Download as PDF, PPTX







![Queries can be as complex as you want
SELECT * FROM tweets WHERE lucene = ‘{
filter :
{
type : "boolean", must :
[
{type : "range", field : "time" lower : "2014/04/25”},
{type : "boolean", should :
[
{type : "prefix", field : "user", value : "a"} ,
{type : "wildcard", field : "user", value : "*b*"} ,
{type : "match", field : "user", value : "fast"}
]
}
]
},
sort :
{
fields: [ {field :"time", reverse : true},
{field : "user", reverse : false} ]
}
}’ LIMIT 10000;
#CassandraSummit 2014 20](https://image.slidesharecdn.com/advancedsearchandtop-kqueriesincassandracassandrasummiteurope2014-141210033634-conversion-gate01/75/Advanced-search-and-Top-k-queries-in-Cassandra-Cassandra-Summit-Europe-2014-20-2048.jpg)


![Query builder example
SELECT * FROM tweets WHERE lucene =
‘{
query : {type : "range",
field : "time”,
lower : "2014/04/25”,
upper : "2014/04/30”},
filter : {type : "match",
field : "text",
value : "cassandra"},
sort :
{
fields: [ {field :"time",
reverse : true}} ]
}
}’ LIMIT 10;
String'filter'='SearchBuilders'
