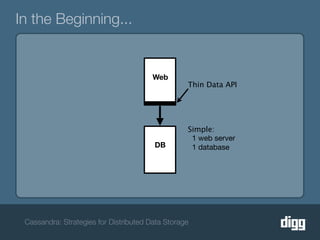
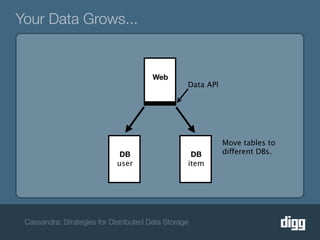
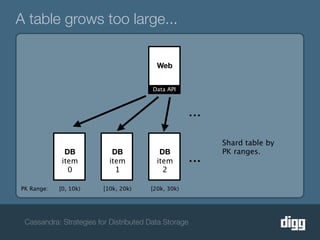
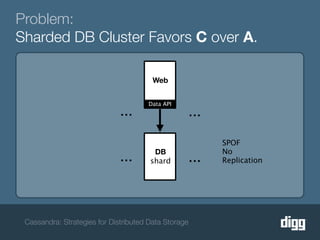
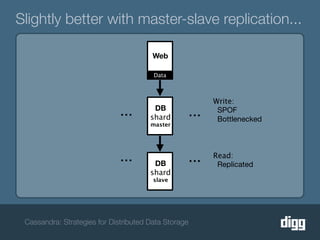
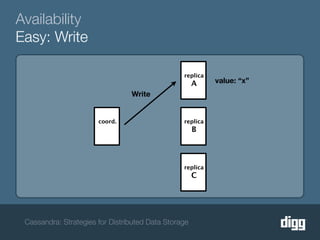
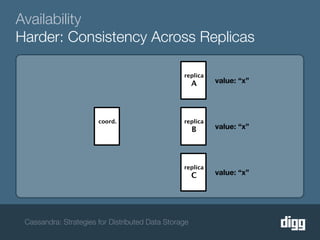
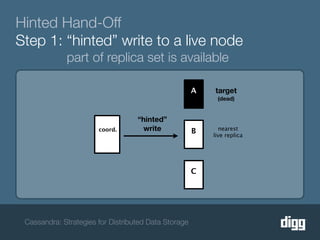
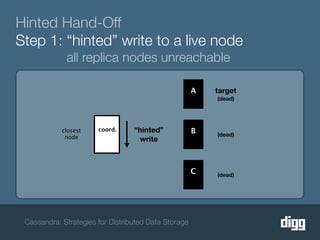
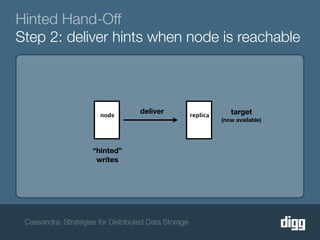
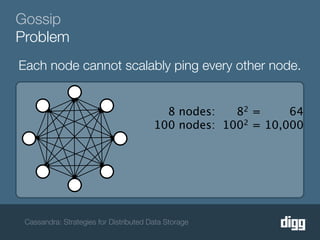
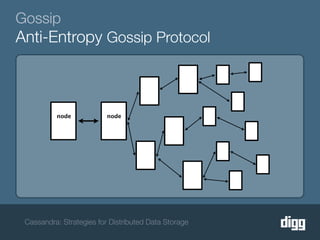
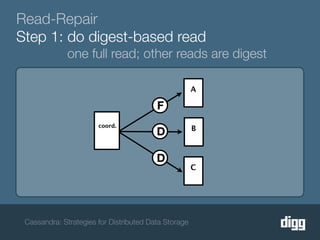
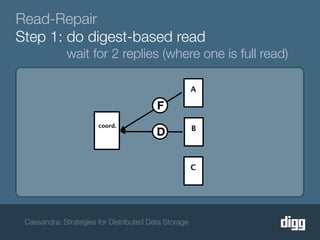
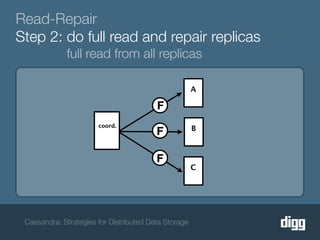
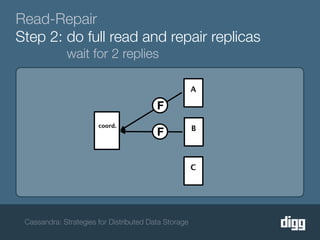
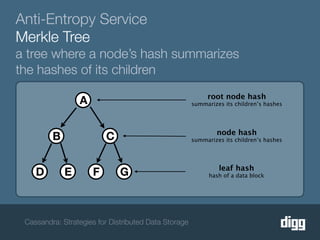
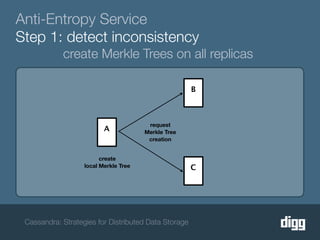
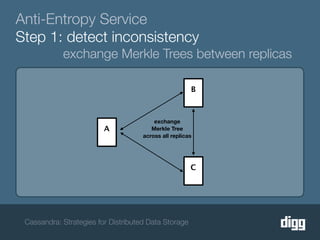
The document discusses strategies for achieving eventual consistency in distributed databases like Cassandra. It covers using hinted hand-offs to handle writes to unavailable nodes, gossip protocols to detect node availability, read repair to fix inconsistencies found during reads, and an anti-entropy service to repair unread data using Merkle trees. The strategies aim to maximize availability while achieving eventual consistency across distributed replicas in the face of network failures.