



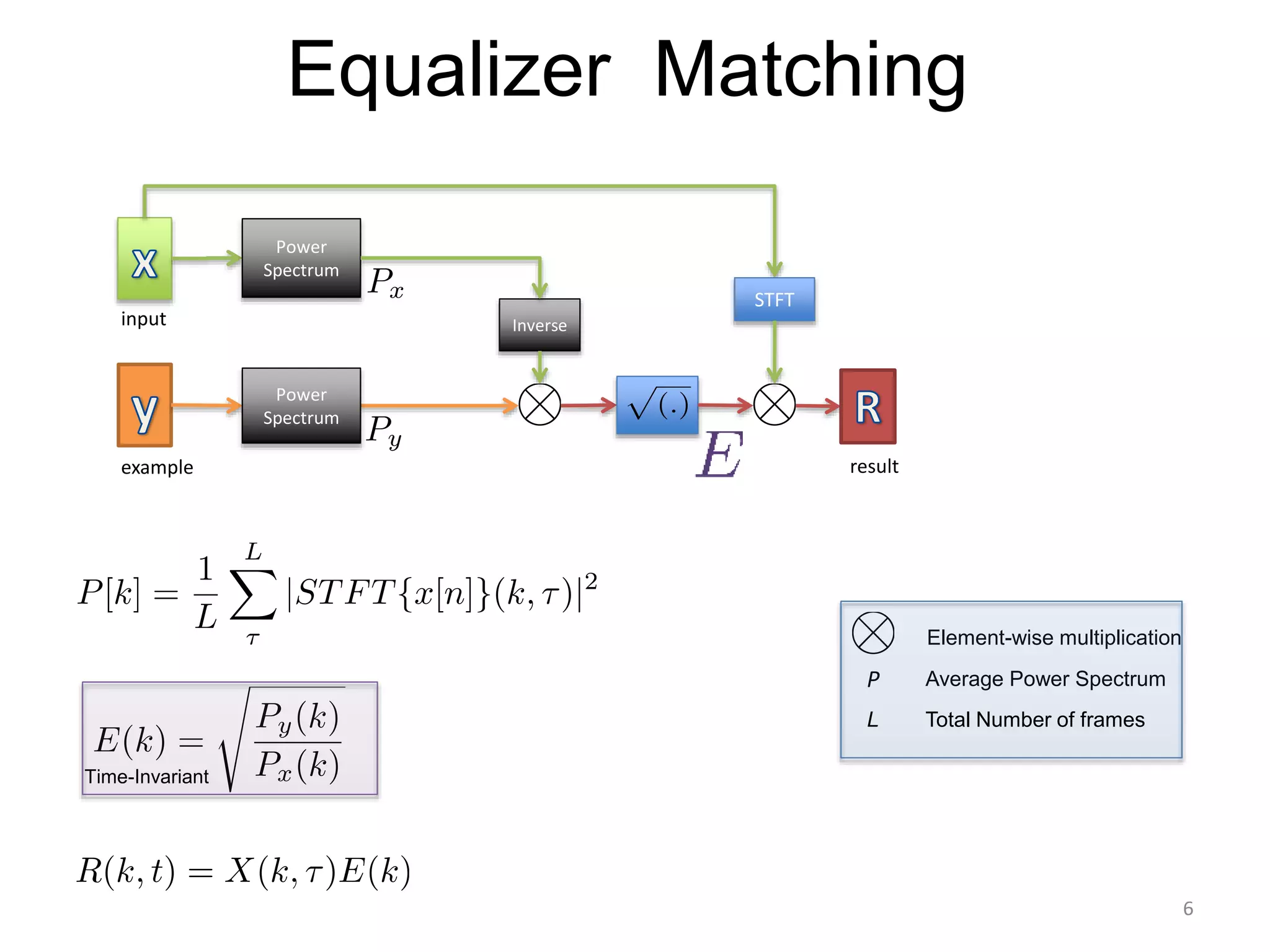
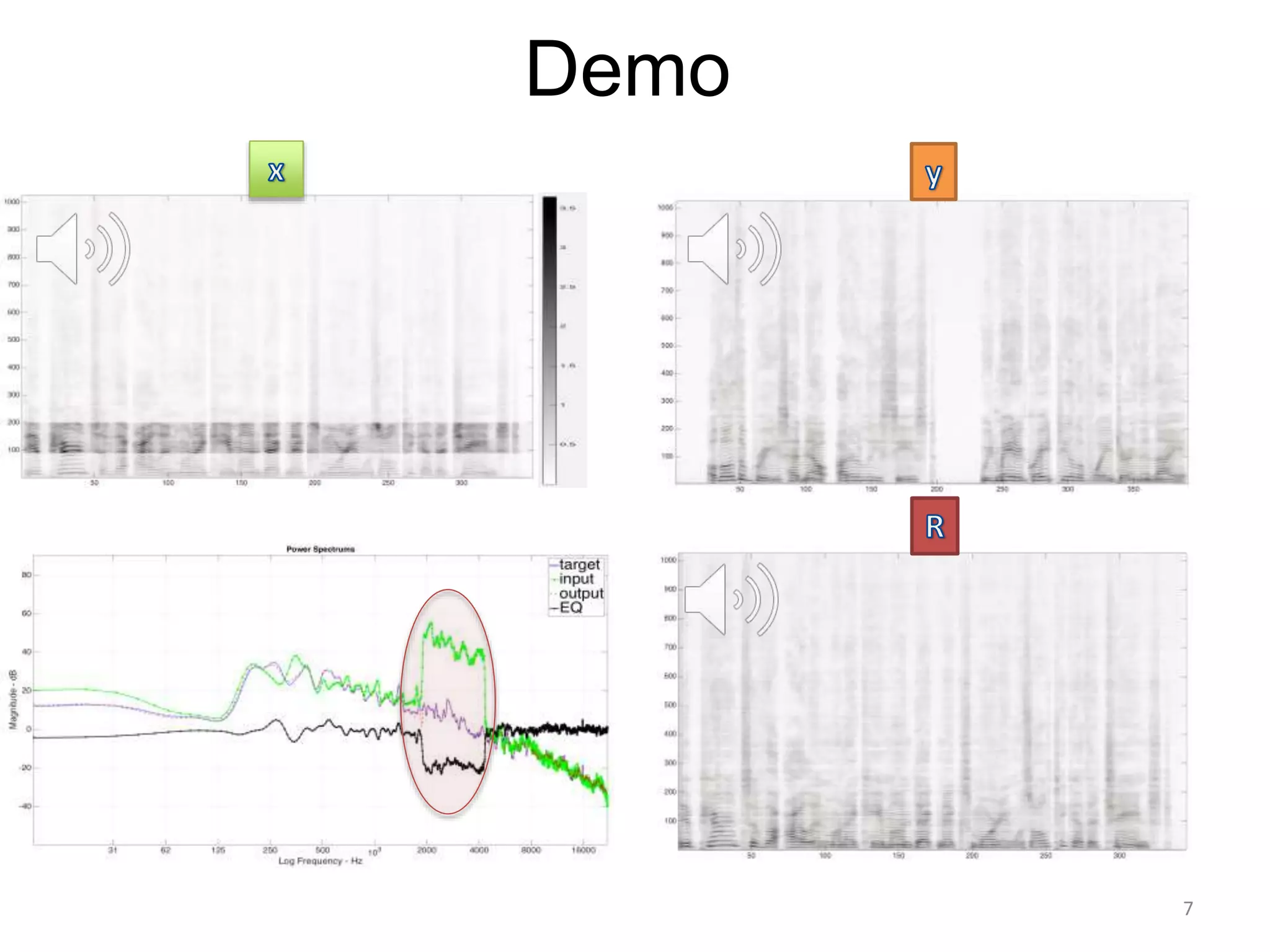
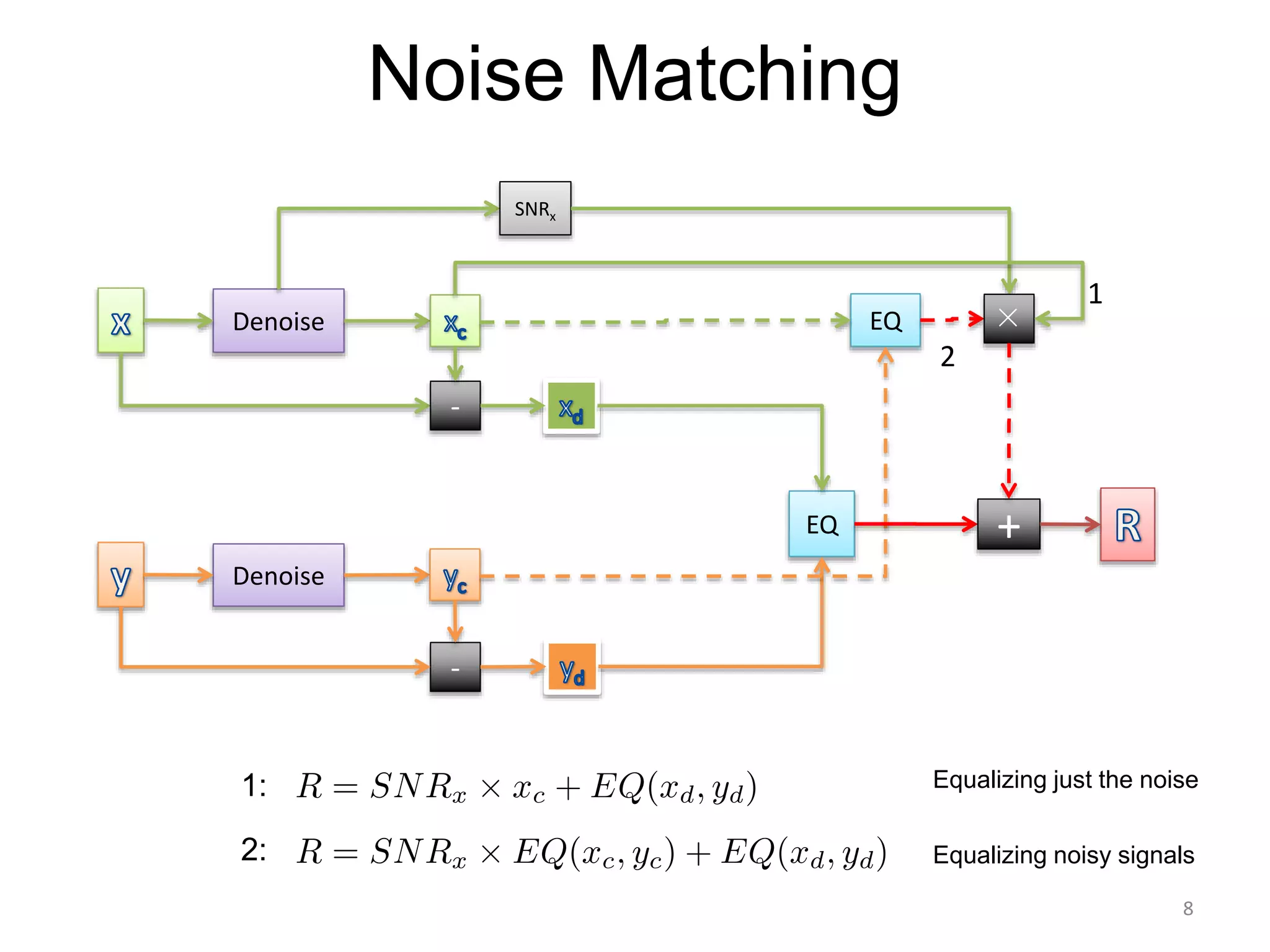
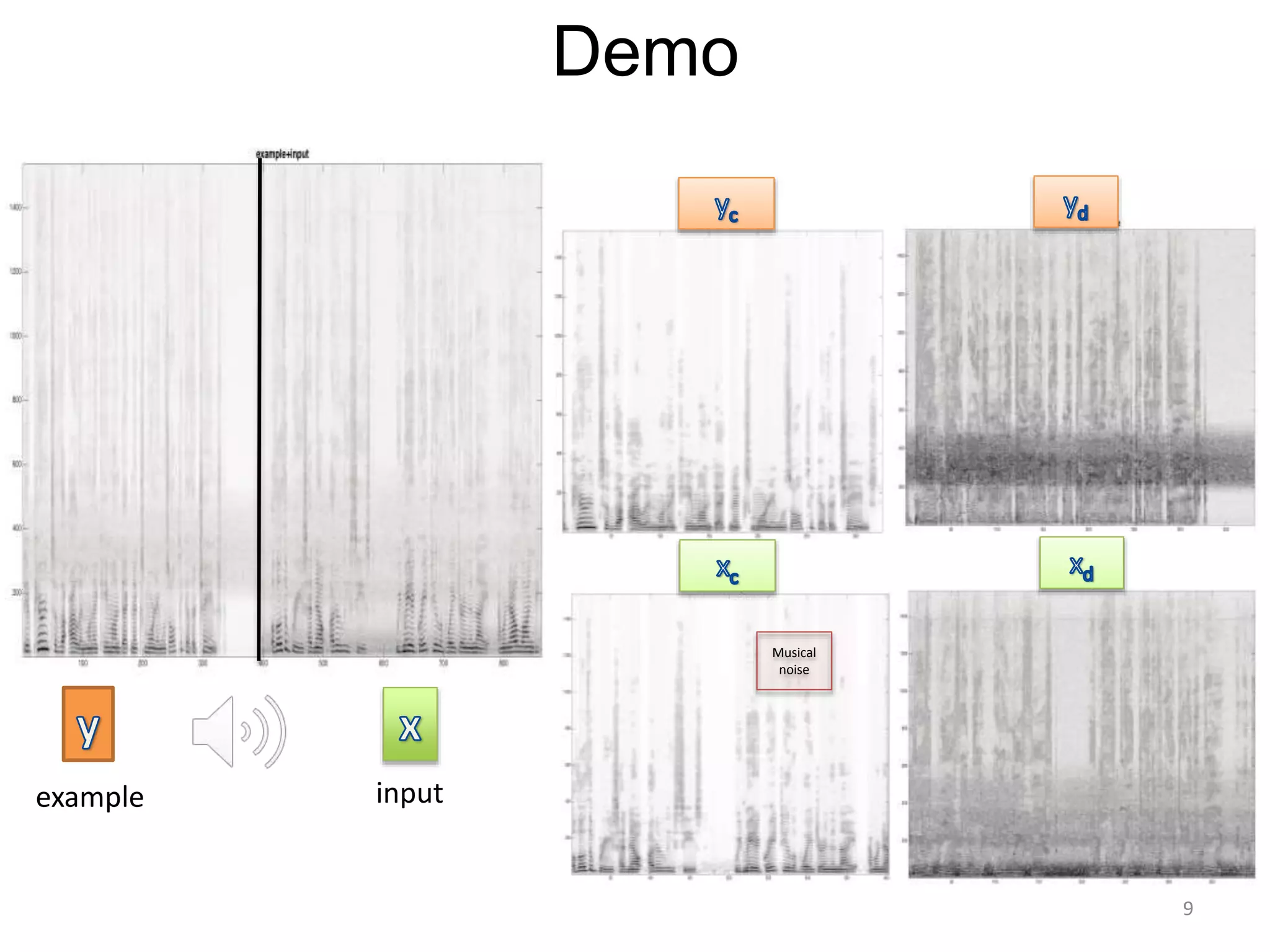
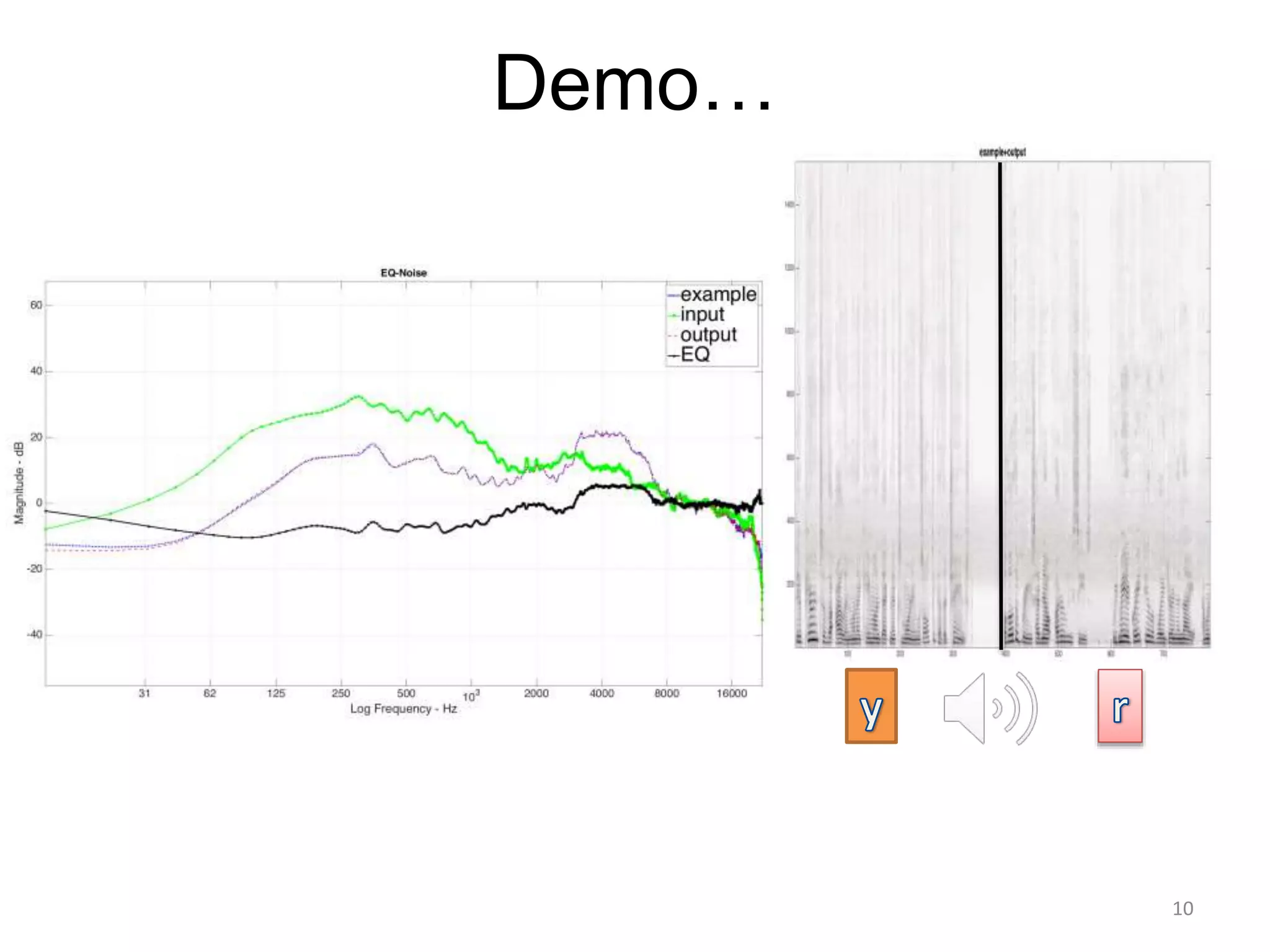


