Download as PDF, PPTX


![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
Linear convolution is a widely used operation typically employed for audio
rendering purpose aiming to reproduce the reverberation effect generated
when a sound is produced within an enclosed space.
One of the main problems
LINEAR
CONVOLUTION
STATIC
PROCEDURE
It allows to reproduce only the acoustic effect produced taking into
account a specific sound source with the relative receiver position.
Solution
• Time varying convolution to simulate the moving receiver
positions performing IRs interpolation [1].
• A large impulse response (IR) database is needed.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
3/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-3-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
Linear convolution is a widely used operation typically employed for audio
rendering purpose aiming to reproduce the reverberation effect generated
when a sound is produced within an enclosed space.
One of the main problems
LINEAR
CONVOLUTION
STATIC
PROCEDURE
It allows to reproduce only the acoustic effect produced taking into
account a specific sound source with the relative receiver position.
Solution
• Time varying convolution to simulate the moving receiver
positions performing IRs interpolation [1].
• A large impulse response (IR) database is needed.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
3/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-4-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
Linear convolution is a widely used operation typically employed for audio
rendering purpose aiming to reproduce the reverberation effect generated
when a sound is produced within an enclosed space.
One of the main problems
LINEAR
CONVOLUTION
STATIC
PROCEDURE
It allows to reproduce only the acoustic effect produced taking into
account a specific sound source with the relative receiver position.
Solution
• Time varying convolution to simulate the moving receiver
positions performing IRs interpolation [1].
• A large impulse response (IR) database is needed.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
3/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-5-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
PROBLEM: Large impulse responses database required high memory
usage.
In [2] a database reduction procedure for auralization purpose with moving
listener position has been proposed:
Consideration
• Early reflections contain most of the information regarding the
location of the sound source and receiver.
• Late reflections gives more information about room properties
(e.g., size, geometry, materials) [3].
• The information in the late reverberation tail is largely
redundant across multiple impulse responses recorded in the
same space.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
4/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-6-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
PROBLEM: Large impulse responses database required high memory
usage.
In [2] a database reduction procedure for auralization purpose with moving
listener position has been proposed:
Metodology
• Mixing time evaluation to discriminate late from early
reflections.
• Approximation of the reverberation tail of the whole IR
database as stochastic process (i.e., white noise).
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
5/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-7-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Introduction
State of the art
Proposed algorithm
PROBLEM: Large impulse responses database required high memory
usage.
Proposed Solution
Taking into account the procedure described in [2] a novel methodology has been proposed considering the advantages introduced by
hybrid reveberation structure [4] [5].
• It is possible to approximate the convolution operation using
recursive structure (i.e., IIR filters).
• This procedure allows to further reduce the database dimension
with respect to [2].
• The employed structures permits to decrease the computational
load required to perform the real-time auralization.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
6/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-8-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Analysis of reverberation tail
Synthesis of the reverberation effect
Real-time Reproduction of Moving Listener Position
Three are the main phases of the approach presented for the reproduction
of moving listener position exploiting a hybrid reverberator structure:
1
2
3
Andrea Primavera
Analysis of reverberation tail:
Generate a prototype representing the database average reveberation
tail.
Synthesis of the reverberation effect:
Approximate the reverberation tail prototype exploiting an hybrid
reverberation algorithm [4] [5].
Real-time reproduction of moving listener position:
Reverberation effect reproduction using the hybrid reverberation
structure (mixed FIR/IIR filter network).
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
7/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-9-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
1
Analysis of reverberation tail
Synthesis of the reverberation effect
Real-time Reproduction of Moving Listener Position
Analysis of reverberation tail:
• Mixing time analysis:
The partitioning of early from late reflections has been performed
exploiting gaussianity [4] [6] and phase evolution estimators [7].
• Prototype evaluation:
The reverberation tail prototype is computed as a mean of the IRs
database after the maximum mixing time tm .
htail =
1
N
Lm
hn (t)
(1)
hn : database IRs
t=tm
• Scaling operation:
In order to simulate the distance among the source and the different
listereners position a scaling factor is evaluated.
Sm
Andrea Primavera
RMS(hs )
=
=
RMS(hm )
1
Lm
1
Lm
Lm
t=tm
Lm
t=tm
2
hs (t)
(2)
hs : synthesized IR
hm : original IR
2
hm (t)
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
8/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-10-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
2
Analysis of reverberation tail
Synthesis of the reverberation effect
Real-time Reproduction of Moving Listener Position
Synthesis of the reverberation effect:
gain
x[n]
EARLY
REFLECTIONS
DEVICE
LATE
REFLECTIONS
DEVICE
+
×
DELAY
y[n]
Hybrid reverberator block diagram for the single channel case.
