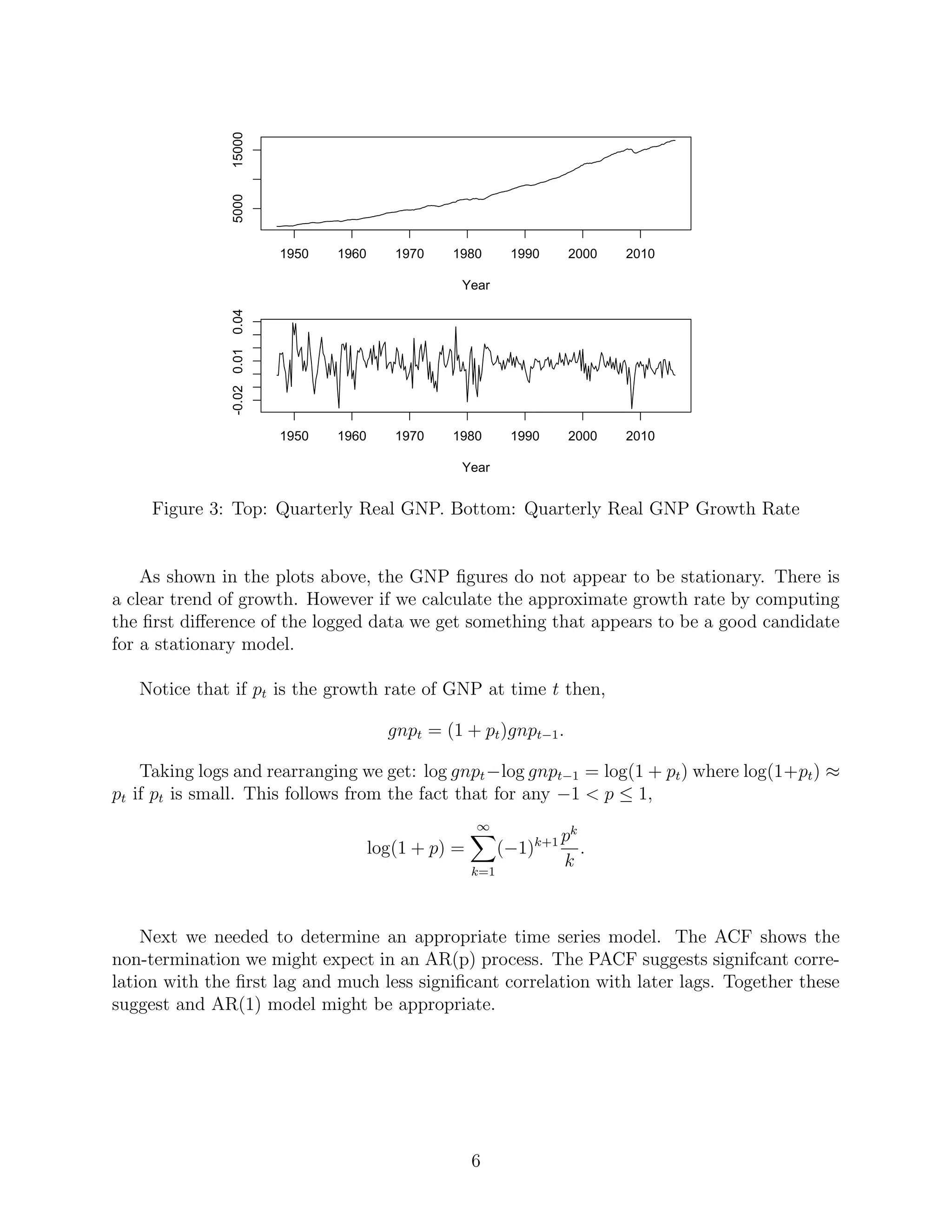
This document discusses using bootstrap methods to create confidence intervals for time series forecasts. It provides examples of time series data and introduces the AR(1) model. The document describes an algorithm for calculating a bootstrap confidence interval for forecasting from an AR(1) model. It then discusses a simulation study comparing empirical coverage rates of bootstrap confidence intervals under different parameters. Finally, it applies the bootstrap method to forecasting Gross National Product growth, comparing the results to a parametric approach.

![1 Introduction
In this report we will discuss some preliminaries about time series in general then explore
how we can apply bootstrap methods to create confidence intervals for forecasts from time
series data. Following Shumway and Stover [3], we first give some examples of times series
data, introduce the AR(1) model and the Partial Autocorrelation Function (PACF). We then
give an algorithm for calculating a bootstrap confidence interval of a forecast as discussed
in Chernick and LaBudde [1]. In the latter parts of the paper we use a modification of
their R code (pp 120-122) to conduct a simulation study and an application with real data.
In Section 5, we discuss the simulation process and report empirical coverage rates for our
bootstrap confidence intervals. In Section 6, we apply an AR(1) model Gross National
Product (GNP) growth data, comparing bootstrap and parametric approaches.
