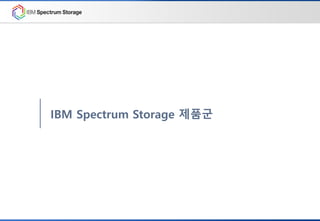
IBM Software DefinedStorage 전제품 포트폴리오
Scale-Out
스토리지
스토리지
서비스
데이터
백업
데이터
아카이빙
VM
가용성
증대
스토리지
관리
스냅샷 등
데이터
복제본 관리
모니터링
관리 툴
블록
스토리지
가상화
초고성능
File 공유
Scale-out
Block
무한확장
Object
어플라이언스 및 에서 제공되는 IBM 소프트웨어 정의 스토리지 제품군
메타
데이터
분석
4.
IBM 비정형 DataContainer 솔루션 비교
구분 IBM Spectrum Scale IBM Cloud Object Storage
워크
로드
HPC (슈퍼컴퓨팅, AI)
Big Data Analytics
클라우드,
Native Object Application
초 고성능 File Sharing 비정형 데이터 통합 저장소
초 고성능 File Processing 아카이브, 소산, 배포
특장점
✓ 업계 1위의 High Performance
✓ 수백PB 이상의 대용량 파일시스템
✓ 1조개 이상의 파일
✓ 무한 확장
✓ 신뢰성 99.9999999999999%
✓ Multi-site 분산 저장
오브젝트 스토리지에 대한오해
S3 프로토콜을 지원하면 Object 스토리지 이다.1
오브젝트 스토리지는 아카이빙 / 백업용이다.2
오브젝트 스토리지는 신뢰성이 떨어진다.3
✓ 저장 아키텍처가 정통 Object Storage 이어야 Object Storage의
다양한 특성을 활용할 수 있다.
✓ S3를 지원하는 NAS는 Object Storage가 아니다.
✓ Object Storage를 아카이빙/백업 S/W가 적극 지원하면서 생긴
오해이다.
✓ Object Storage는 미션 크리티컬 한 비정형 데이터 저장을 위한
솔루션 이다.
✓ Object Storage는 비정형 데이터를 위한 최상의 신뢰성을
제공한다.
✓ 9-nines (99.9999999%) ~ 15-nines (99.9999999999999%)의
신뢰성을 보장해야 진정한 Object Storage 이다.
8.
오브젝트 스토리지의 탄생배경
대용량 저장소의 필요성
• 대형 포털사
• Google, AWS 등 클라우드 서비스
• 컨텐츠 서비스 (Facebook,
YouTube)
고 신뢰성 저장소의 필요성
• 수백 PB ~ 수 EB
→ 전통적 Data 백업 불가
→ 그러나, Data는 존립을 위한
필수 요소
✓ Scale-out 구조 (용량, 성능)
✓ Meta Data Table 제거
✓ Object 개념 도입 (폴더, 파일
등등이 동등한 Level의 Object로
저장)
✓ Hardware 비용 최소화 (범용 서버
사용)
✓ Bucket 개념 도입 (멀티테넌시
지원)
✓ 백업 및 리스토어 불가
✓ 컨텐츠가 비즈니스
✓ Disk 장애에 대비 (패리티 블록
증가, +1, +2, +3, +4, +5, +6…)
✓ 노드 장애 대비 (블록 복제 or
Erasure Code)
✓ Site 장애 대비 (분산 저장)
✓ Self-Healing
지역적으로 분리된 사용자
• Global Storage 서비스
→ 각 지역의 사용자는 응답
성능이 빠른 가까운 곳으로
접속
✓ 멀티 사이트에 분산 저장하는
가상화 된 단일 저장소
✓ 사용자는 가장 빠른/가까운
시스템을 통하여 Data에 Access
✓ 지역적으로 불규칙한 사용자 분포
→ 각 사이트 마다 Access 성능
조정
Google, Facebook, YouTube 등 대용량 비정형 데이터 저장소가 필요한 서비스를 위해서 개발됨
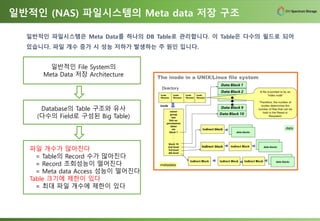
일반적인 (NAS) 파일시스템의Meta data 저장 구조
일반적인 File System의
Meta Data 저장 Architecture
Database의 Table 구조와 유사
(다수의 Field로 구성된 Big Table)
파일 개수가 많아진다
= Table의 Record 수가 많아진다
= Record 조회성능이 떨어진다
= Meta data Access 성능이 떨어진다
Table 크기에 제한이 있다
= 최대 파일 개수에 제한이 있다
일반적인 파일시스템은 Meta Data를 하나의 DB Table로 관리합니다. 이 Table은 다수의 필드로 되어
있습니다. 파일 개수 증가 시 성능 저하가 발생하는 주 원인 입니다.
