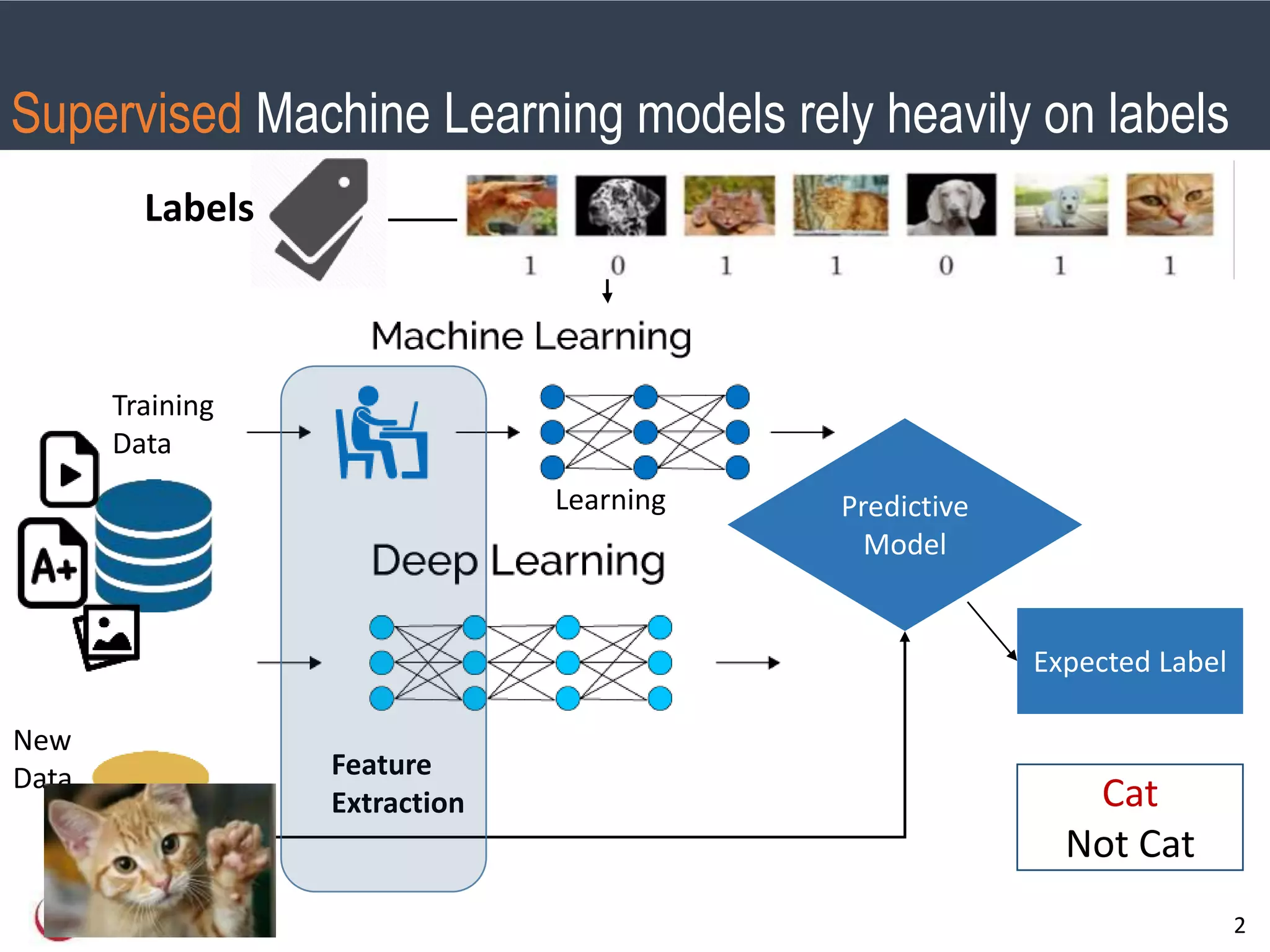
