Downloaded 51 times





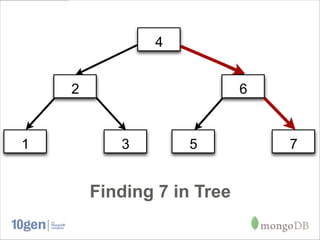





![What can be indexed?
// Multiple fields (compound key indexes)
db.recipes.ensureIndex({
main_ingredient: 1,
calories: -1
})
// Arrays of values (multikey indexes)
{
name: 'Chicken Noodle Soup’,
ingredients : ['chicken', 'noodles']
}
db.recipes.ensureIndex({ ingredients: 1 })](https://image.slidesharecdn.com/indexingqueryoptimization-130131142146-phpapp01/85/Indexing-Query-Optimization-17-320.jpg)






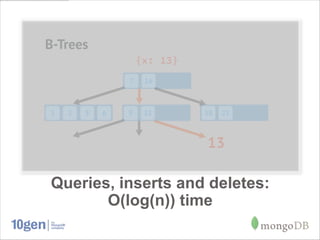
![Geospatial Indexes
// Add latitude, longitude coordinates
{
name: '10gen Palo Alto’,
loc: [ 37.449157, -122.158574 ]
}
// Index the coordinates
db.locations.ensureIndex( { loc : '2d' } )
// Query for locations 'near' a particular coordinate
db.locations.find({
loc: { $near: [ 37.4, -122.3 ] }
})](https://image.slidesharecdn.com/indexingqueryoptimization-130131142146-phpapp01/85/Indexing-Query-Optimization-24-320.jpg)














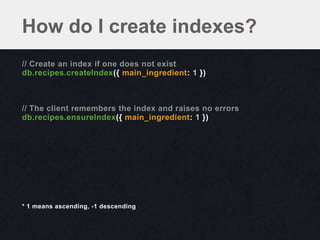
![Low Selectivity Indexes
db.collection.distinct('status’)
[ 'new', 'processed' ]
db.collection.ensureIndex({ status: 1 })
// Low selectivity indexes provide little benefit
db.collection.find({ status: 'new' })
// Better
db.collection.ensureIndex({ status: 1, created_at: -1 })
db.collection.find(
{ status: 'new' }
).sort({ created_at: -1 })](https://image.slidesharecdn.com/indexingqueryoptimization-130131142146-phpapp01/85/Indexing-Query-Optimization-40-320.jpg)

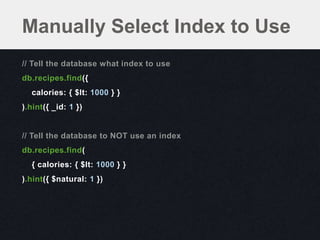
![Negation
// Indexes aren't helpful with negations
db.things.ensureIndex({ x: 1 })
// e.g. "not equal" queries
db.things.find({ x: { $ne: 3 } })
// …or "not in" queries
db.things.find({ x: { $nin: [2, 3, 4 ] } })
// …or the $not operator
db.people.find({ name: { $not: 'John Doe' } })](https://image.slidesharecdn.com/indexingqueryoptimization-130131142146-phpapp01/85/Indexing-Query-Optimization-42-320.jpg)



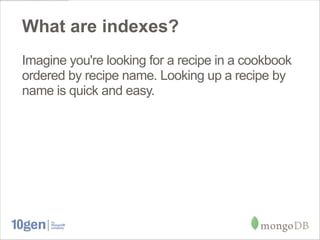
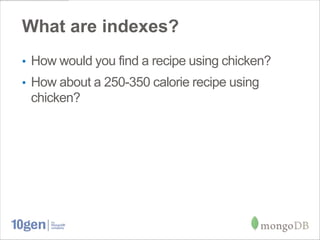
This document provides an overview of indexing in MongoDB. It discusses what indexes are, why they are needed to optimize queries, and how to work with indexes in MongoDB. Some key points covered include how to create, manage, and optimize indexes. Common indexing mistakes are also discussed, such as trying to use multiple indexes per query, having indexes with low selectivity, and queries that cannot use indexes like regular expressions and negation queries.








![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)








![[AWS Builders] Effective AWS Glue](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws301effectiveawsgluetaehyunkim-190306061037-thumbnail.jpg?width=640&height=640&fit=bounds)




































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)