11.
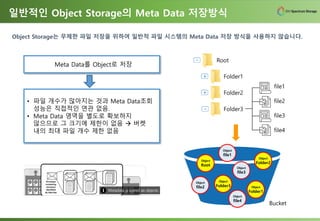
일반적인 Object Storage의Meta Data 저장방식
Object Storage는 무제한 파일 저장을 위하여 일반적 파일 시스템의 Meta Data 저장 방식을 사용하지 않습니다.
Meta Data를 Object로 저장
• 파일 개수가 많아지는 것과 Meta Data조회
성능은 직접적인 연관 없음.
• Meta Data 영역을 별도로 확보하지
않으므로 그 크기에 제한이 없음 → 버켓
내의 최대 파일 개수 제한 없음
Root
Folder1
Folder2
Folder3
Object
Root
Object
Folder1
Object
Folder2
Object
Folder3
Object
file4
file1
file2
file3
file4
Object
file3
Object
file2
Object
file1
Bucket
12.
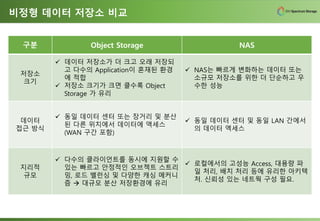
비정형 데이터 저장소
NAS와Object Storage는 비정형 Data 저장소라는 면에서 유사하다.
또한, 서로의 영역을 포함하도록 양측이 지원 범위를 넓혀 가고 있어
외관적 기능상 차이는 없어지고 있다. 다만, 각각의 Data 저장
아키텍처의 차이로 인하여 특정 고객 환경에 어느 것이 더
적합한지에 대한 검토가 필요할 뿐이다.
NAS or Object Storage
Cloud 환경에는 Object Storage가 여러가지 측면에서 최적화 되어있다.
(Object Storage는 Cloud 환경에서 비정형 데이터를 저장하기 위해 만들어
진 솔루션이다.)
다중 업무가 복합되어 있고, 대용량 저장소가 필요하고, 데이터의 가용성이
중요할 수록 Object Storage가 더 적합하다.
13.
비정형 데이터 저장소비교
구분 Object Storage NAS
저장소
크기
✓ 데이터 저장소가 더 크고 오래 저장되
고 다수의 Application이 혼재된 환경
에 적합
✓ 저장소 크기가 크면 클수록 Object
Storage 가 유리
✓ NAS는 빠르게 변화하는 데이터 또는
소규모 저장소를 위한 더 단순하고 우
수한 성능
데이터
접근 방식
✓ 동일 데이터 센터 또는 장거리 및 분산
된 다른 위치에서 데이터에 액세스
(WAN 구간 포함)
✓ 동일 데이터 센터 및 동일 LAN 간에서
의 데이터 엑세스
지리적
규모
✓ 다수의 클라이언트를 동시에 지원할 수
있는 빠르고 안정적인 오브젝트 스트리
밍, 로드 밸런싱 및 다양한 캐싱 메커니
즘 → 대규모 분산 저장환경에 유리
✓ 로컬에서의 고성능 Access, 대용량 파
일 처리, 배치 처리 등에 유리한 아키텍
처. 신뢰성 있는 네트웍 구성 필요.
14.
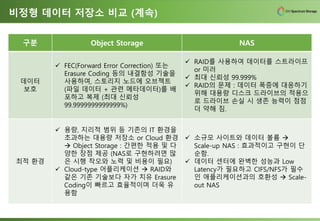
비정형 데이터 저장소비교 (계속)
구분 Object Storage NAS
데이터
보호
✓ FEC(Forward Error Correction) 또는
Erasure Coding 등의 내결함성 기술을
사용하여, 스토리지 노드에 오브젝트
(파일 데이터 + 관련 메타데이터)를 배
포하고 복제 (최대 신뢰성
99.9999999999999%)
✓ RAID를 사용하여 데이터를 스트라이프
or 미러
✓ 최대 신뢰성 99.999%
✓ RAID의 문제 : 데이터 폭증에 대응하기
위해 대용량 디스크 드라이브의 적용으
로 드라이브 손실 시 생존 능력이 점점
더 약해 짐.
