Downloaded 745 times





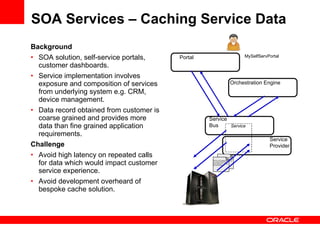
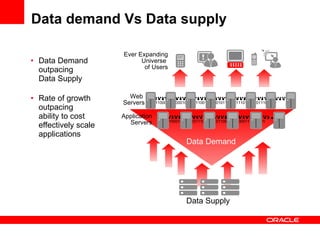
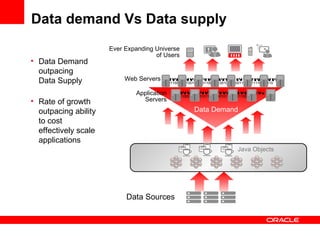

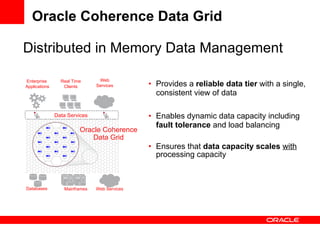
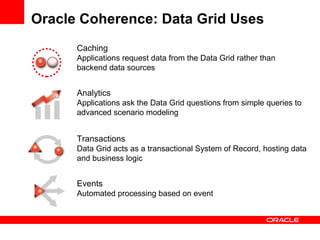


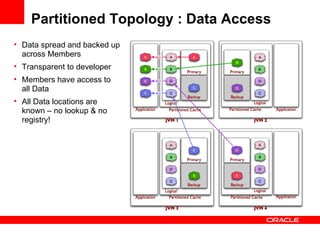



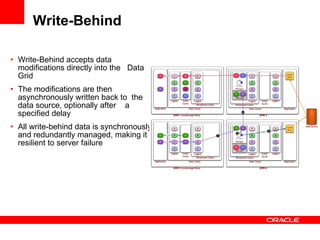

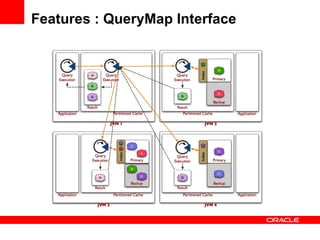







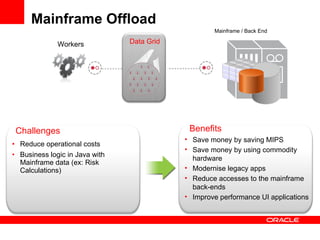



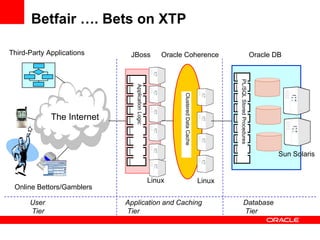



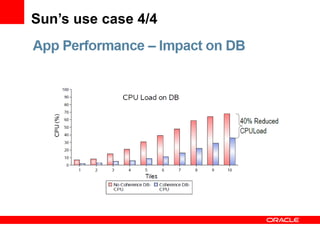







The document discusses Oracle Coherence, an in-memory data grid solution designed to enhance the scalability, reliability, and performance of applications by caching data and managing data access efficiently. It highlights the need for such solutions in contexts like e-commerce and enterprise applications, showcasing use cases and benefits, such as improved customer experience and reduced operational costs. The overview covers various features, benefits, and the architecture of Oracle Coherence, emphasizing its ability to provide continuous data availability and support for large-scale data processing.









































![[OracleCode SF] In memory analytics with apache spark and hazelcast](https://cdn.slidesharecdn.com/ss_thumbnails/in-memoryanalyticswithapachesparkandhazelcast-oraclecode-03-01-2017-170302180618-thumbnail.jpg?width=640&height=640&fit=bounds)





![[TDC 2013] Integre um grid de dados em memória na sua Arquitetura](https://cdn.slidesharecdn.com/ss_thumbnails/tdc2013integrandocoherencearqttv1-130526184010-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























