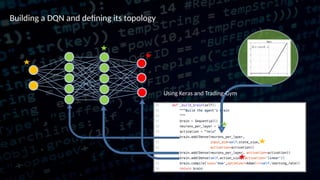
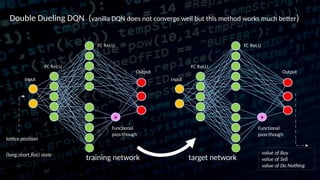
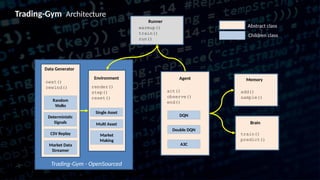
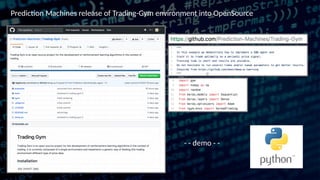
This document discusses the application of reinforcement learning, particularly Q-reinforcement learning (QRL), in automated trading, drawing parallels with learning processes in children. It introduces a trading environment built using TensorFlow and Keras, alongside concepts like mean-reversion strategies and various enhancements to learning algorithms to improve trading performance. The document also highlights the release of open-source tools, such as trading-gym and trading-brain, designed for simulating and visualizing trading strategies.

















![Tensorflow key API
Namespaces for organizing the graph and showing in tensorboard
with tf.variable_scope('prediction'):
Sessions
with tf.Session() as sess:
Create variables and placeholders
var = tf.placeholder('int32', [None, 2, 3], name='varname’)
self.global_step = tf.Variable(0, trainable=False)
Session.run or variable.eval to run parts of the graph and retrieve values
pred_action = self.q_action.eval({self.s_t['p']: s_t_plus_1})
q_t, loss= self.sess.run([q['p'], loss], {target_q_t: target_q_t, action: action})](https://image.slidesharecdn.com/pythonmeetuppresentation-170707022217/85/Deep-Learning-in-Python-with-Tensorflow-for-Finance-27-320.jpg)



















