최적 환경
✓ 용량, 지리적 범위 등 기존의 IT 환경을
초과하는 대용량 저장소 or Cloud 환경
→ Object Storage : 간편한 적용 및 다
양한 장점 제공 (NAS로 구현하려면 많
은 시행 착오와 노력 및 비용이 필요)
✓ Cloud-type 어플리케이션 → RAID와
같은 기존 기술보다 자가 치유 Erasure
Coding이 빠르고 효율적이며 더욱 유
용함
✓ 소규모 사이트와 데이터 볼륨 →
Scale-up NAS : 효과적이고 구현이 단
순함.
✓ 데이터 센터에 완벽한 성능과 Low
Latency가 필요하고 CIFS/NFS가 필수
인 애플리케이션과의 호환성 → Scale-
out NAS
구성의 유연성
가용성/용량 요구조건에 따라
다양한 Parity 구성 가능
용량/성능이 정해진 모델을 선택해야 함
특정 (12+4 / 10+2) Parity로 제한
스토리지 확장성
API 호환성
용량/성능 요구 조건에 따라
각각 단위 별 증설 가능 필요시 용량/성능 동시 증설해야 함
H/W선택 유연성
일부 X86 모델로 제한됨
(HPE SL4540, Dell R730XD, DSS 7000)
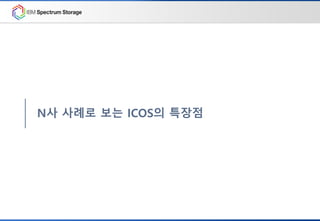
N사가 ICOS를 선택한 다섯 가지 이유
IBM Certified 상용 X86 서버 구성
(Lenovo, HPE, Dell, Supermicro 등 다양)
S3 API 호환성 90% S3 API 호환성 50% 내외
타사
Object Storage
최대 8 사이트 까지
멀티 사이트 Active-Active 구성
Data Replication 기반
Active-Standby
멀티 사이트 지원
17.
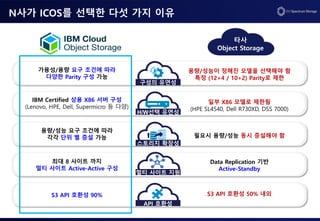
Key Point 1.구성의 유연성
Manager
Accesser
Slicestor
Manager Node, 1U
GUI관리, 시스템 구성 정보 등 저장
시스템 당 최소 1대 ※ 2대로 Active-Active 구성 가능
Gateway Node, 1U
S3 (http/https) 프로토콜 기반 데이터 I/O 처리
성능 요건에 따라 수량 산정
Storage Node, 3U
HDD 12Bay의 스토리지리치 서버
데이터 분산 저장 용도
시스템 당 최소 3대
용량 요건에 따라 수량 산정
IBM Cloud Object Storage는 Manager(시스템 관리/모니터), Accesser (데이터 I/O),
Slicestor (데이터 저장)으로 구성됩니다.
18.
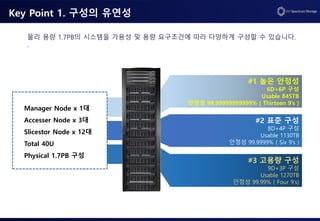
Key Point 1.구성의 유연성
#1 높은 안정성
6D+6P 구성
Usable 845TB
안정성 99.99999999999% ( Thirteen 9’s )
Manager Node x 1대
Accesser Node x 3대
Slicestor Node x 12대
Total 40U
Physical 1.7PB 구성
#2 표준 구성
8D+4P 구성
Usable 1130TB
안정성 99.9999% ( Six 9’s )
#3 고용량 구성
9D+3P 구성
Usable 1270TB
안정성 99.99% ( Four 9’s)
물리 용량 1.7PB의 시스템을 가용성 및 용량 요구조건에 따라 다양하게 구성할 수 있습니다.
.
19.