'''.filter(range("time")'
'''''''''''''.lower("2014/04/25")'
'''''''''''''.upper("2014/04/30"))'
'''.query(match("text",'"cassandra")'
'''.sort(sorting("time",'true))'
'''.toJson();'
'
QueryBuilder.select()''''''''''''''''''''''''''
'''.from(KEYSPACE,'TABLE)'
'''.where(eq("lucene",'filter))'
'''.limit(10)
#CassandraSummit 2014 24](https://image.slidesharecdn.com/advancedsearchandtop-kqueriesincassandracassandrasummiteurope2014-141210033634-conversion-gate01/75/Advanced-search-and-Top-k-queries-in-Cassandra-Cassandra-Summit-Europe-2014-24-2048.jpg)

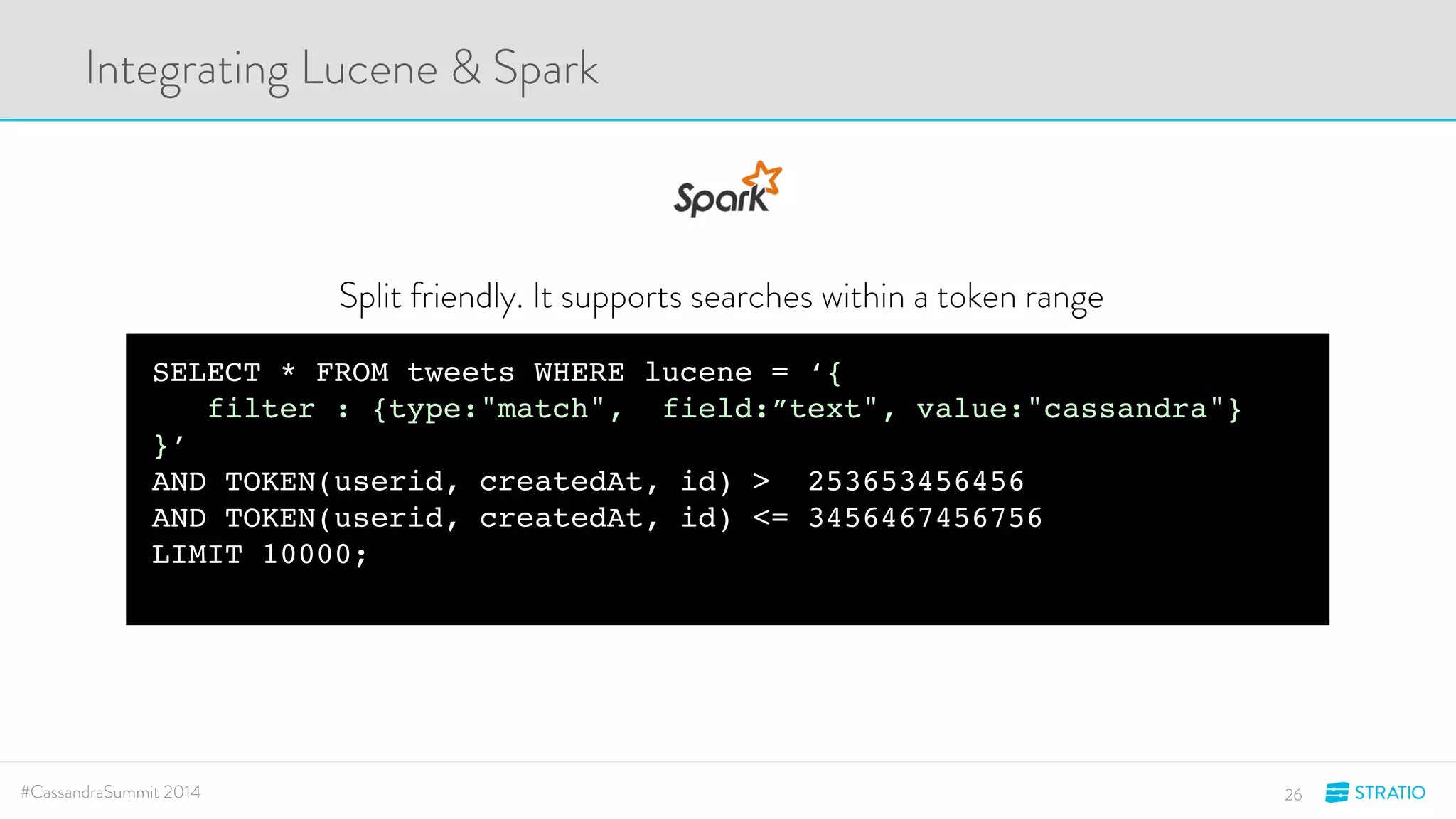
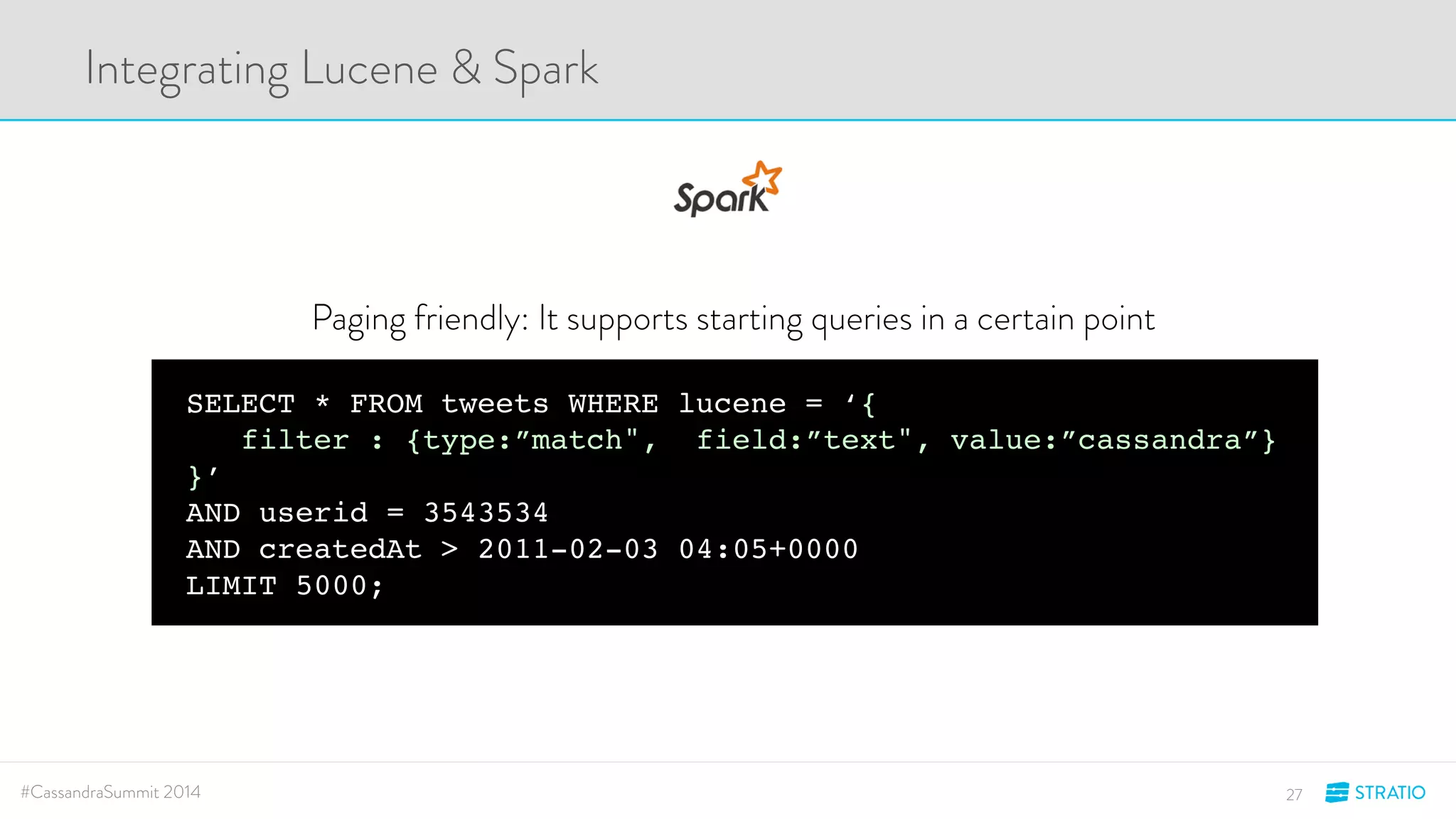
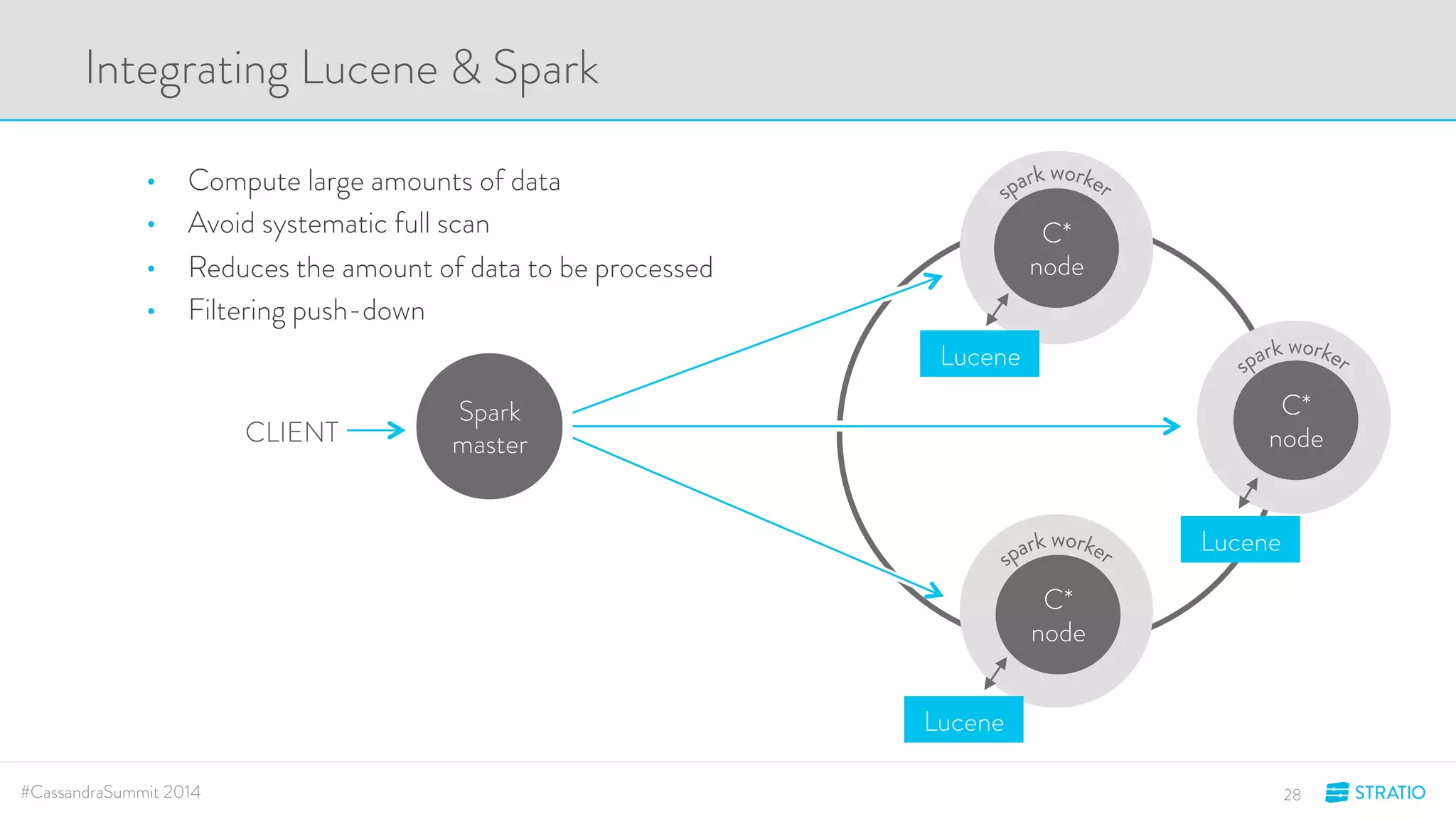

