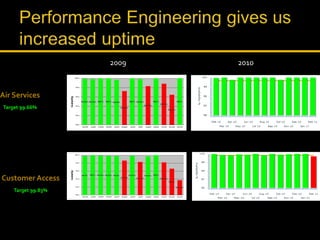
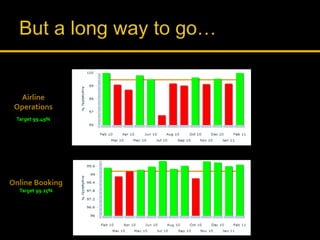
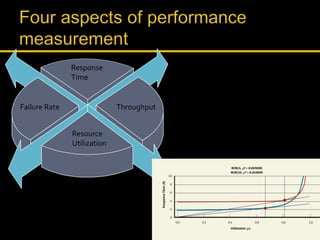
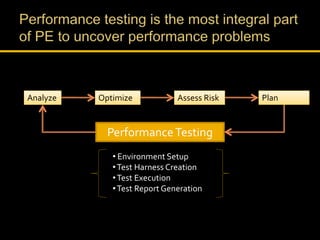
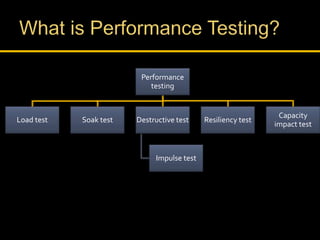
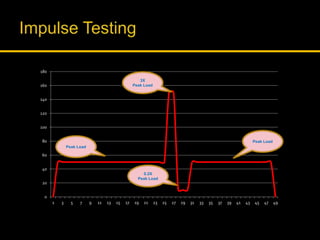
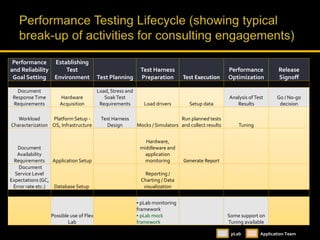
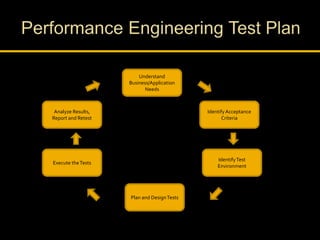
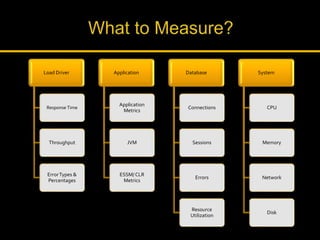
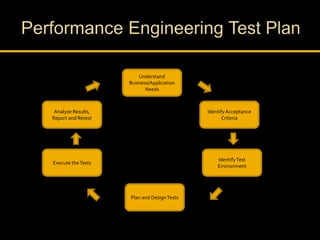
Kingshuk Dasgupta leads pLab, which helps institutionalize performance engineering across the enterprise. pLab aims to promote performance awareness, educate teams, benchmark technologies, and build a shared testing environment. Performance is defined as a system's ability to meet objectives for response time, stability, scalability, and efficiency. Issues caused by poor performance include increased costs and lost income/competitiveness. pLab monitors key metrics like response times and outages to ensure service level targets are met.