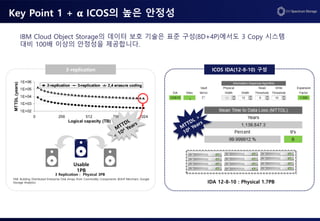
Key Point 1+ 𝛂 ICOS의 높은 안정성
3-replication ICOS IDA(12-8-10) 구성
Usable
1PB
3 Replication : Physical 3PB
IDA 12-8-10 : Physical 1.7PB
FAB: Building Distributed Enterprise Disk Arrays from Commodity Components @Arif Merchant, Google
Storage Analytics
IBM Cloud Object Storage의 데이터 보호 기술은 표준 구성(8D+4P)에서도 3 Copy 시스템
대비 100배 이상의 안정성을 제공합니다.
20.
참고 : ICOS의Data 보호 방식 (Information Dispersal Algorithm)
IBM Cloud Object Storage는 IDA라는 규칙을 기반으로 데이터를 저장합니다. Accesser를 통해 유입된 Data는 4MB 단위의
Segment로 분할되며, Segment는 Erasure Coding 기반의 IDA에 따라 분할돼 Storage Node (Slicestor)에 분산 저장됩니다.
IDA 규칙 예시 : 12-7-9
Width
: Slicestor 수
Read Threshold
: 12대의 Slicestor 중 Data Read를 위해 필요한 최소 Node 수.
12대 중 가장 빠른 응답시간을 보인 8개 Node에서 데이터 Read.
최대 5대의 node가 Down 되더라도 데이터 읽기에 문제가 없음.
Write Threshold
: 12대의 Slicestor 중 Data가 쓰여지는 데 필요한 최소 Node 수.
* Read threshold 보다 커야 함.
Write threshold에 도달 하면 다음 쓰기 작업 수행
Original Data
$
Accesser
$
4MB4MB4MB4MB4MB
7
6
5
4
3
1
2
12
11
10
9
8
7
6
5
4
3
1
2
12111098765431 2
Storage Nodes
SITE 2 SITE 3
SITE 3SITE 1 SITE 2
1
2
3
4
5
6
7
8
9
10
11
12
① 데이터가 Accesser를 통해 Ingest ② 4MB Segment 분할
③ Segment를
Slice로 분할
④ Erasure
Coding으로 Slice 추가
⑤ 각 Slice를 Storage Node (Slicestor)에 분산 저장
IDA규칙
기반으로
Slice 추가
원본 Slice
12 7 9
Reliability 최대 99.9999999999999%
21.
Key Point 2.HW활용성
IBM Cloud Object Storage는 Cisco, Dell, HP, Lenovo, SuperMicro, Quanta 등 6개
Vendor의 표준 모델을 지원 하며, 고객의 요구 사항에 따라 아래 제품 외 타사 및
타제품의 H/W Certification을 지원합니다.
• HP Branded Appliance (Gen9/Gen10)
– DL 360 / DL 380
– Apollo 4200 / 4510 / 4530
– HPE Smart Array Gen10 SAS Controllers
• Cisco Branded Appliances
– USC-C3260 M4 / C3260-M5
– USC-C220 M4 / C220 M5 / C240 M5
• SuperMicro Branded Appliances
• Lenovo Branded Appliances
– X3650 / X3550
– SR 650 / SR 630
• Dell Branded Appliances
– R740
– DSS7000
• Quanta Branded Appliance
– QuantaGrid D51PH-1U
IBM의 Appliance 제품 외에도 IBM의 인증을 받은 업계 표준 플랫폼 하드웨어를 지원합니다
22.
Key Point 3.확장성
ICOS는 추가 용량 증설 시 스토리지 노드를, 성능 증설 필요 시 게이트웨이 노드를 각각
추가해 용량, 성능을 확장할 수 있습니다.
구 분 Access Pool(성능) Storage Pool(용량)
온라인 확장 Yes Yes
상이한 노드
(용량/세대)
Yes Yes
확장 기준 제약사항 없음
• 기존 용량 증설 시, 기존 IDA를 따르며
증설 (노드 수, 용량)
• 신규 Pool 생성 시, 제약 없음
[ Access Pool ]
https://<LB-IP>/platium-bucket
https://<LB-IP>/gold-bucket
Load
Balancer
기존 Pool
(12/7/9)
신규 Pool
(6대)
[ Storage Pool ]
Platinum-container
용량 확장
성능 확장
사용자/버킷
Gold-container
23.