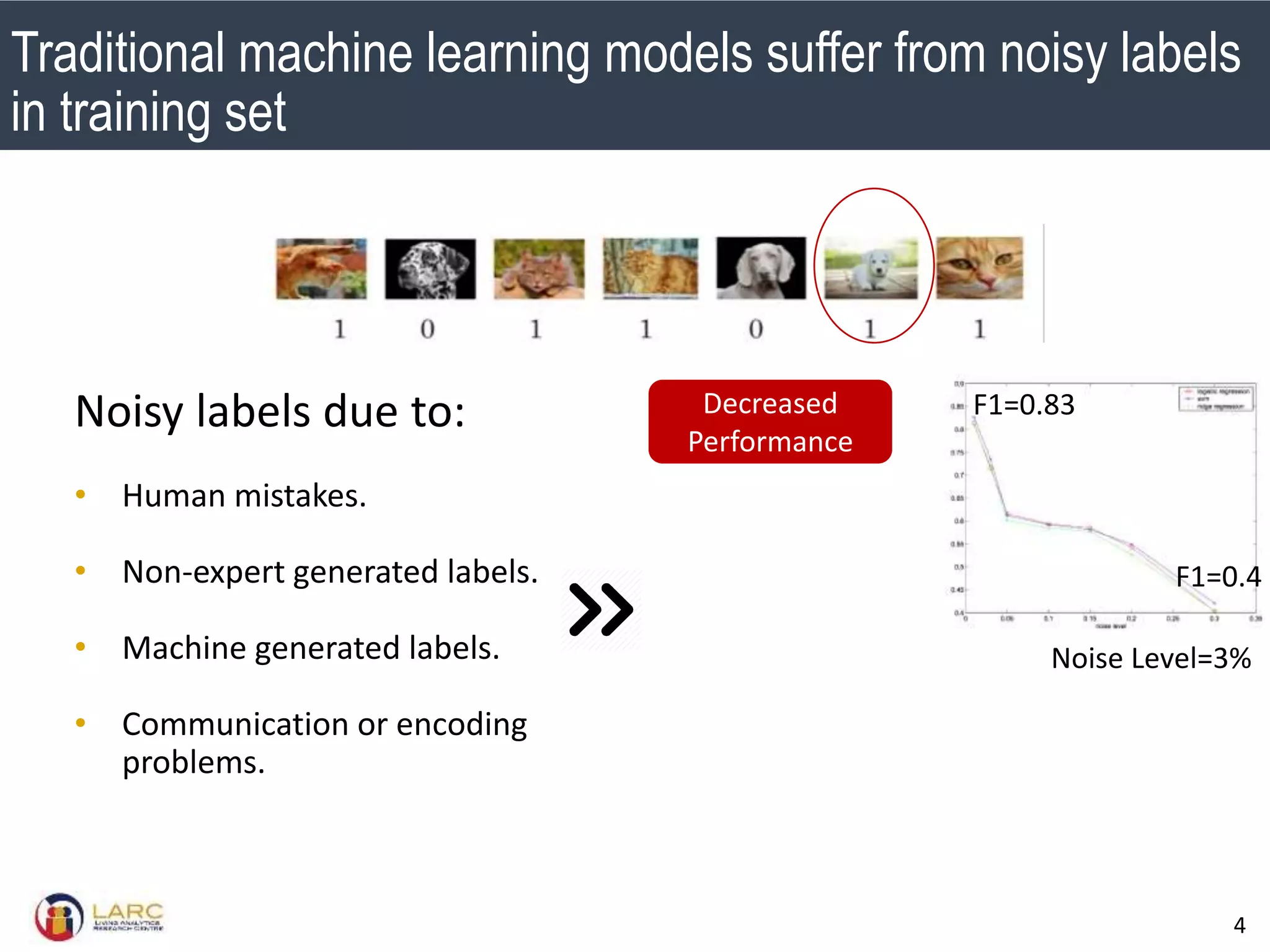
