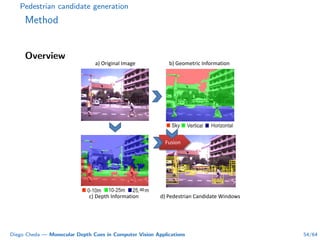
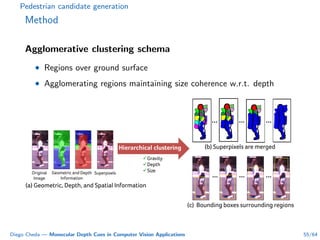
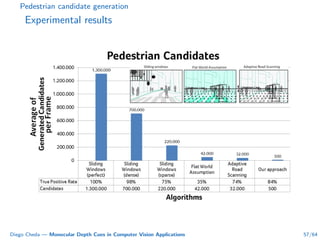
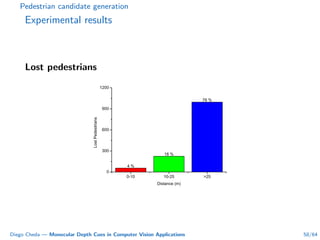
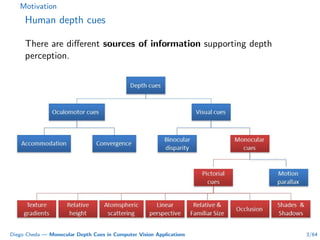
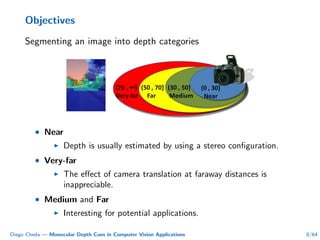
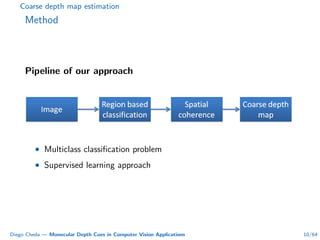
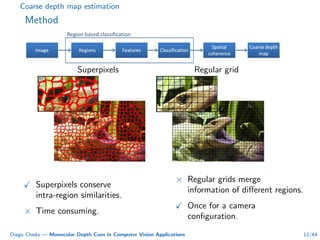
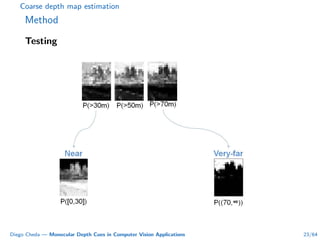
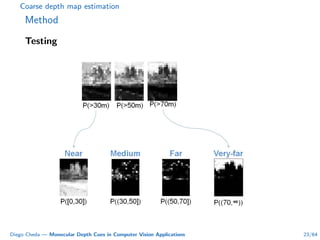
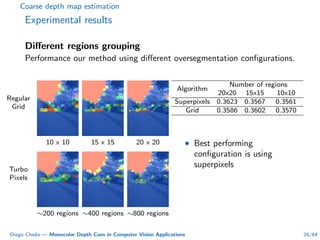
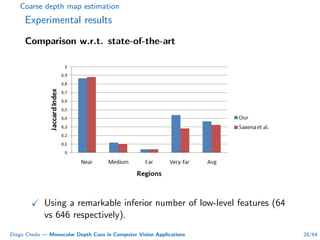
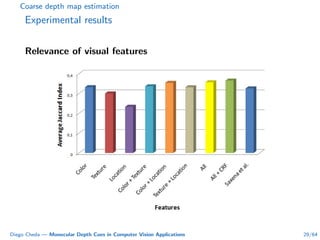
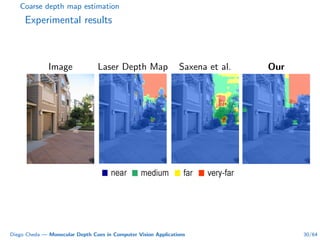
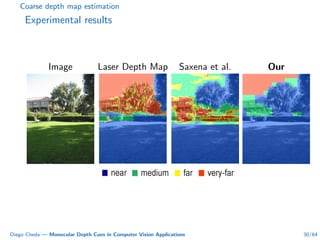
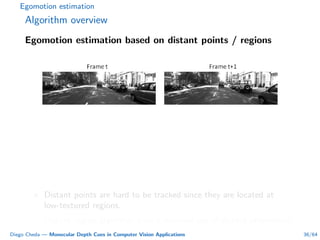
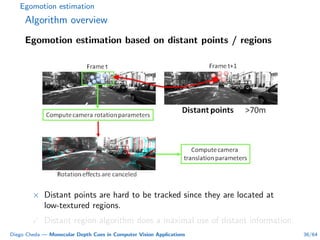
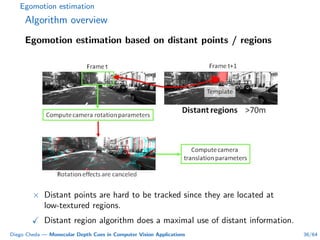
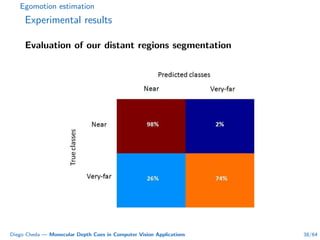
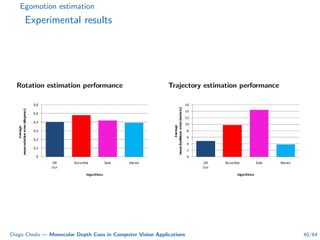
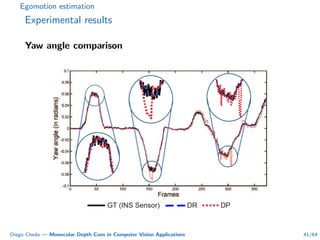
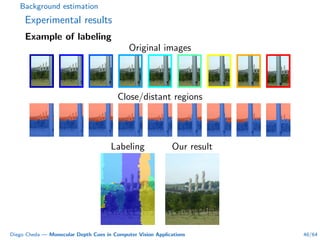
This document summarizes Diego Cheda's thesis on using monocular depth cues in computer vision applications. The thesis outlines methods for coarse depth map estimation, egomotion estimation, background estimation, and pedestrian candidate generation using monocular cues. For coarse depth map estimation, the author presents a supervised learning approach to segment images into near, medium, far, and very far depth categories using low-level visual features. Experimental results show the approach outperforms other methods