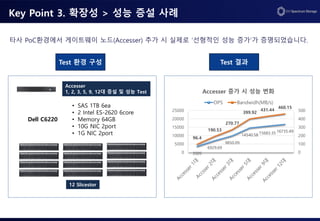
Key Point 3.확장성 > 성능 증설 사례
Dell C6220
12 Slicestor
Accesser
1, 2, 3, 5, 9, 12대 증설 및 성능 Test
Test 환경 구성 Test 결과
3505
6929.69
9850.09
14540.58 15683.35 16735.49
96.4
190.53
270.77
399.92
431.44
460.15
0
100
200
300
400
500
0
5000
10000
15000
20000
25000
Accesser 증가 시 성능 변화
OPS Bandwidh(MB/s)
타사 PoC환경에서 게이트웨이 노드(Accesser) 추가 시 실제로 ‘선형적인 성능 증가’가 증명되었습니다.
• SAS 1TB 6ea
• 2 Intel ES-2620 6core
• Memory 64GB
• 10G NIC 2port
• 1G NIC 2port
24.
Key Point 4.Multi Site 구성
6개 사이트 구성 예시 – 단일 네임 스페이스 (24D+6P 적용 시)
Geo Dispersed
Site D
Site E
Site F
Site A
Site B
Site C
Manager X 2
Accesser X 12
Slicestor X 30
[동작 방식 설명]
① 각 사이트 별 사용자는 해당 사이트의
Accesser에 접속
(성능/이중화 요건 고려 2대 이상 권고)
② 24D+6P 적용 시, 사이트 별 스토리지 노드
5대씩 구성
③ 1개 사이트가 완전히 다운되어도
나머지사이트에서 데이터 액세스 가능
④ 전체 6 노드 장애 시에도 데이터 읽기 가능
⑤ 전체 4 노드 장애 시에도 데이터 쓰기 가능
ICOS는 데이터 분산 저장에 기반한 설계로, 최대 8 사이트까지 단일 네임 스페이스에서 Active-
Active 구성이 가능합니다.
25.
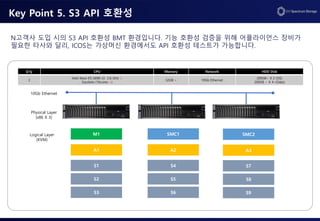
Key Point 5.S3 API 호환성
ObjectApiTest: 22 total, 22 passed BucketApiTest: 29 total, 24 passed
Grand total : 46 Passed / 51 total (90%)
Sample
2017-12-07 16:33:24 [DEBUG](request :1183)
com.amazonaws.http.AmazonHttpClient$RequestExecutor
executeOneRequest Sending Request: PUT http://10.250.11.147
/ncptest-20171207163324386/destination.txt Headers: (x-amz-copy-
source: /ncptest-20171207163324315/source.txt, Content-Length: 0,
User-Agent: aws-sdk-java/1.11.238 Mac_OS_X/10.10.5
Java_HotSpot(TM)_64-Bit_Server_VM/24.79-b02 java/1.7.0_79, amz-sdk-
invocation-id: dcc2928e-3841-b3a6-9211-c8cf736b2785, Content-Type:
application/octet-stream, )x-amz-copy-source:/ncptest-
20171207163324315/source.txt
S3 API 호환성 테스트 결과, N사가 요구한 51개 API 기능 중 46개를 지원해, 경쟁사 대비 월등히
뛰어난 API 호환성을 기록했습니다.
26.
Key Point 5.S3 API 호환성
Logical Layer
(KVM)
Physical Layer
(x86 X 3)
10Gb Ethernet
M1 SMC1 SMC2
A1 A2 A3
S1 S4 S7
S2 S5 S8
S3 S6 S9
Q’ty CPU Memory Network HDD Disk
3
Intel Xeon E5-2690 v3 2.6 GHz +
2sockets (16cores +)
32GB + 10Gb Ethernet
200GB+ X 2 (OS)
200GB + X 4+(Data)
N고객사 도입 시의 S3 API 호환성 BMT 환경입니다. 기능 호환성 검증을 위해 어플라이언스 장비가
필요한 타사와 달리, ICOS는 가상머신 환경에서도 API 호환성 테스트가 가능합니다.
