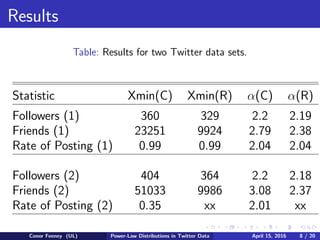
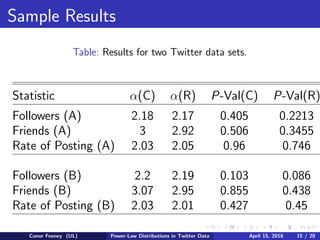
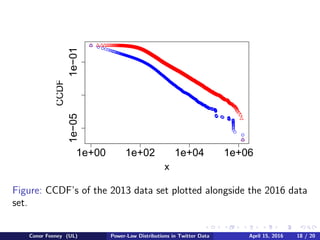
The document examines power-law distributions in Twitter data. It collected over 8 million rows of Twitter data using the TwitteR package in R. Testing showed that the number of followers, friends, and posting rates followed power-law distributions. Synthetic data was generated and the Kolmogorov-Smirnov test confirmed the power-law fits. While R's poweRlaw package provided reasonable results, Aaron Clauset's code was more accurate. Comparing to 2013 data, the power-law distributions for number of followers was similar, showing the structure of Twitter has remained stable.