Download as PDF, PPTX













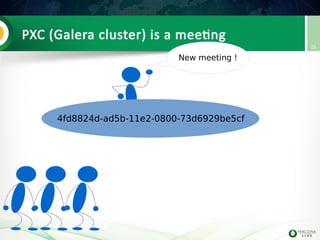











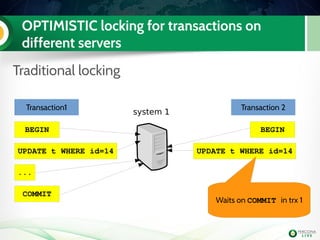



![Lab 2: Install PXC on node3
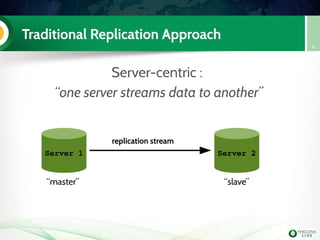
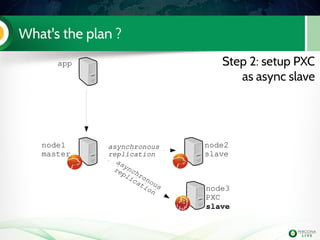
Install PerconaXtraDBCluster
server56
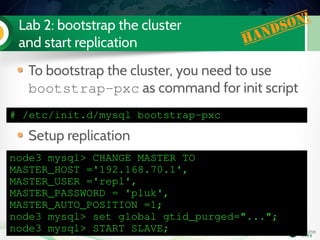
Edit my.cnf to have the mandatory PXC
settings
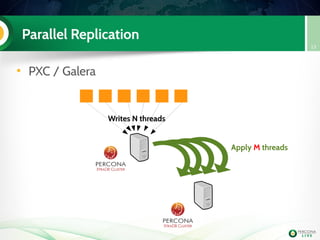
node3
PXC
Handson!
[mysqld]
binlog_format=ROW
wsrep_provider=/usr/lib/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.70.3
wsrep_node_address=192.168.70.3
wsrep_cluster_name=Pluk2k13
wsrep_node_name=node3
innodb_autoinc_lock_mode=2](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-50-320.jpg)


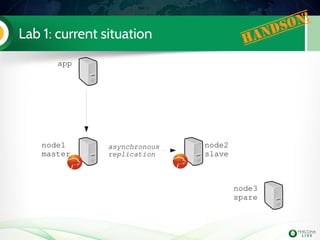
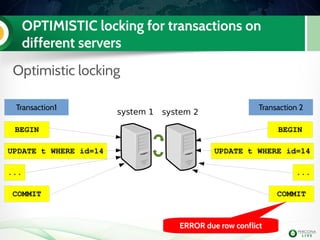
![Lab 2: It's time for some extra work ! Handson!
It's always better to have a specific user to use
with xtrabackup (we will use it later for SST too)
Even if you use the default datadir in MySQL,
it's mandatory to add it in my.cnf
node1 mysql> GRANT reload, lock tables, replication client ON
*.* TO 'sst'@'localhost' IDENTIFIED BY 'sst';
datadir=/var/lib/mysl
[xtrabackup]
user=sst
password=sst](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-53-320.jpg)