ICOS 어디에 적용하면좋을까요?
비 정형데이터 통합 저장소
Enterprise Contents
Management
PC 백업
협업 시스템 (공유)
백업 + 자동소산
아카이브
파일저장이
필요한
모든 App.
29.
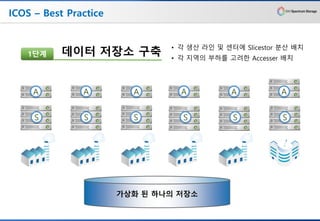
ICOS – BestPractice
A
데이터 저장소 구축
가상화 된 하나의 저장소
S
1단계
S S S S S
A A A A A
• 각 생산 라인 및 센터에 Slicestor 분산 배치
• 각 지역의 부하를 고려한 Accesser 배치
30.
ICOS – BestPractice
• 생산로그 수집&분석
• 문서중앙화, 그룹웨어
• 전 직원 PC백업,부서용 NAS
• 전사 Archive Storage
• 통합 백업 Storage + 자동 소산
#1 데이터 안정성
#1 용량/성능 확장성
필요한 용도의 서비스를 개통2단계
가상화 된 하나의 저장소
31.
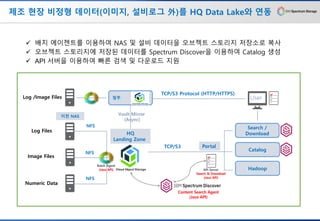
제조 현장 비정형데이터(이미지, 설비로그 外)를 HQ Data Lake와 연동
Log Files
Image Files
Numeric Data
이천 NAS
청주
Catalog
Hadoop
User
Search /
Download
TCP/S3 Protocol (HTTP/HTTPS)
NFS
NFS
NFS
Log /Image Files
Portal
HQ
Landing Zone
Batch Agent
(Java API)
Vault Mirror
(Async)
TCP/S3
Content Search Agent
(Java API)
API Server
Search & Download
(Java API)
✓ 배치 에이젠트를 이용하여 NAS 및 설비 데이터을 오브젝트 스토리지 저장소로 복사
✓ 오브젝트 스토리지에 저장된 데이터를 Spectrum Discover을 이용하여 Catalog 생성
✓ API 서버을 이용하여 빠른 검색 및 다운로드 지원
32.
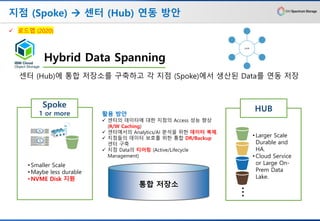
지점 (Spoke) →센터 (Hub) 연동 방안
Hybrid Data Spanning
통합 저장소
HUB
• Larger Scale
Durable and
HA.
• Cloud Service
or Large On-
Prem Data
Lake.
센터 (Hub)에 통합 저장소를 구축하고 각 지점 (Spoke)에서 생산된 Data를 연동 저장
✓ 로드맵 (2020)
Spoke
1 or more
• Smaller Scale
• Maybe less durable
• NVME Disk 지원
활용 방안
✓ 센터의 데이터에 대한 지점의 Access 성능 향상
(R/W Caching)
✓ 센터에서의 Analytics/AI 분석을 위한 데이터 복제.
✓ 지점들의 데이터 보호를 위한 통합 DR/Backup
센터 구축
✓ 지점 Data의 티어링 (Active/Lifecycle
Management)
…
ICOS의 존재의 이유
✓무한 확장
• 비정형 Data의 통합 저장소로서…
가속되는 데이터 증가율에 대응하기
위해 지속적인 저장소 확장의 필요성
Scalable Object storage
No limits
온라인 중 성능/용량 확장
✓ 데이터 자동 소산
• 비정형 Data의 통합 저장소로서…
백업/아카이브 Data의 보호 극대화를
위한 리모트 자동 소산의 필요성
패리티 분산 저장을 통한 비용효율적
데이터 소산
2 Site는 물론 3~8 Site 까지 Data 분
산 소산 가능
✓ Global 서비스
• 비정형 Data의 통합 저장소로서…
사용자 위치에 관계없이 최적의 접속
환경 제공의 필요성
Active-Active Site
사용자 위치에 관계없는 Data 접속
GSLB 연동
✓ Storage 신뢰성 극대화
• 비정형 Data의 통합 저장소로서…
가용성, 안전성, 관리 편의성 등 지속
적인 서비스 유지를 위한 필요성
Fifteen 9s Reliability
Disk, Node, Site 장애 대비
Better manageability
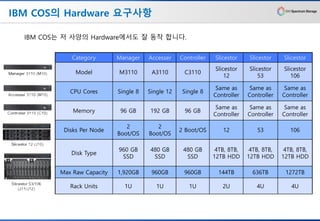
IBM COS의 Hardware요구사항
IBM COS는 저 사양의 Hardware에서도 잘 동작 합니다.
