Downloaded 63 times



























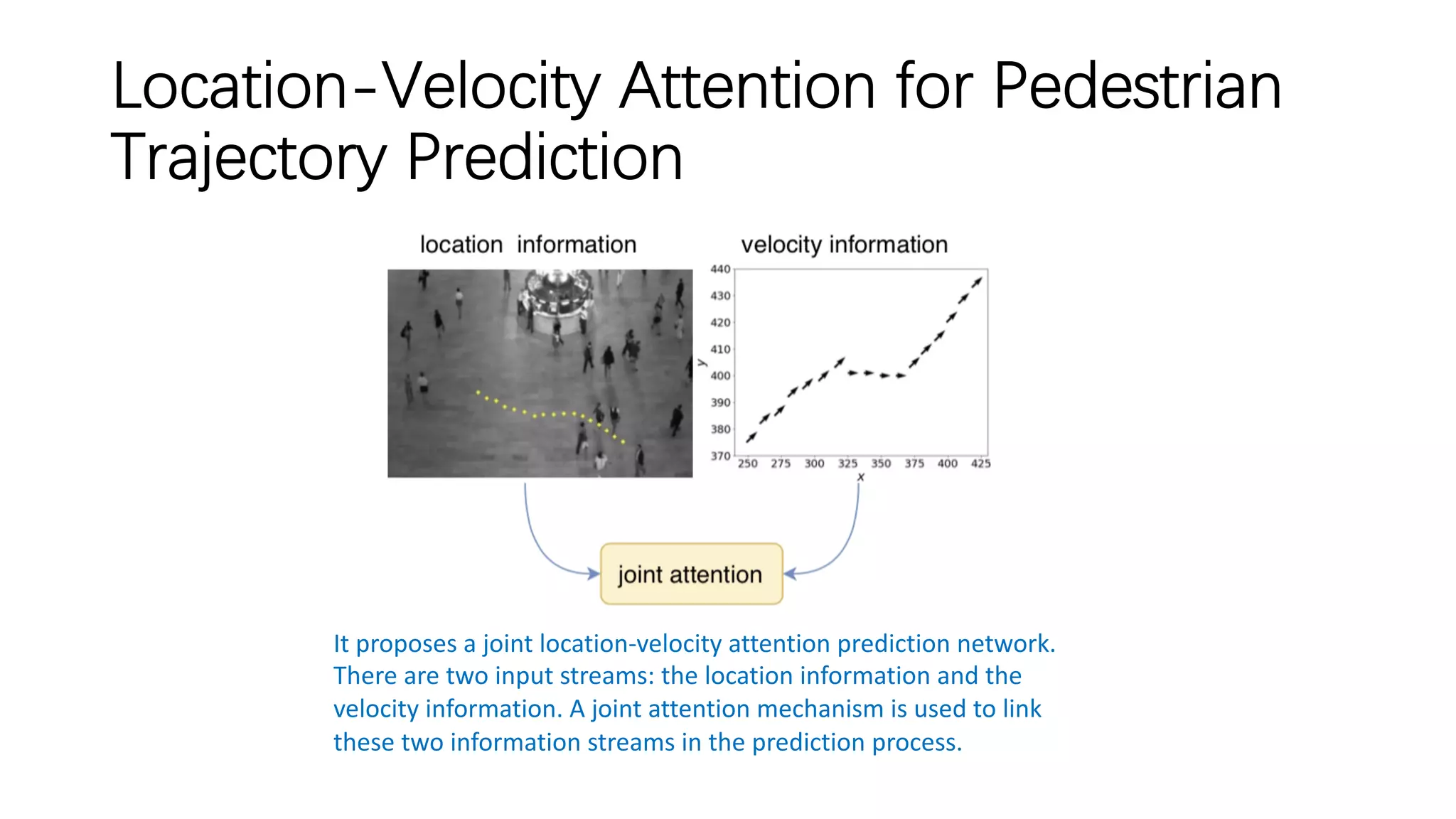

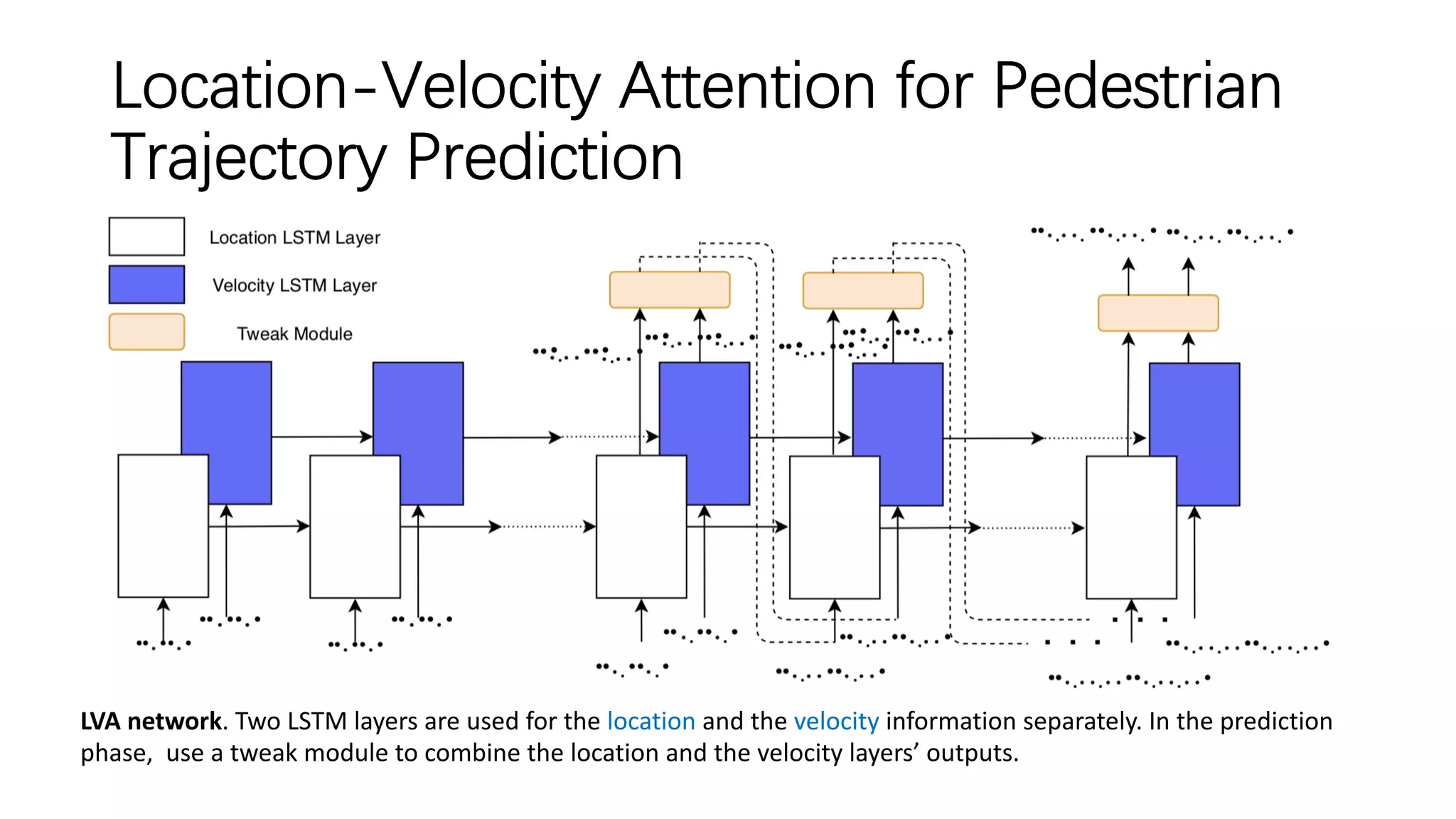

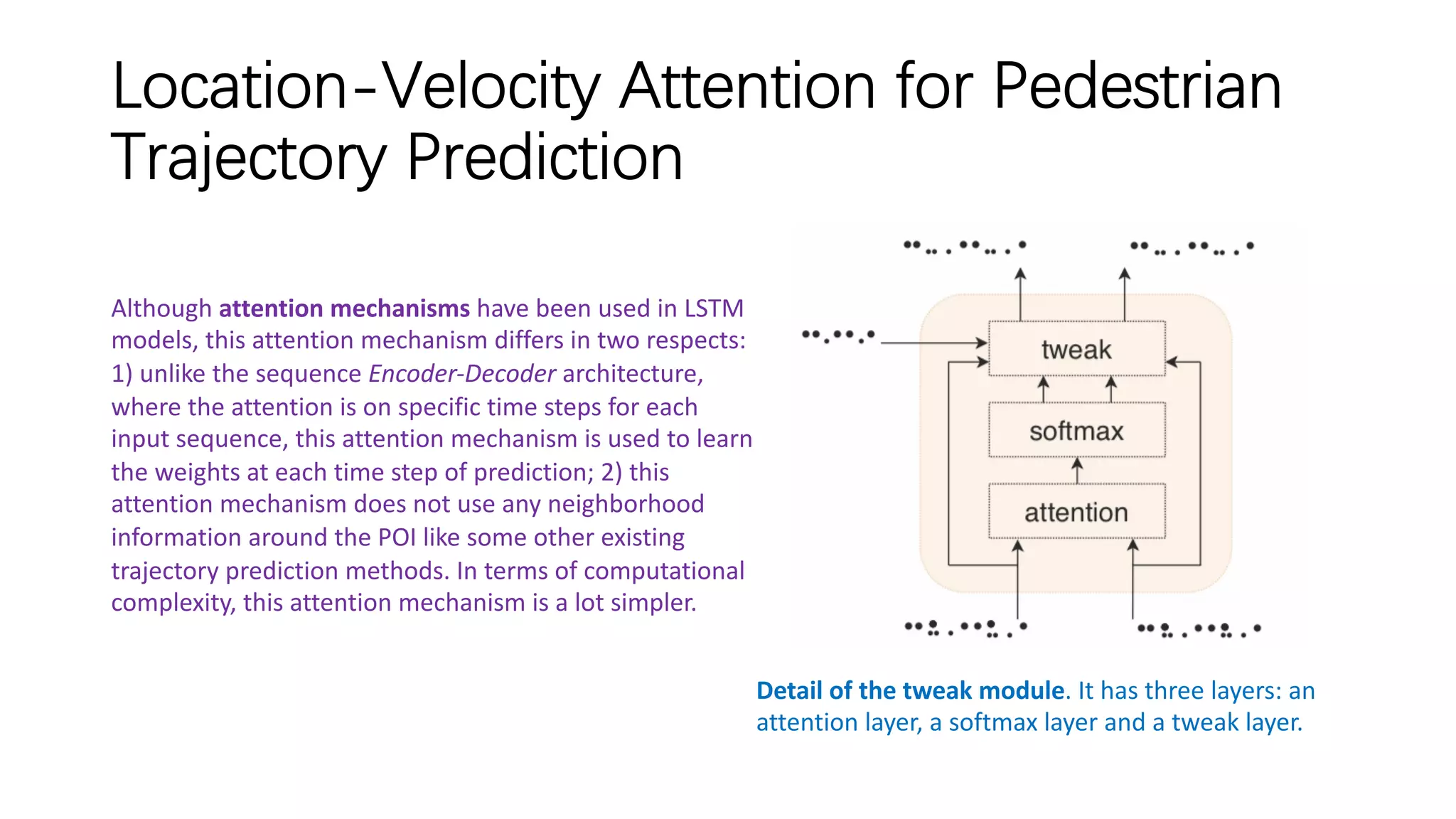




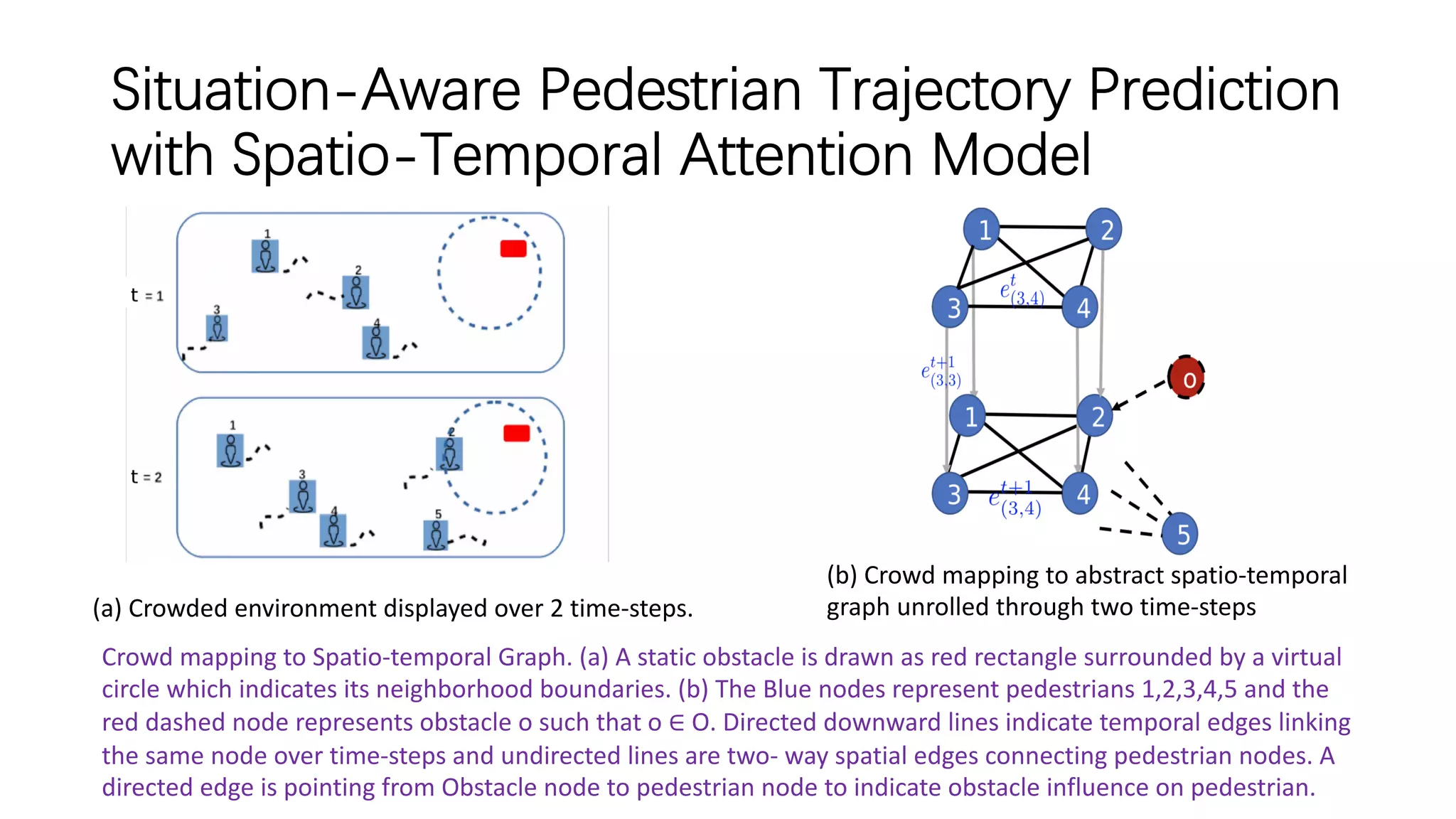

![Situation-Aware Pedestrian Trajectory Prediction