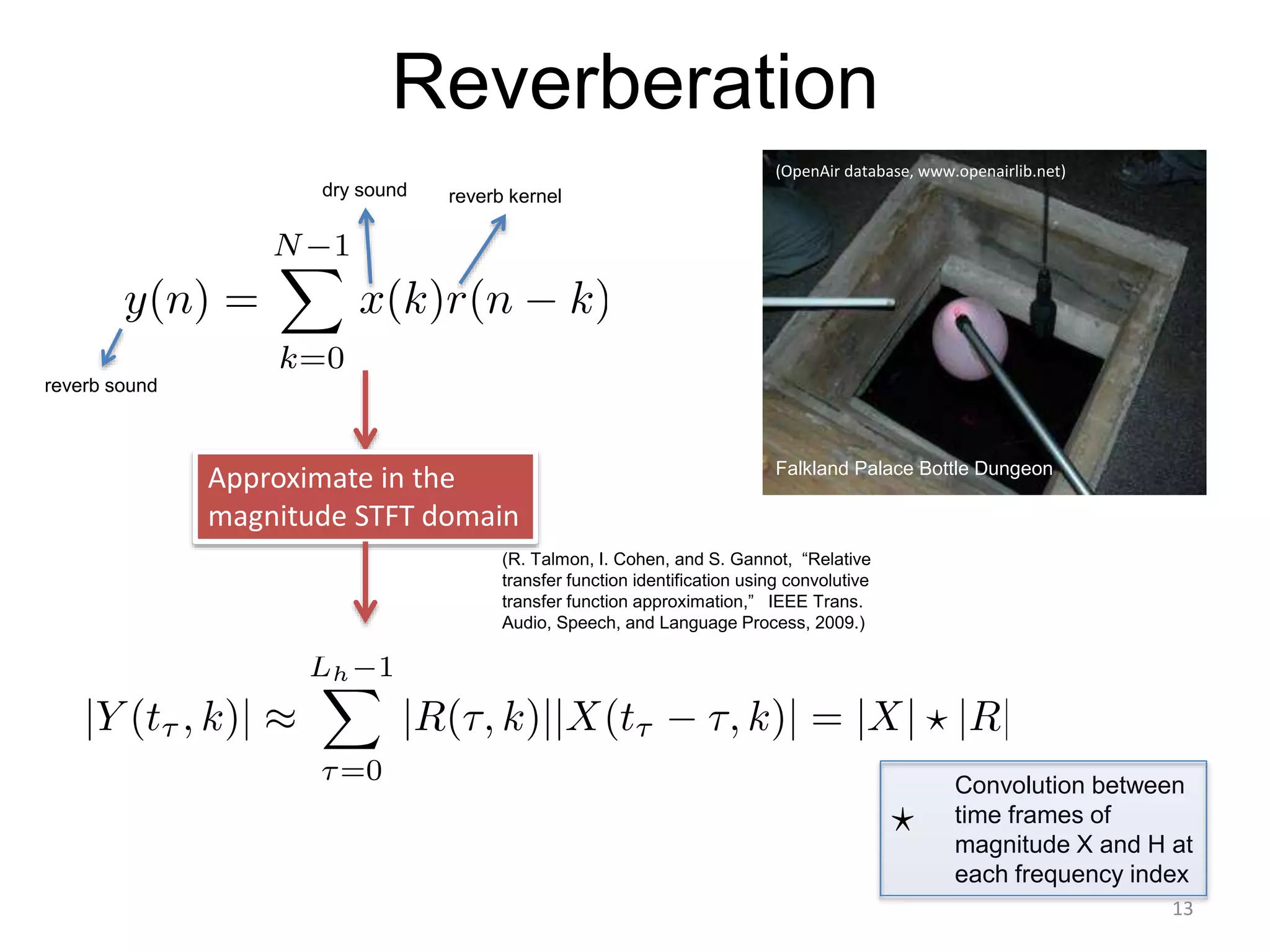
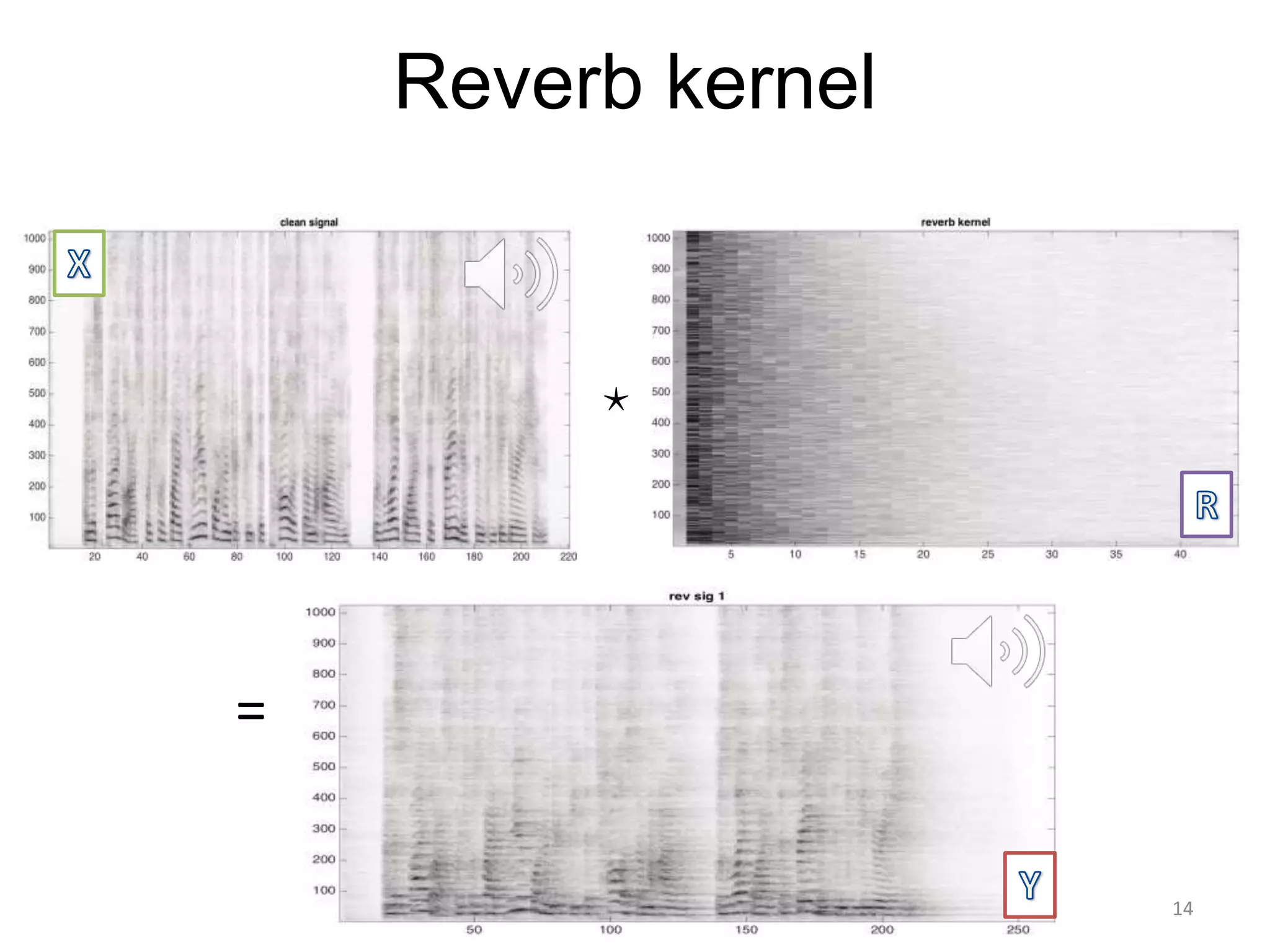
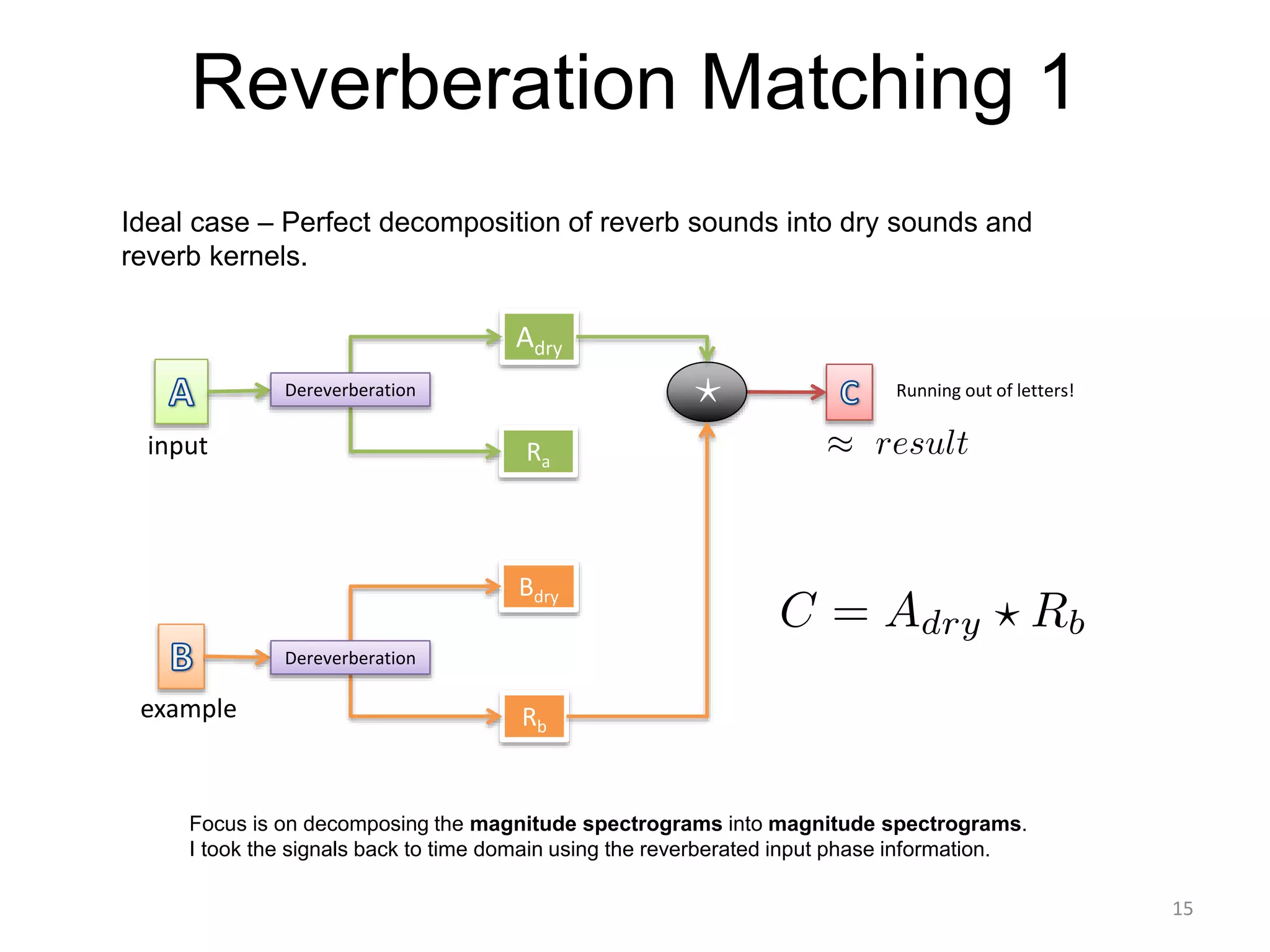



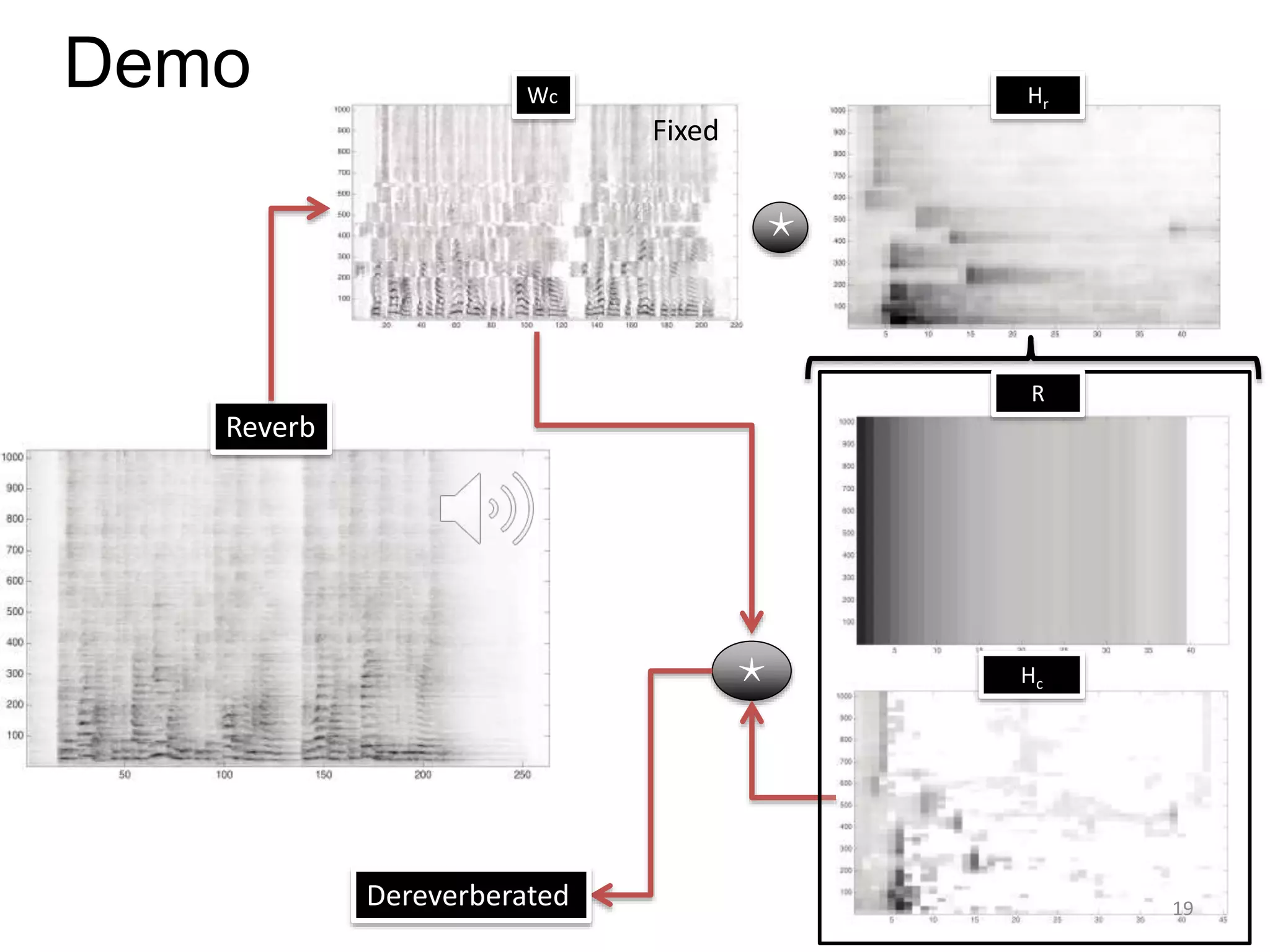
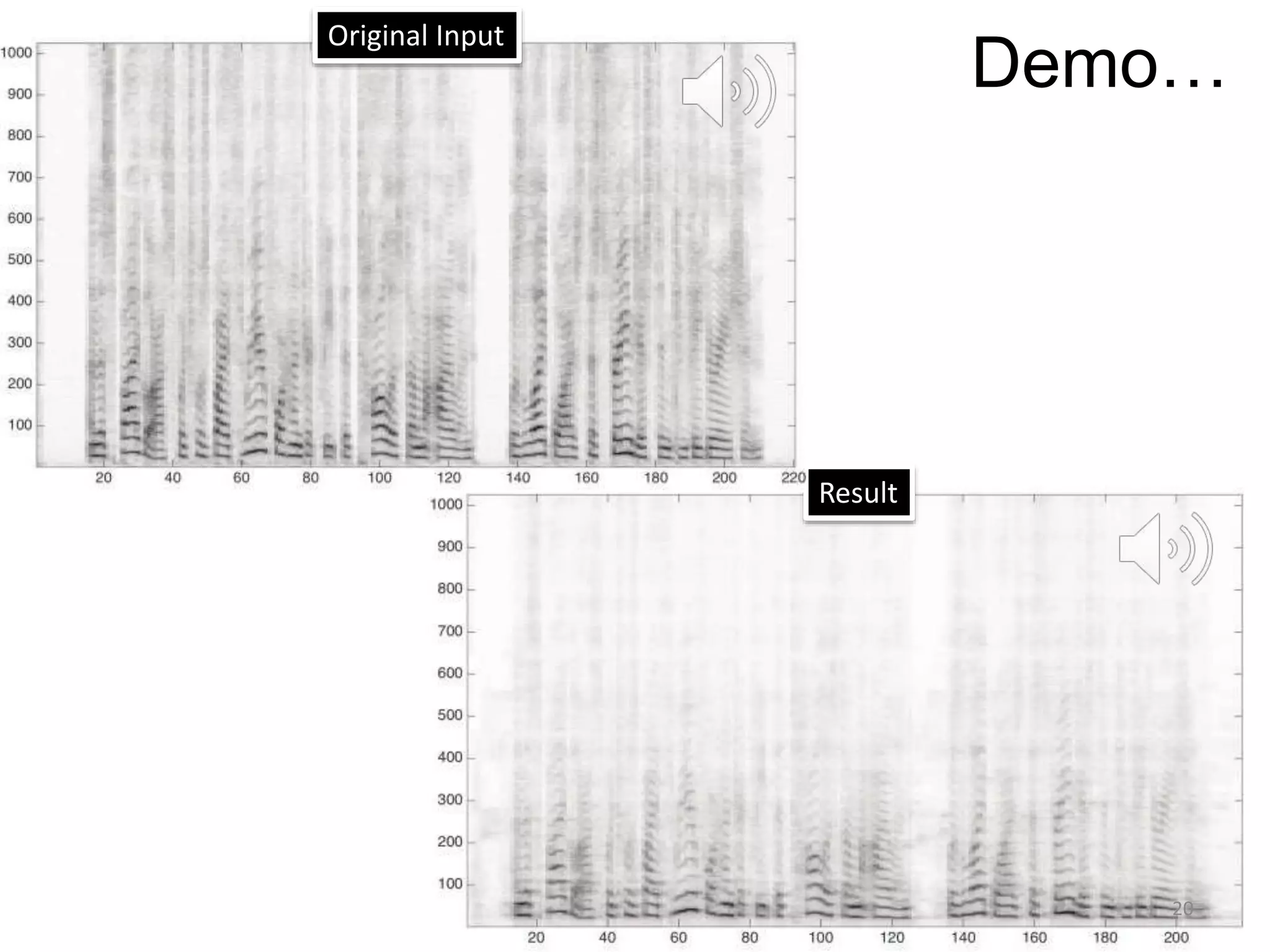