Category Manager Accesser Controller Slicestor Slicestor Slicestor
Model M3110 A3110 C3110
Slicestor
12
Slicestor
53
Slicestor
106
CPU Cores Single 8 Single 12 Single 8
Same as
Controller
Same as
Controller
Same as
Controller
Memory 96 GB 192 GB 96 GB
Same as
Controller
Same as
Controller
Same as
Controller
Disks Per Node
2
Boot/OS
2
Boot/OS
2 Boot/OS 12 53 106
Disk Type
960 GB
SSD
480 GB
SSD
480 GB
SSD
4TB, 8TB,
12TB HDD
4TB, 8TB,
12TB HDD
4TB, 8TB,
12TB HDD
Max Raw Capacity 1,920GB 960GB 960GB 144TB 636TB 1272TB
Rack Units 1U 1U 1U 2U 4U 4U
37.
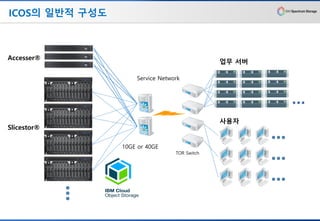
ICOS의 일반적 구성도
10GEor 40GE
Service Network
TOR Switch
업무 서버
사용자
Accesser®
Slicestor®
38.
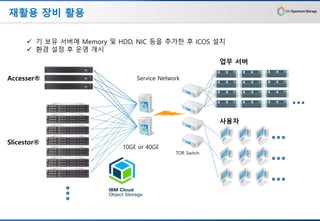
재활용 장비 활용
10GEor 40GE
Service Network
TOR Switch
업무 서버
사용자
✓ 기 보유 서버에 Memory 및 HDD, NIC 등을 추가한 후 ICOS 설치
✓ 환경 설정 후 운영 개시
Accesser®
Slicestor®
39.
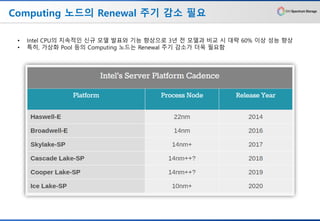
Computing 노드의 Renewal주기 감소 필요
• Intel CPU의 지속적인 신규 모델 발표와 기능 향상으로 3년 전 모델과 비교 시 대략 60% 이상 성능 향상
• 특히, 가상화 Pool 등의 Computing 노드는 Renewal 주기 감소가 더욱 필요함
40.
Computing 노드 →Storage 노드 전환 (예시)
Computing 노드 도입 Storage 노드 전환
3년 후
▪ 자원 사용 최적화를 위하여 도입 및 전환 정책 수립 필요
▪ 각 노드들의 수요 분석 후 전환 대상 수량 산정
▪ Storage 노드 전환을 대비하여…
✓ 총 사용 기간 동안 MA 계약 방식 검토
✓ 노드 전환 시 추가 부품 구매 방식 검토
✓ Computing 노드 도입 시, 전환 비용 최소화를 위한 설계 필요
① 전면부에 불필요한 Indicator 제거 및 Disk Bay 전체 장착
② OS Disk는 서버 후면에 설치 (가능한 경우)
③ 전원공급장치 등은 전환 후를 고려해 용량 산정
④ Data Disk는 Storage 노드 전환 시 구매










![Key Point 3. 확장성
ICOS는 추가 용량 증설 시 스토리지 노드를, 성능 증설 필요 시 게이트웨이 노드를 각각
추가해 용량, 성능을 확장할 수 있습니다.
