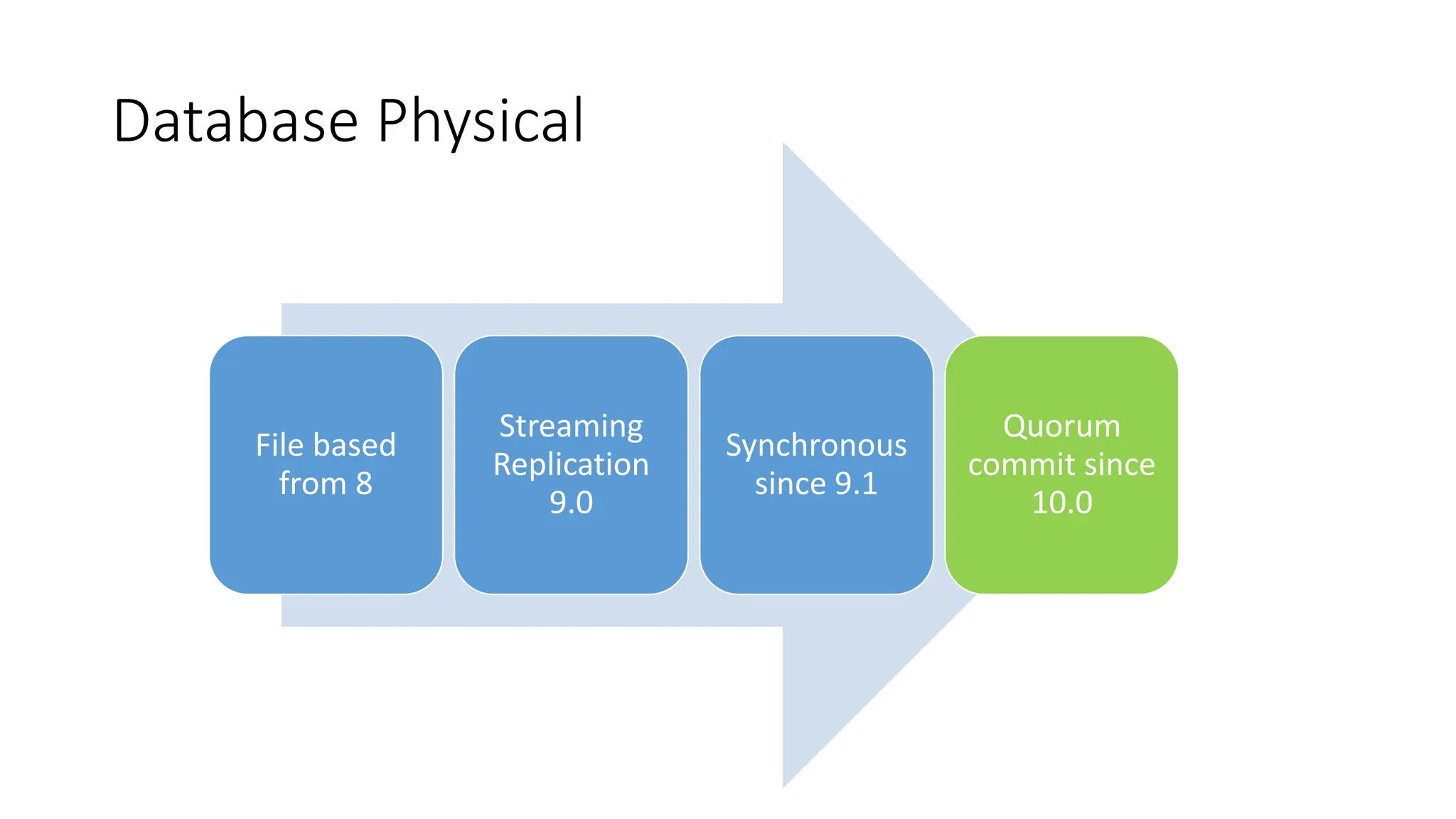
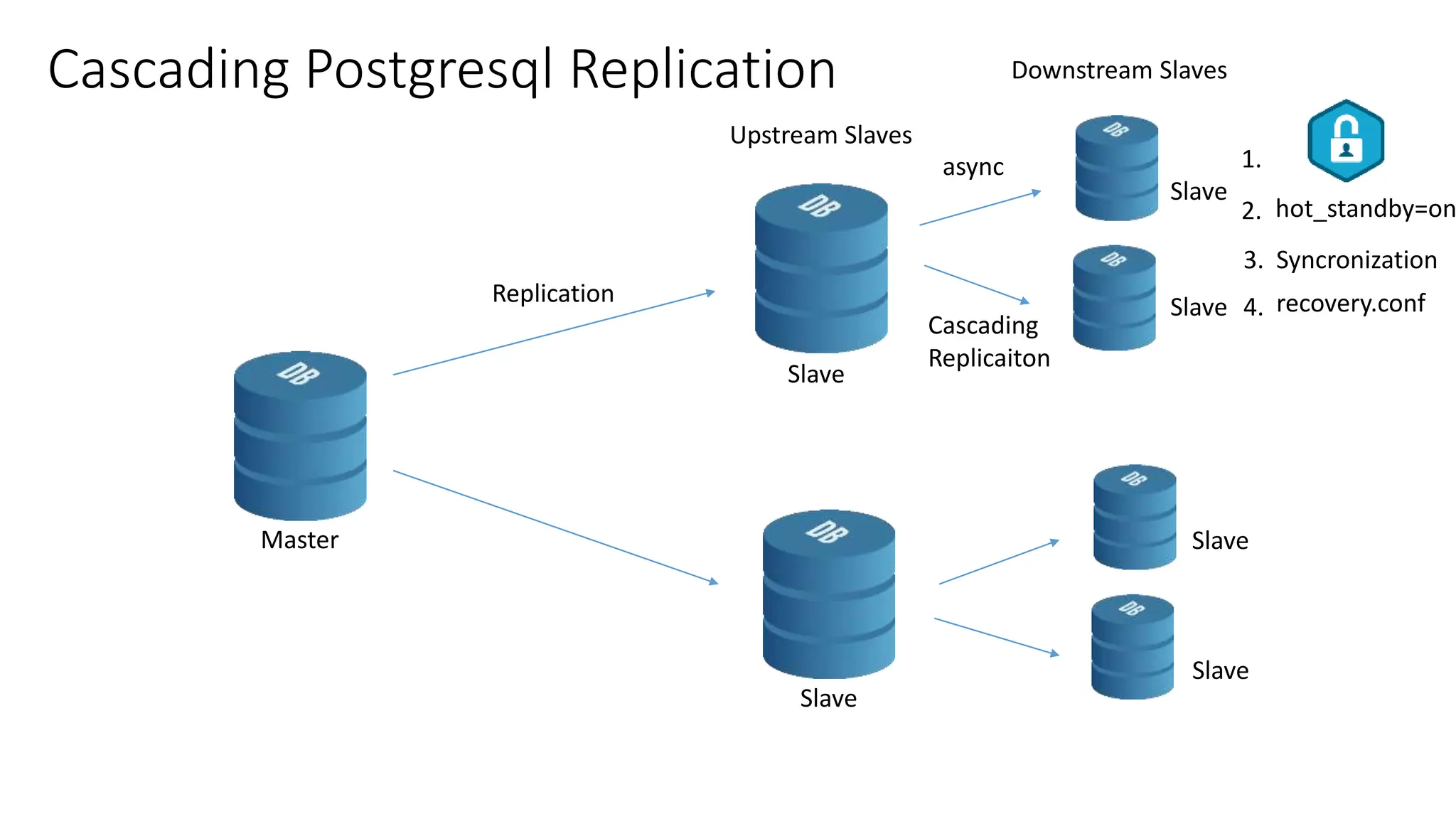
- The milestones of physical replication including file-based replication from PostgreSQL 8, streaming replication introduced in 9.0, and synchronous replication and quorum commit features added later.