using fewer features. The thesis also describes algorithms for egomotion estimation based on tracking distant regions and comparing results to other state-of-the-art methods, showing the distant region approach provides accurate rotation estimates.


![We don’t need two eyes to perceive depth.
[Edgar Muller]](https://image.slidesharecdn.com/e048a3a1-ca62-45da-b295-61ad378b9b42-160502065115/85/PhD_ppt_2012-2-320.jpg)







































![Pedestrian candidate generation
Problem definition
Pedestrian candidate generation Generating hypothesis to be
evaluated by a pedestrian classifier.
[Ger´onimo 2010]
Goal
Exploiting geometric and depth information available on single images
to reduce the number of windows to be further processed.
Diego Cheda — Monocular Depth Cues in Computer Vision Applications 53/64](https://image.slidesharecdn.com/e048a3a1-ca62-45da-b295-61ad378b9b42-160502065115/85/PhD_ppt_2012-69-320.jpg)
![Pedestrian candidate generation
Problem definition
Pedestrian candidate generation Generating hypothesis to be
evaluated by a pedestrian classifier.
[Ger´onimo 2010]
Goal
Exploiting geometric and depth information available on single images
to reduce the number of windows to be further processed.
Diego Cheda — Monocular Depth Cues in Computer Vision Applications 53/64](https://image.slidesharecdn.com/e048a3a1-ca62-45da-b295-61ad378b9b42-160502065115/85/PhD_ppt_2012-70-320.jpg)