Downloaded 50 times






![Definitions
- Return: total discounted reward:
- Policy: Agent’s behavior
- Deterministic policy: π(s) = a
- Stochastic policy: π(a | s) = P[At = a | St = s]
- Value function: Expected return starting from state s:
- State-value function: Vπ(s) = Eπ[R | St = s]
- Action-value function: Qπ(s, a) = Eπ[R | St = s, At = a]](https://image.slidesharecdn.com/practicalrlwithtensorflow-170509162822/85/Practical-Reinforcement-Learning-with-TensorFlow-8-320.jpg)




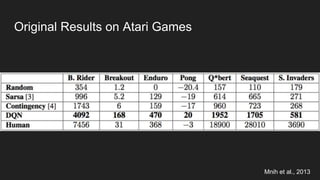
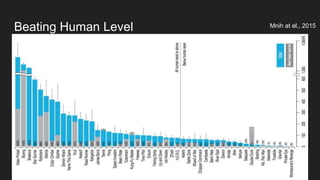



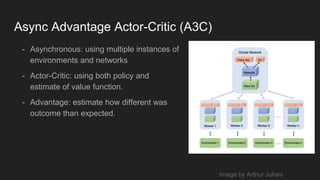







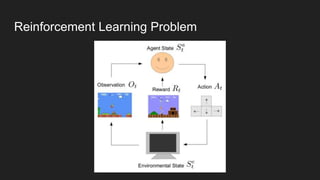
This document discusses reinforcement learning techniques for solving problems modeled as Markov decision processes using TensorFlow. It introduces the OpenAI Gym environment for testing RL algorithms, describes modeling problems as MDPs and key concepts like state-value functions and Q-learning. Deep Q-learning and policy gradient methods are explained for approximating value and policy functions with neural networks. Asynchronous advantage actor-critic (A3C) is presented as an effective approach and results are shown matching or beating human performance on Atari games. Practical applications of RL are identified in robotics, finance, optimization and predictive assistants.






















































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)