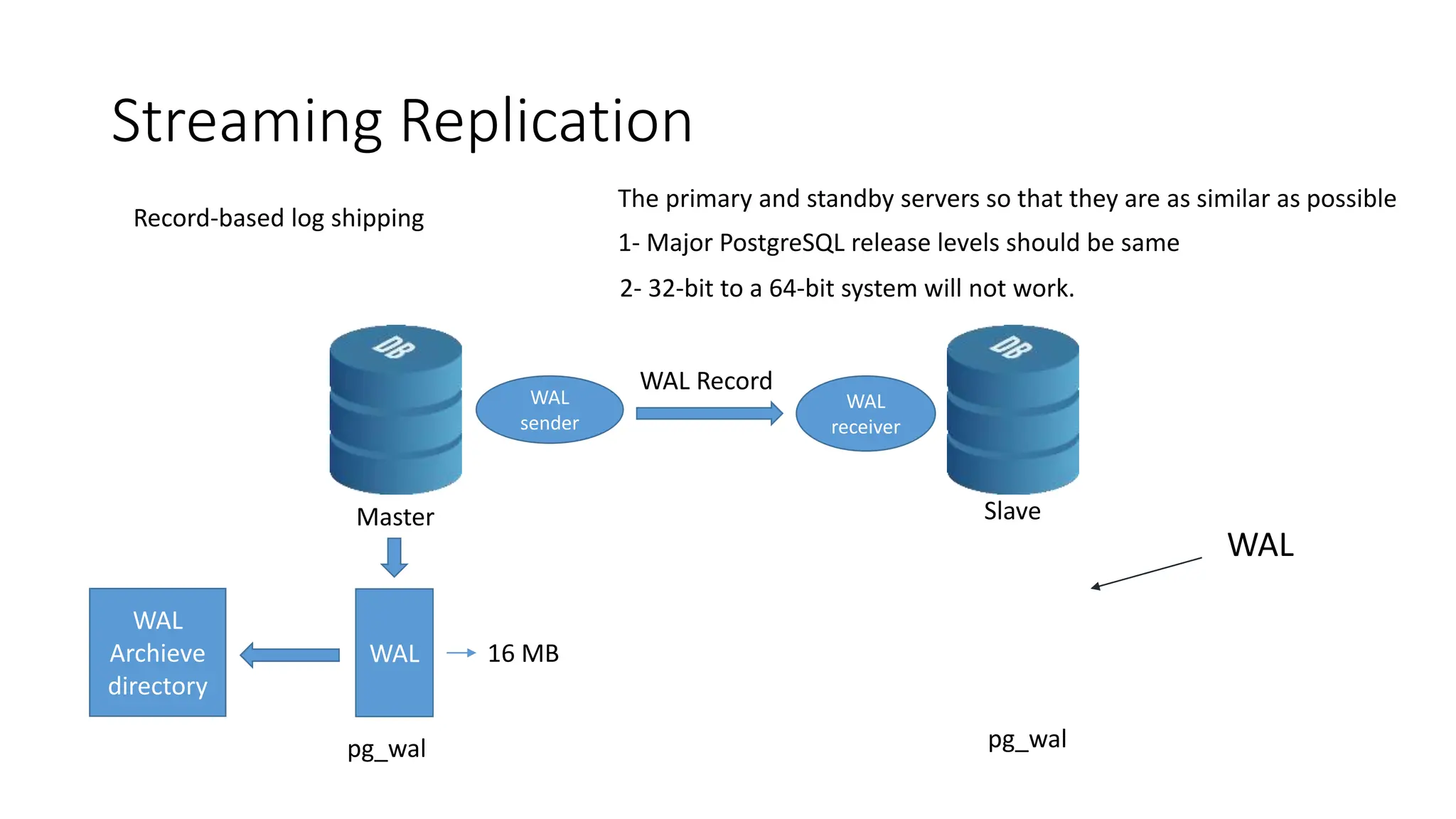
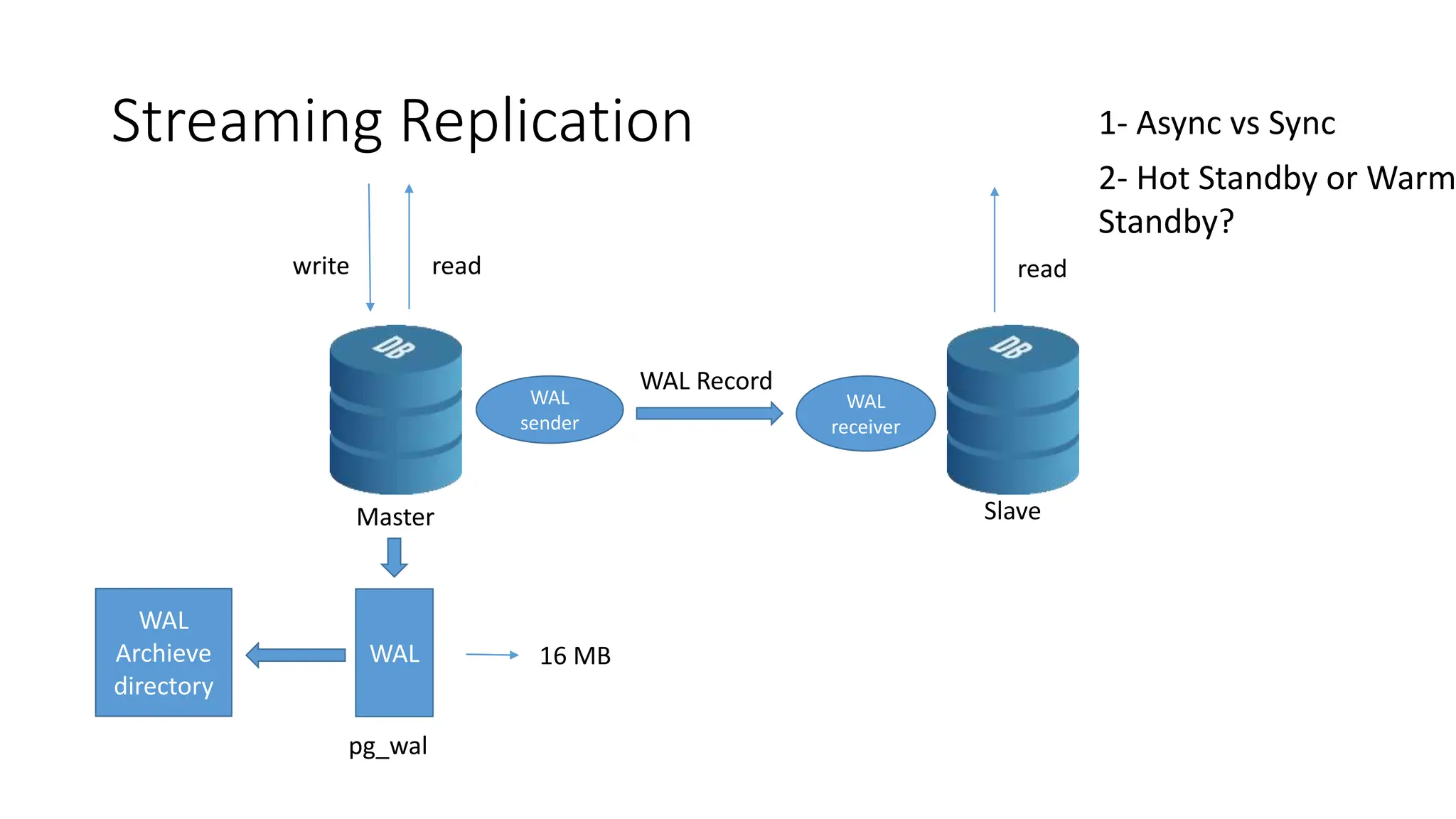
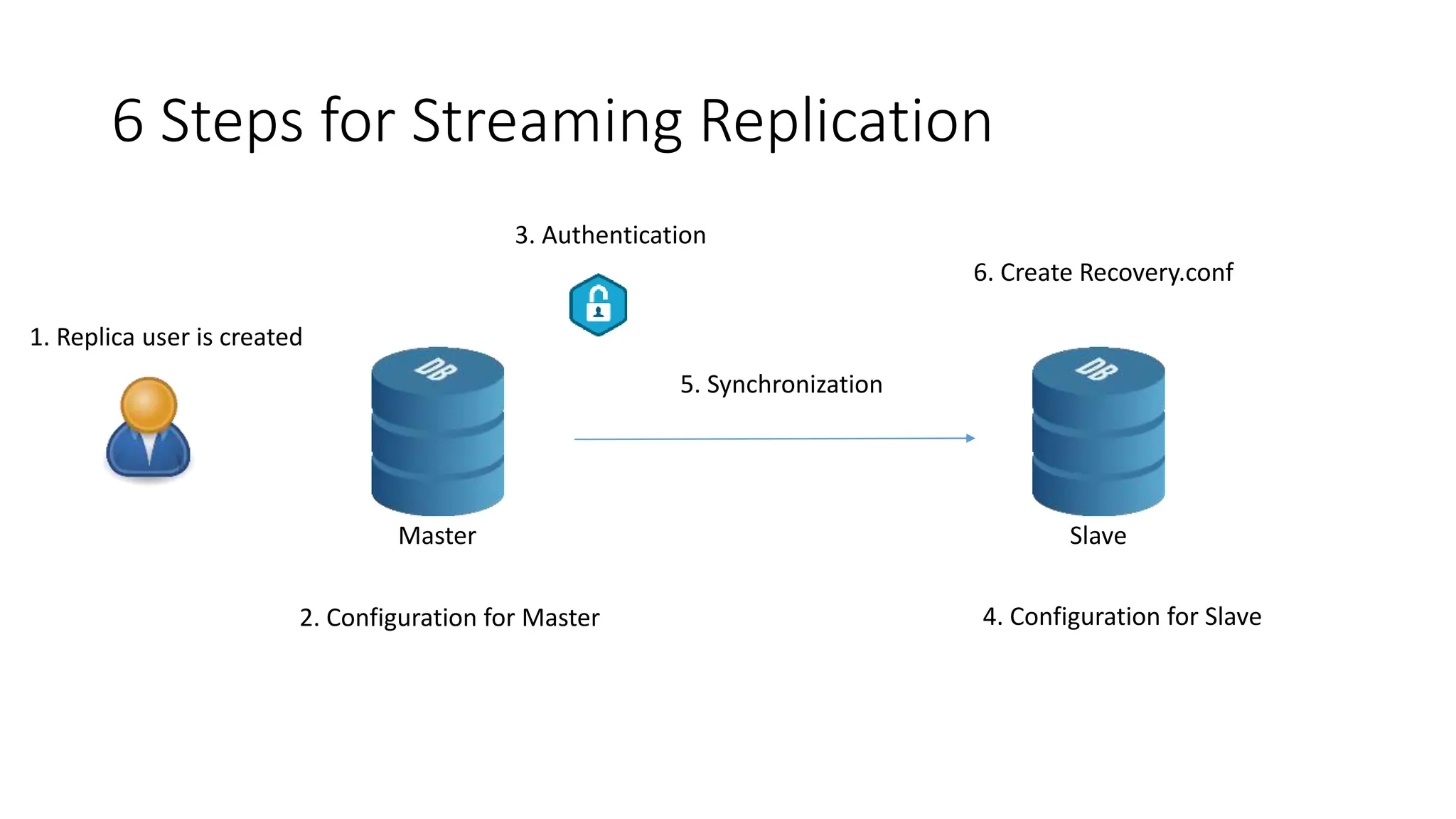
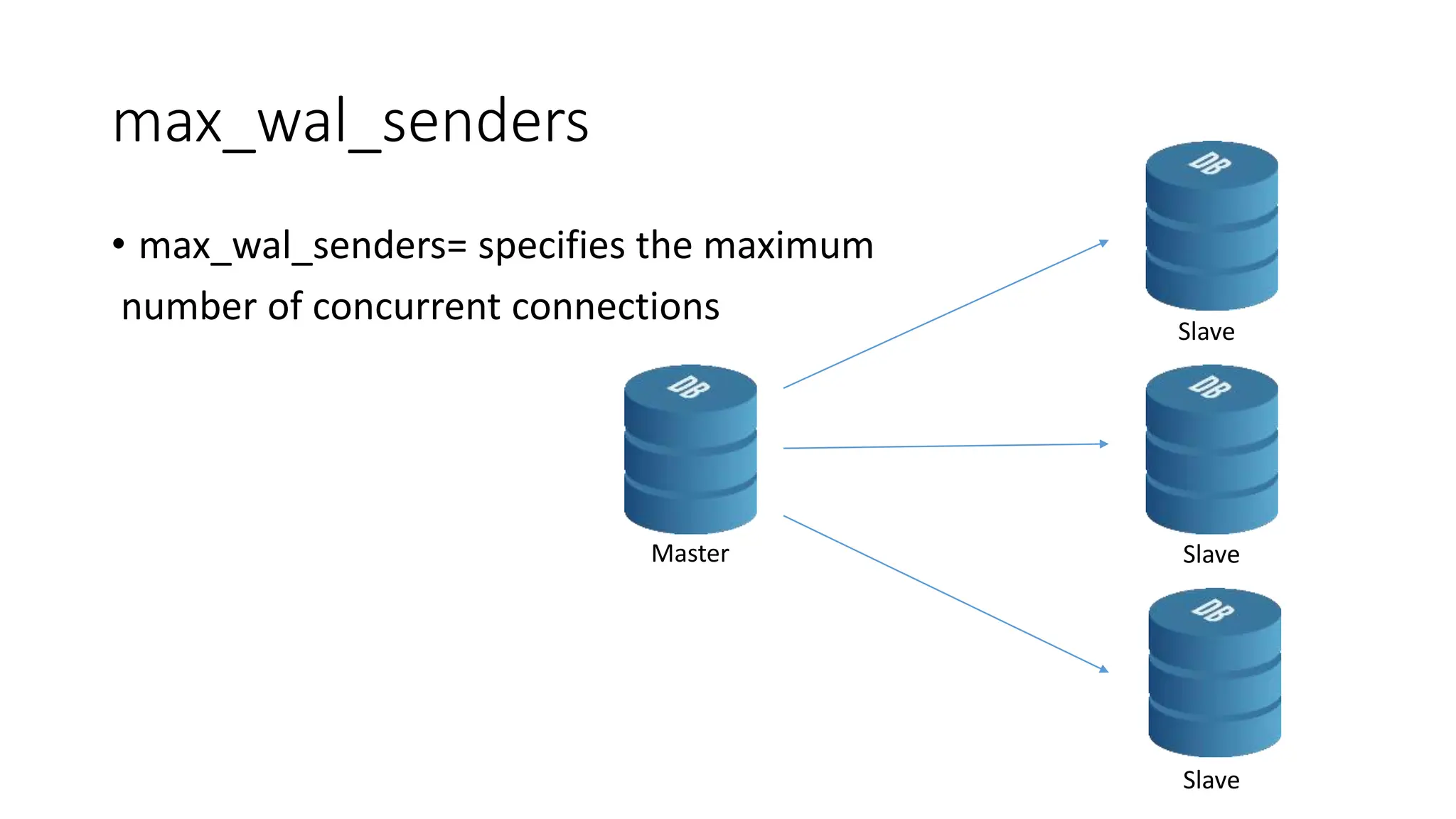
