Download to read offline























![Thanks !
Bart Hanssens / Fedict
WTC III, Simon Bolivarlaan 30
1000 Brussels, Belgium
@BartHanssens
bart.hanssens [at] fedict.be | www.fedict.belgium.be](https://image.slidesharecdn.com/rdf-microservices201701-170116113127/85/Publishing-RDF-SKOS-with-microservices-24-320.jpg)

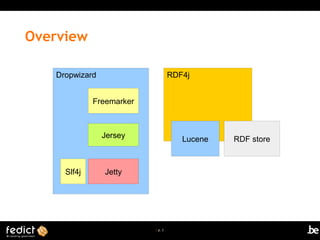
The document discusses publishing RDF and SKOS using Java microservices, focusing on frameworks like Jena and RDF4J for handling semantic web data. It outlines key concepts such as linked data, resource identifiers, and various RDF serialization formats, along with the advantages and use cases for triple stores versus traditional databases. Additionally, it highlights Dropwizard's capabilities for building microservices and RESTful applications efficiently.









































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)









![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)



