Download as PDF, PPTX






![Cassandra DevOps
$CASSANDRA_HOME/bin$ ./cassandra-cli --host localhost
[default@unknown] show keyspaces;
Keyspace: system:
Replication Strategy: org.apache.cassandra.locator.LocalStrategy
Durable Writes: true
Options: [replication_factor:1]
Column Families:
ColumnFamily: HintsColumnFamily (Super)
"hinted handoff data"
Key Validation Class: org.apache.cassandra.db.marshal.BytesType
Default column value validator: org.apache.cassandra.db.marshal.BytesType
Columns sorted by: org.apache.cassandra.db.marshal.BytesType/org.apache.cassandra.db.
marshal.BytesType
Row cache size / save period in seconds / keys to save : 0.0/0/all
Row Cache Provider: org.apache.cassandra.cache.ConcurrentLinkedHashCacheProvider
Key cache size / save period in seconds: 0.01/0
GC grace seconds: 0
Compaction min/max thresholds: 4/32
Read repair chance: 0.0
Replicate on write: true
Bloom Filter FP chance: default
Built indexes: []
Compaction Strategy: org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy](https://image.slidesharecdn.com/hadoopcassandraapachebarcamp-120425015713-phpapp01/85/Store-and-Process-Big-Data-with-Hadoop-and-Cassandra-7-320.jpg)
![Cassandra CLI
[default@apache] create column family Location with comparator=UTF8Type and
default_validation_class=UTF8Type and key_validation_class=UTF8Type;
f04561a0-60ed-11e1-0000-242d50cf1fbf
Waiting for schema agreement...
... schemas agree across the cluster
[default@apache] set Location[00001][City]='Colombo';
Value inserted.
Elapsed time: 140 msec(s).
[default@apache] list Location;
Using default limit of 100
-------------------
RowKey: 00001
=> (column=City, value=Colombo, timestamp=1330311097464000)
1 Row Returned.
Elapsed time: 122 msec(s).](https://image.slidesharecdn.com/hadoopcassandraapachebarcamp-120425015713-phpapp01/85/Store-and-Process-Big-Data-with-Hadoop-and-Cassandra-8-320.jpg)








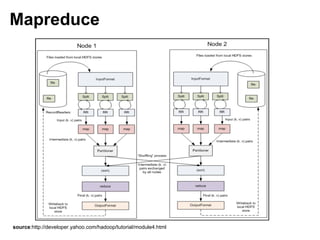


![Simple Mapreduce Job
Job Runner:
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);](https://image.slidesharecdn.com/hadoopcassandraapachebarcamp-120425015713-phpapp01/85/Store-and-Process-Big-Data-with-Hadoop-and-Cassandra-21-320.jpg)



This document provides information on storing and processing big data with Apache Hadoop and Cassandra. It discusses how to install and configure Cassandra and Hadoop, perform basic operations with their command line interfaces, and implement simple MapReduce jobs in Hadoop. Key points include how to deploy Cassandra and Hadoop clusters, store and retrieve data from Cassandra using Hector and CQL, and use high-level interfaces like Hive and Pig with Hadoop.























































