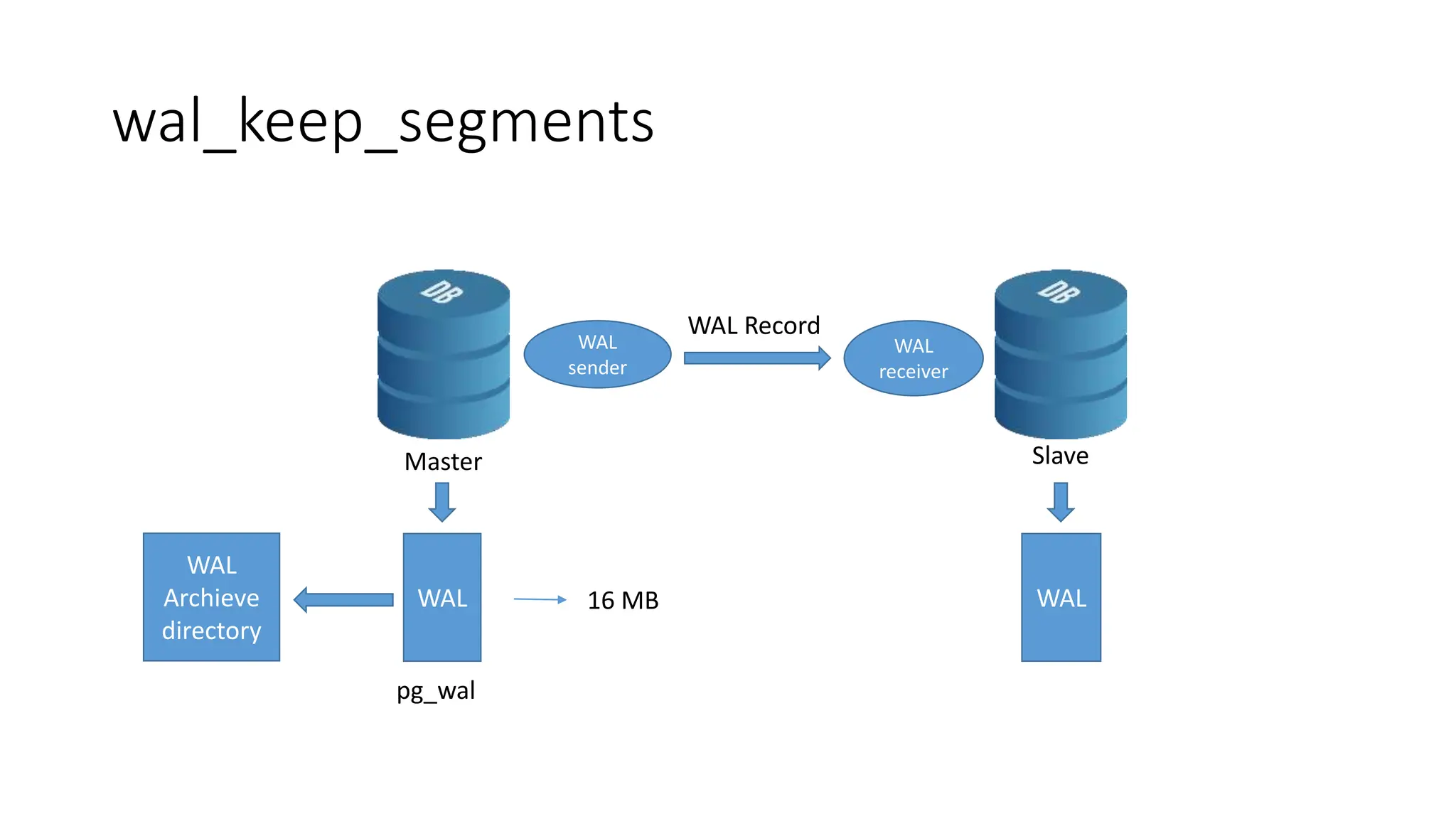
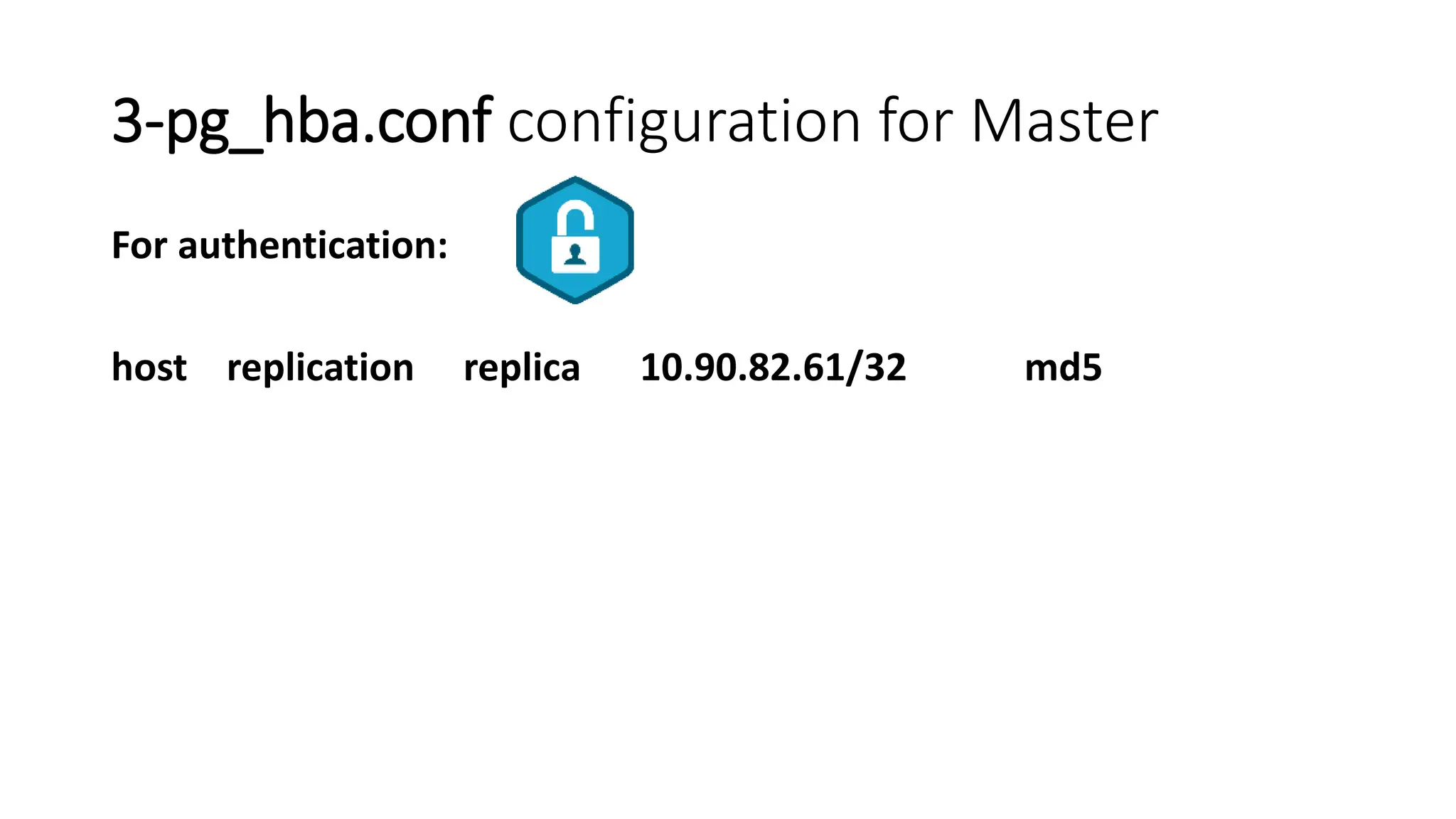
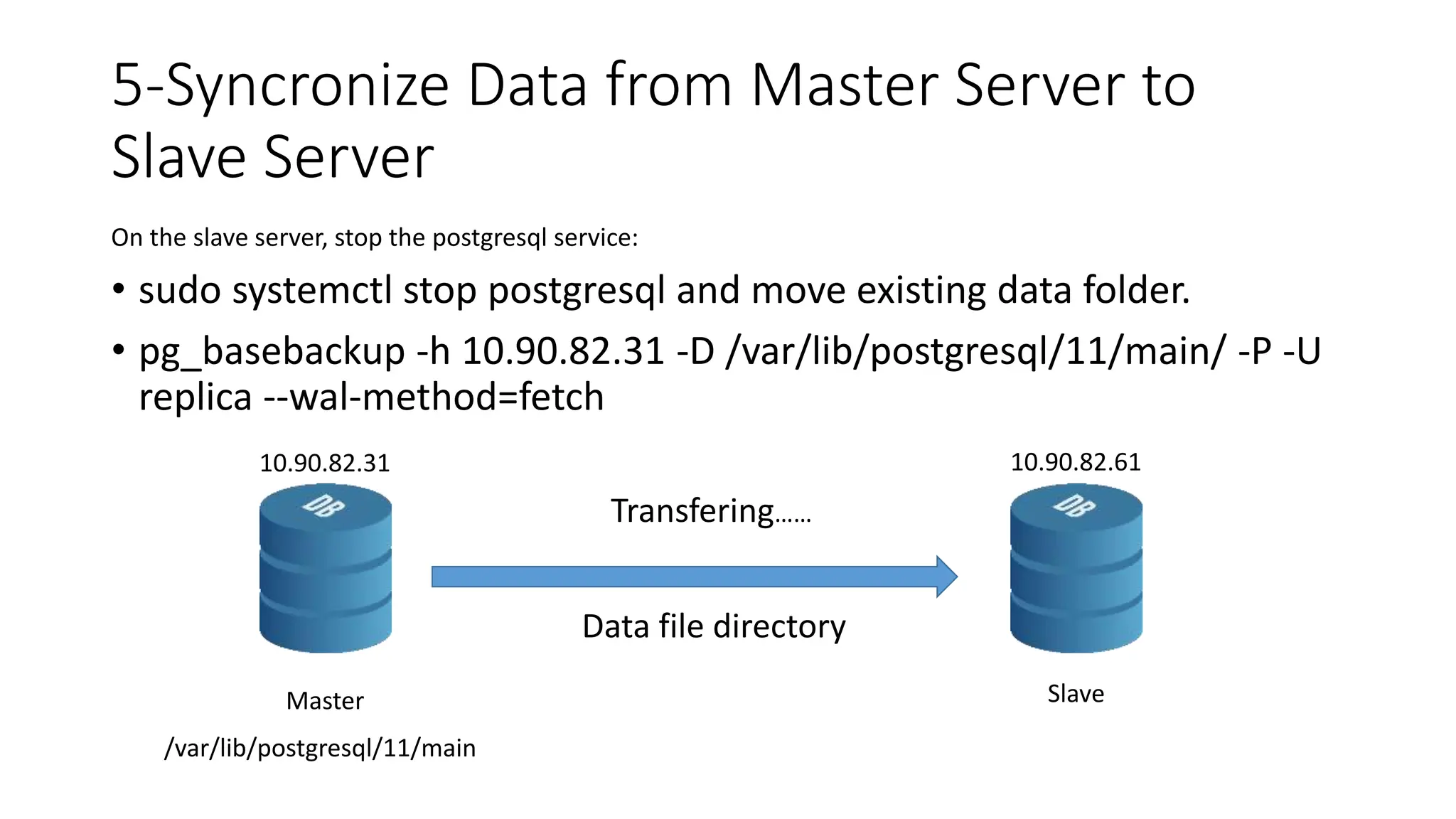
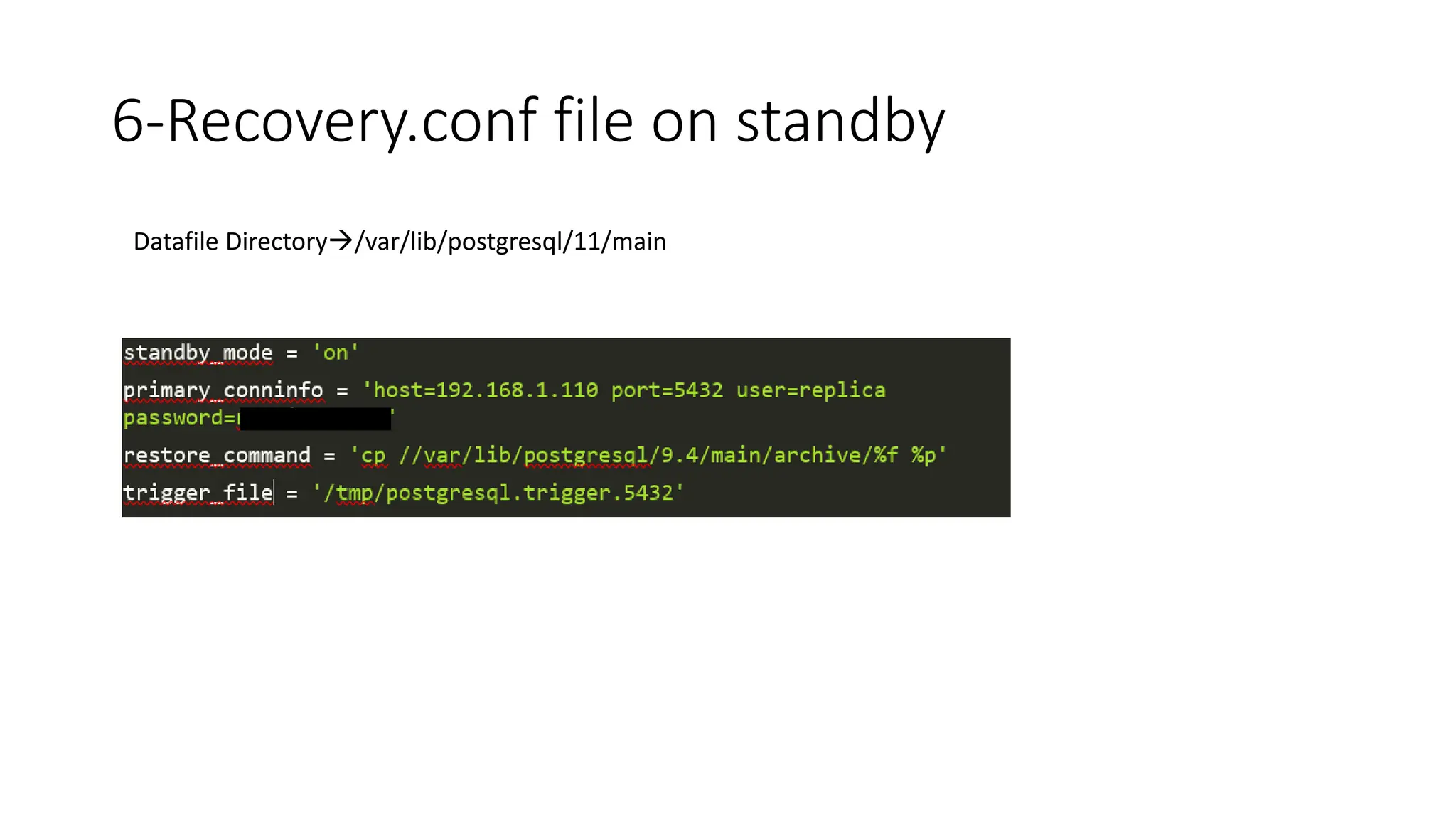
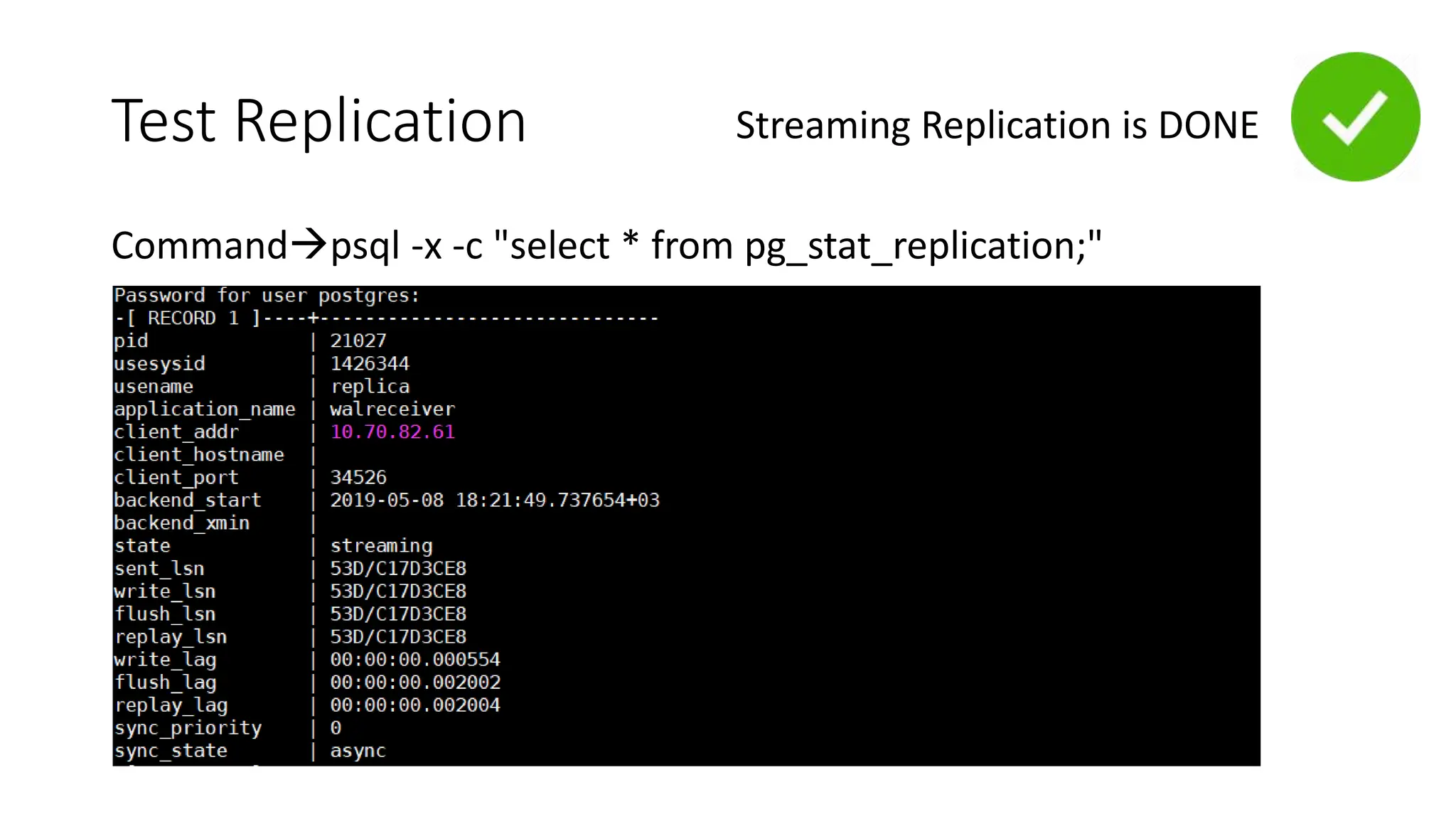