Early reflections device
Based on the convolution with a
real IR for the reproduction of the
early echoes.
A
+
LBCF
+
LBCF
y[n]
x[n]
Late reflections device
+
+
LBCF
+
Based on IIR filters network (e.g.,
comb and/or all-pass) and a FDN
matrix [8] for the simulation of the
reverberation tail.
Andrea Primavera
AP
AP
+
NAP filters
LBCF
NLBCF filters
Late reflections device block diagram
for the single channel case.
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
9/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-11-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
2
Analysis of reverberation tail
Synthesis of the reverberation effect
Real-time Reproduction of Moving Listener Position
Synthesis of the reverberation effect:
gain
x[n]
EARLY
REFLECTIONS
DEVICE
LATE
REFLECTIONS
DEVICE
+
×
DELAY
y[n]
Hybrid reverberator block diagram for the single channel case.
Autotuning procedure
An automatic procedure allows to
set the parameters of hybrid reverberator in order to emulate a
real environment starting from its
impulse.
A
+
LBCF
+
LBCF
y[n]
x[n]
+
+
LBCF
+
AP
AP
+
NAP filters
LBCF
NLBCF filters
FIR TO IIR APPROXIMATION
Andrea Primavera
Late reflections device block diagram
for the single channel case.
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
10/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-12-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
2
Analysis of reverberation tail
Synthesis of the reverberation effect
Real-time Reproduction of Moving Listener Position
Synthesis of the reverberation effect:
Two are the main phases of the autotuning procedure:
Late Reflections Analysis
Early Reflections Partitioning
Evaluation of the mixing time to set the
early reflection device:
•
•
Andrea Primavera
Gaussianity estimators:
Similarities between IR behavior
and gaussian noise can be found
in late reflections.
Kurtosis and MAD/SD ratio
have been used.
Phase distortion evaluation:
The unwrapped phase of the IR
tends to become not linear with
late reflections evolution.
An offline adaptation procedure, based on SPSA [9], has been used to
iteratively find the IIR parameters.
A single loss function computed in cepstral domain [10] has been adopted in
the minimization procedure.
L = max
max
[Tr (i, j) − Ta (i, j)]2
i=1 j=1
K
M
where:
• Tr is a matrix representing the
MFCC derived from the real IR.
•
Ta is the MFCC obtained by the
artificial IR.
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
11/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-13-2048.jpg)

![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Experimental Setup
Reverberation Time
Clarity Index
Subjective Analysis
The effectiveness of the presented technique has been proved taking into
account account the IR database of a real environment (i.e., St. Margarets
Church in York [11]).
As reported in [11], a total of 18
IRs has been derived using:
• A logarithmic sweep signal
excitation (20 Hz - 22 kHz).
• Sample rate of 96kHz.
• A Soundfield SPS422B
microphone.
• A Genelec S30D loudspeaker.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
13/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-15-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Experimental Setup
Reverberation Time
Clarity Index