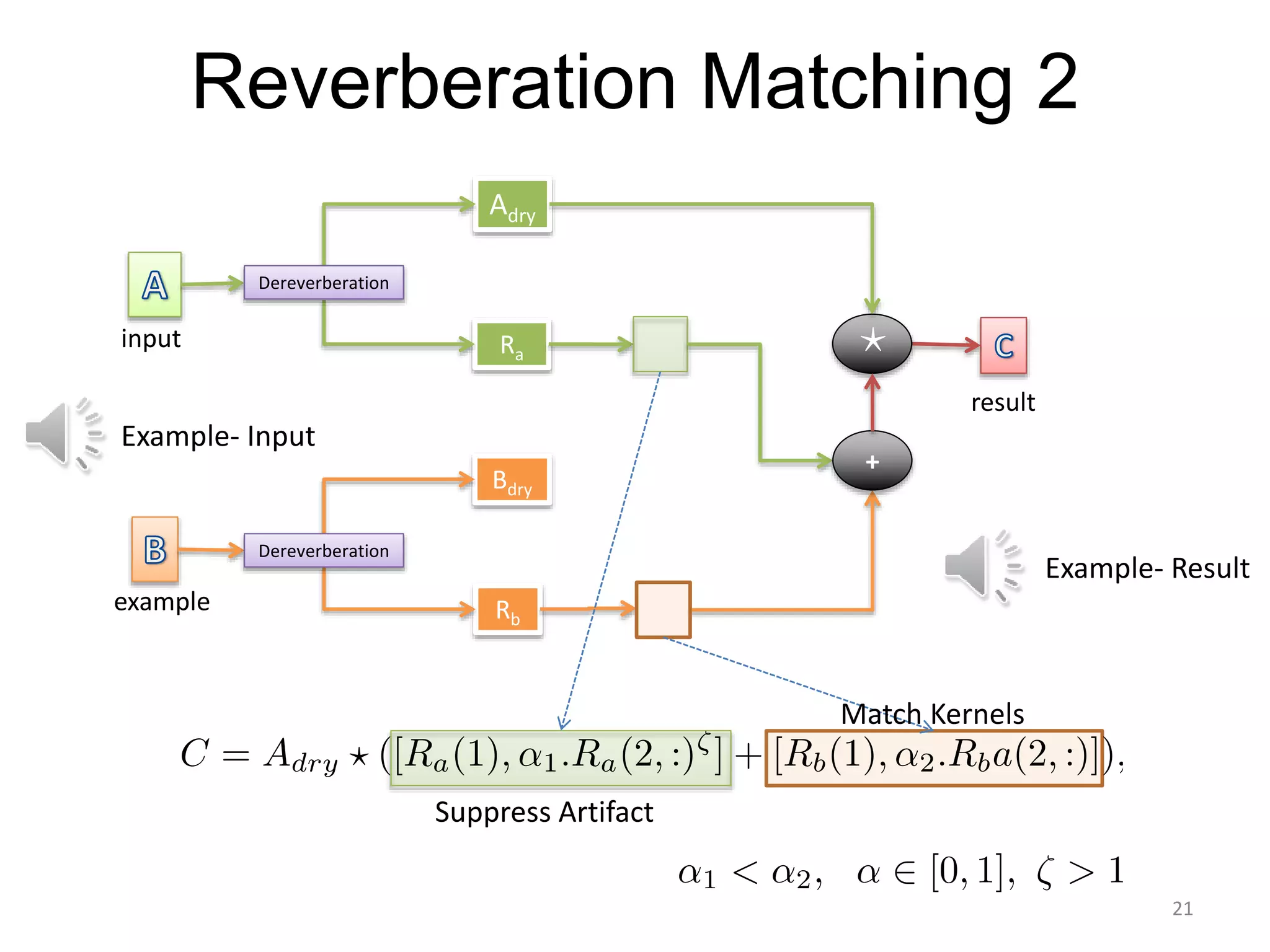
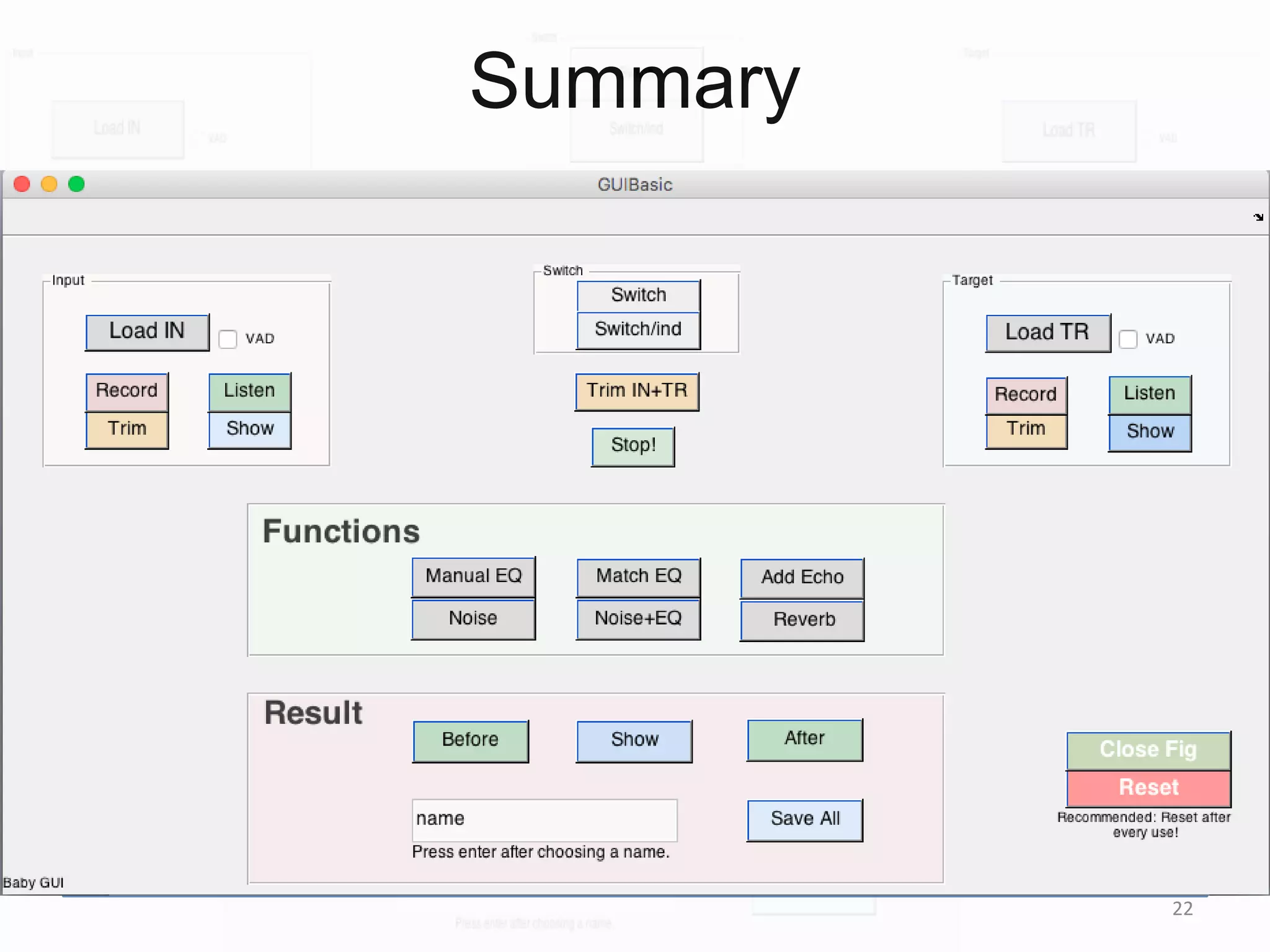

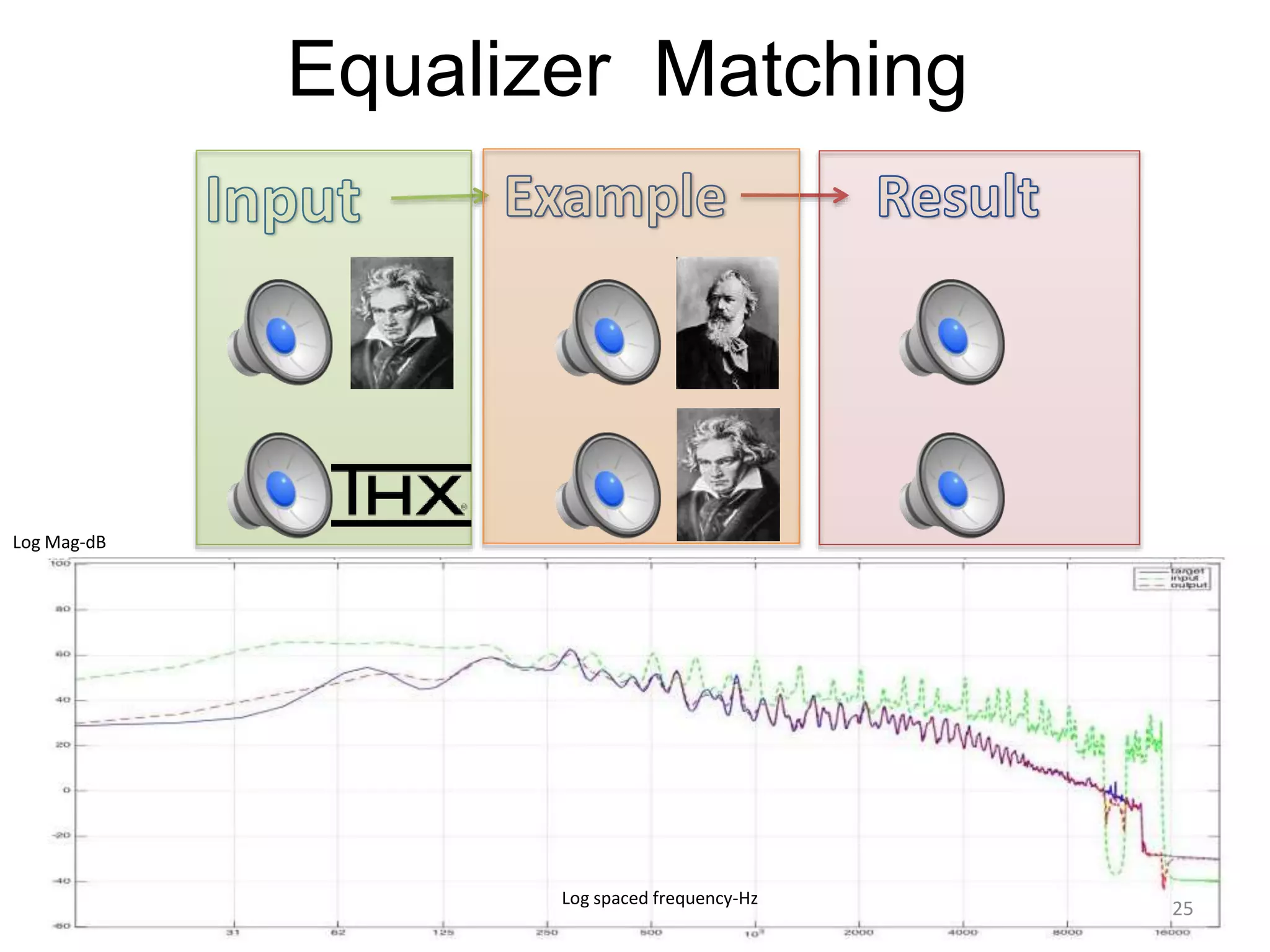

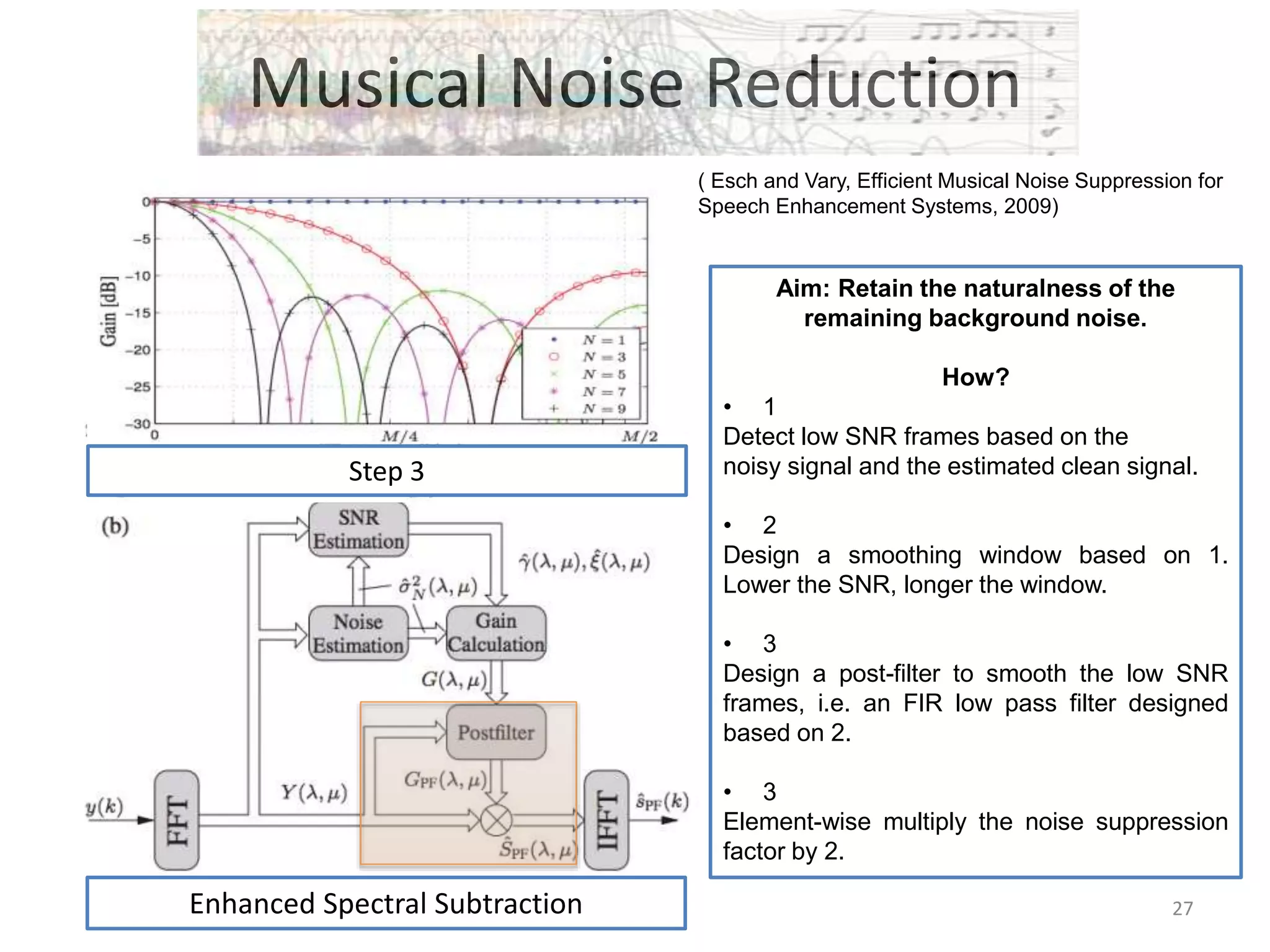
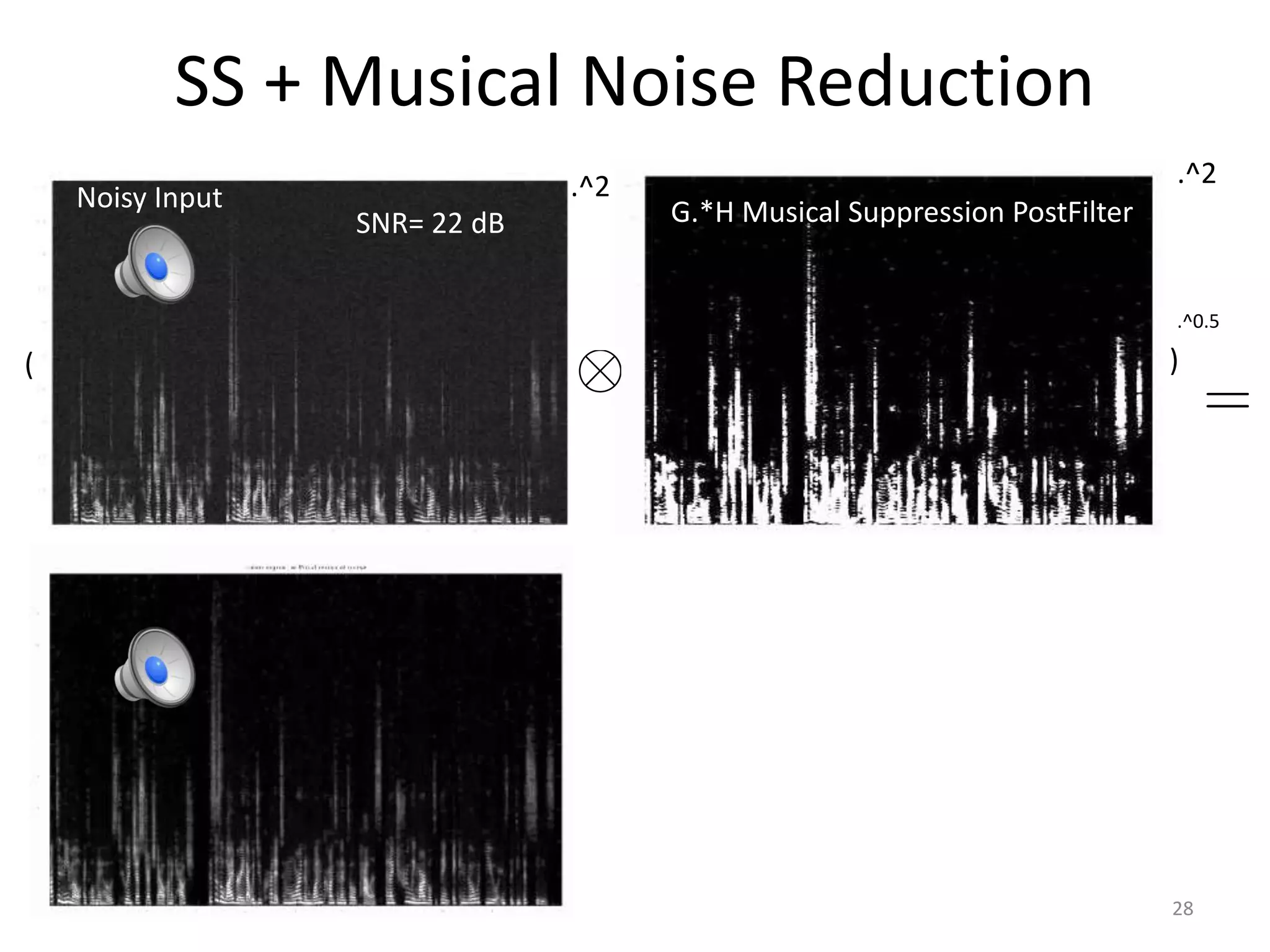