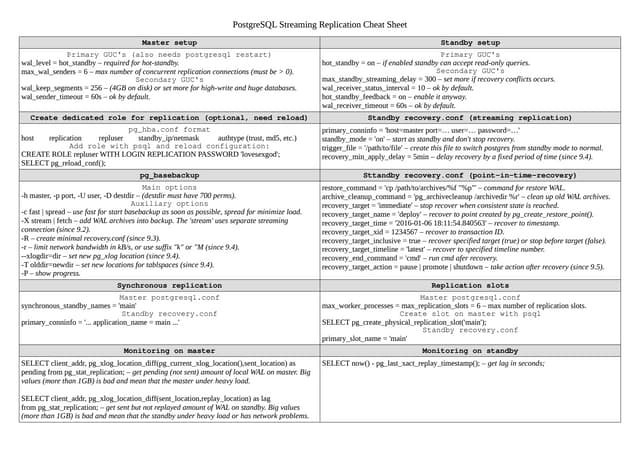
- How to set up streaming replication including configuring the master and standby servers, synchronizing data, and creating a recovery configuration file.
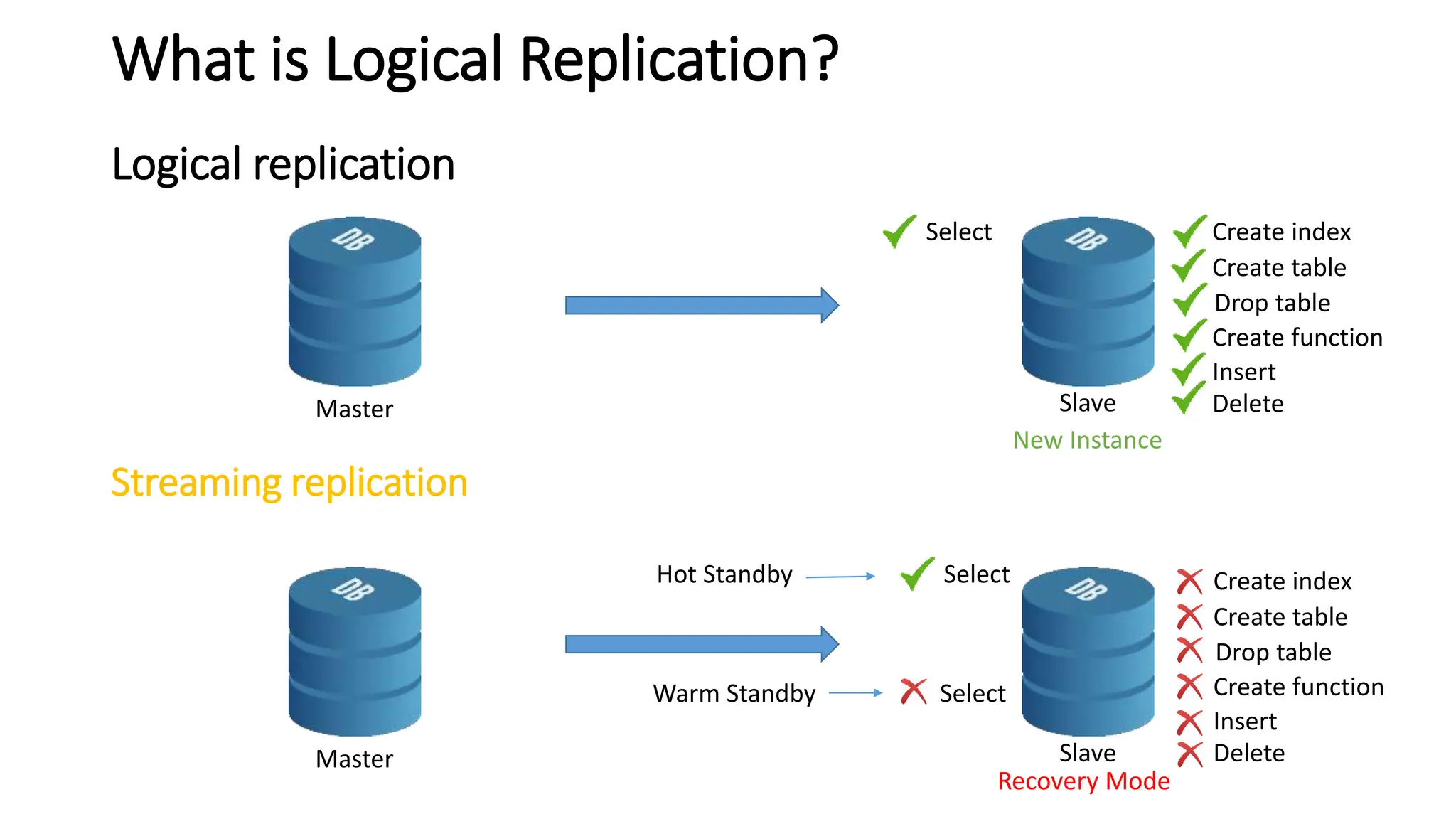
- Features of streaming replication like asynchronous vs synchronous modes and hot standby vs warm standby.