구 분 Access Pool(성능) Storage Pool(용량)
온라인 확장 Yes Yes
상이한 노드
(용량/세대)
Yes Yes
확장 기준 제약사항 없음
• 기존 용량 증설 시, 기존 IDA를 따르며
증설 (노드 수, 용량)
• 신규 Pool 생성 시, 제약 없음
[ Access Pool ]
https://<LB-IP>/platium-bucket
https://<LB-IP>/gold-bucket
Load
Balancer
기존 Pool
(12/7/9)
신규 Pool
(6대)
[ Storage Pool ]
Platinum-container
용량 확장
성능 확장
사용자/버킷
Gold-container](https://image.slidesharecdn.com/objectstoragev1-converted-200317013638/85/Object-storage-22-320.jpg)
![Key Point 4. Multi Site 구성
6개 사이트 구성 예시 – 단일 네임 스페이스 (24D+6P 적용 시)
Geo Dispersed
Site D
Site E
Site F
Site A
Site B
Site C
Manager X 2
Accesser X 12
Slicestor X 30
[동작 방식 설명]
① 각 사이트 별 사용자는 해당 사이트의
Accesser에 접속
(성능/이중화 요건 고려 2대 이상 권고)
② 24D+6P 적용 시, 사이트 별 스토리지 노드
5대씩 구성
③ 1개 사이트가 완전히 다운되어도
나머지사이트에서 데이터 액세스 가능
④ 전체 6 노드 장애 시에도 데이터 읽기 가능
⑤ 전체 4 노드 장애 시에도 데이터 쓰기 가능
ICOS는 데이터 분산 저장에 기반한 설계로, 최대 8 사이트까지 단일 네임 스페이스에서 Active-
Active 구성이 가능합니다.](https://image.slidesharecdn.com/objectstoragev1-converted-200317013638/85/Object-storage-24-320.jpg)

com.amazonaws.http.AmazonHttpClient$RequestExecutor
executeOneRequest Sending Request: PUT http://10.250.11.147
/ncptest-20171207163324386/destination.txt Headers: (x-amz-copy-
source: /ncptest-20171207163324315/source.txt, Content-Length: 0,
User-Agent: aws-sdk-java/1.11.238 Mac_OS_X/10.10.5
Java_HotSpot(TM)_64-Bit_Server_VM/24.79-b02 java/1.7.0_79, amz-sdk-
invocation-id: dcc2928e-3841-b3a6-9211-c8cf736b2785, Content-Type:
application/octet-stream, )x-amz-copy-source:/ncptest-
20171207163324315/source.txt
S3 API 호환성 테스트 결과, N사가 요구한 51개 API 기능 중 46개를 지원해, 경쟁사 대비 월등히
뛰어난 API 호환성을 기록했습니다.](https://image.slidesharecdn.com/objectstoragev1-converted-200317013638/85/Object-storage-25-320.jpg)






![[IBM 김상훈] 오브젝트스토리지 | 늘어만 가는 데이터 저장문제로 골 아프신가요? (자료를 다운로드하시면 고화질로 보실 수 있습니다.)](https://cdn.slidesharecdn.com/ss_thumbnails/2-181031090033-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅]유닉스의 리눅스 마이그레이션 전략_v3](https://cdn.slidesharecdn.com/ss_thumbnails/unixtolinuxarchitecturev3-140807111733-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)























![[IBM 김상훈] NAS_IBM Spectrum NAS 상세 설명](https://cdn.slidesharecdn.com/ss_thumbnails/3213-181212044648-thumbnail.jpg?width=640&height=640&fit=bounds)


![[AWS Builders] AWS 스토리지 서비스 소개 및 사용 방법](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuilders200storageservice-190611112205-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Games on AWS 2019] AWS 입문자를 위한 초단기 레벨업 트랙 | AWS 레벨업 하기! : 스토리지 - 현륜식 AWS 솔루션...](https://cdn.slidesharecdn.com/ss_thumbnails/03gamesonawsawsstorage-191014081535-thumbnail.jpg?width=640&height=640&fit=bounds)

![[IBM Korea 김상훈] Cleversafe 소개자료](https://cdn.slidesharecdn.com/ss_thumbnails/201607softlayercleversafe-160930062357-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Builders] 우리 워크로드에 맞는 데이터베이스 찾기](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws201webinardatabasejuyeonpark-190306072417-thumbnail.jpg?width=640&height=640&fit=bounds)