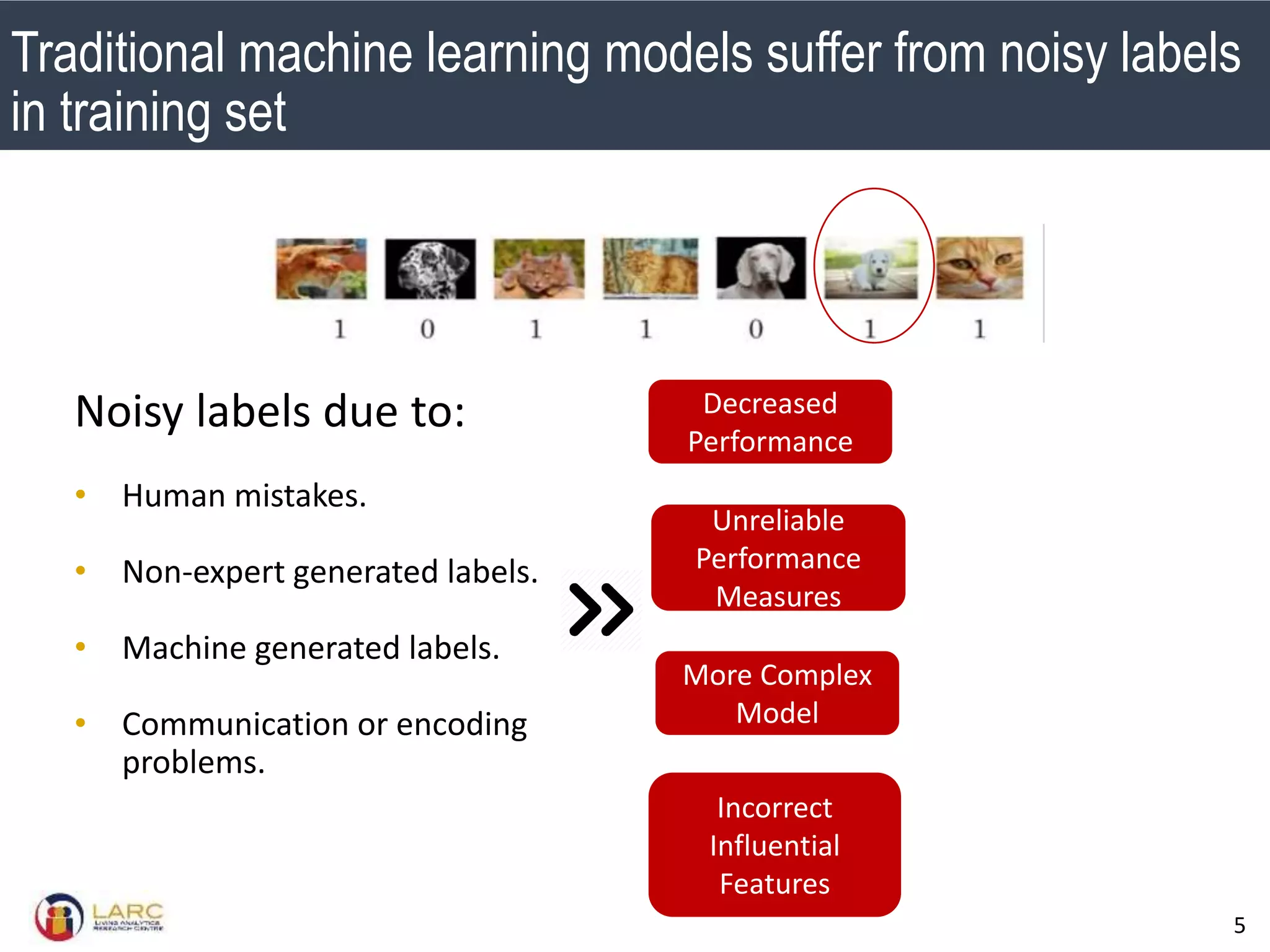