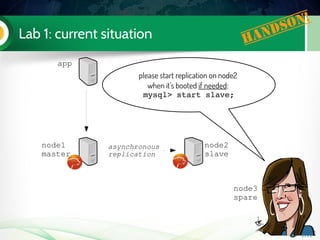
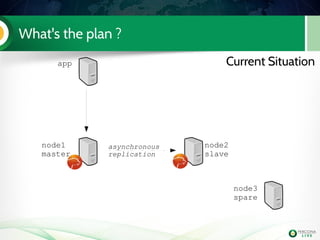
![Lab 2: configuration for replication Handson!
[mysqld]
binlog_format=ROW
log_slave_updates
wsrep_provider=/usr/lib/libgalera_smm.so
wsrep_cluster_address=gcomm://192.168.70.3
wsrep_node_address=192.168.70.3
wsrep_cluster_name=Pluk2k13
wsrep_node_name=node3
wsrep_slave_threads=2
wsrep_sst_method=xtrabackupv2
wsrep_sst_auth=sst:sst
innodb_autoinc_lock_mode=2
innodb_file_per_table
gtid_mode=on
enforce_gtid_consistency
skip_slave_start
serverid=3
log_bin=mysqlbin
datadir=/var/lib/mysql
[xtrabackup]
user=sst
password=sst](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-56-320.jpg)
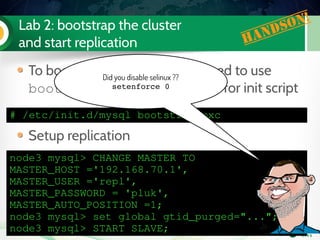
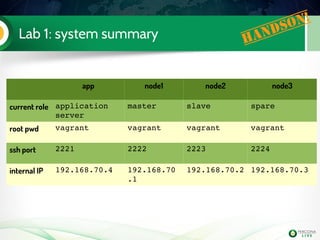
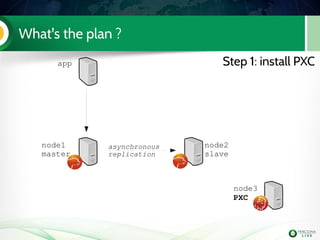
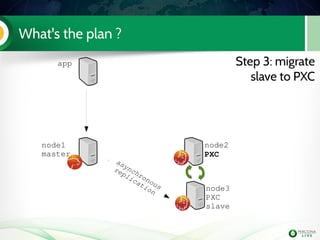
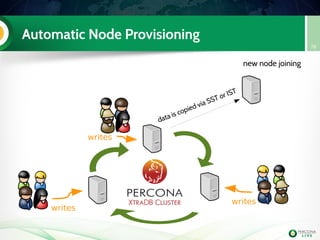
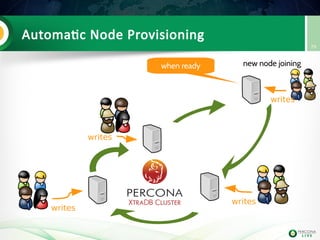
![Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both
PXC nodes
node2
PXC
node3
PXC
slave
Handson!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3
wsrep_node_address=192.168.70.2
wsrep_node_name=node2
[...]](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-59-320.jpg)
![Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both
PXC nodes
node2
PXC
node3
PXC
slave
Handson!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3
wsrep_node_address=192.168.70.2
wsrep_node_name=node2
[...]
Did you disable selinux ??
setenforce 0](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-60-320.jpg)
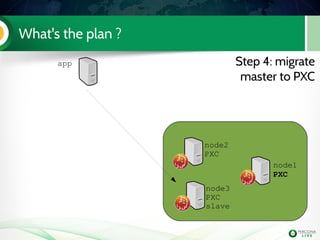
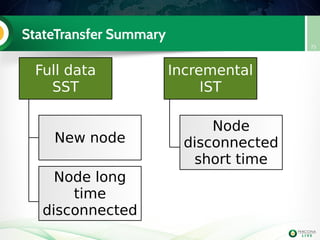
![Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both
PXC nodes
node2
PXC
node3
PXC
slave
Handson!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3
wsrep_node_address=192.168.70.2
wsrep_node_name=node2
[...]
on node3 (the donor) tail the file innobackup.backup.log in datadir
on node 2 (the joiner) as soon as created check the file innobackup.prepare.log](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-61-320.jpg)
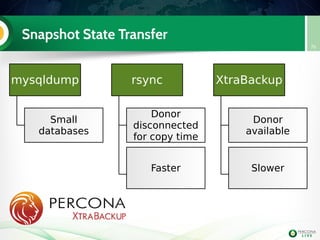
![Lab 3: migrate 5.6 slave to PXC (step 3)
Install PXC on node2
Configure it
Start it (don't bootstrap it !)
Check the mysql logs on both
PXC nodes
node2
PXC
node3
PXC
slave
Handson!
wsrep_cluster_address=gcomm://192.168.70.2,192.168.70.3
wsrep_node_address=192.168.70.2
wsrep_node_name=node2
[...]
we can check on one of the nodes if the cluster
is indeed running with two nodes:
mysql> show global status like 'wsrep_cluster_size';
+++
| Variable_name | Value |
+++
| wsrep_cluster_size | 2 |
+++](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-62-320.jpg)