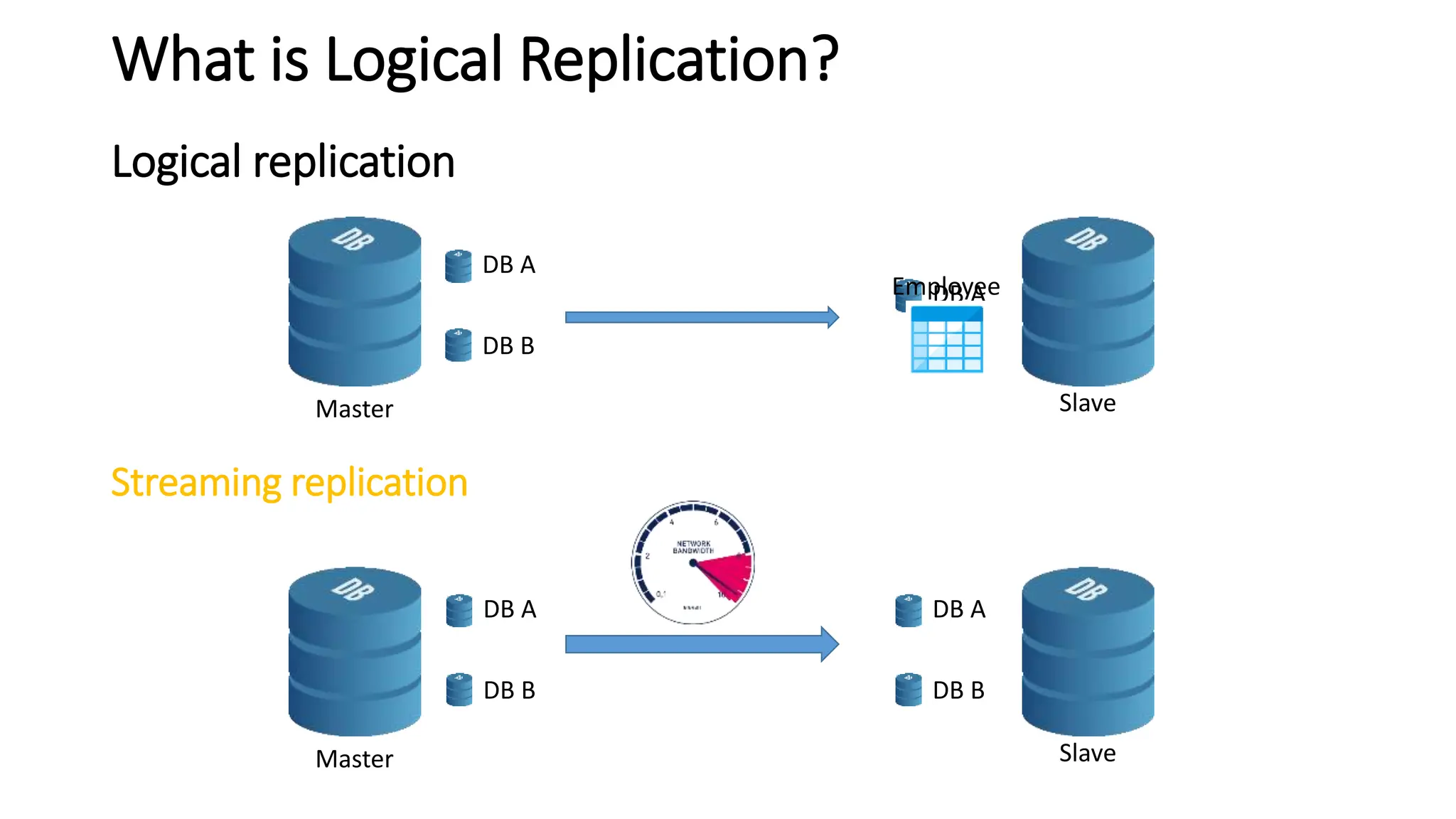
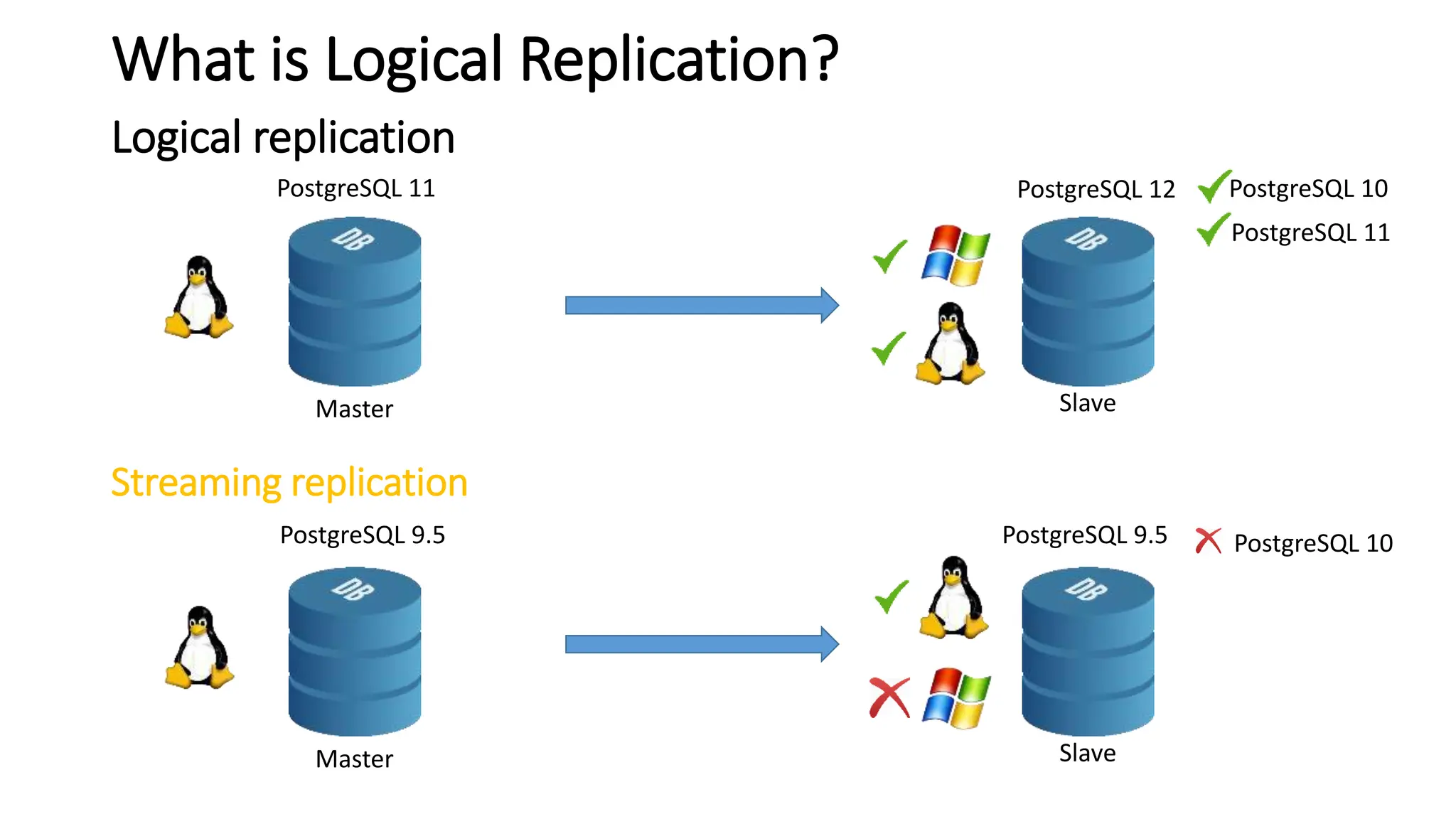
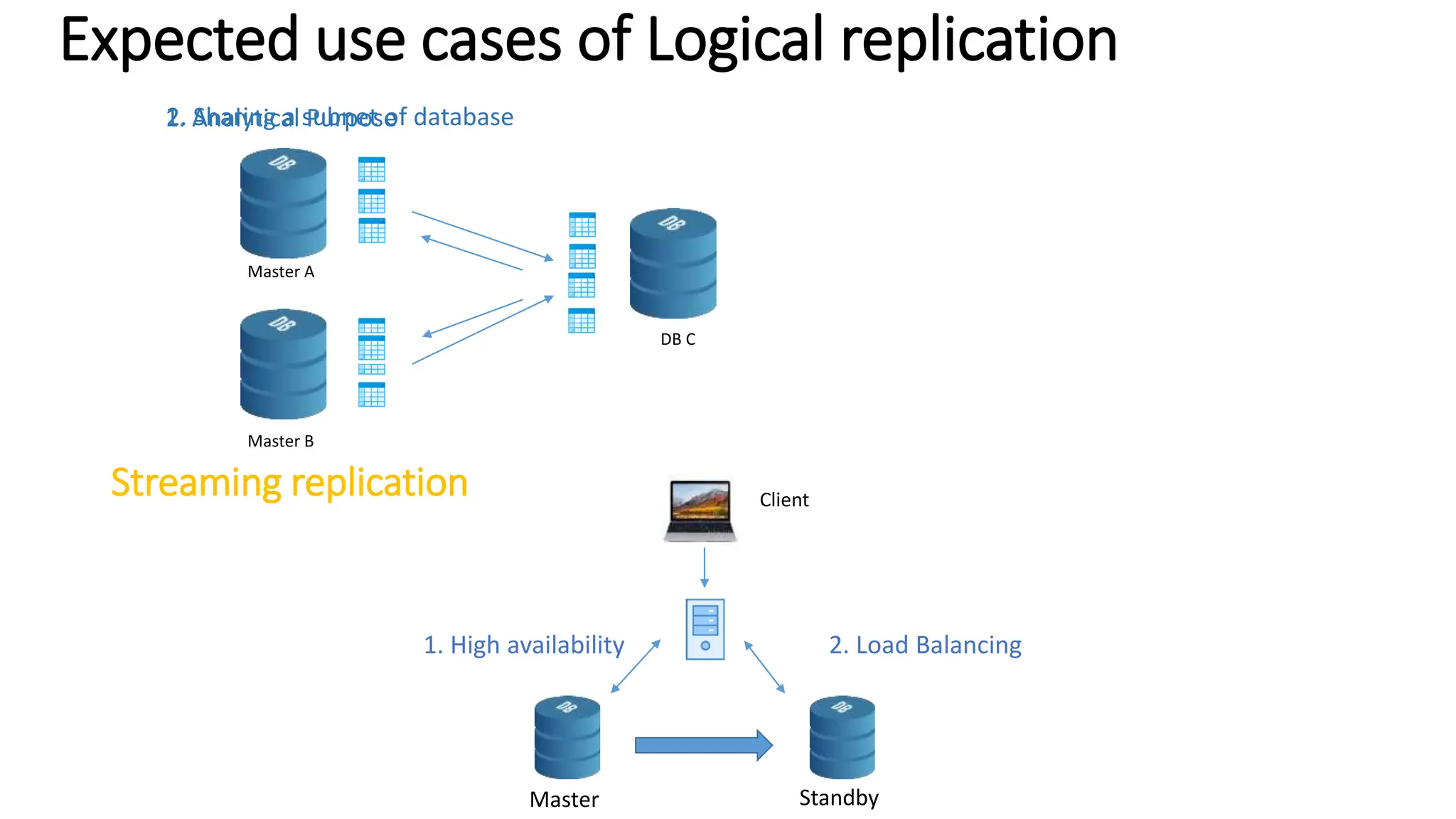
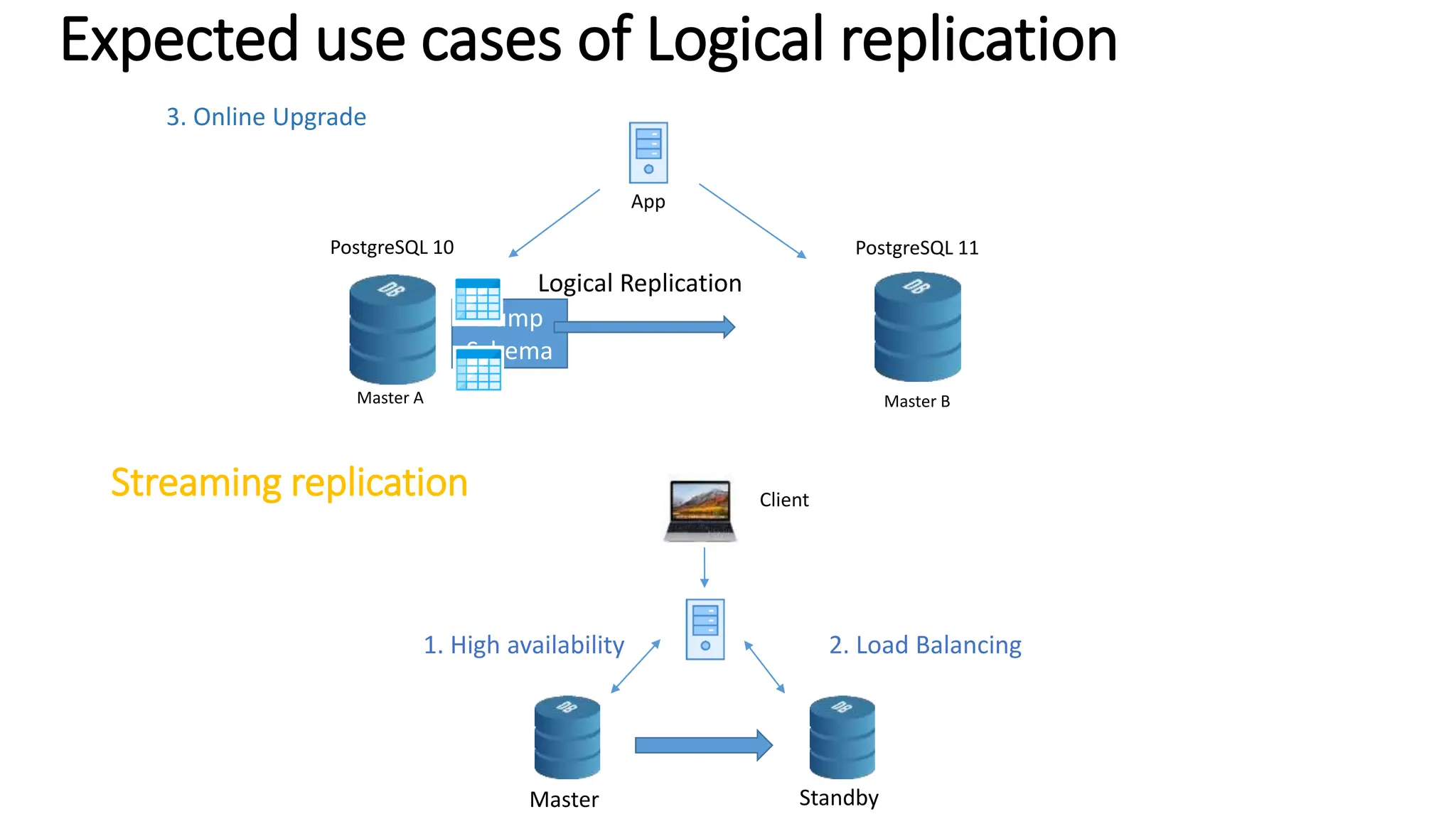