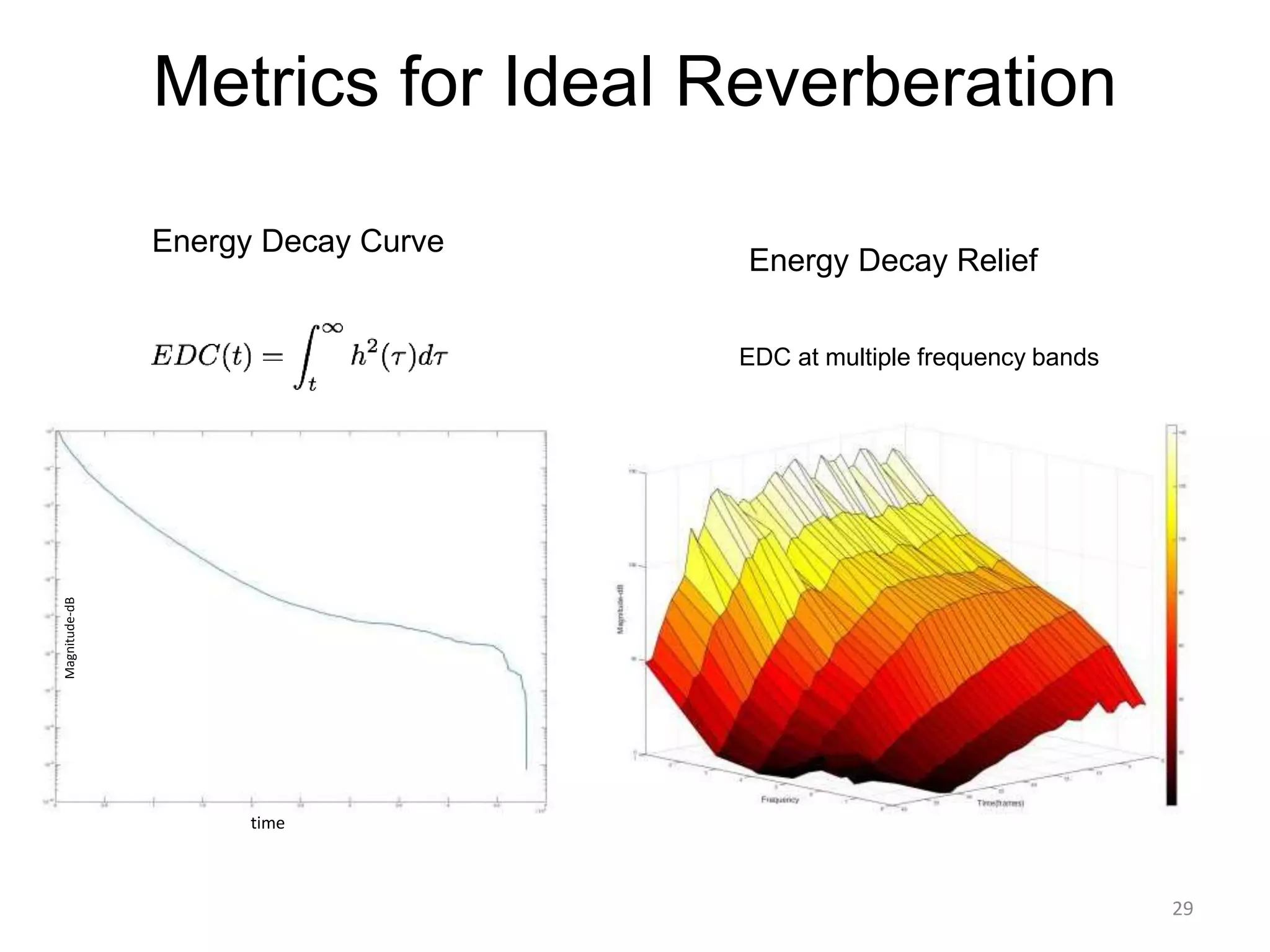

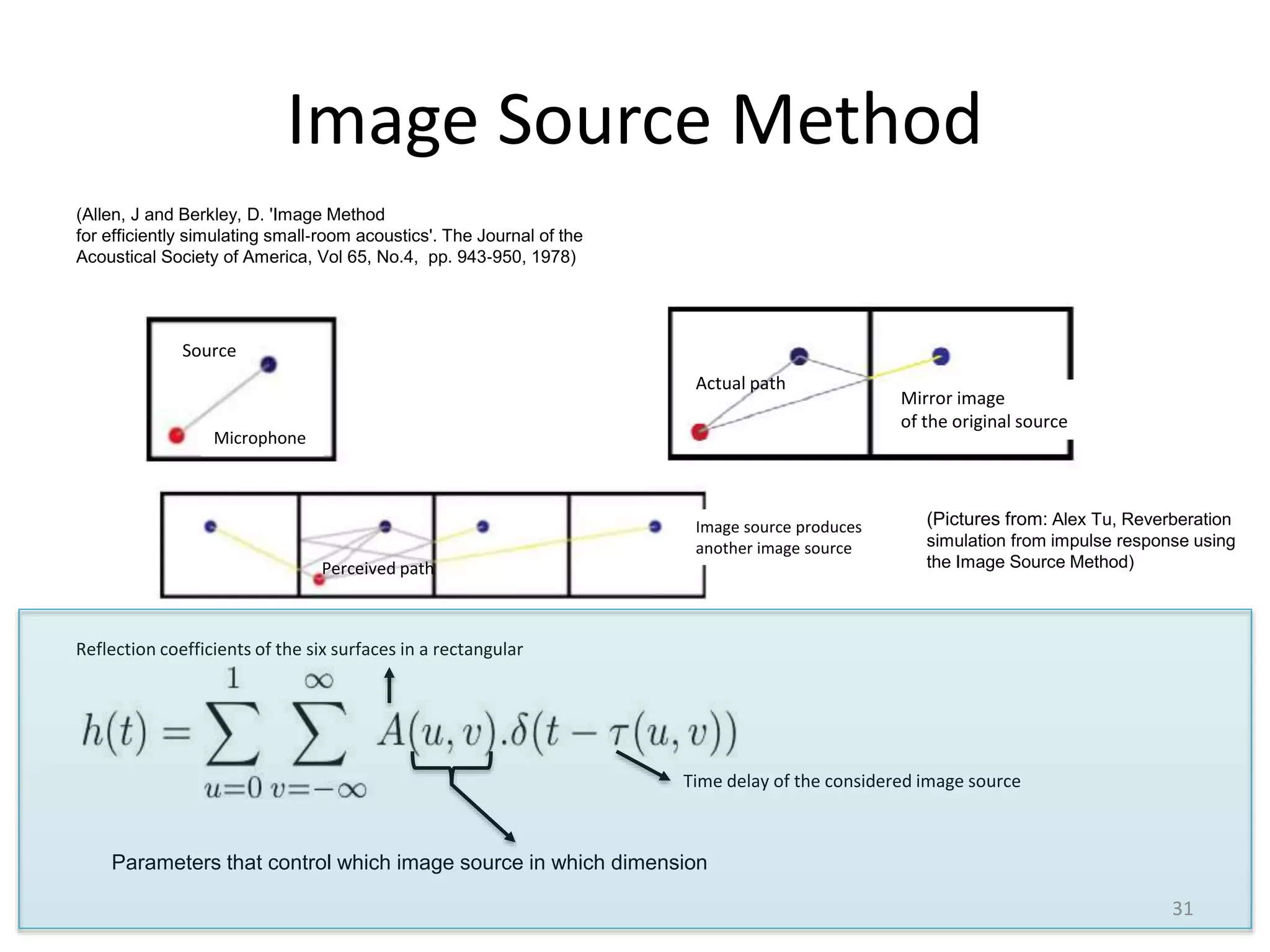

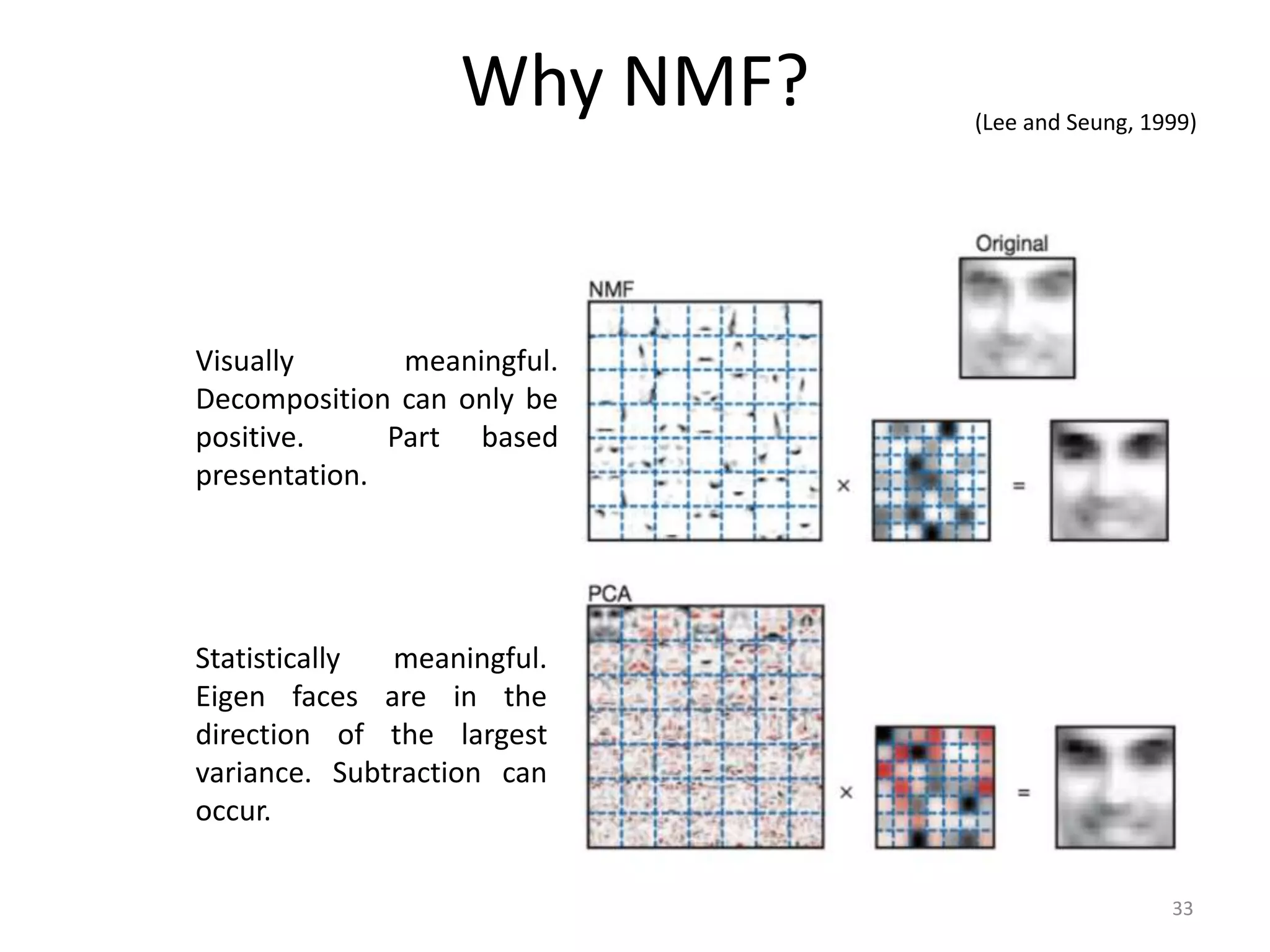
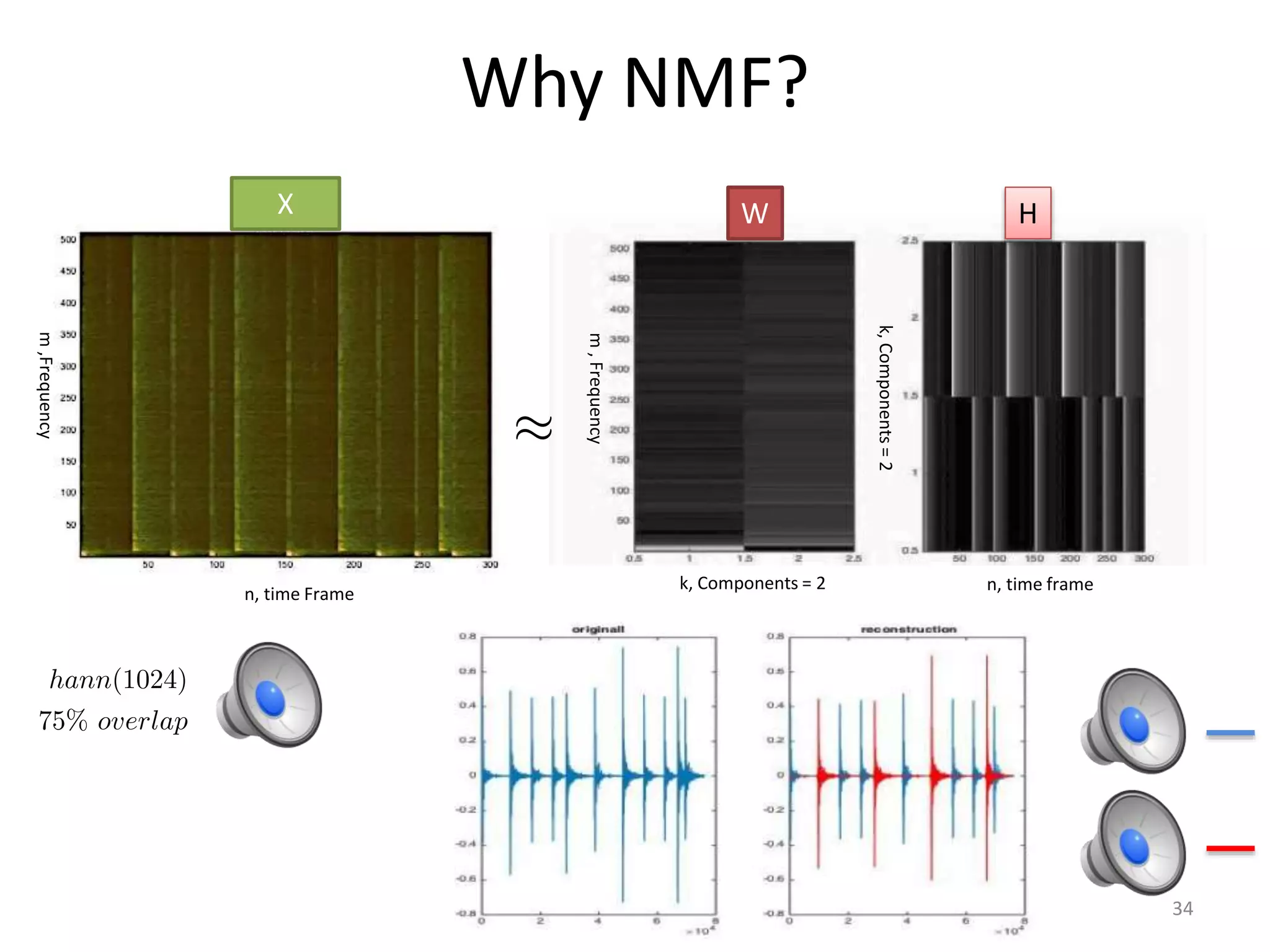
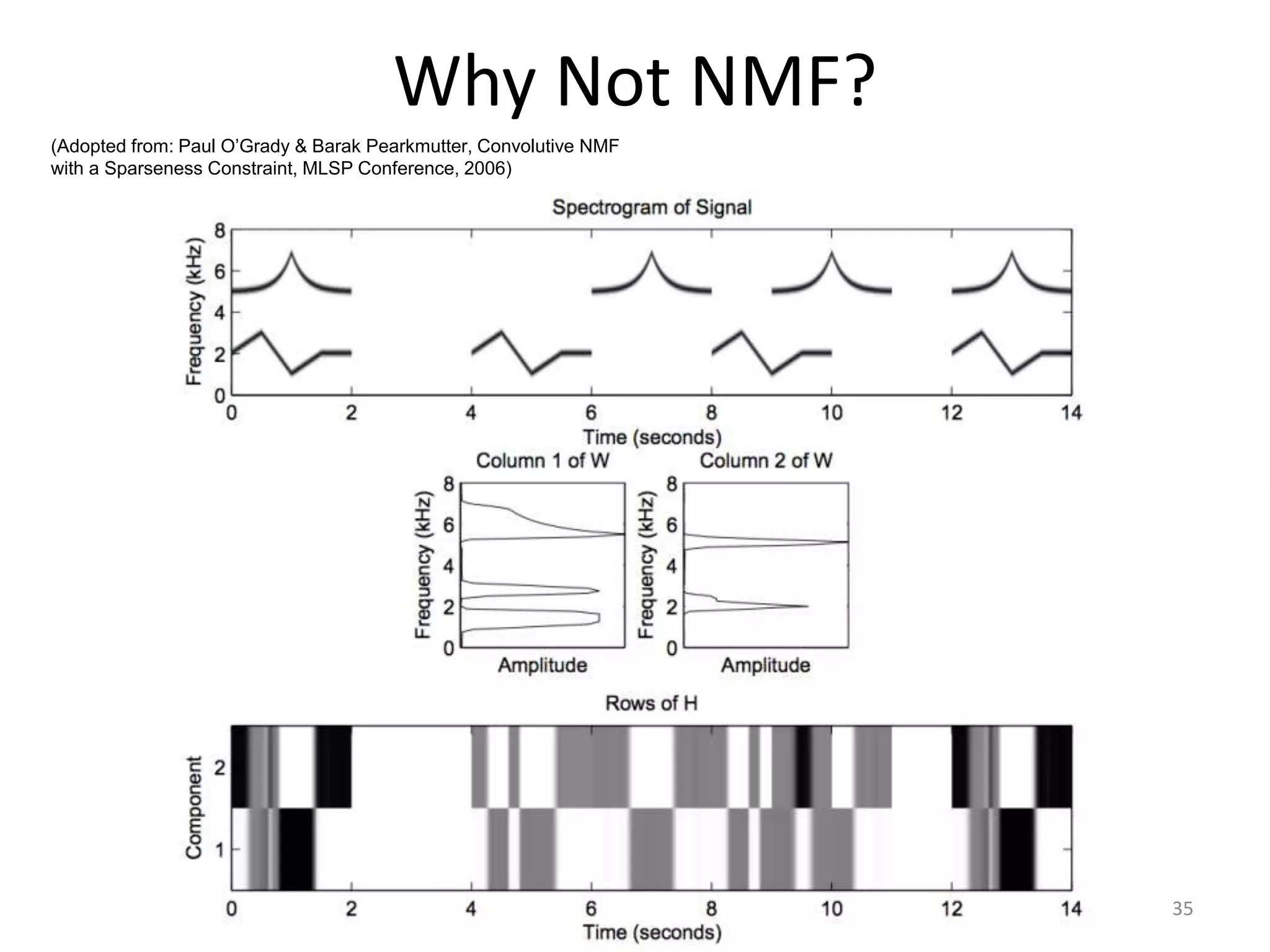