with Spatio-Temporal Attention Model
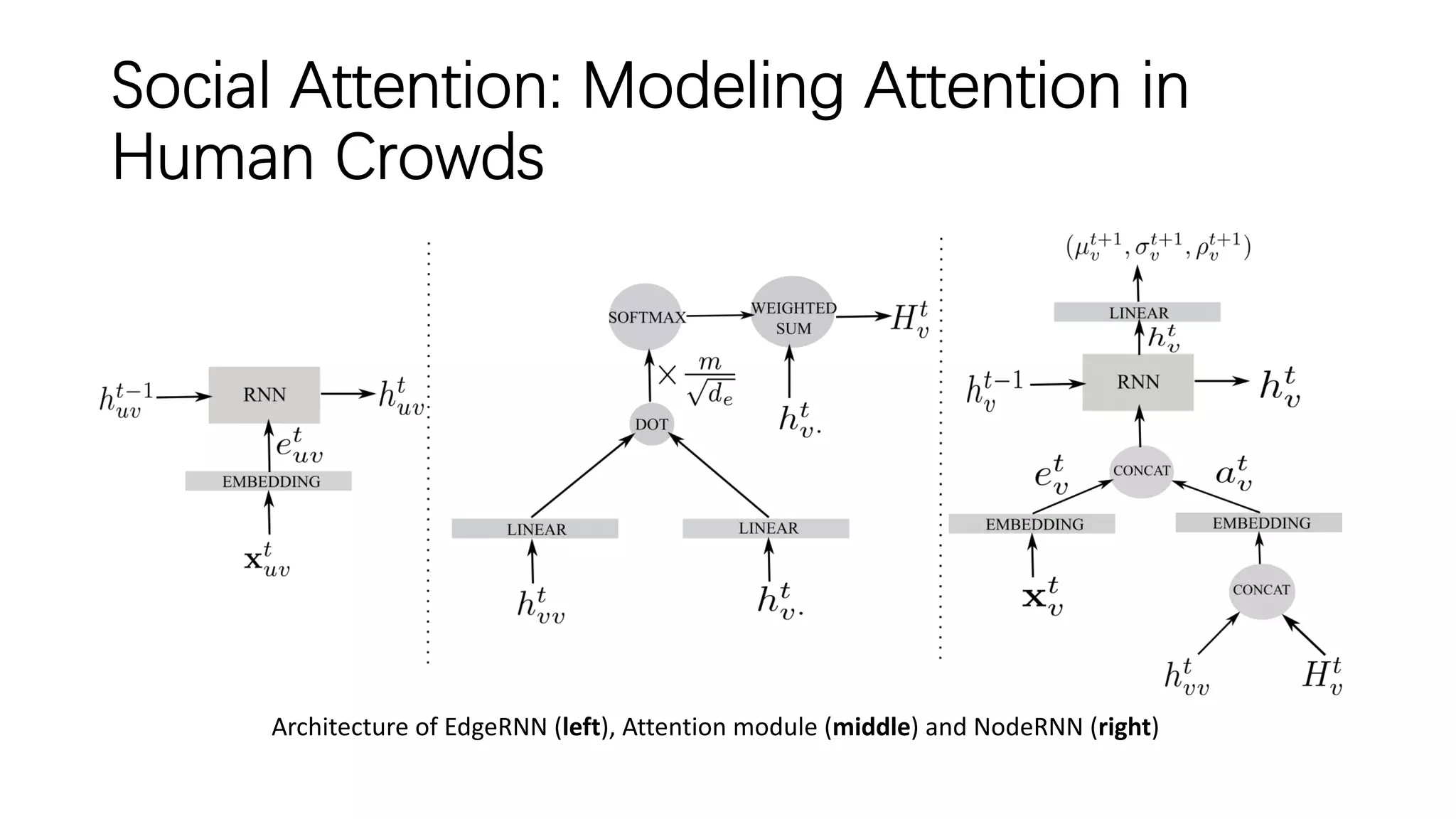
• The Multi-Head attention works by stacking multiple attention layers (heads) in which each
layer makes mappings between words in two sentences.