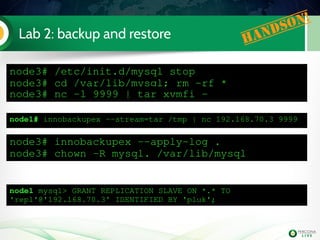
![Lab 4: Xtrabackup & xbstream
as SST (step 4)
Migrate the master to PXC
Configure SST to use Xtrabackup with 2
threads and compression
[mysqld]
wsrep_sst_method=xtrabackupv2
wsrep_sst_auth=sst:sst
[xtrabackup]
compress
parallel=2
compressthreads=2
[sst]
streamfmt=xbstream
Handson!
qpress needs to be
installed on all nodes
don't forget to stop & reset async slave](https://image.slidesharecdn.com/pxctutorialpluk2k14-160520082302/85/Percon-XtraDB-Cluster-in-a-nutshell-70-320.jpg)





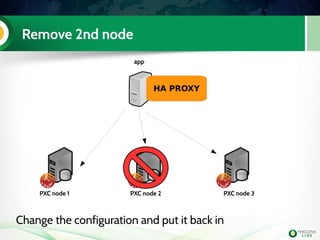
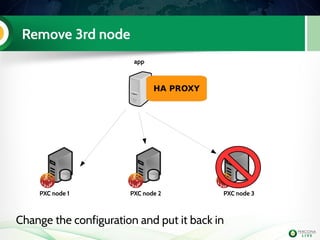











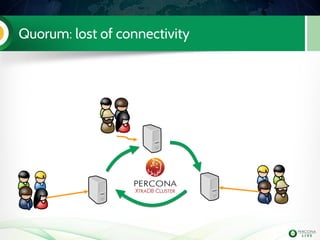
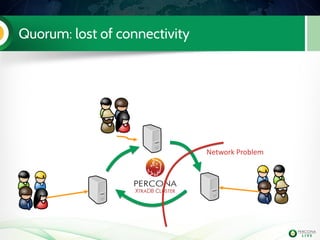

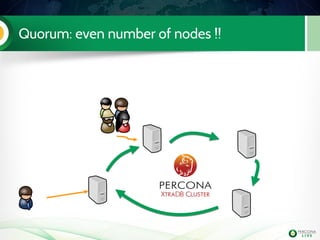
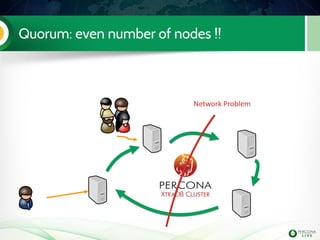
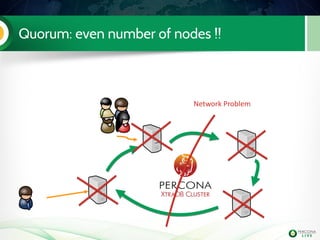
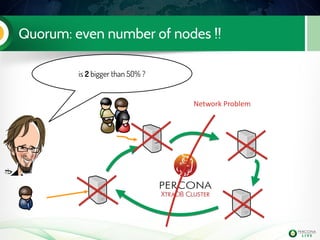




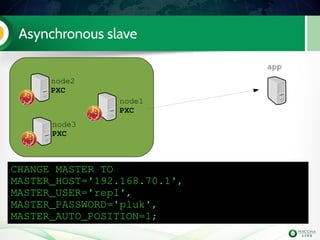
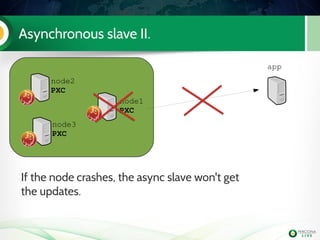
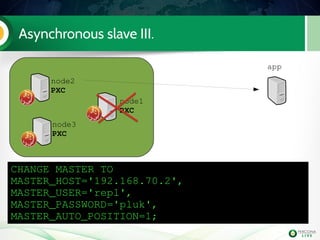
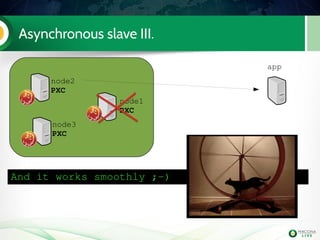













The document is a hands-on tutorial on the Percona XtraDB Cluster, covering essential topics such as migration from a master/slave setup, Galera replication concepts, and application interaction. It also includes detailed steps for setting up, configuring, and migrating to the XtraDB Cluster, highlighting the differences between synchronous and asynchronous replication. Limitations and best practices for optimizing the use of the cluster are shared throughout the tutorial.







































































