Subjective Analysis
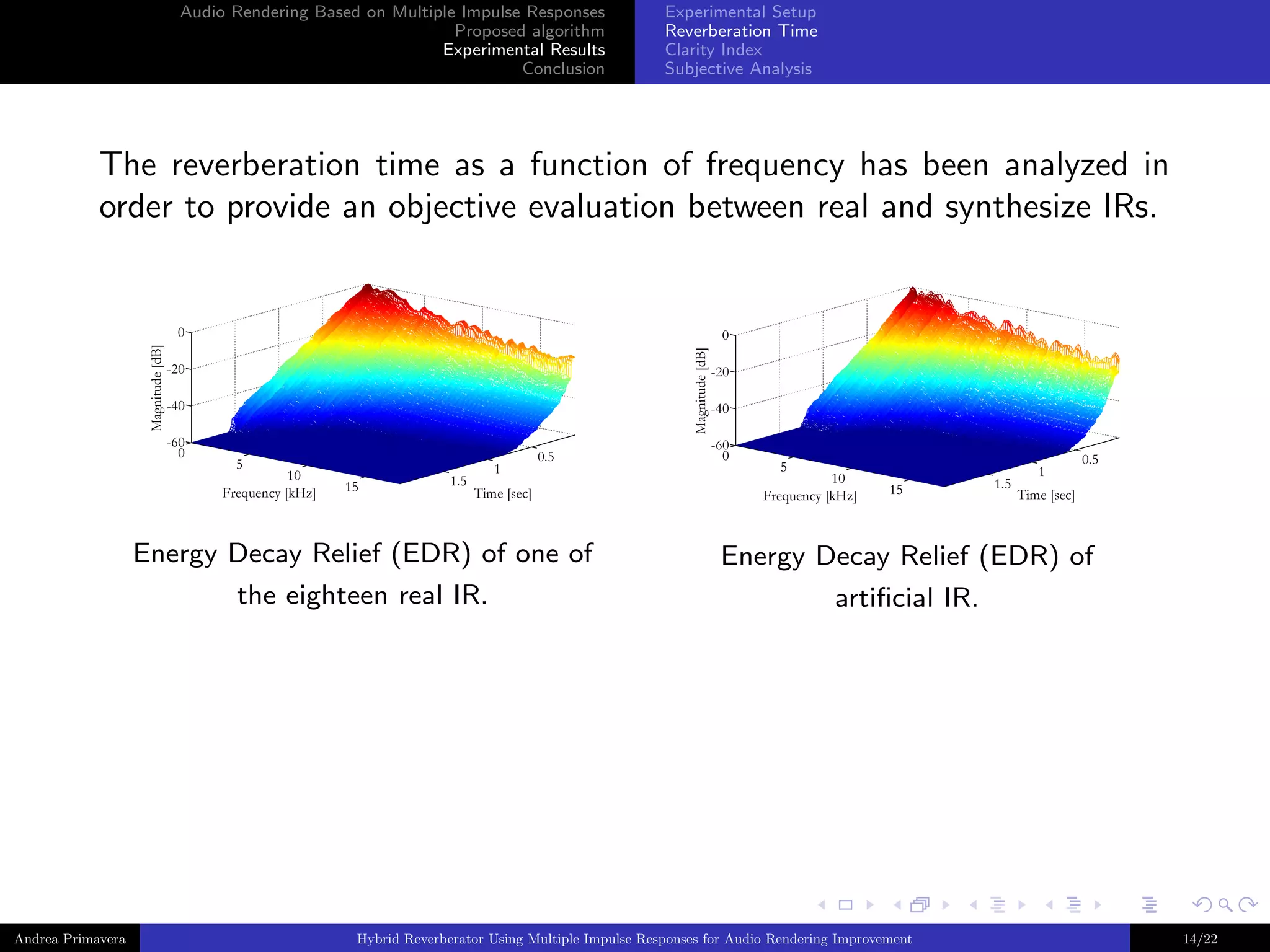
The reverberation time as a function of frequency has been analyzed in
order to provide an objective evaluation between real and synthesize IRs.
Mean difference in reverberation time between the measured and synthesized IRs
exploiting (a) the proposed approach and (b) the technique described in [2].
Since the obtained errors are comparable, the effectiveness of the proposed
technique in time frequency behaviors reproduction is confirmed.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
15/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-17-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Experimental Setup
Reverberation Time
Clarity Index
Subjective Analysis
Another parameter employed in objective analysis is clarity (C50 and C80):
Proposed approach
Approach presented in [2]
Mean real
1.75
1.75
Proposed approach
Approach presented in [2]
4.23
4.23
C50
Mean synth
2.28
0.10
C80
5.49
3.41
Mean err
0.52
1.65
Std err
1.09
1.97
1.26
0.81
1.06
1.29
Clarity measures: mean and the standard deviation (STD) error computed as
difference in corresponding receiver positions of the synthesized and measured IRs
exploiting the proposed approach and the one described in [2].
The similar values obtained as mean and standard deviation evaluation
confirms the validity of the approach.
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
16/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-18-2048.jpg)
![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Experimental Setup
Reverberation Time
Clarity Index
Subjective Analysis
Informal listening tests have been performed:
• The movement of the listener position along one dimension has been
simulated.
• The effectiveness of the approach has been confirmed since listeners
are not able to hear any difference between the presented approach
and the one described in [2].
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
17/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-19-2048.jpg)



![Audio Rendering Based on Multiple Impulse Responses
Proposed algorithm
Experimental Results
Conclusion
Conclusion
Questions
Bibliography
“OpenAIR, Audiolab, University of York.” [Online]. Available:
http://www.openairlib.net/
Andrea Primavera
Hybrid Reverberator Using Multiple Impulse Responses for Audio Rendering Improvement
22/22](https://image.slidesharecdn.com/hybridreverberatorusingmultipleimpulseresponsesforaudiorenderingimprovementpresentation-131022022332-phpapp01/75/Hybrid-Reverberator-Using-Multiple-Impulse-Responses-for-Audio-Rendering-Improvement-24-2048.jpg)

The document proposes an algorithm for audio rendering using multiple impulse responses that allows for reproduction of a moving listener position. It analyzes impulse response tails to generate a prototype tail and uses a hybrid reverberation structure including FIR and IIR filters to synthesize the reverberation effect in real-time. Experimental results on a church impulse response database show the approach can accurately reproduce reverberation time and clarity measurements compared to real impulse responses. Informal listening tests found no perceptible differences between the proposed approach and an existing technique.