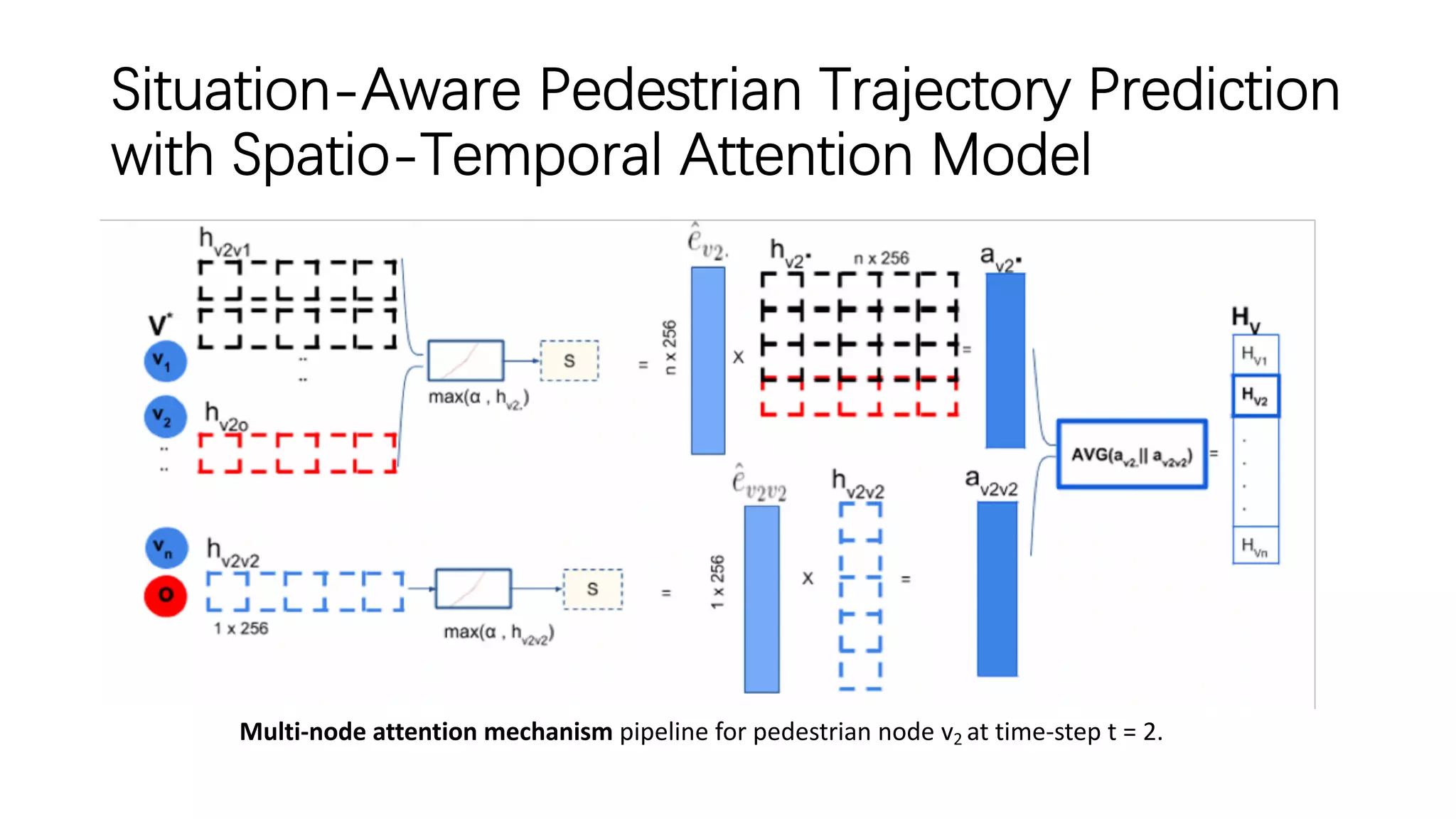
• A simple attention mechanism is used, i.e. Multi-Node attention, which only has a single
layer that jointly pays attention to the features from spatial and temporal domains and store
the attention coefficients into single vector for node v2 trajectory at each time-step.
• Neighboring edgeL-STMs states are transformed before concatenation using the
embedding function, which is a composite of Parametric ReLU and softmax.
