



![8
Работа с персональными данными
Исходные столбцы
Пример: Ф.И.О. генеральных директоров
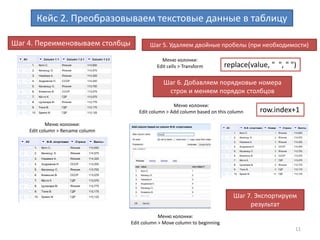
Ошибки в заполнении данных
Построение фасетов
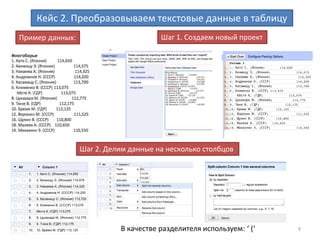
Объединение столбцов
value + " " + cells["First Name"].value + " " + cells["Middle Name"].value
(Объединяем столбцы с фамилией, именем и отчеством в один столбец)
Количество
вариантов](https://image.slidesharecdn.com/openrefinev1-140619154619-phpapp01/85/Open-refine-8-320.jpg)

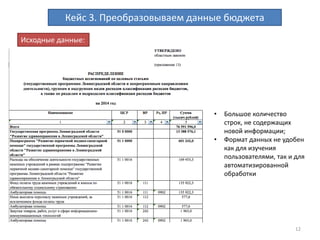
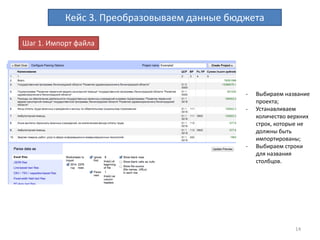
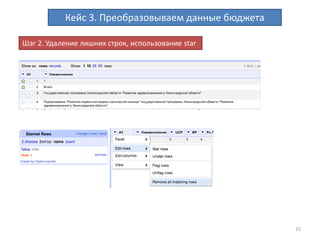
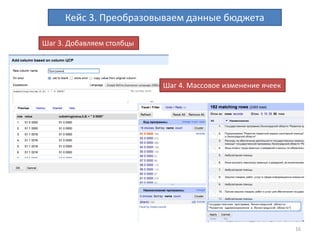




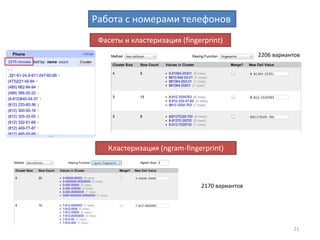



Документ описывает процесс очистки и обработки данных с использованием OpenRefine, принимая во внимание ошибки, преобразования форматов и работу с персональными данными. Приводятся примеры кейсов, включая создание машиночитаемых данных, кластеризацию для нахождения дубликатов и преобразование текстовых данных в таблицы. Завершается информацией о результатах работы с данными бюджета и контактах автора.

























































