Download to read offline























![<div itemprop="image" itemscope="" itemtype="http://schema.org/ImageObject">
<meta itemprop="description" content="I-797, Notice of Action: I-601, application for travel docu
<div itemprop="exampleOfWork" itemscope="" itemtype="http://schema.org/CreativeWork" >
<meta itemprop="isBasedOnUrl" content="http://www.uscis.gov/i-601" />
</div>
[caption]<a itemprop="url" href="XXX"><img itemprop="image" src="XXX" alt="XXX" width="" he
</div>](https://image.slidesharecdn.com/issmay2018-180521200001/85/Principles-of-Structured-Data-Implementation-for-Multilingual-Websites-30-320.jpg)


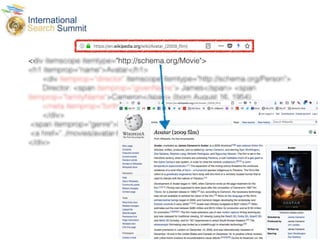
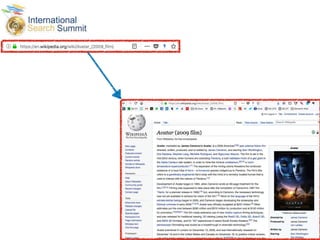







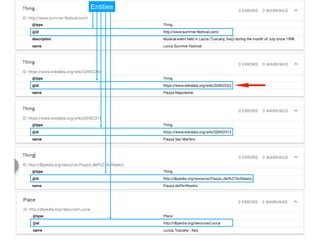
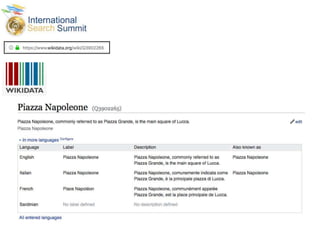


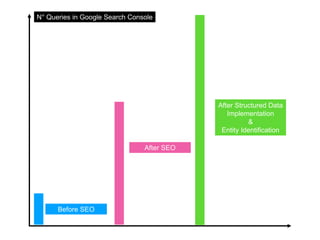




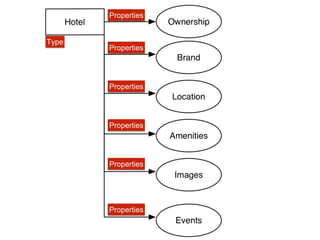
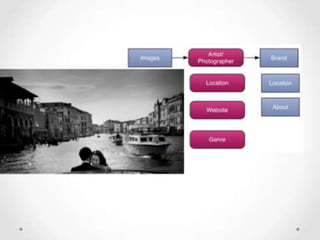
The document discusses structured data principles for multilingual websites, emphasizing the importance of creating a model to organize website content clearly and reduce ambiguity. It highlights the transition from keywords to entities, the role of structured data in providing unambiguous signals, and outlines practical steps for implementation. Additionally, it introduces DBpedia as a resource for extracting structured information from Wikipedia to enhance data processing.

















