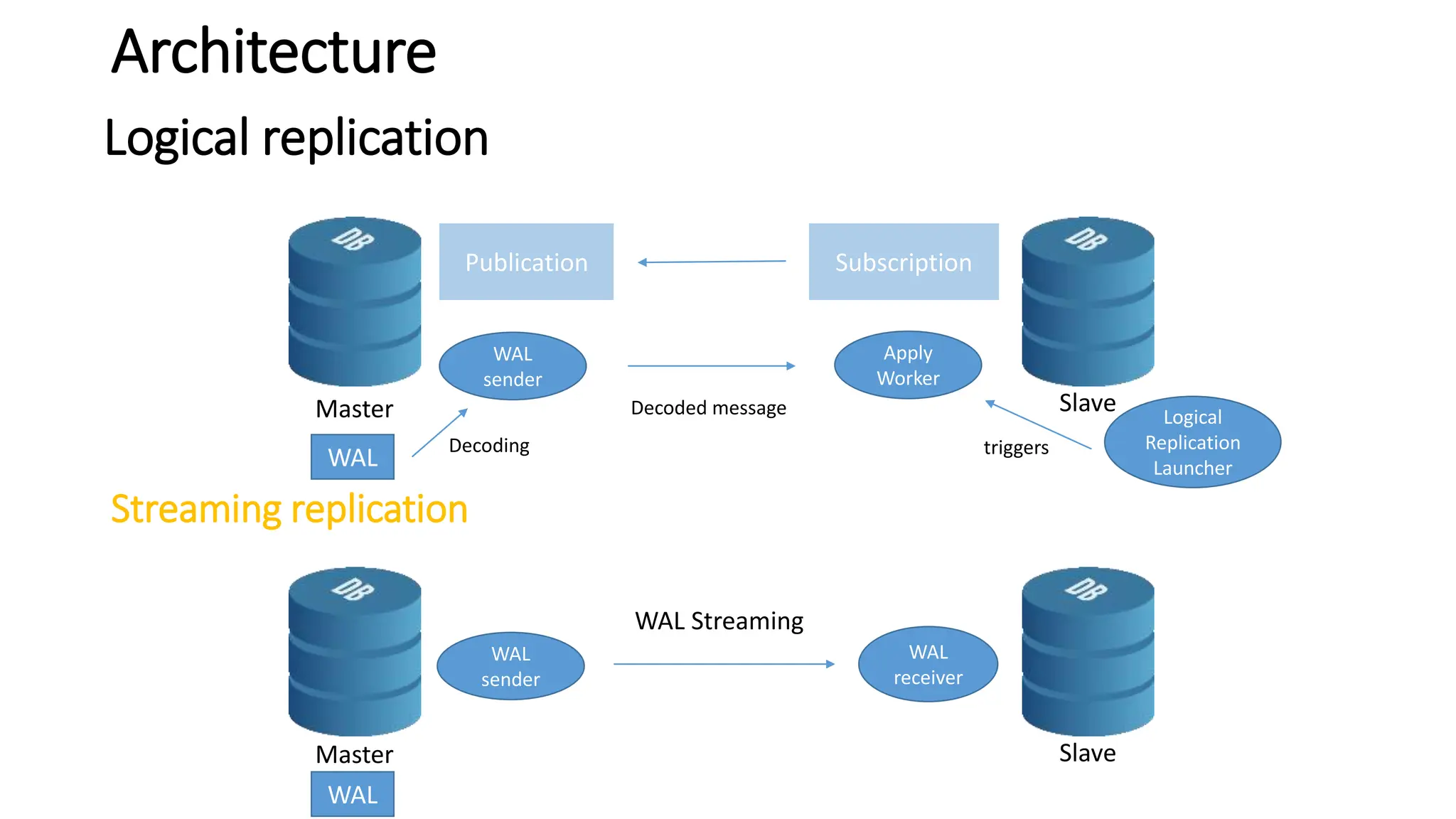
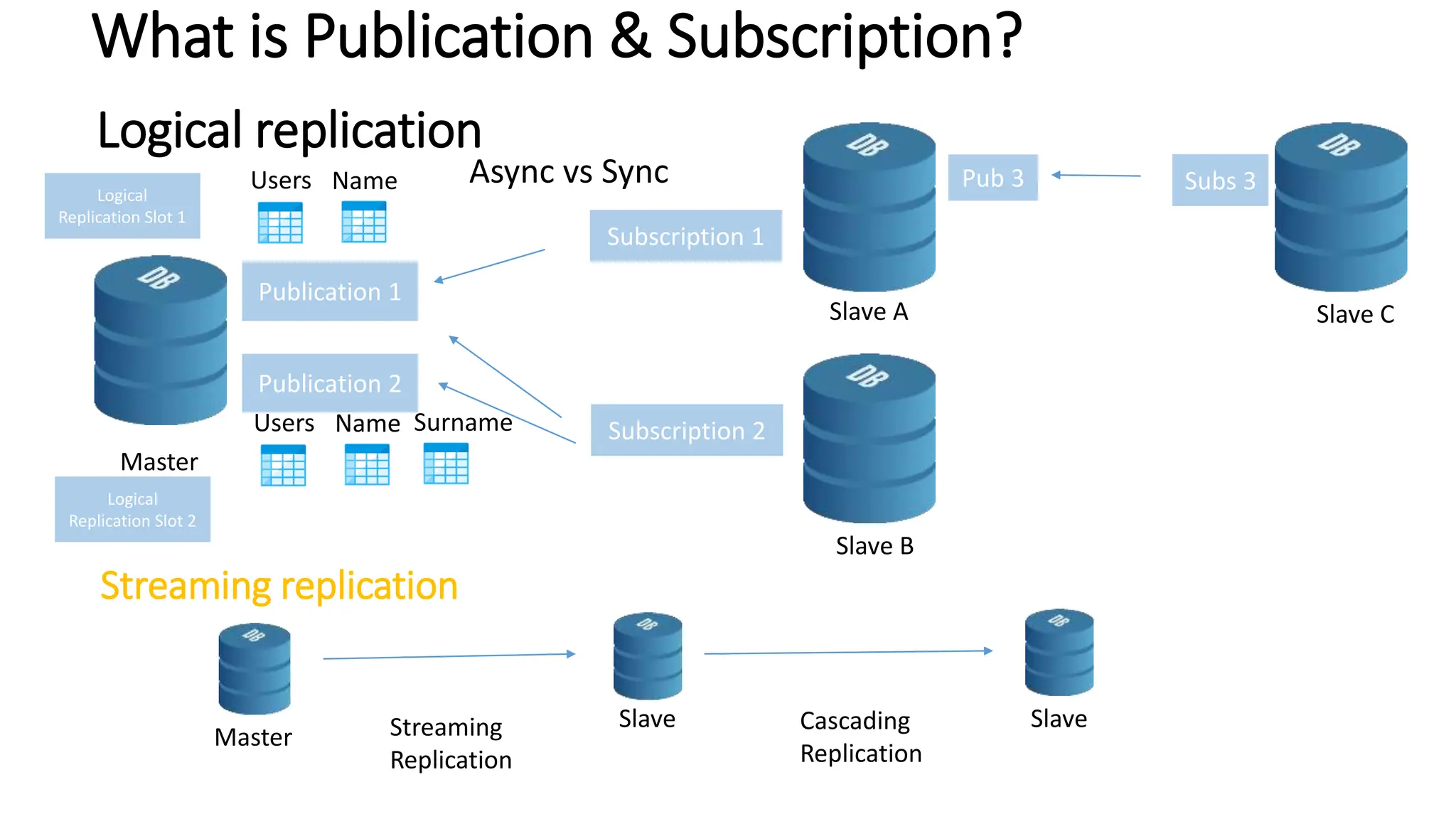
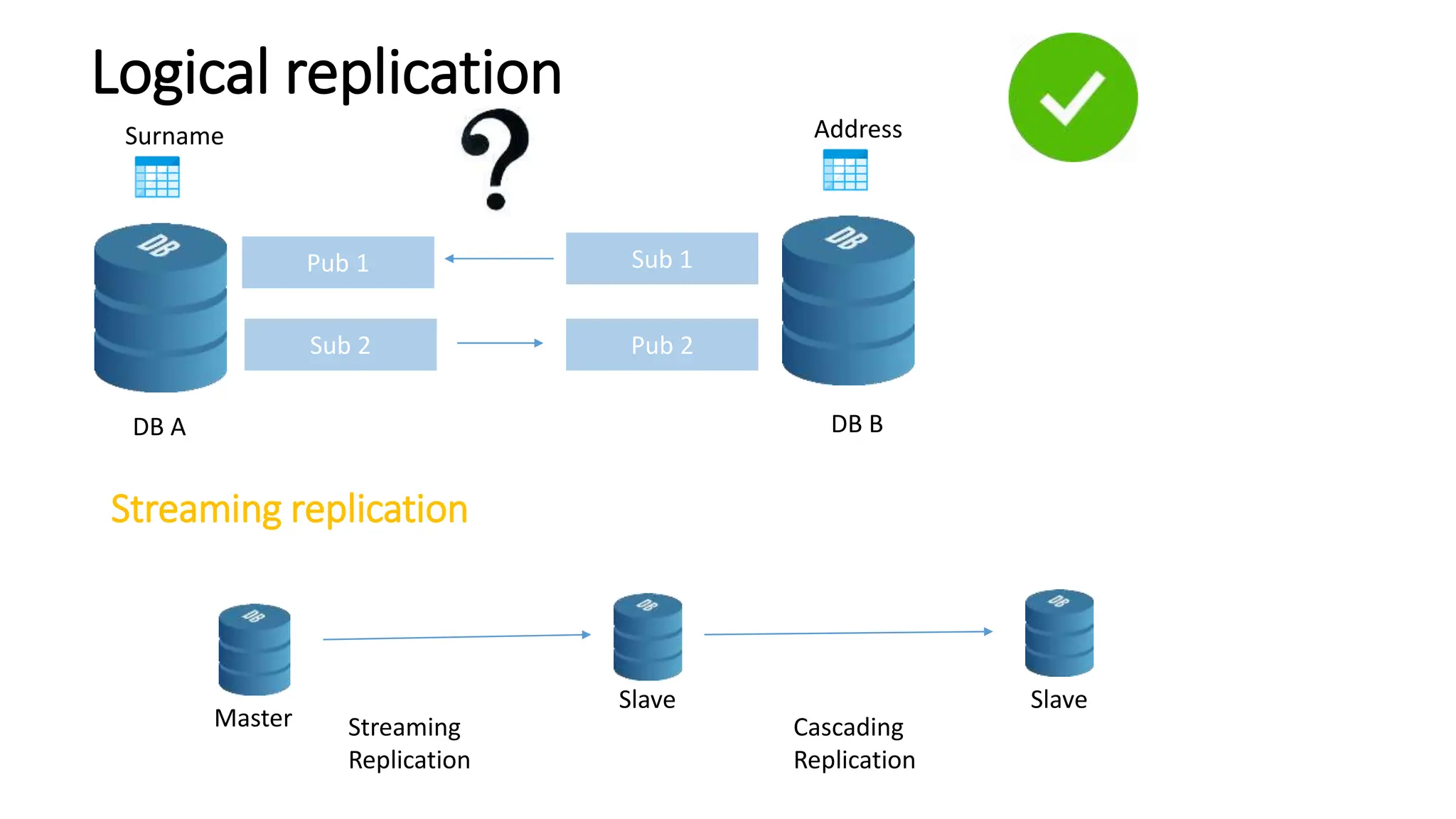
