Downloaded 12 times



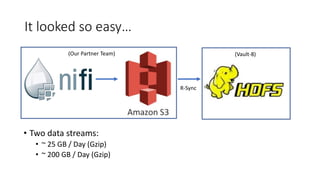
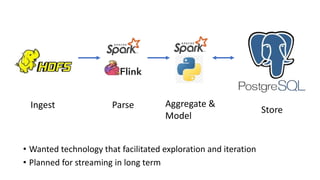

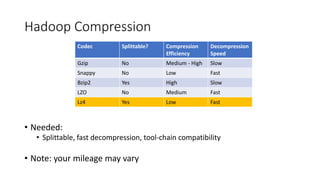
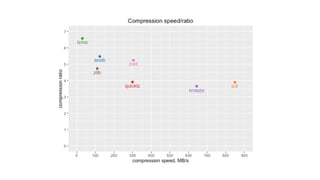





















The document discusses the complexities and challenges faced in data engineering, focusing on issues like data compression and ingestion. It highlights the inefficiencies of various compression formats and the need for splittable formats compatible with existing tools, ultimately recommending the use of lz4. The author shares lessons learned, emphasizing the importance of system changes, thorough testing, and having a robust backup plan.



































