• This combined activation ensures that hidden states remain within a small range of [-1,1]
which will be mapped once again at the sampling stage to a range of normalized outputs
range of [0,1].
• The Parametric ReLU, is the generalized ReLU function as it ties the leak parameter α as a
network learnable parameter.
• Employing such activation function with an adaptive leak parameters, allows a slightly
different span of the negative hidden states along training batches.](https://image.slidesharecdn.com/pedestrianbehaviormodeling2-191002052339/75/Pedestrian-behavior-intention-modeling-for-autonomous-driving-II-56-2048.jpg)




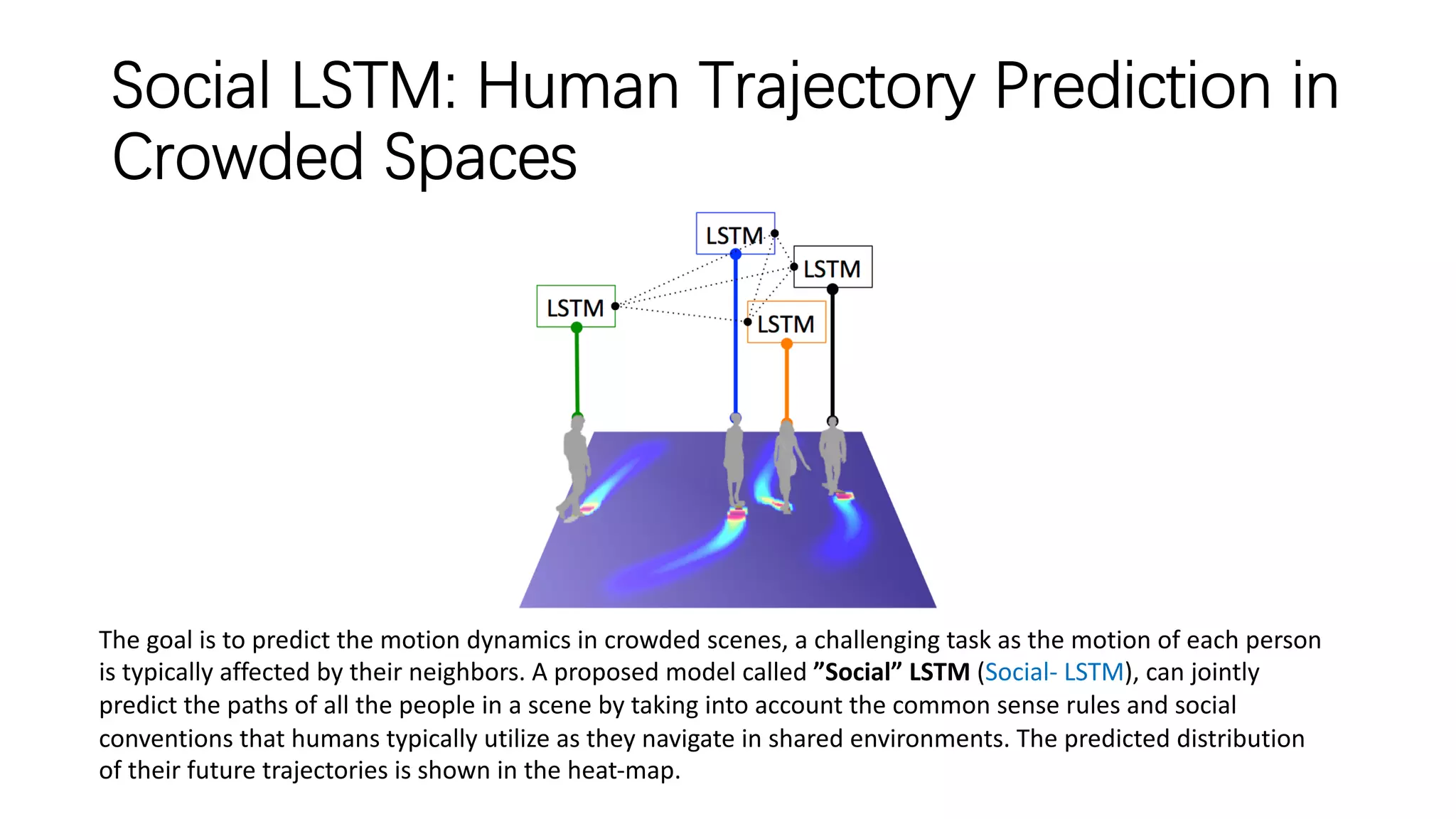
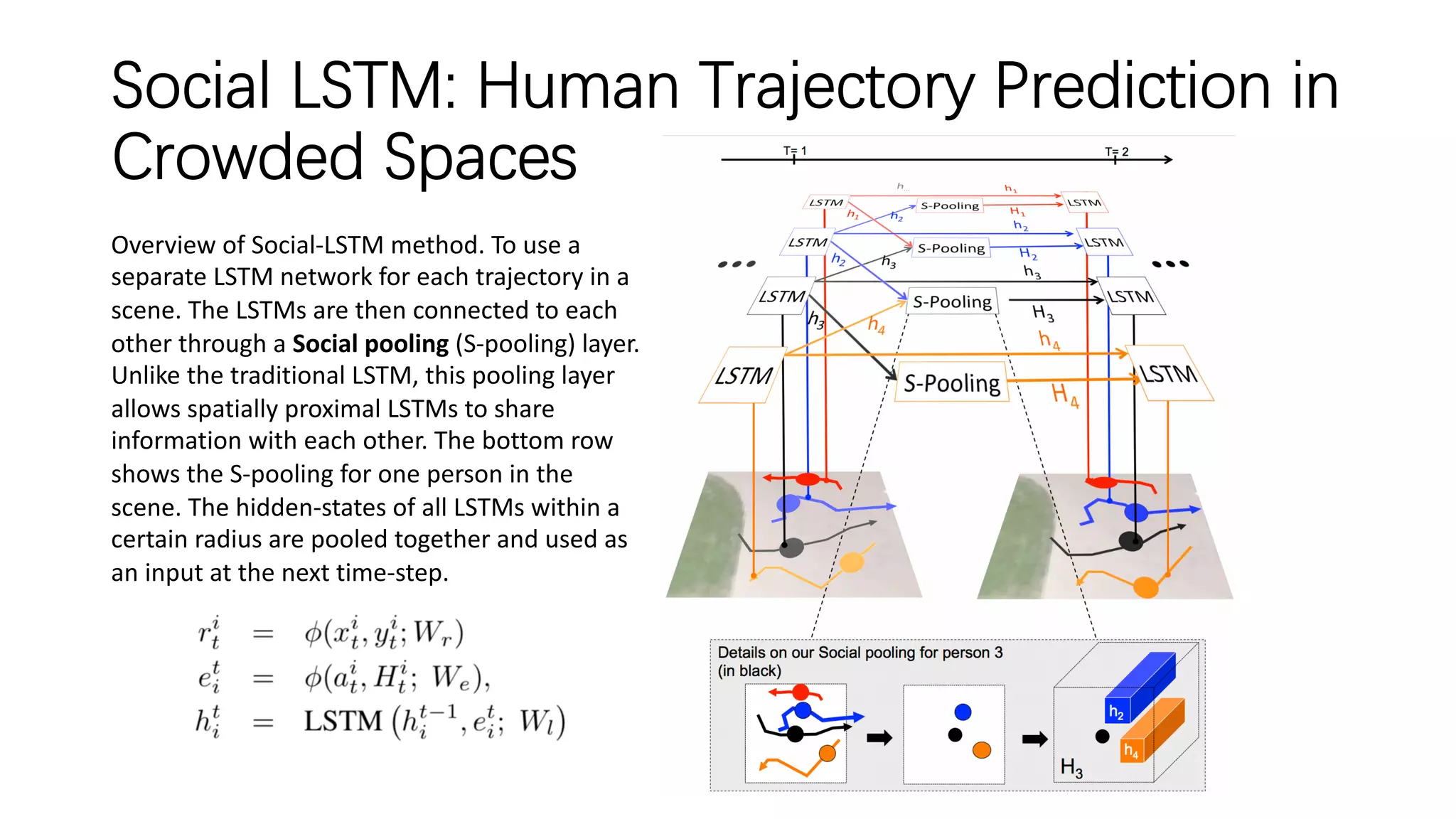
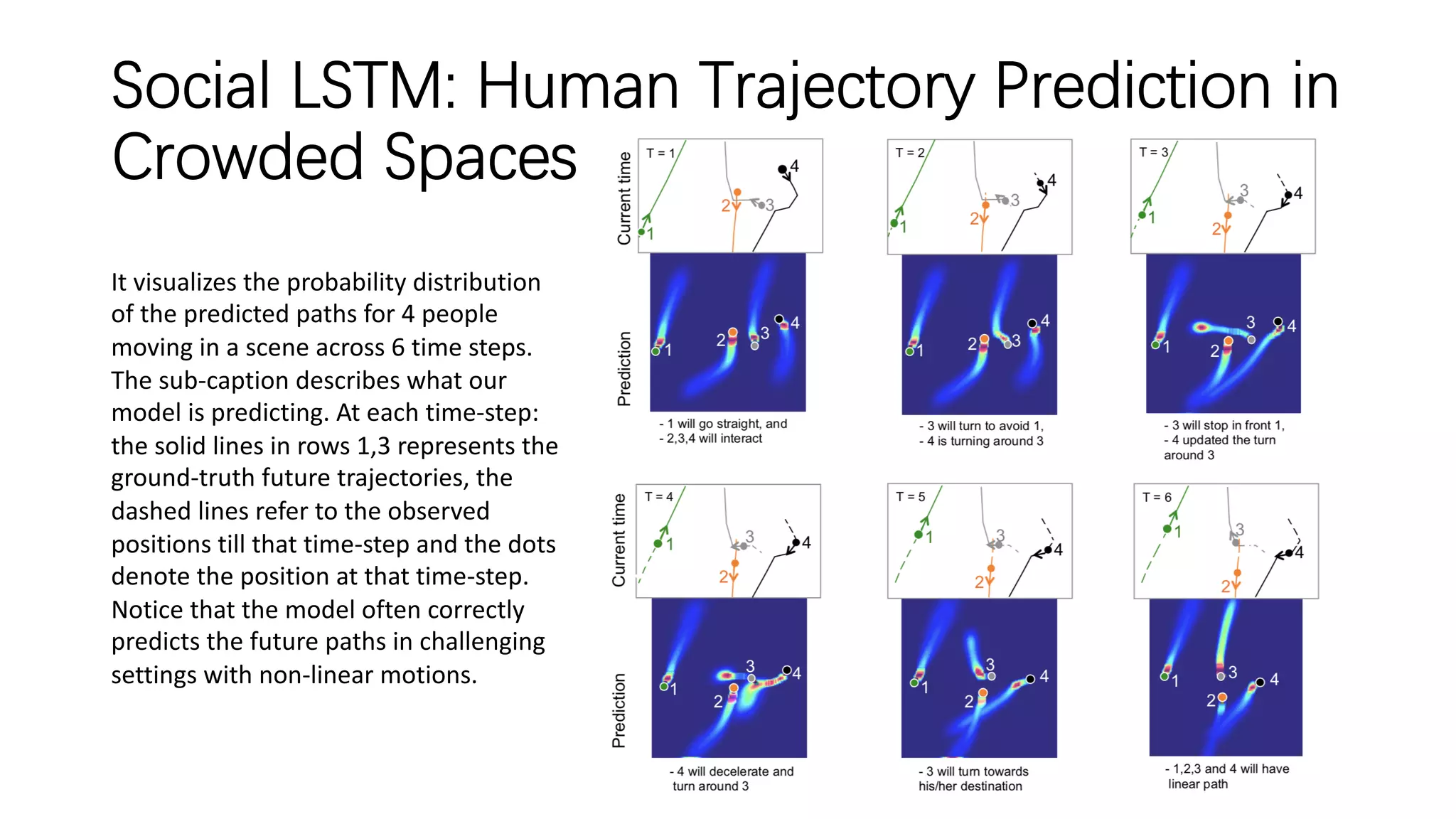
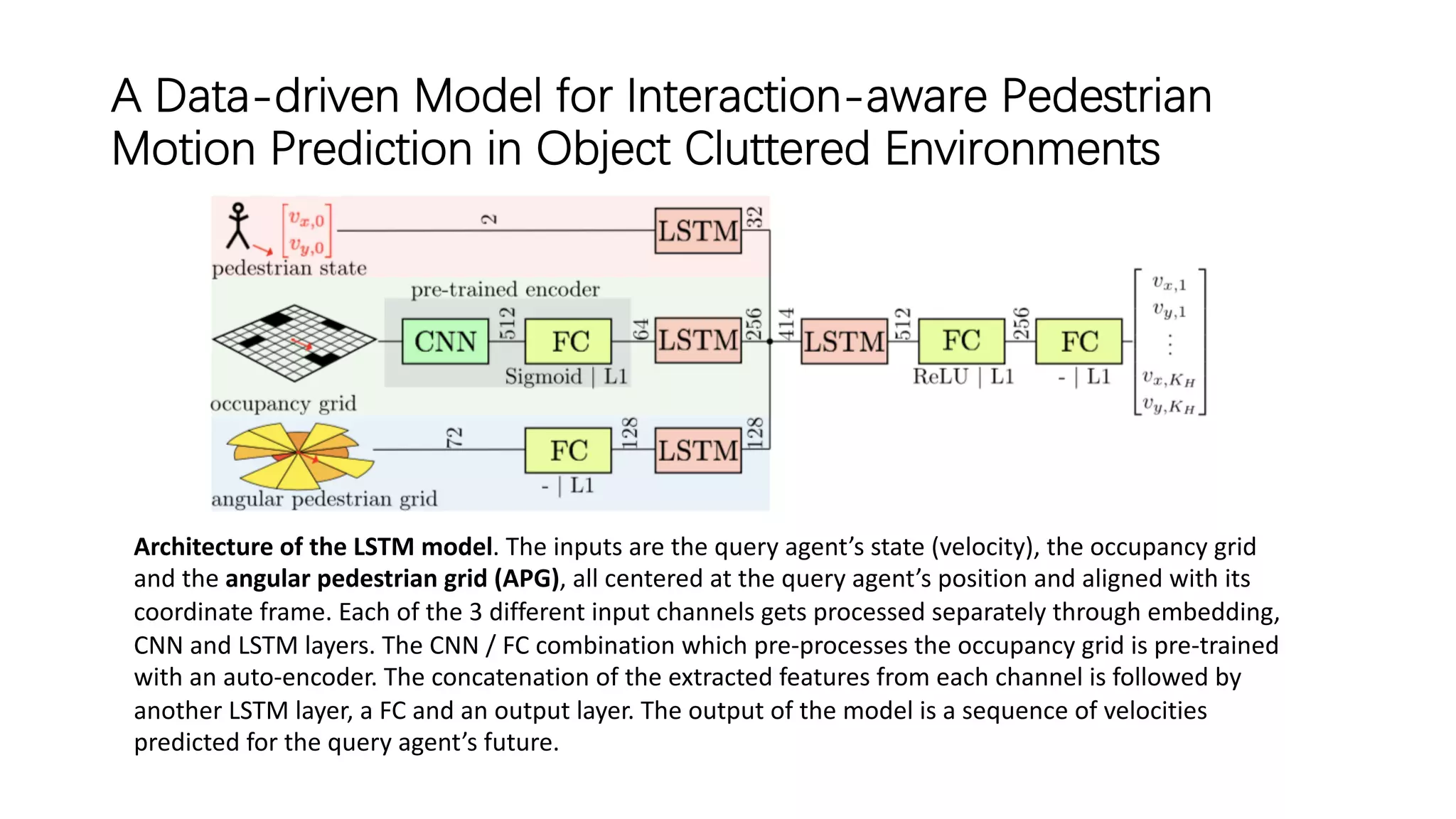
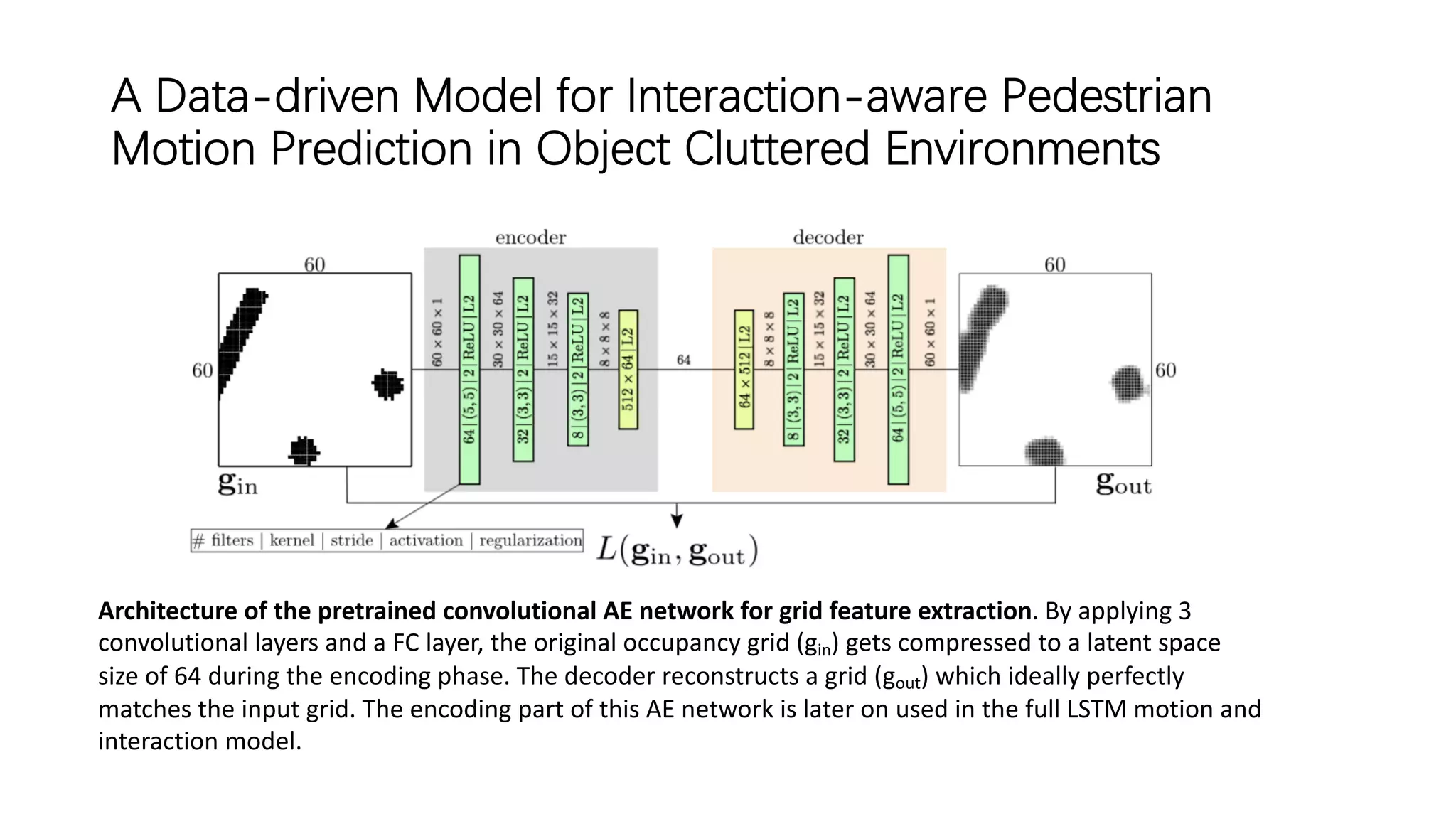
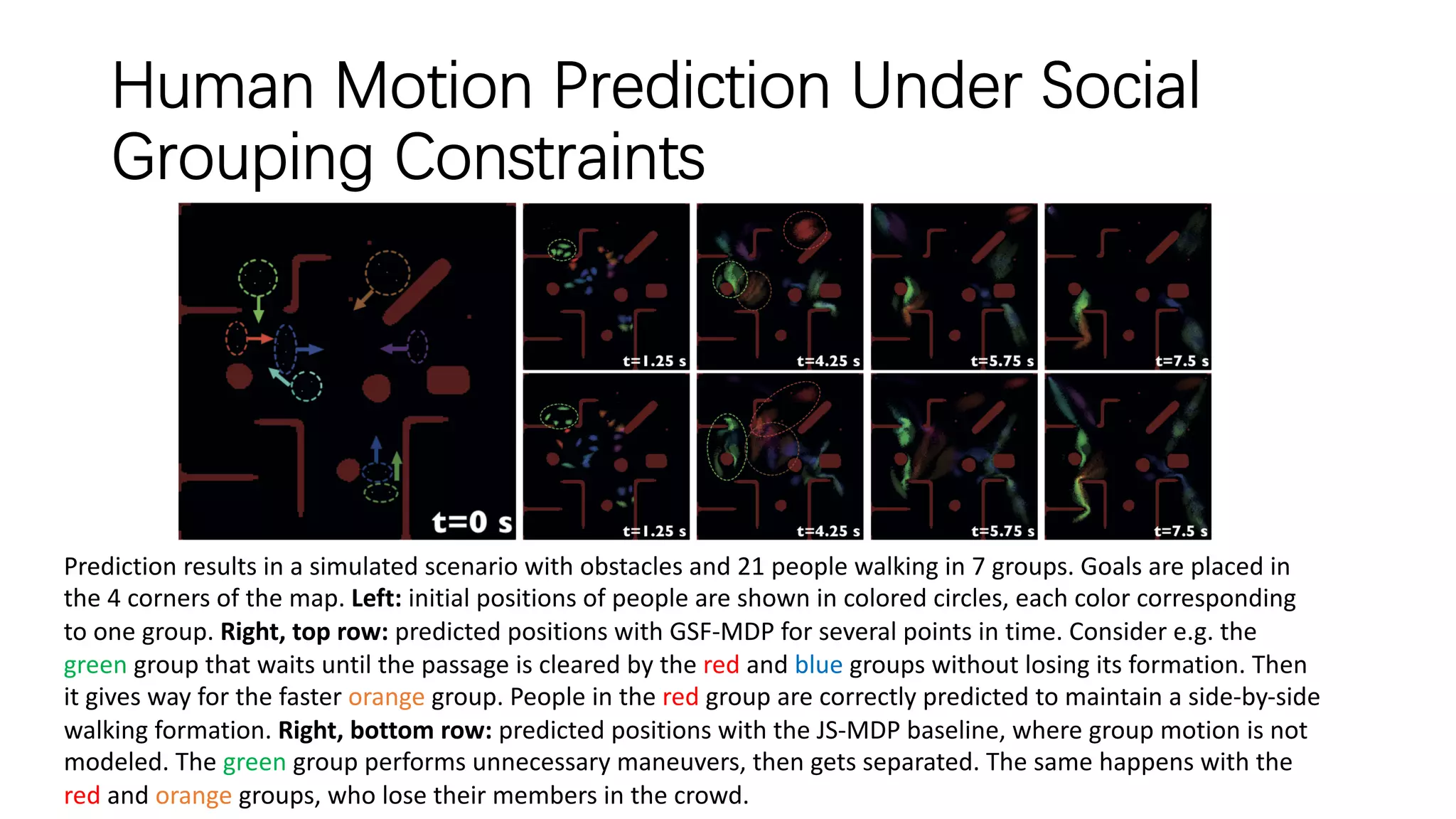
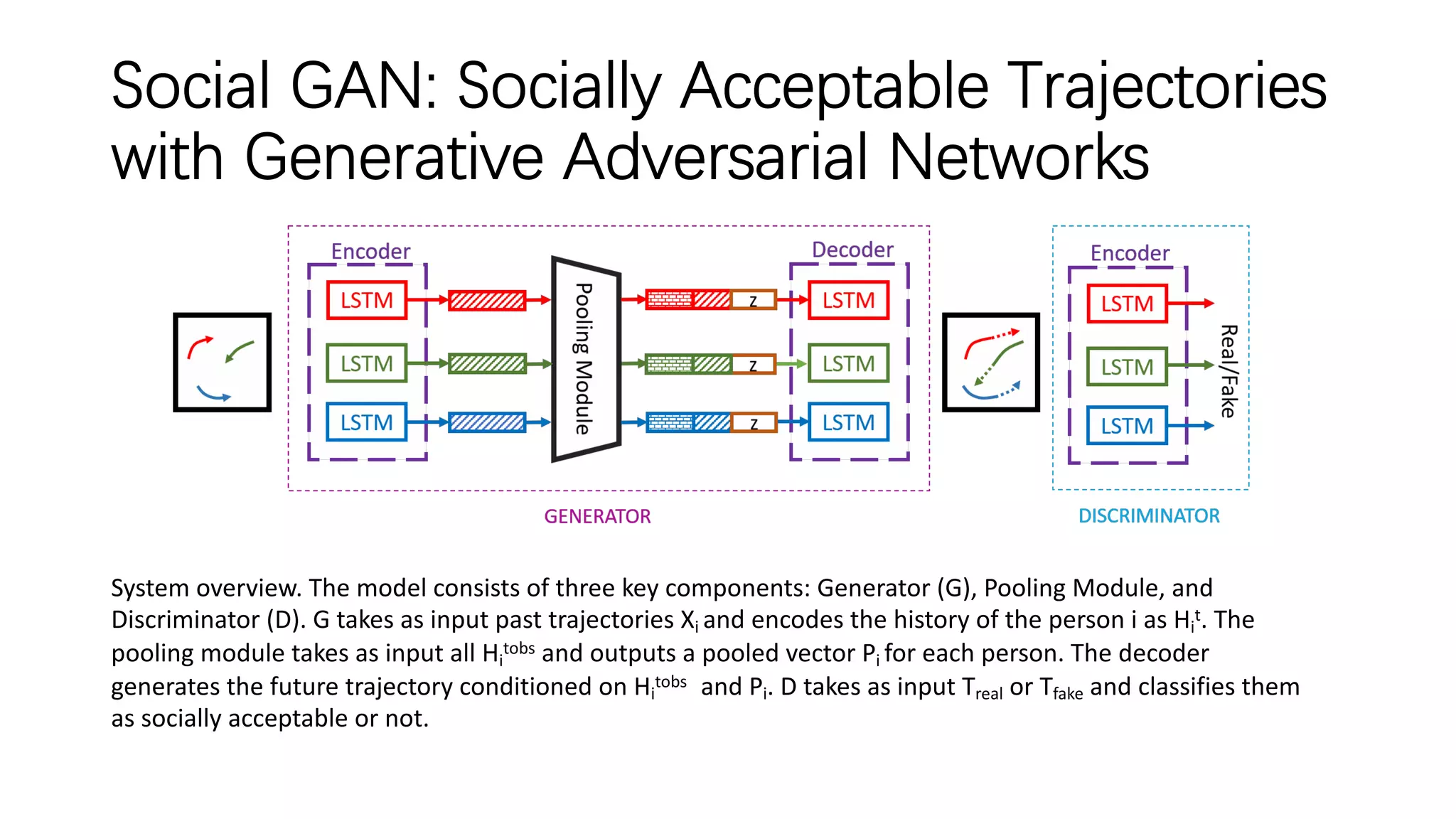
