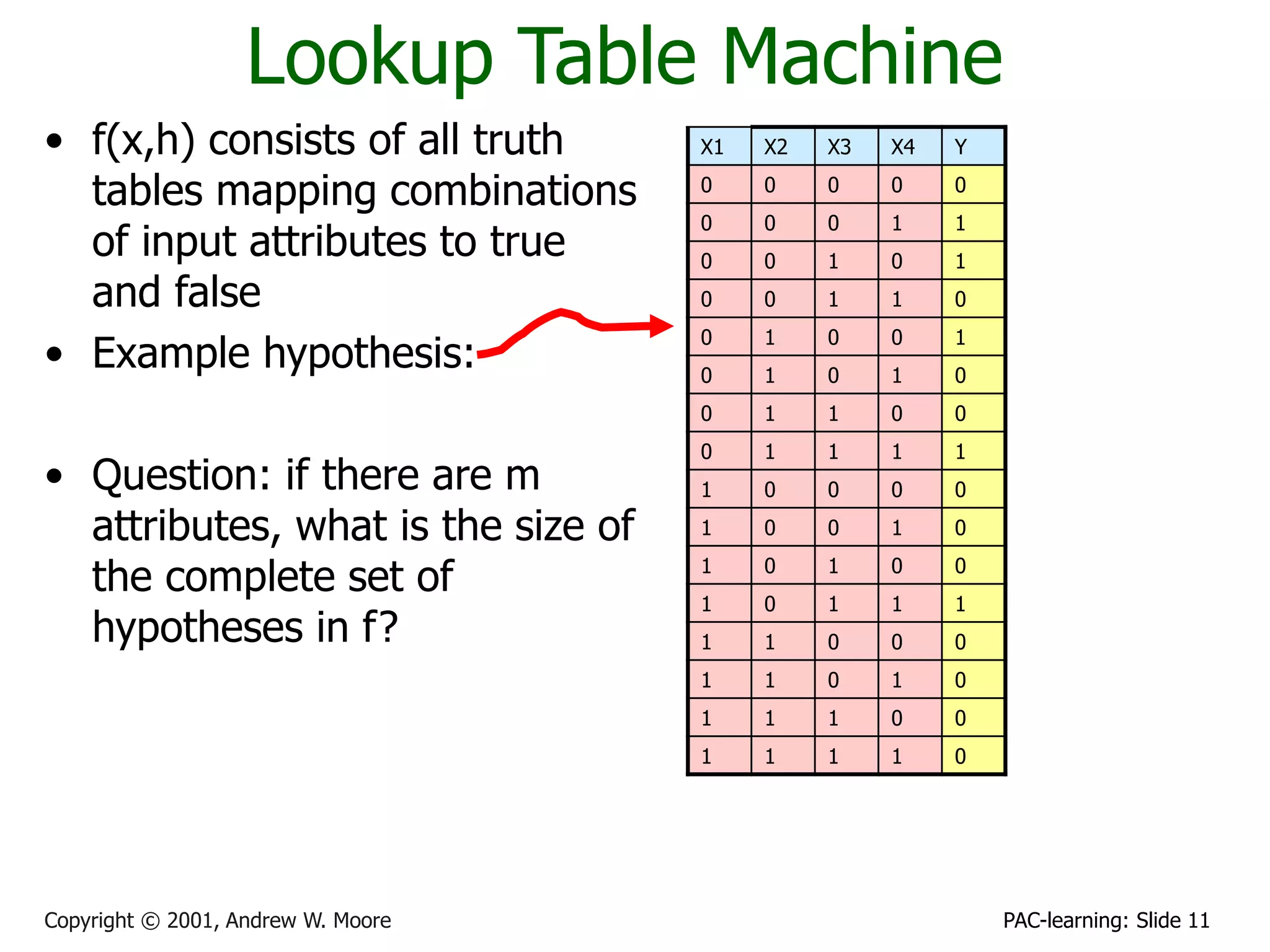
This document contains slides from a lecture on PAC (Probably Approximately Correct) learning given by Andrew W. Moore. The slides provide examples of different types of learning machines (classifiers) with different hypothesis spaces and calculate the number of training examples needed to PAC learn each machine to guarantee a low probability of error. For instance, it is shown that an AND-literals machine with m attributes has 3m possible hypotheses and the number of training examples needed to PAC learn is proportional to log(3m).






























































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)









