












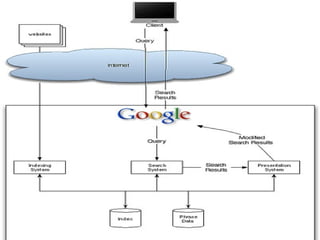









The document describes phrase-based indexing for information retrieval systems. It discusses identifying phrases in documents, indexing documents according to related phrases, ranking documents based on contained phrases and anchor phrases, and using phrases to generate descriptions of documents. The system can also detect duplicate and spam documents using the phrase information.



































