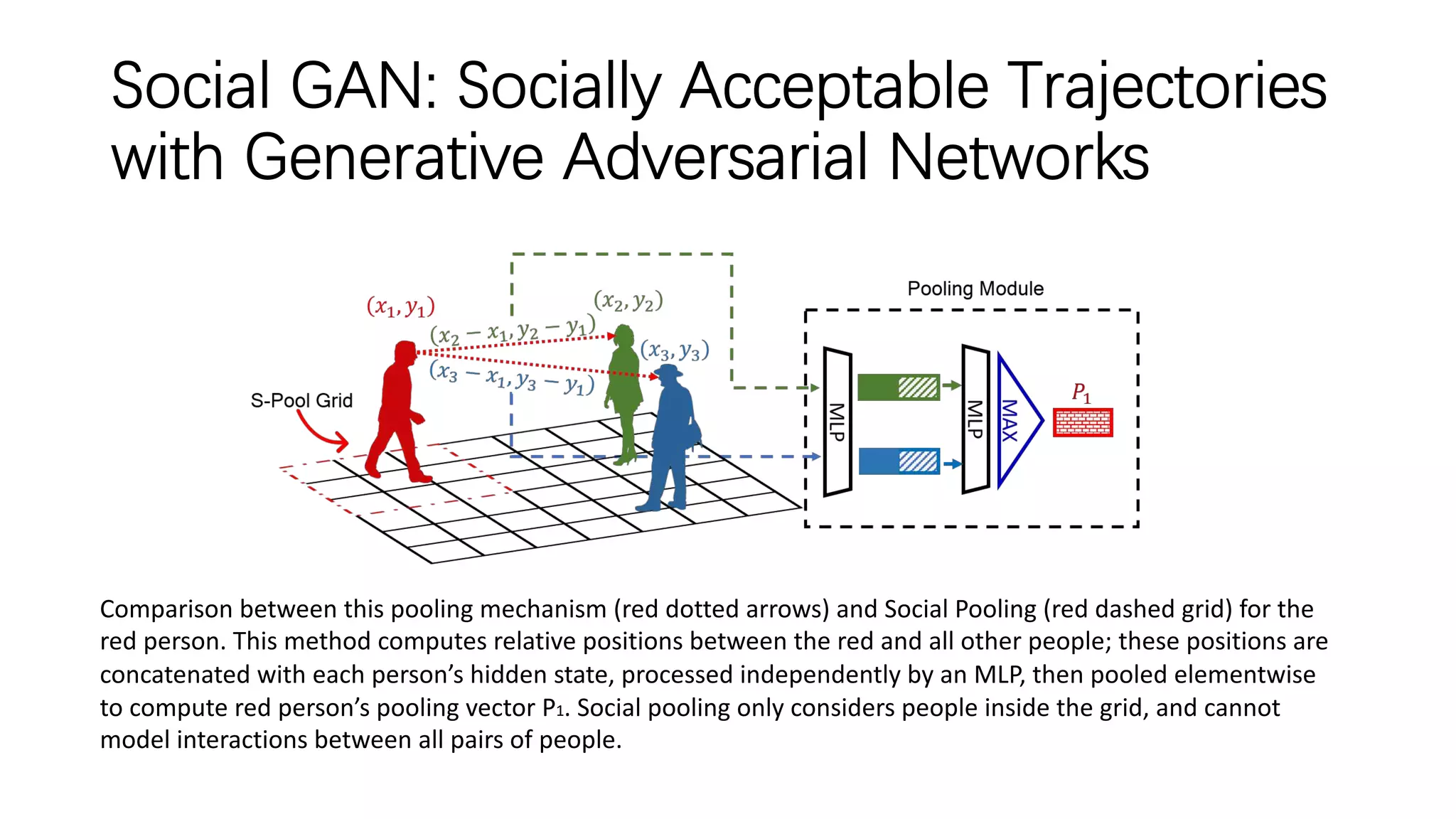
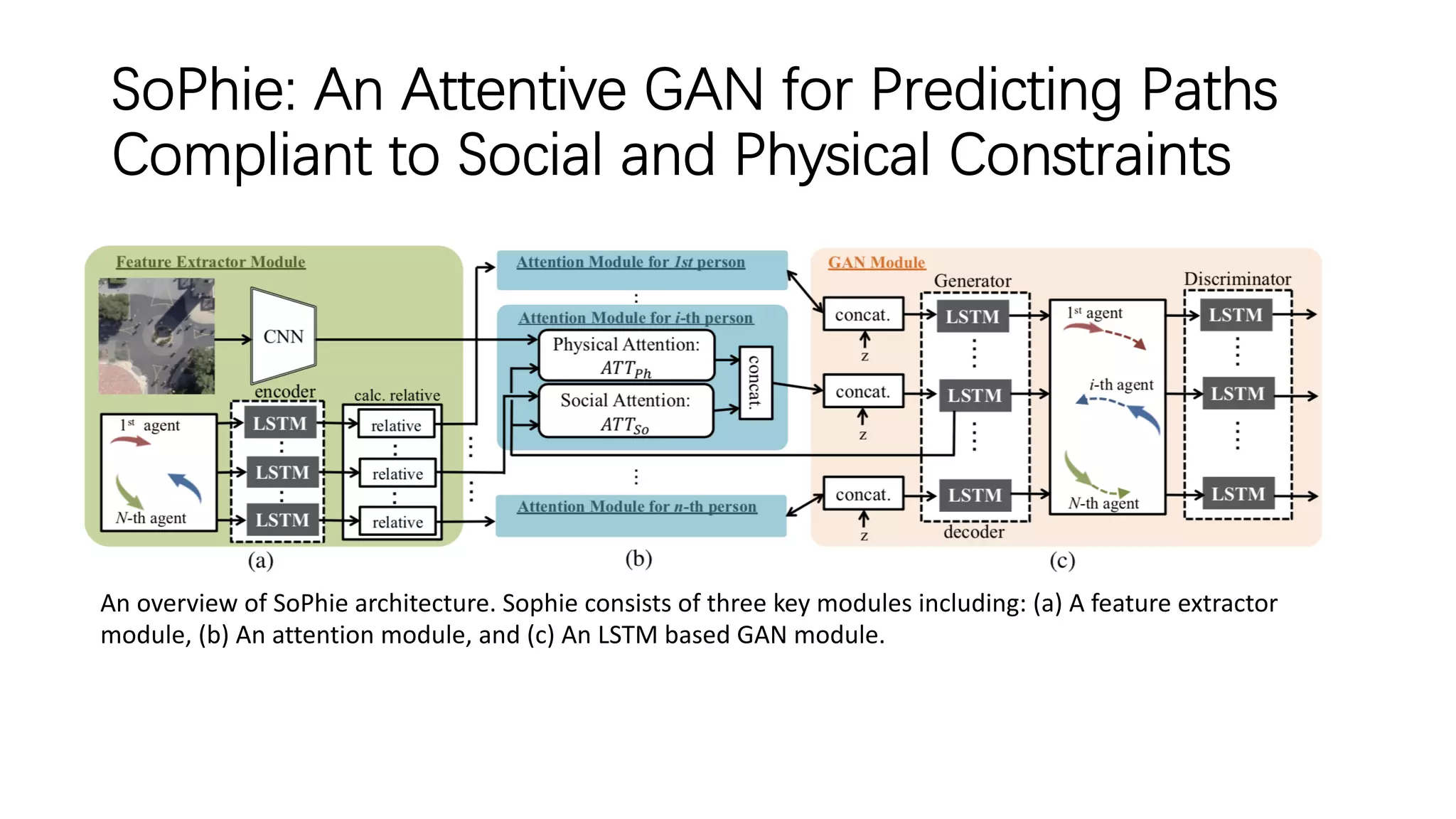
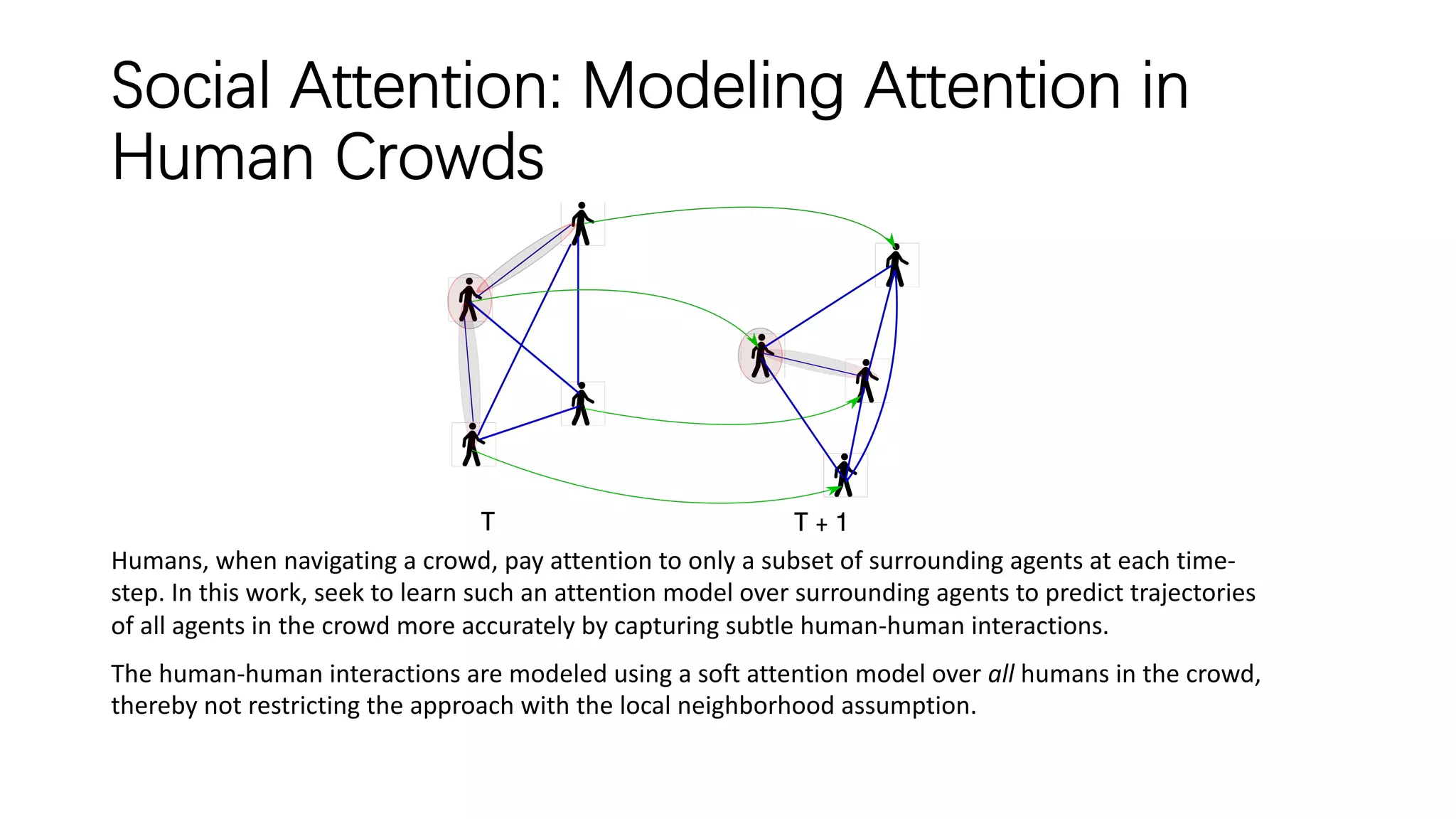
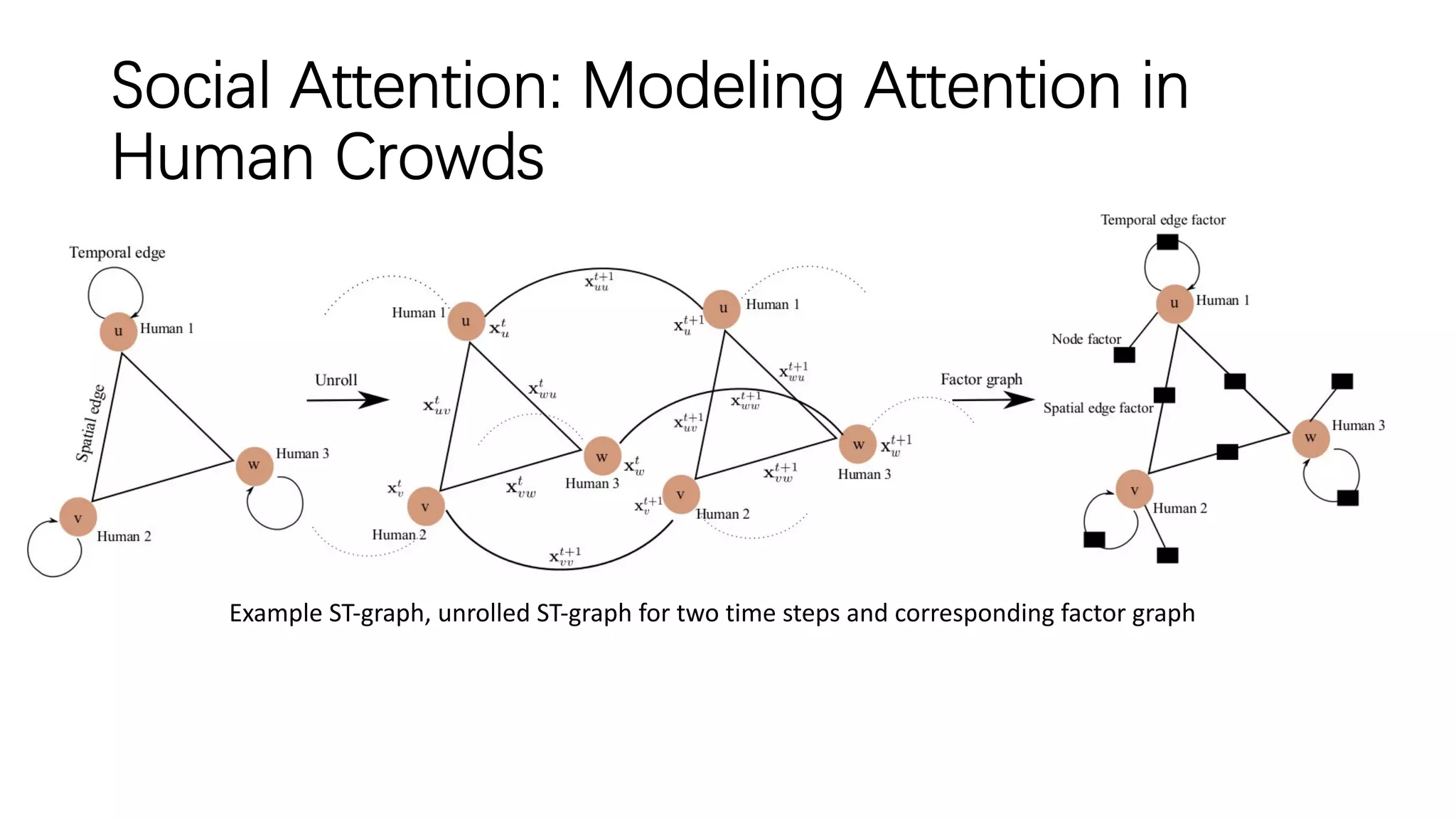
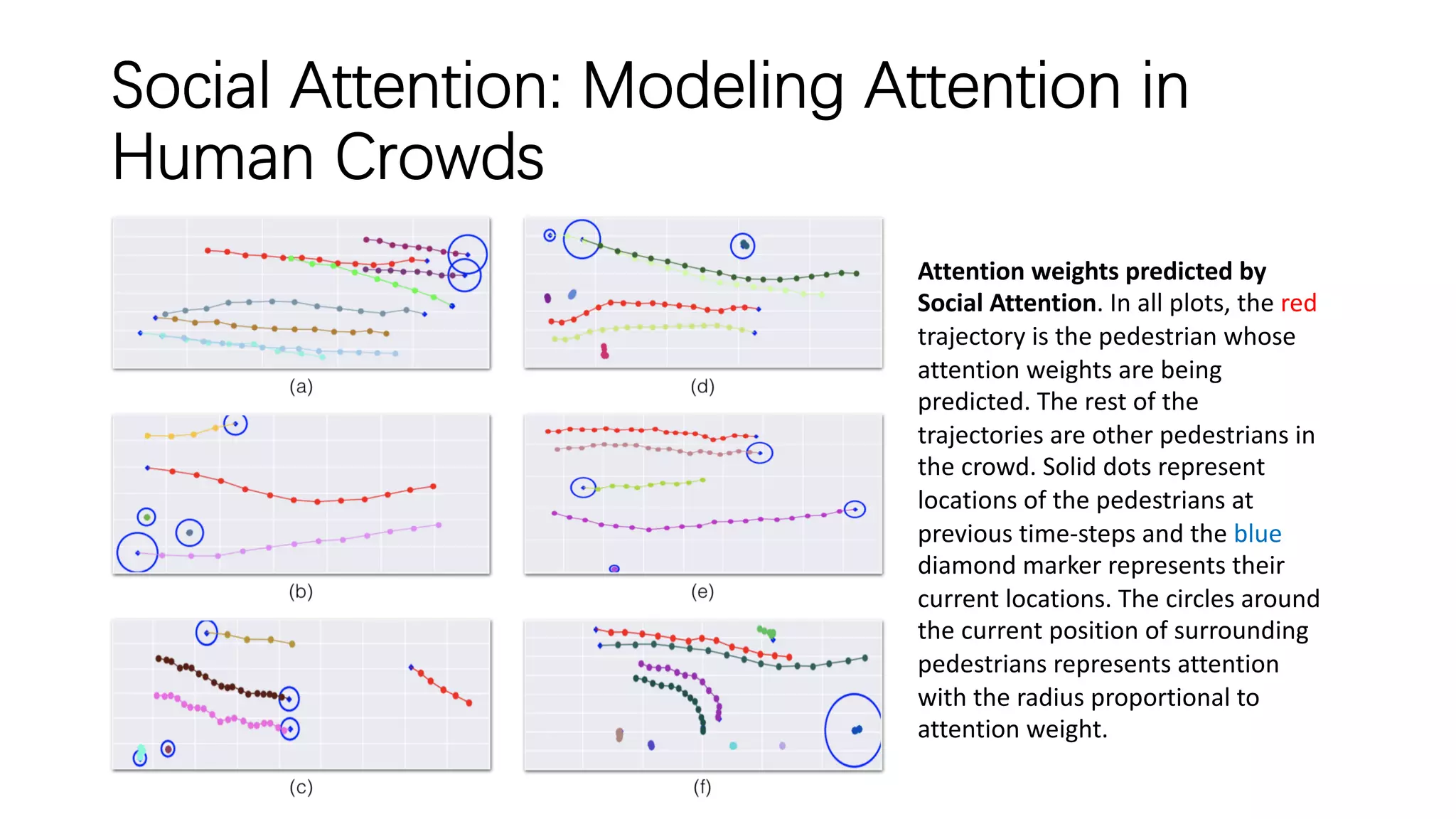
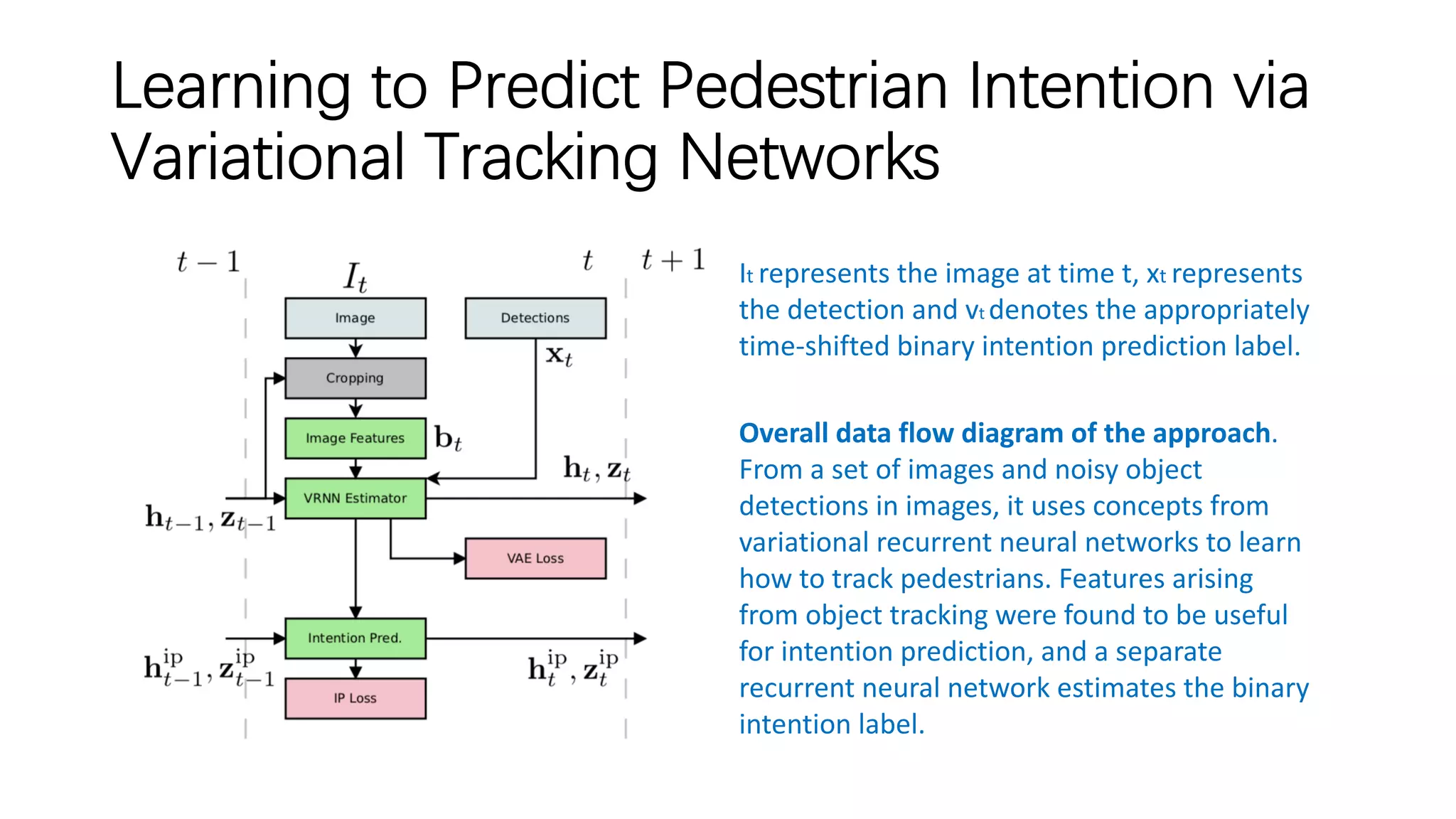
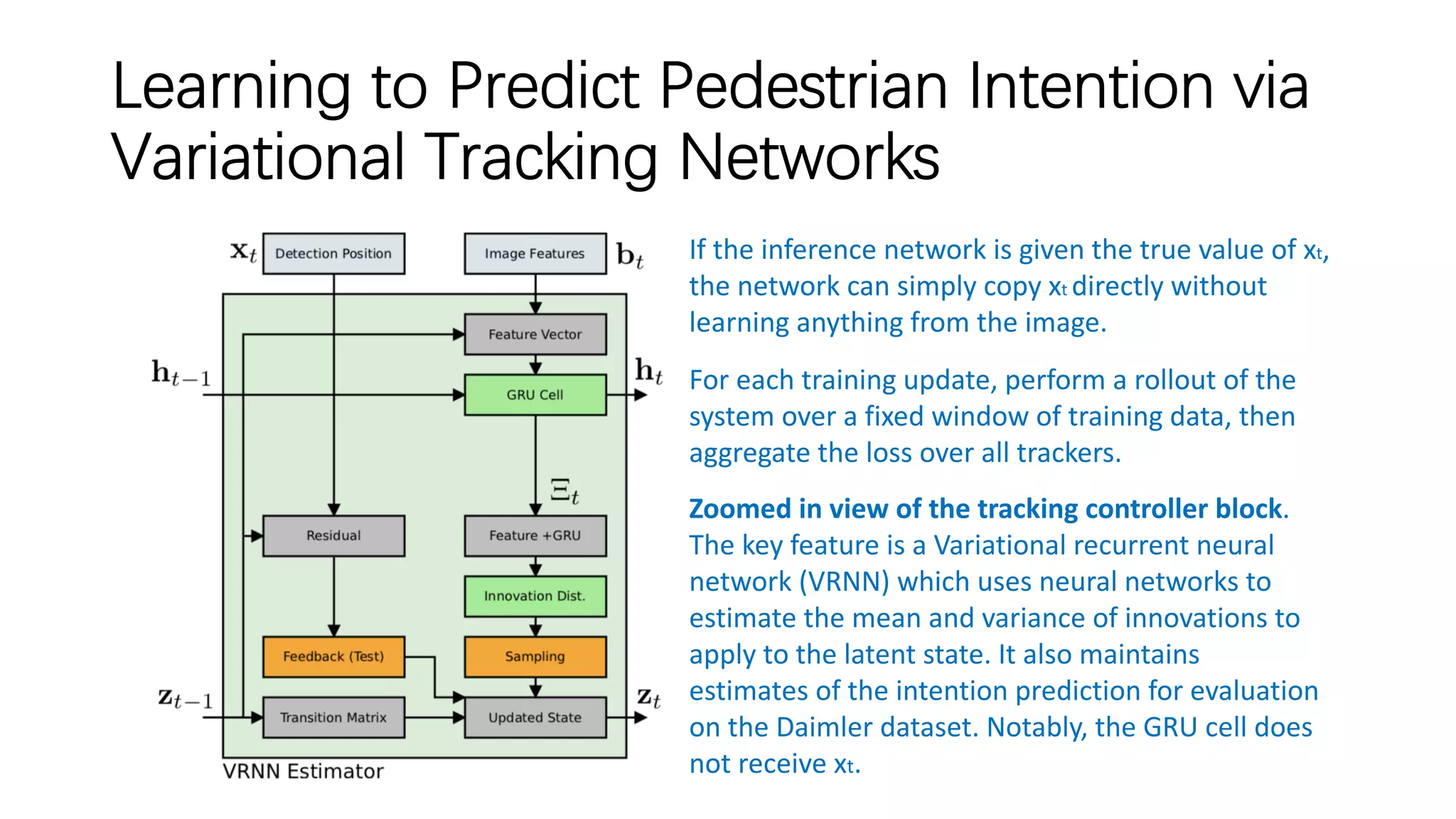
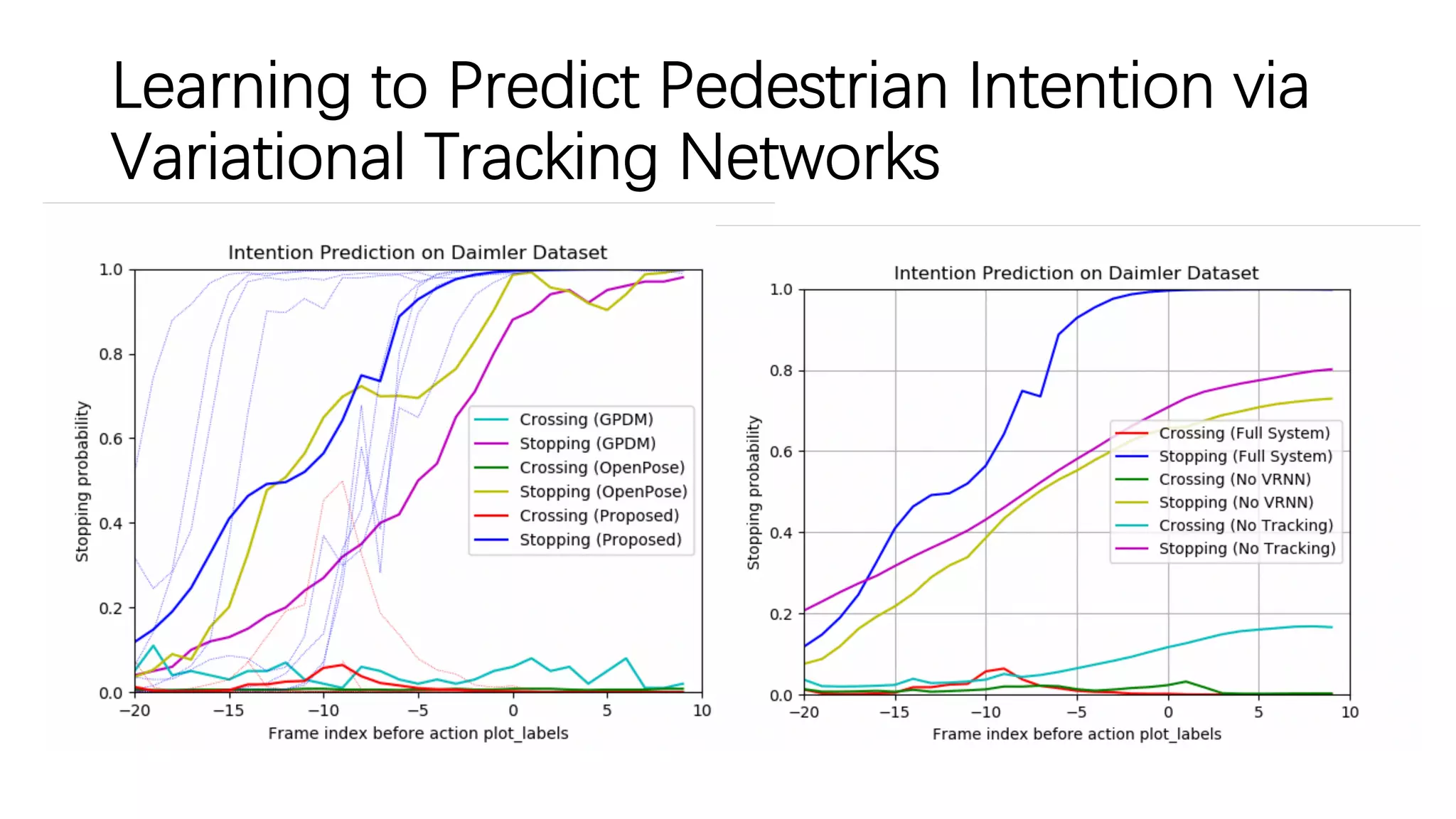
The document discusses several papers related to modeling pedestrian behavior and predicting pedestrian trajectories for autonomous vehicles. It begins with an outline listing the paper titles and authors. It then provides more detailed summaries of three papers: 1) "Social LSTM: Human Trajectory Prediction in Crowded Spaces" which uses an LSTM model and social pooling layer to jointly predict paths of all people in a scene by taking into account social conventions. 2) "A Data-driven Model for Interaction-aware Pedestrian Motion Prediction in Object Cluttered Environments" which uses an LSTM model incorporating static obstacles and surrounding pedestrians to forecast trajectories. 3) "Social GAN: Socially Acceptable Trajectories with Generative













![[2024107_LabSeminar_Huy]MFTraj: Map-Free, Behavior-Driven Trajectory Predicti...](https://cdn.slidesharecdn.com/ss_thumbnails/2024107labseminarhuymftraj-241009064509-715fd922-thumbnail.jpg?width=640&height=640&fit=bounds)





















































