




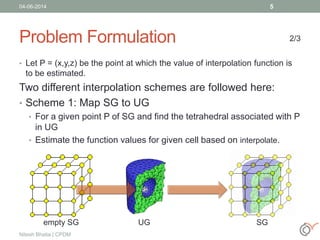
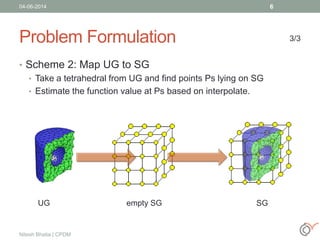









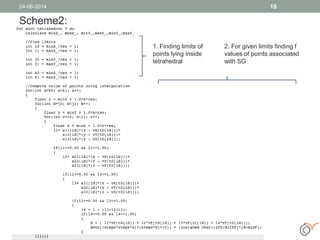

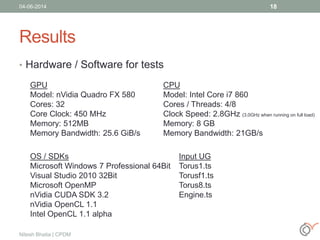
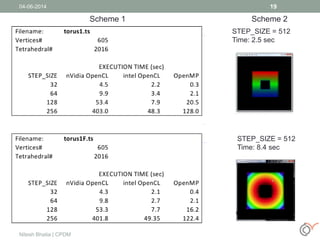
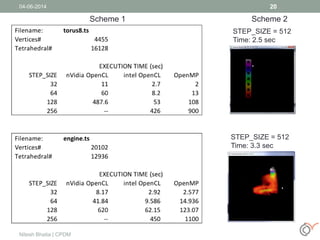

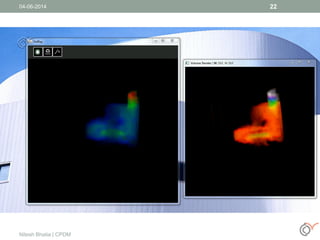



This document discusses the process of volume rendering for unstructured tetrahedral grids, detailing interpolation techniques and implementation methods. It outlines two mapping schemes from unstructured to structured grids and presents a three-step approach to computation and visualization using OpenCL or OpenMP. Results from tests are also provided, demonstrating the performance of different schemes implemented on hardware and software setups.













































































