The document discusses privacy and security issues with recommender systems as they become more contextual and utilize deep learning techniques. It proposes that as recommender systems are able to analyze more user data through cloud computing, there are increased risks of privacy breaches and data hacking. The researchers conducted a survey that found professionals have significant concerns about emerging technologies, privacy/security of recommender systems, and mobile device security. They propose further research into cryptographic methods like homomorphic encryption that could help secure user data processed by recommender systems.





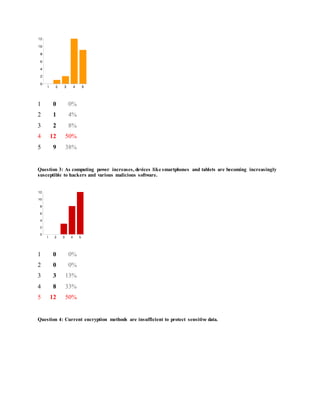











































![Mexcur paul[2]](https://cdn.slidesharecdn.com/ss_thumbnails/mexcurpaul2-140903144014-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























