Download as PDF, PPTX















![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
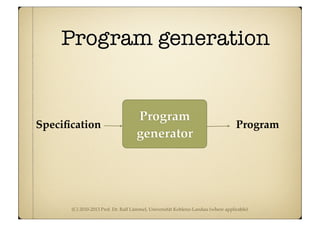
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
}
This is basically boilerplate
code. Copy and Paste!](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-18-320.jpg)
![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
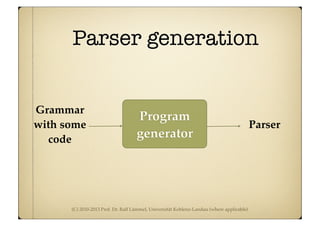
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
}
Prepare System.in
as ANTLR input
stream](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-19-320.jpg)
![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
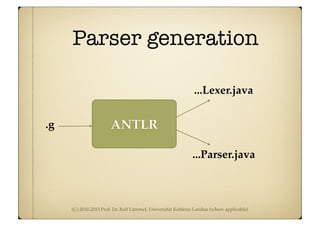
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
}
Set up lexer
for language](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-20-320.jpg)
![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
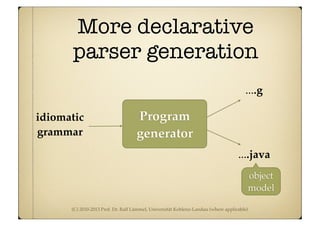
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
}
Obtain token
stream from lexer](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-21-320.jpg)
![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
} Set up parser and
feed with token
stream of lexer](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-22-320.jpg)
![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
Driver for acceptor
import org.antlr.runtime.*;
public class Test {
public static void main(String[] args) throws Exception {
ANTLRInputStream input = new ANTLRInputStream(System.in);
SetyLexer lexer = new ...Lexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
...Parser parser = new ...Parser(tokens);
parser....();
}
}
Invoke start
symbol of parser](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-23-320.jpg)






![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
Parser descriptions can also use
“synthesized” attributes.
Add synthesized attributes to nonterminals.
Add semantic actions to productions.
expr returns [int value]
: e=multExpr {$value = $e.value;}
( '+' e=multExpr {$value += $e.value;}
| '-' e=multExpr {$value -= $e.value;}
)*;
(Context-free part in bold face.)
Compute an int
value
Perform addition
& Co.](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-30-320.jpg)



![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
With semantic actions for
object construction included
company returns [Company c]:
{ $c = new Company(); }
'company' STRING
{ $c.setName($STRING.text); }
'{'
( topdept= department
{ $c.getDepts().add($topdept.d); }
)*
'}'
;
Construct company object.
Set name of company.
Add all departments.](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-34-320.jpg)













![(C) 2010-2013 Prof. Dr. Ralf Lämmel, Universität Koblenz-Landau (where applicable)
Cut: Tree walking with ANTLR
Match trees
Rebuild tree
topdown : employee;
employee :
^(EMPLOYEE STRING STRING s=FLOAT)
-> ^(EMPLOYEE
STRING
STRING
FLOAT[
Double.toString(
Double.parseDouble(
$s.text) / 2.0d)])
;
Tree walking
strategy](https://image.slidesharecdn.com/pgen-130514030151-phpapp02/85/Generative-programming-mostly-parser-generation-48-320.jpg)










The document discusses various patterns for generative programming including parser generation. It describes using a context-free grammar as input to automatically generate a parser. The key steps are: 1. Define regular expressions for tokens and context-free productions for nonterminals 2. Generate code for the parser from the grammar 3. Write boilerplate code to execute the generated parser and feed it a token stream. The overall approach is to specify language structure through a grammar and then generate artifacts like lexers and parsers that can recognize or operate on that language.
































































