2 Time Series Basics
For our purposes, a time series is a sequence of data points spaced equally over time. In
general, the correlation between two adjacent points make it difficult to apply conventional
statistical methods that rely on the random variables being independent and identically dis-
tributed. However, with an appropriate time series model, one can make reasonably accurate
predictions about future values. First we give some basic examples and introduce some def-
initions.
A simple example of a time series model is a random walk with drift. Let
xt = δ + xt−1 + wt
where δ is some drift constant, and wt is some white noise coming from a distribution with
mean 0. For example, wt ∼ N(0, 1). If δ = 0, the model is simply a random walk. We will
use the above example to help illustrate a few concepts and definitions.
The mean function is defined by
µxt = E(xt)
or, when the time series is clearly specified, simply µt. Since we can write the random walk
with drift as xt = δt + t−1
j=1 wj, we get
µt = E(xt) = δt +
t−1
j=1
E(wj) = δt.
The autovariance funtion is defined by
γx(s, t) = cov(xs, xt) = E[(xs − µs)(xt − µt)].
The autocovariance function measures the linear dependence between two points. For the
random walk model with wt ∼ N(0, σ2
) we get
γx(s, t) = cov(xs, xt) = cov
s
j=1
wj,
t
j=1
wj = min{s, t}σ2
.
1](https://image.slidesharecdn.com/fb69b412-97cb-4e8d-8a28-574c09557d35-160618025920/75/Project-Paper-2-2048.jpg)
![The autocovariance function can be normalized to obtain the autocorrelation function
(ACF) written as
ρ(s, t) =
γ(s, t)
γ(s, s)γ(t, t)
.
The ACF measures the linear predictability between two variables in a time series. Using
the Cauchy-Schwartz inequality we get −1 ≤ ρ(s, t) ≤ 1.
In this paper we restrict our discussion to stationary time series. A time series is weakly
stationary if
(i) the mean value function µt is constant and does not depend on time, and
(ii) the autocovariance function, γ(s, t) depends on s and t only through their difference
|s − t|.
For now on we use the term stationary to mean weakly stationary.
Notice that a random walk and a random walk with drift are both non-stationary. The
random walk with drift fails both conditions (i) and (ii). A random walk passes condition
(i) but fails condition (ii).
For a stationary times series we now have
γ(h) = cov(xt+h, xt) = E[(xt+h − µ)(xt − µ)]
and
ρ(h) =
γ(h)
γ(0)
.
3 Autoregressive Models and The PACF
In what follows we will restrict our attention to the Autoregressive Model of order 1. An
Autoregressive Model of order p or AR(p), is a model of the form
xt = β1xt−1 + β2xt−2 + · · · + βpxp + et
where βi, 1 ≤ i ≤ p are nonzero constants, and the error terms et are iid random variables.
It is convenient to have E[xt] = 0. If E[xt] = 0, we replace xt with xt − E[xt].
We note here a theoretical result: given an AR(p) model, xt = β1xt−1 + · · · + βpxp + et,
we can associate it with the polynomial equation p(x) = xp
