Downloaded 15 times



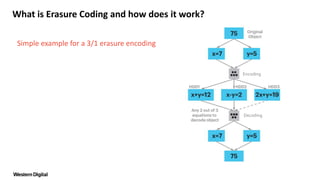
![What is Erasure Coding and how does it work?
Simple example for a 3/1 erasure encoding
• We solve for x:
OR
x+y=12 [+]
x-y= 2
2x =14 [∕2]
X = 7
2x+ y=19 [+]
x- y= 2
3x =21 [∕3]
X = 7
Encoding
Decoding](https://image.slidesharecdn.com/quickfaq-erasurecodingsplit-170214182948/85/Quick-Faq-Erasure-Coding-5-320.jpg)
![What is Erasure Coding and how does it work?
Simple example for a 3/1 erasure encoding
• We solve for x:
x+y=12 [+]
x-y= 2
2x =14 [∕2]
X = 7
Encoding
Decoding](https://image.slidesharecdn.com/quickfaq-erasurecodingsplit-170214182948/85/Quick-Faq-Erasure-Coding-6-320.jpg)
![What is Erasure Coding and how does it work?
Simple example for a 3/1 erasure encoding
• We solve for x:
OR
• Then we solve for y:
x+y=12 [+]
x-y= 2
2x =14 [∕2]
X = 7
2x+ y=19 [+]
x- y= 2
3x =21 [∕3]
X = 7
7+y=12 [-7]
y=5
Encoding
Decoding](https://image.slidesharecdn.com/quickfaq-erasurecodingsplit-170214182948/85/Quick-Faq-Erasure-Coding-7-320.jpg)
![What is Erasure Coding and how does it work?
Simple example for a 3/1 erasure encoding
• We solve for x:
OR
• Then we solve for y:
OR
x+y=12 [+]
x-y= 2
2x =14 [∕2]
X = 7
2x+ y=19 [+]
x- y= 2
3x =21 [∕3]
X = 7
7-y= 2 [-7]
-y=-5 [*-1]
y=5
7+y=12 [-7]
y=5
Encoding
Decoding](https://image.slidesharecdn.com/quickfaq-erasurecodingsplit-170214182948/85/Quick-Faq-Erasure-Coding-8-320.jpg)










![What is Erasure Coding and how does it work?
Simple example for a 18/5 erasure encoding
• We solve for x:
OR
• Then we solve for y:
OR
x+y=12 [+]
x-y= 2
2x =14 [∕2]
X = 7
2x+ y=19 [+]
x- y= 2
3x =21 [∕3]
X = 7
7-y= 2 [-7]
-y=-5 [*-1]
y=5
7+y=12 [-7]
y=5
Encoding
Decoding
… …1 182
Any 13 of 18
equations to
decode object](https://image.slidesharecdn.com/quickfaq-erasurecodingsplit-170214182948/85/Quick-Faq-Erasure-Coding-19-320.jpg)


Erasure coding is a data protection technique that divides data into fragments and encodes them with redundant information, allowing for storage across different media and locations. This method enables recovery of the original data from a subset of fragments, facilitates convenient replacement of failed components, and can lower capital and operational expenses compared to traditional mirroring approaches. Examples of encoding configurations illustrate how specific numbers of fragments are necessary for data rehydration.





































































