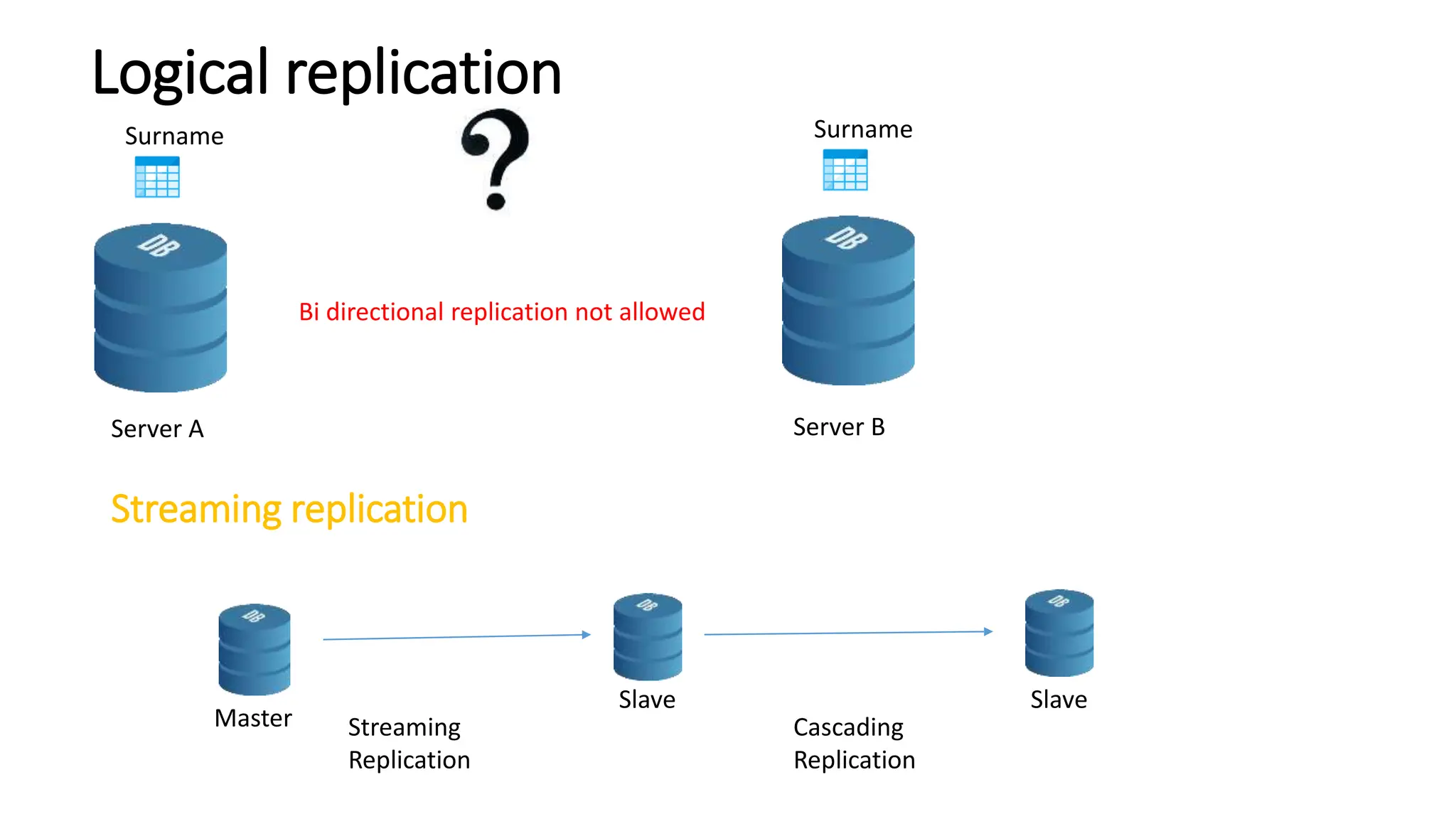
- Logical replication introduced in PostgreSQL 10 and how it differs from physical replication by replic