− β1xp−1
− · · · − βp−1x − βp with
real coefficients and roots in the complex plane. In order for stationarity to hold, all roots
of the polynomial must fall strictly inside the unit circle of the complex plane. In particular
for AR(1) we have p(x) = x − β, and so stationarity holds if |β| < 1.
A natural question is how to determine the appropriate value of p for a given time se-
ries. Prima facie, one might think that the ACF would be sufficient way to determine p. It
2](https://image.slidesharecdn.com/fb69b412-97cb-4e8d-8a28-574c09557d35-160618025920/75/Project-Paper-3-2048.jpg)
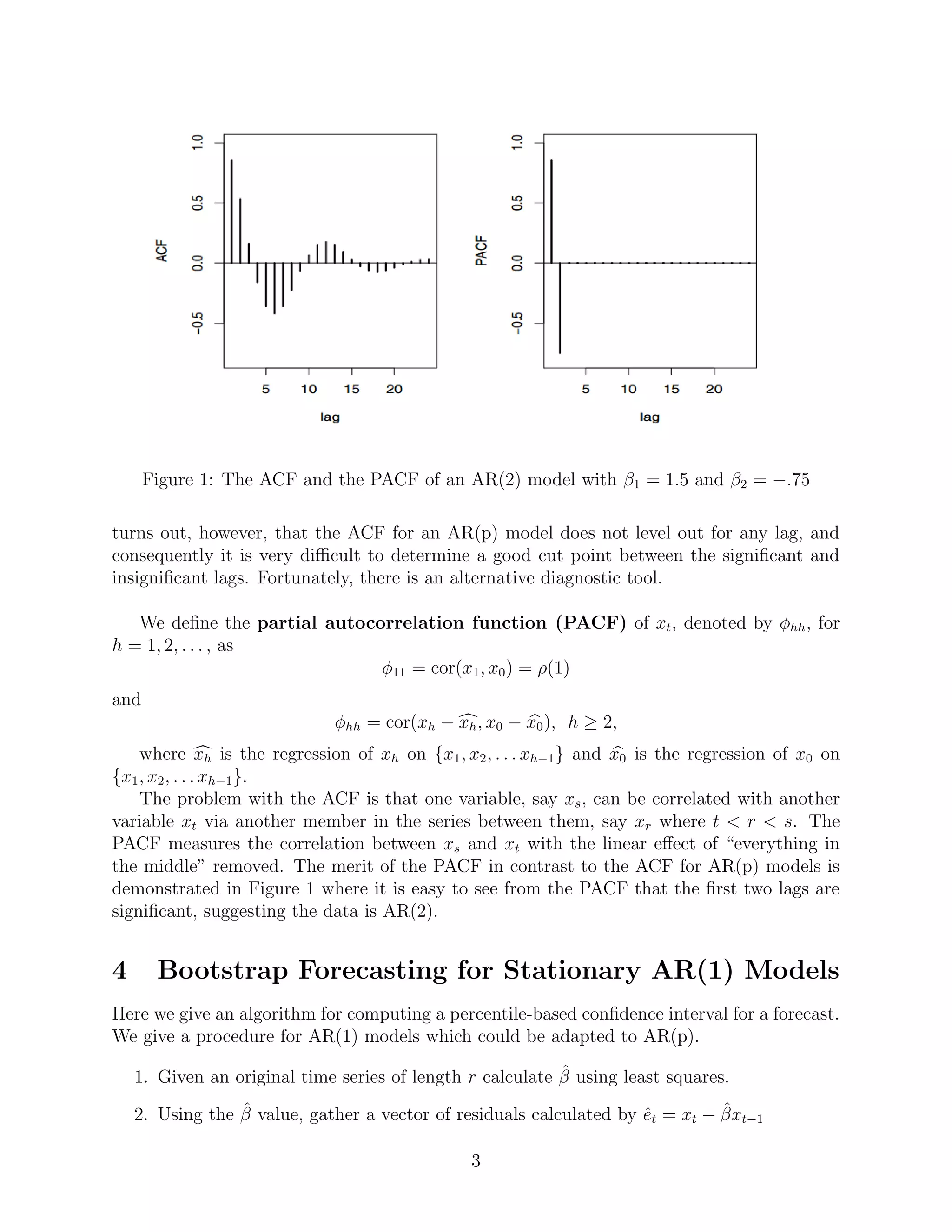



![While the plot does display a pattern, we notice that the correlations are small. We conclude
that the assumption of no correlation is reasonable in this case.
5 10 15 20 25
-0.10.00.10.20.3
Lag (Quarters)
PACF
Figure 5: PACF of Estimated Residuals
6.2 A Bootstrap Confidence Interval
Next, we estimate a forecast confidence interval using bootstrap. The workhorse function
here is tsboot from the boot package in R. We use this to perform the procedure described
in Section 4. After generating 1000 bootstrap time series we obtain the following:
ˆβ .362
Forecast growth rate 0.00795
Forecast Growth Rate CI (0.00011, 0.01564)
Forecast CI (dollars) (16625.08, 16885.17)
Based on this estimate we expect GNP in 2016 Q2 to be between about $16,625 and
$16,885.
We notice that the bootstrap forecast for the growth rate, .8% growth differs somewhat
from the parametric estimate of .5% growth and that the bootstrap confidence interval for
GNP in 2016 Q2 is wider than the parametric interval.
In addition, we can estimate the variance of an OLS estimate of β by looking at the
variance of the 1000 bootstrap estimates. We find that Var(ˆβ) = .002921 which closely
matches the theoretical value described above.
References
[1] Chernick, Michael R. Robert A. LaBudde, An Introduction To Bootstrap Methods with Applications to
R John Wiley and Sons 2012.
[2] Cryer,Jonathan D., Kung-Sik Chan, Time Series Analysis: With Applications in R Springer, Second Ed.
2008. pp 160-161.
8](https://image.slidesharecdn.com/fb69b412-97cb-4e8d-8a28-574c09557d35-160618025920/75/Project-Paper-9-2048.jpg)
![[3] Shumway, Robert H., David S. Stover, Time Series Analysis and Applications With R Examples, EZ
Green Edition 2016.4, 2016.
[4] Real Gross National Product [GNPC96],US. Bureau of Economic Analysis, retrieved from FRED, Federal
Reserve Bank of St. Louis <https://research.stlouisfed.org/fred2/series/GNPC96>, June 9, 2016.
9](https://image.slidesharecdn.com/fb69b412-97cb-4e8d-8a28-574c09557d35-160618025920/75/Project-Paper-10-2048.jpg)























![Inference in generative models using the Wasserstein distance [[INI]](https://cdn.slidesharecdn.com/ss_thumbnails/inewton-170706120746-thumbnail.jpg?width=640&height=640&fit=bounds)





























