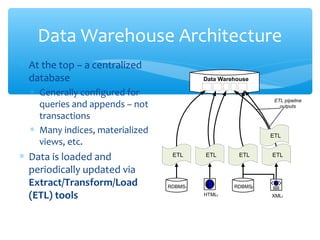
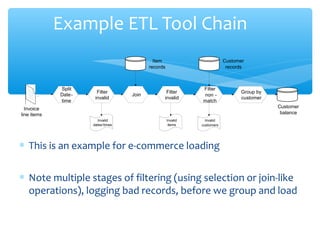
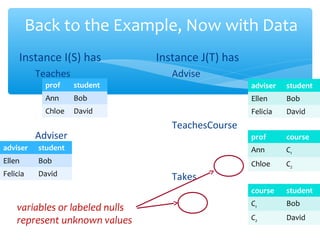
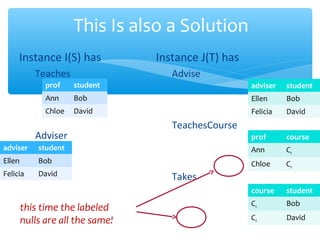
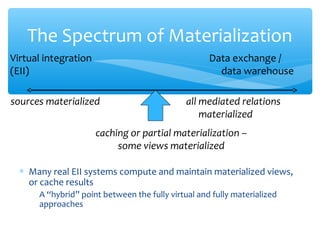
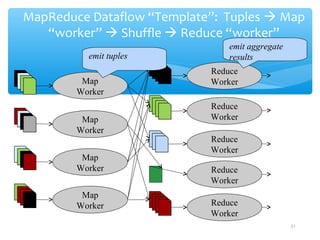
The document discusses techniques for virtual data integration and transformation as well as the role of data warehouses in master data management. It emphasizes the benefits of a centralized database for improved performance and data governance, detailing the use of ETL tools for extracting, transforming, and loading data. Additionally, it explores the evolving landscape of data integration with hybrid approaches, including the use of MapReduce for querying large datasets.















































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




