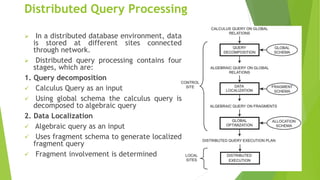
This document discusses query processing strategies in distributed databases. It describes three steps to query processing: parsing and translation, optimizing the query, and evaluating the query. For distributed databases, query processing has four stages: query decomposition, data localization, global optimization, and local optimization. Distributed query optimization aims to find efficient execution strategies by considering access methods, join criteria, and transmission costs. Different optimization algorithms are used depending on whether minimizing response time or total time is the goal.