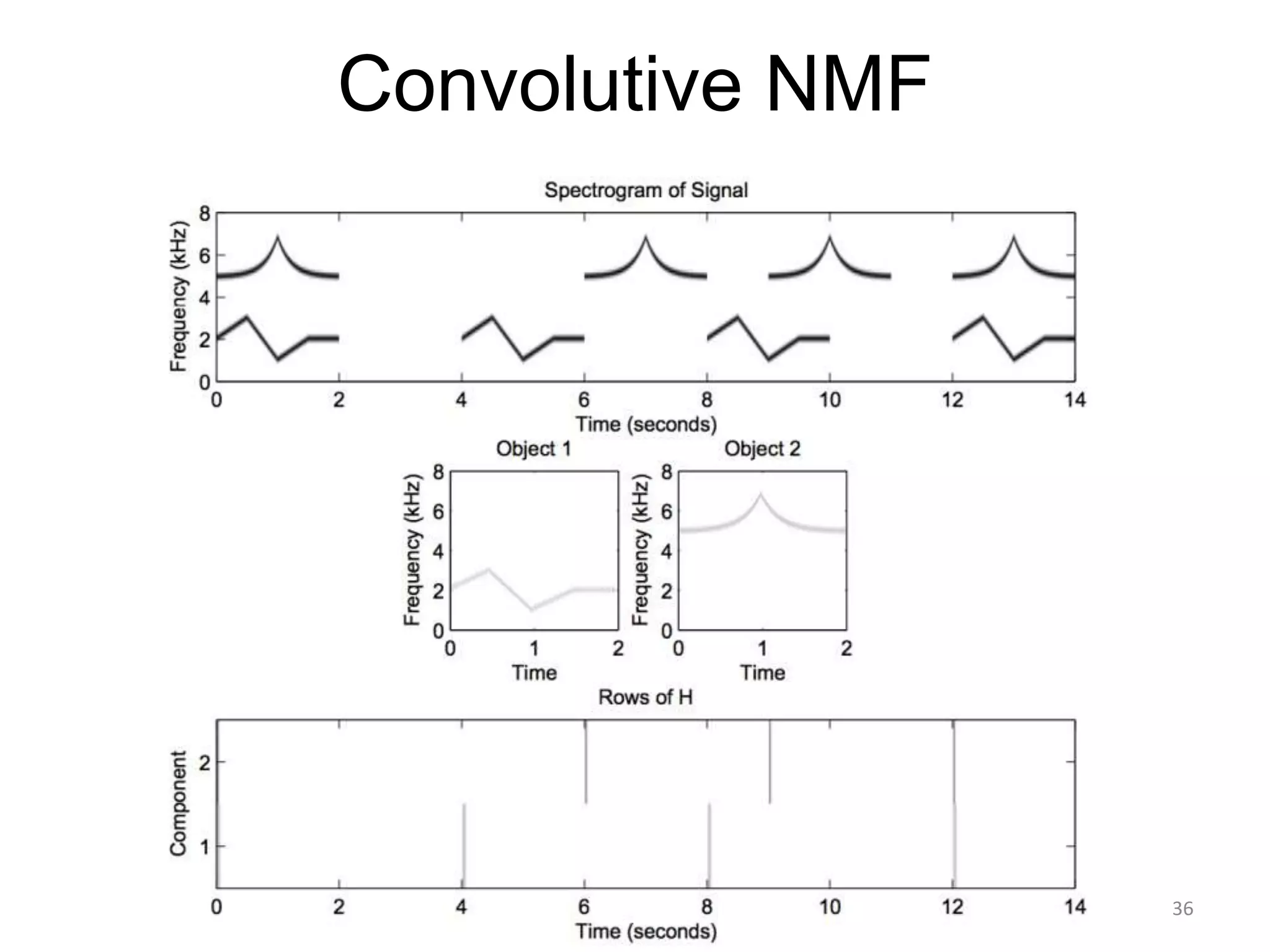
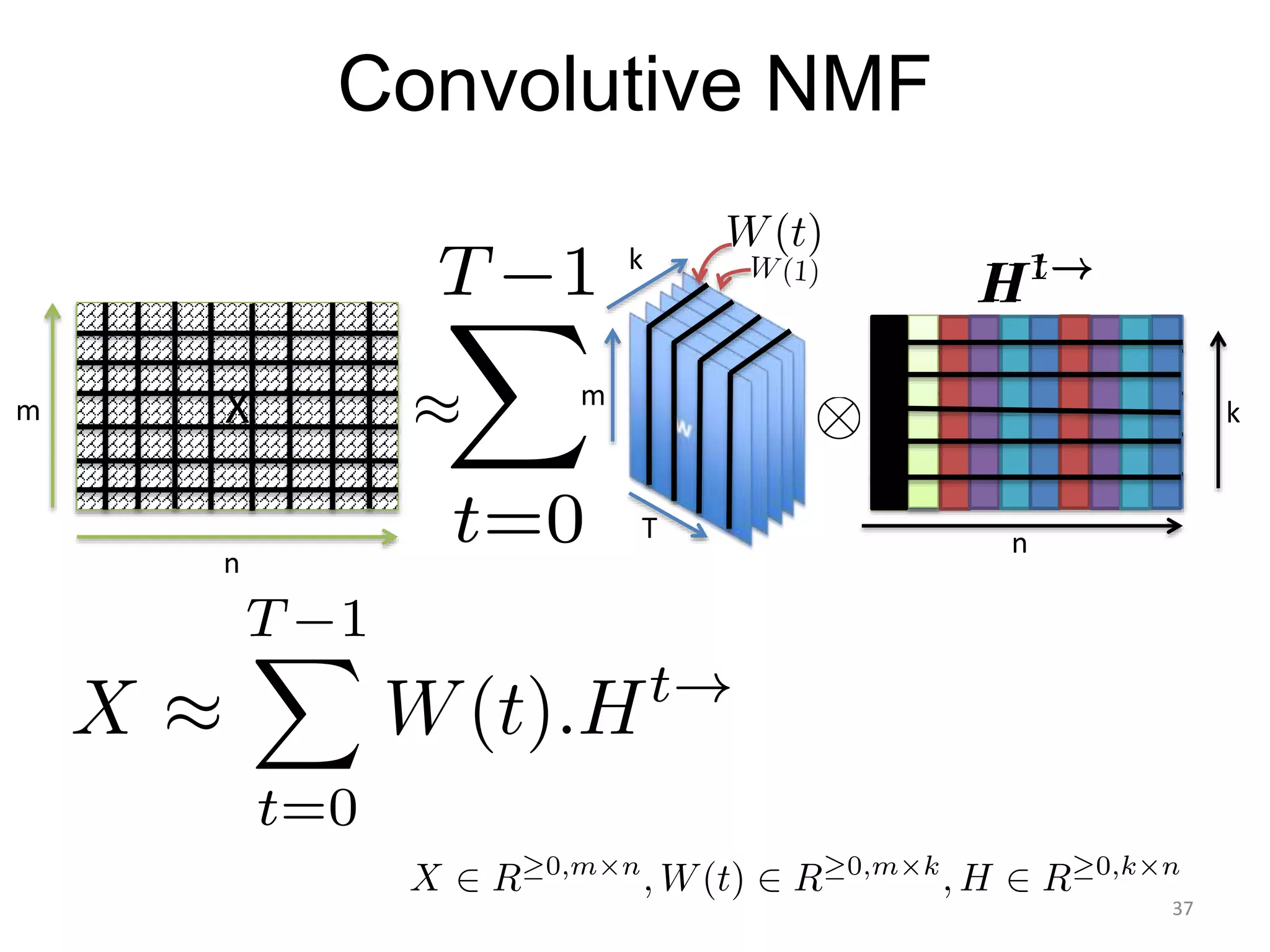
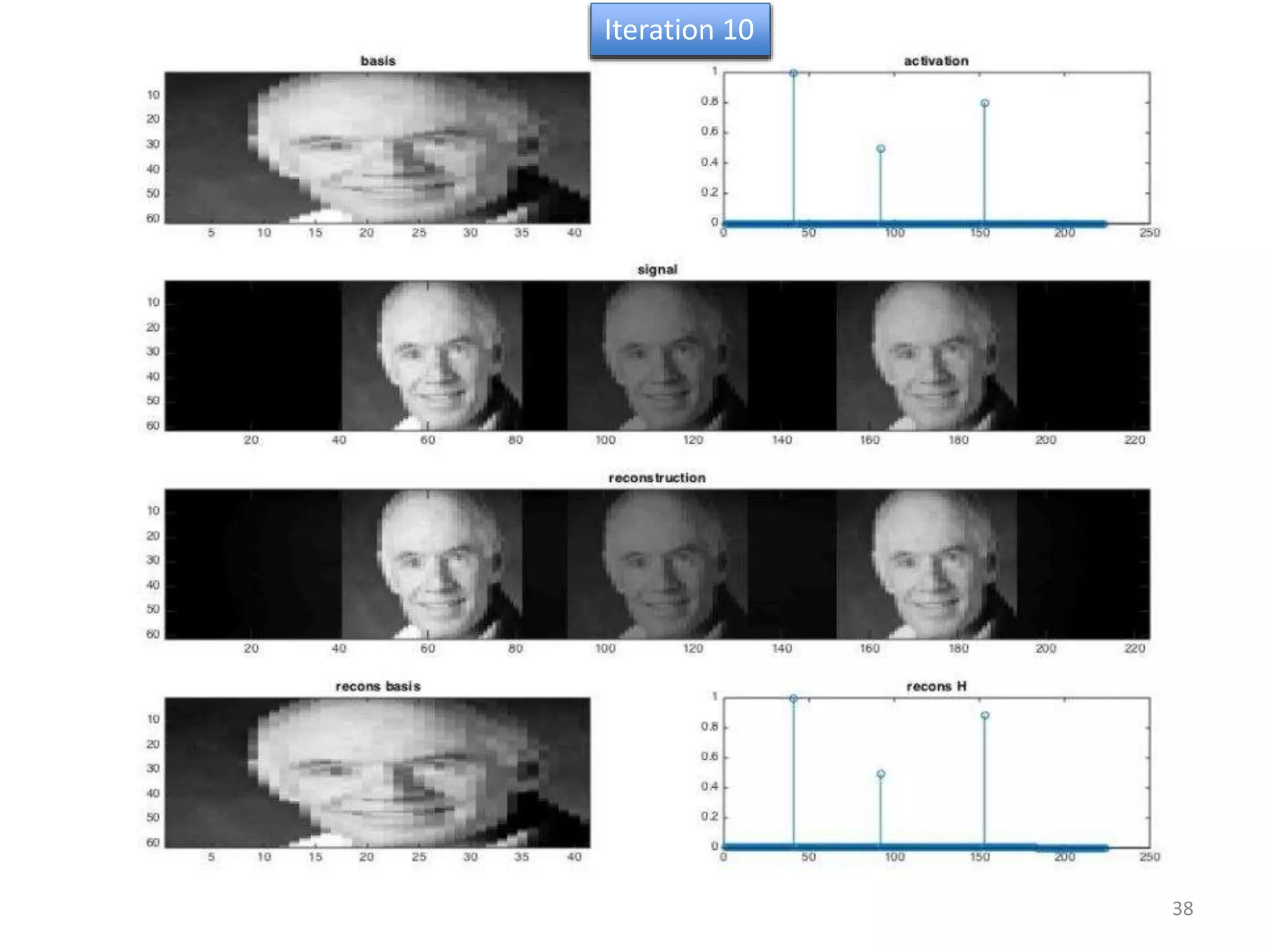
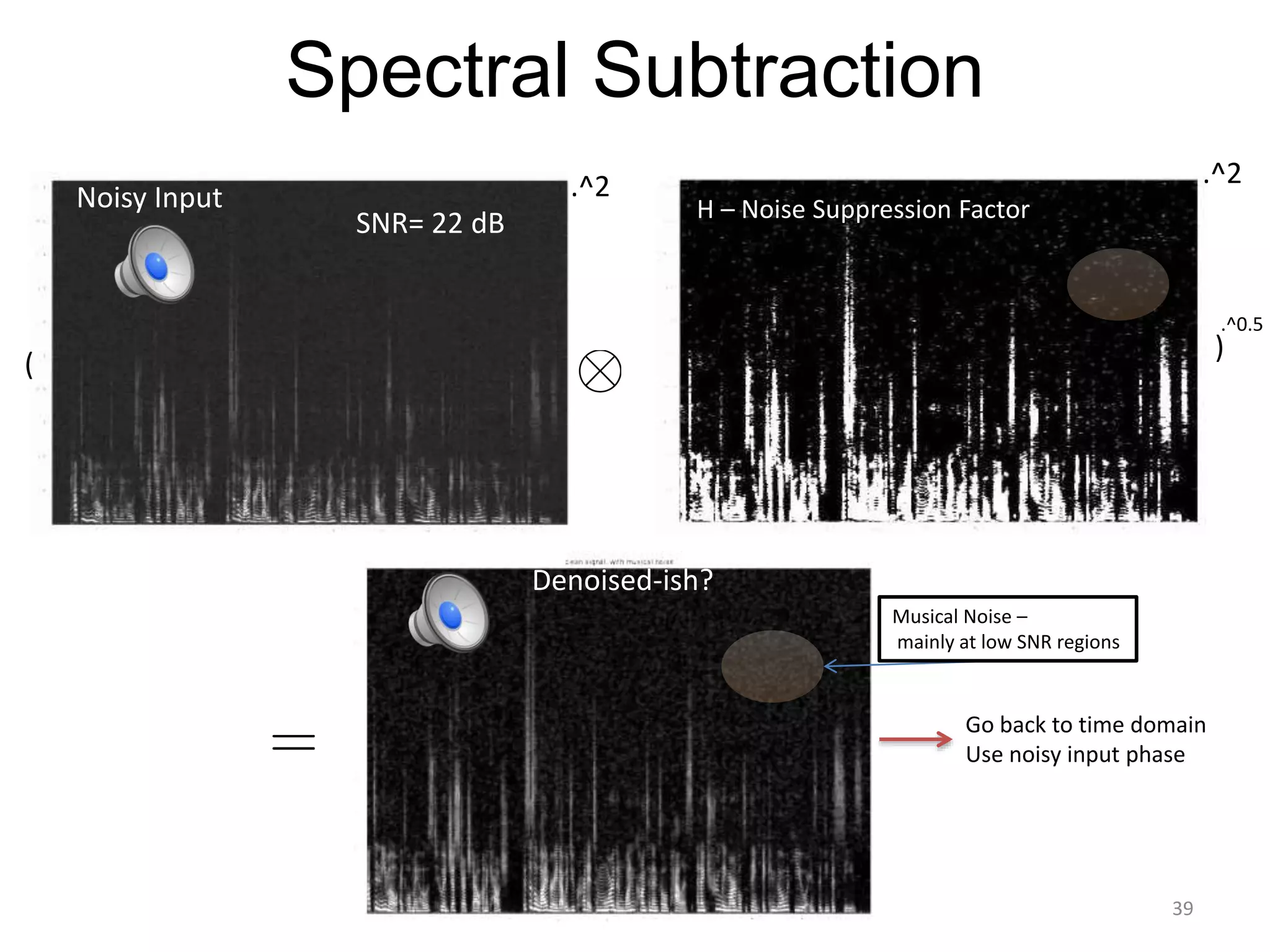
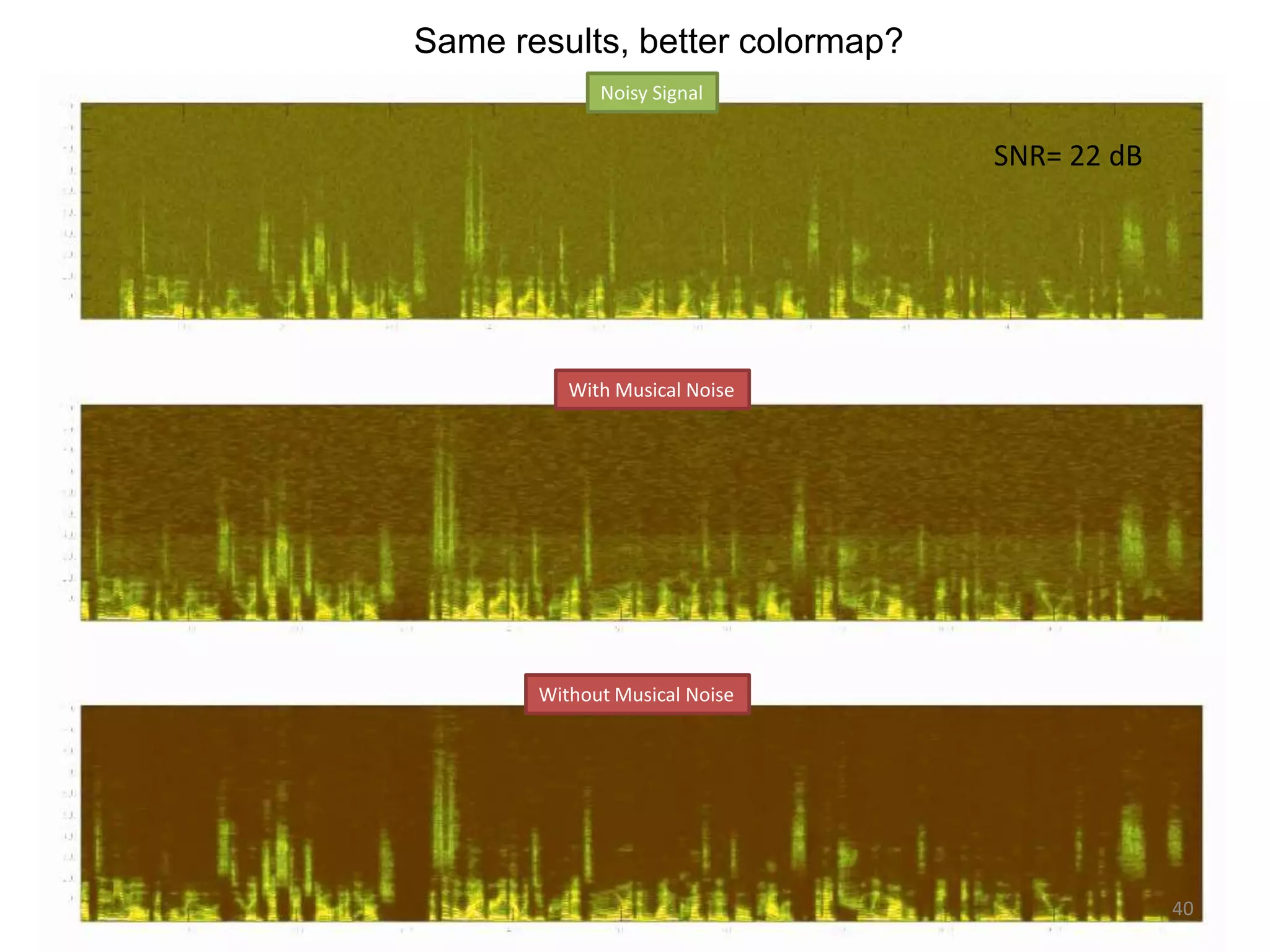

1) Equalizer matching involves finding the power spectrum of an example audio, then multiplying the input audio's magnitude spectrogram by a filter matching the example's power spectrum. 2) Noise matching involves denoising the input and example separately, then recombining their clean and noise components using the original signal-to-noise ratio. 3) Reverberation matching uses convolutive non-negative matrix factorization to decompose the input into a dry sound and reverb kernel, and convolve the estimated dry input with the example's reverb kernel.





















































