Download as PDF, PPTX




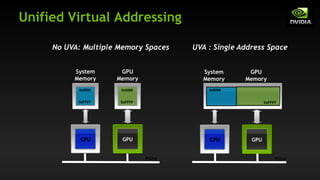




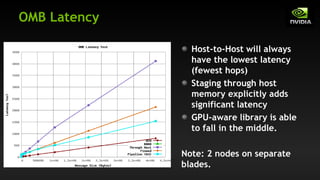



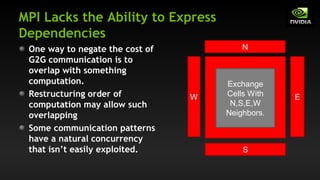






The document discusses the optimization of GPU-to-GPU communication on Cray XK7 systems, highlighting challenges such as higher latency and lower bandwidth when utilizing traditional methods. It emphasizes the importance of GPU-aware MPI libraries that simplify the programming model and enhance performance through techniques like RDMA and pipelining. Ultimately, the paper argues that optimizing communication is crucial as computation scales, and developing effective communication strategies can exploit natural concurrency in certain patterns.

















![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)























































