Download as PDF, PPTX


























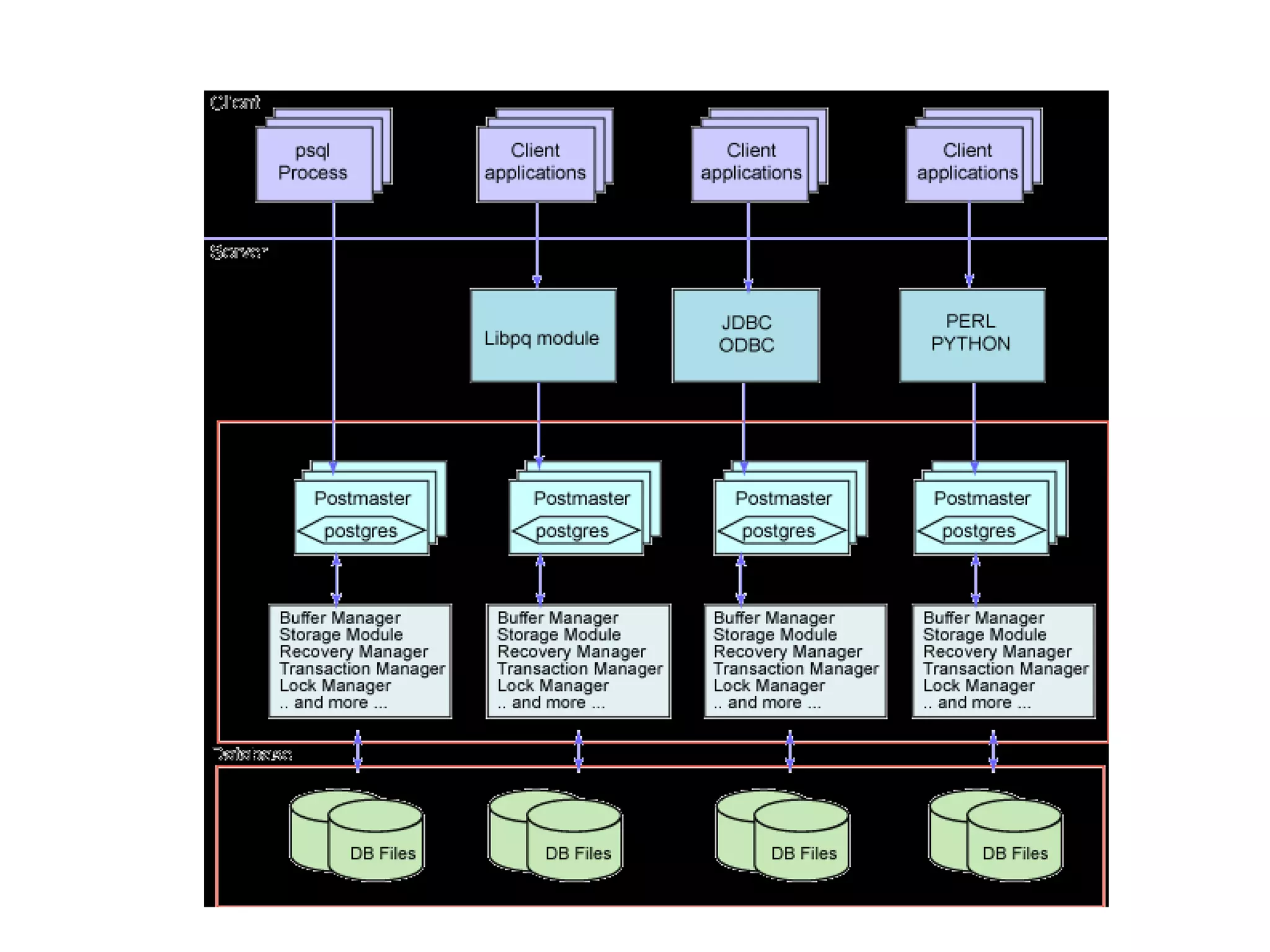



This document discusses PostgreSQL and Solaris as a low-cost platform for medium to large scale critical scenarios. It provides an overview of PostgreSQL, highlighting features like MVCC, PITR, and ACID compliance. It describes how Solaris and PostgreSQL integrate well, with benefits like DTrace support, scalability on multicore/multiprocessor systems, and Solaris Cluster support. Examples are given for installing PostgreSQL on Solaris using different methods, configuring zones for isolation, using ZFS for storage, and monitoring performance with DTrace scripts.

































































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)