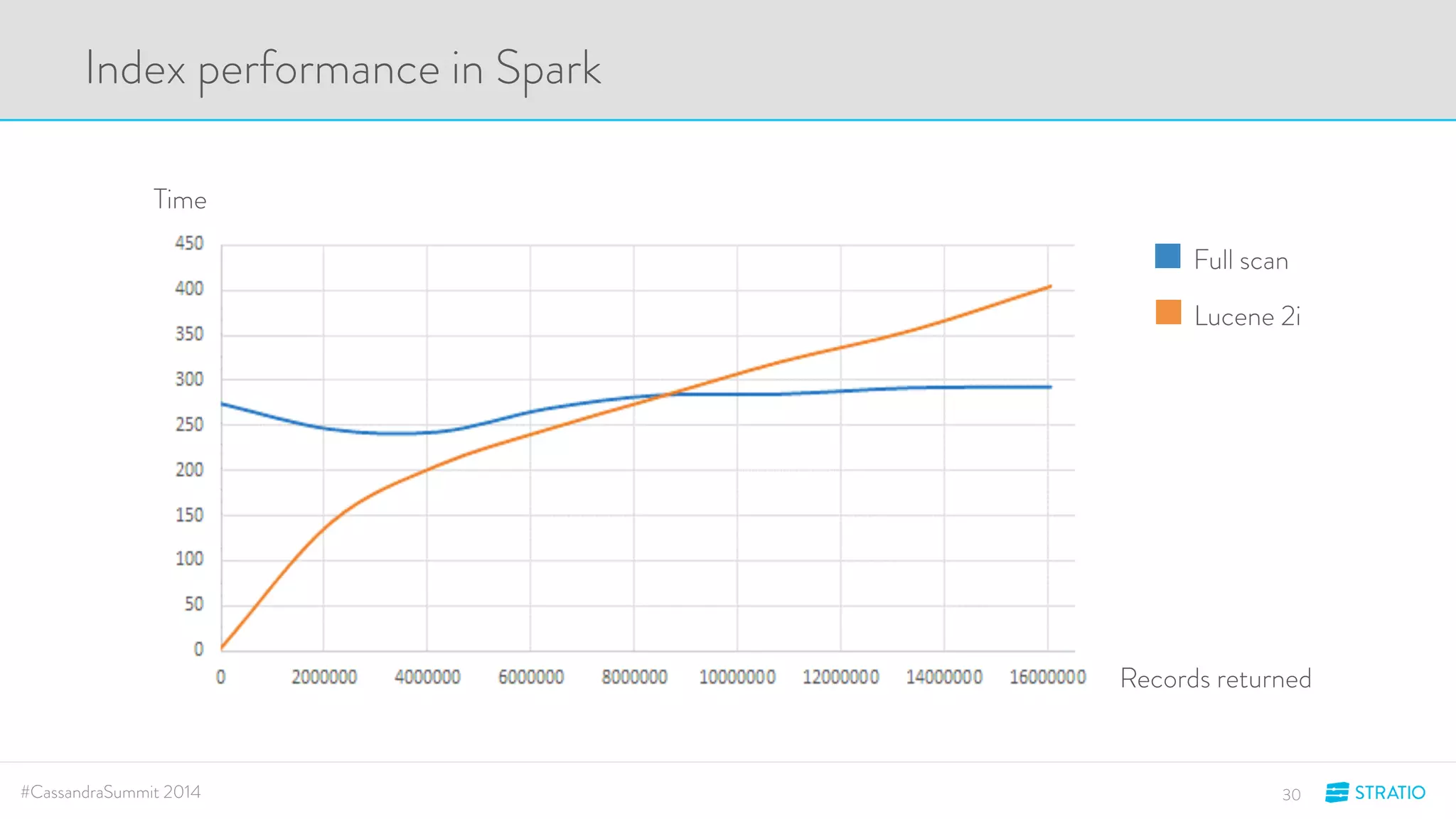



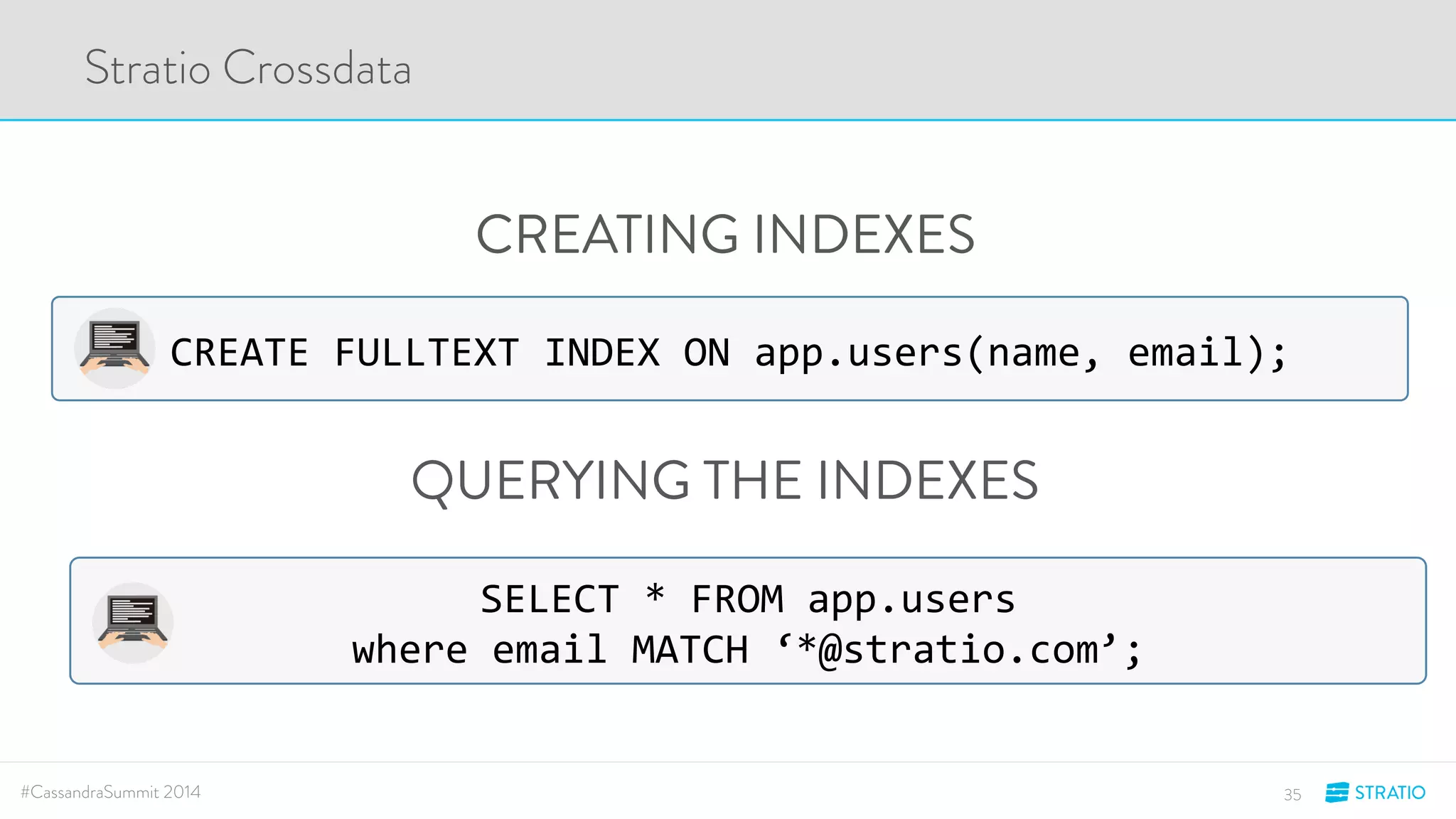
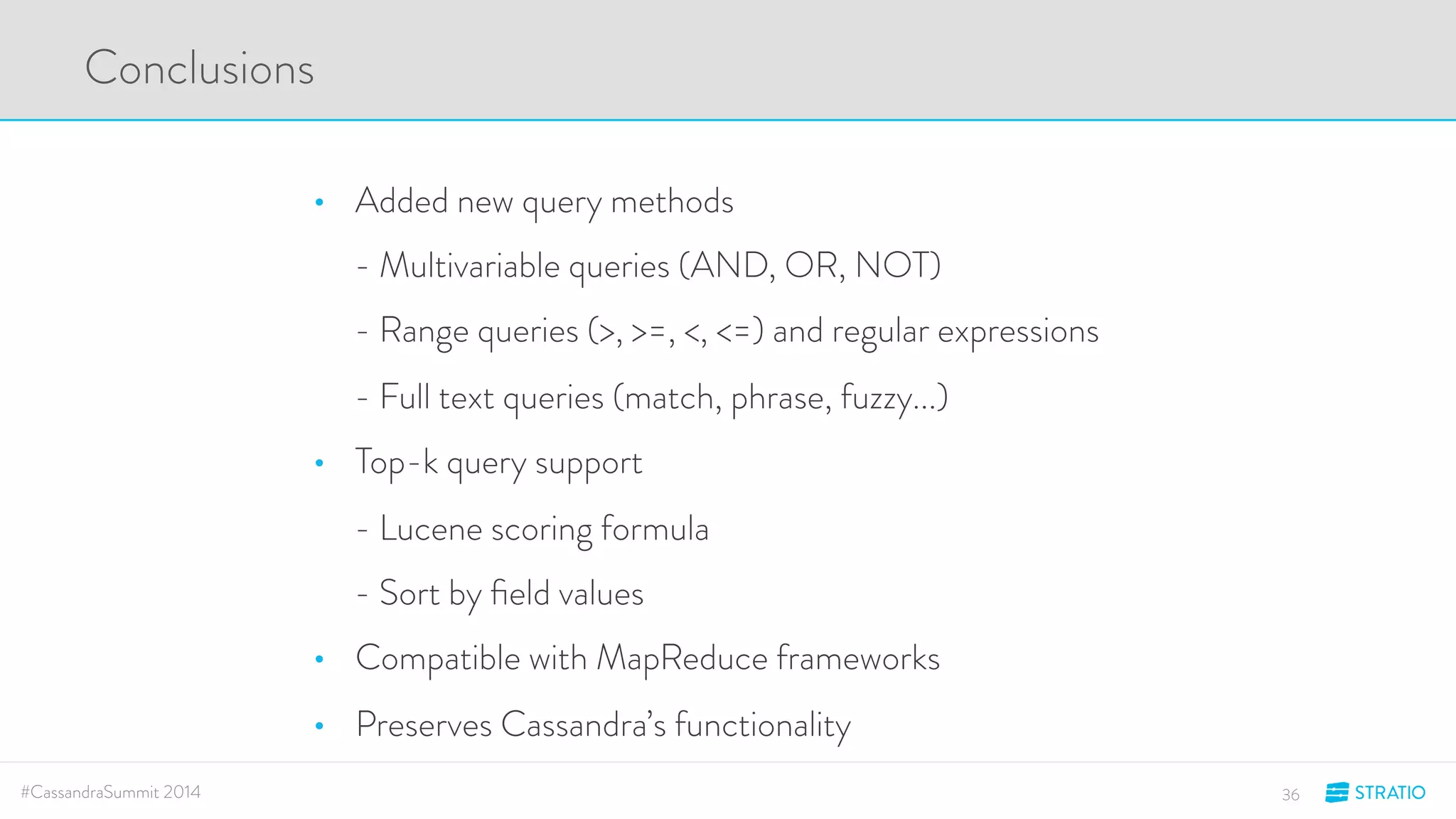


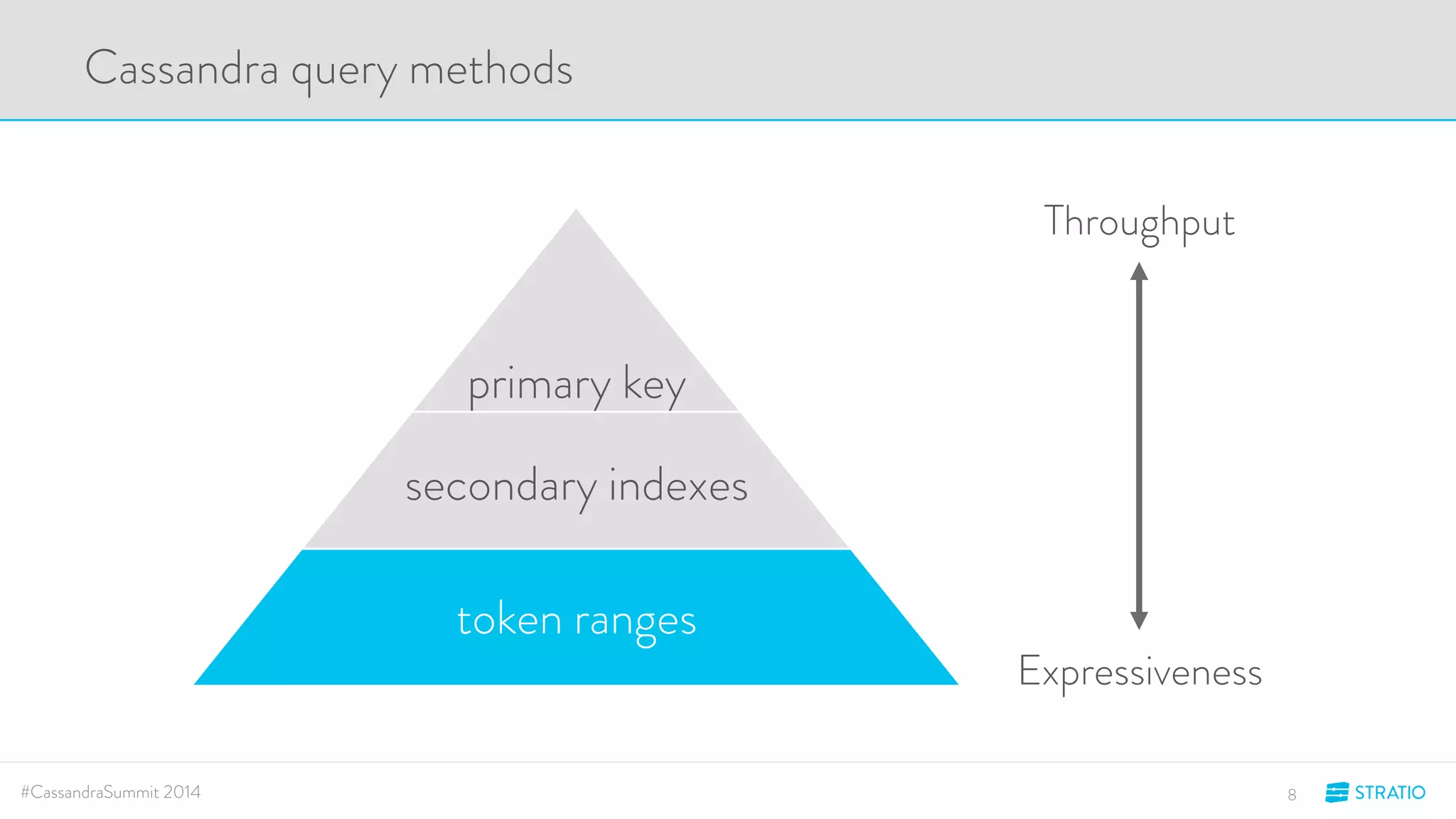
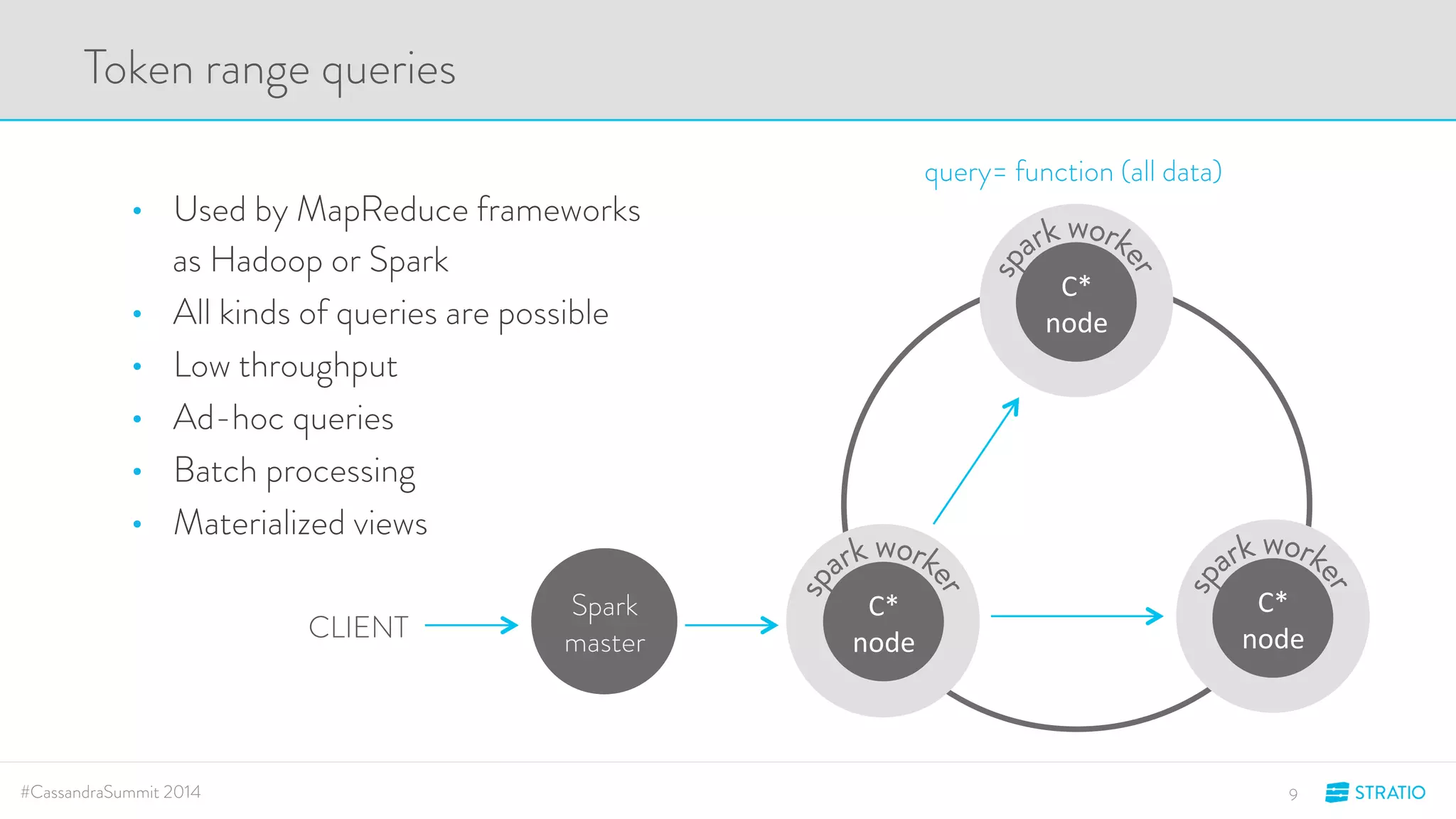
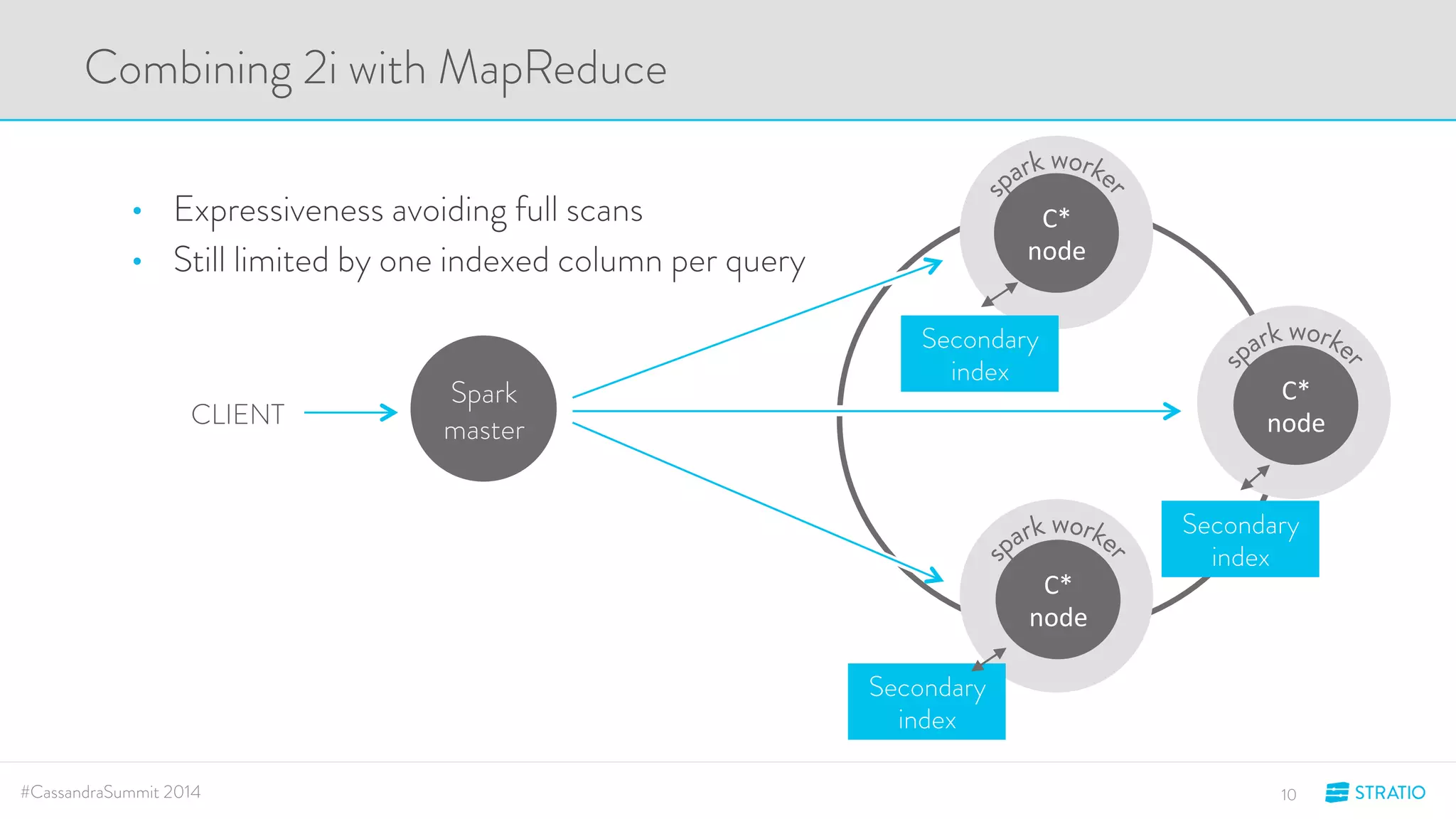
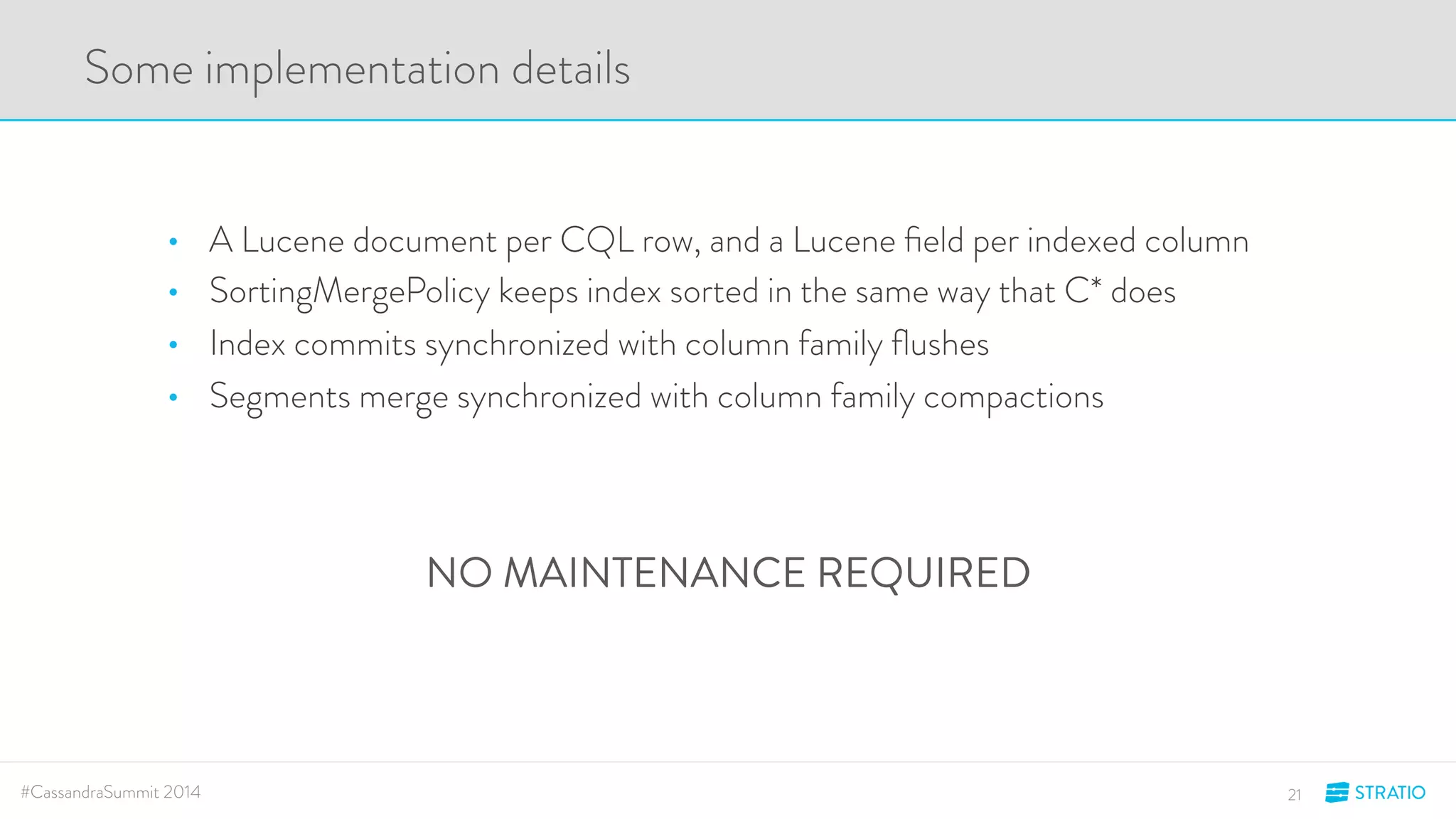
This document discusses advanced search and top-K queries in Cassandra. It proposes integrating Lucene indexes with each Cassandra node to enable more expressive queries like range queries, multi-variable searches, and top-K queries. The integration would allow each node to index its own data with Lucene while supporting distributed queries. The approach aims to combine the expressiveness of Lucene with Cassandra's architecture and compatibility with Spark.



![[Spark meetup] Spark Streaming Overview](https://cdn.slidesharecdn.com/ss_thumbnails/sparkmeetupstratiostreaming-150121022614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)












































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