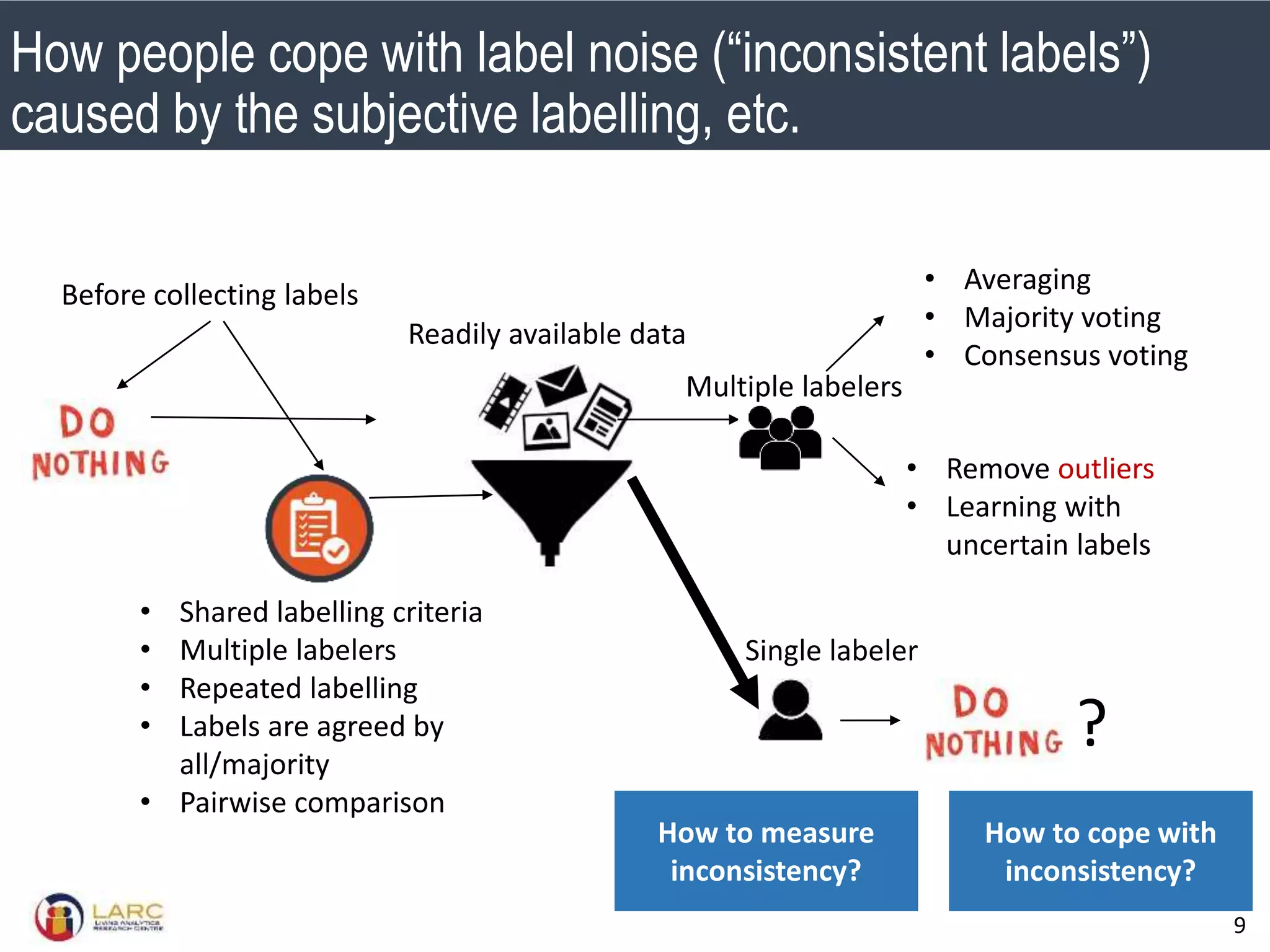
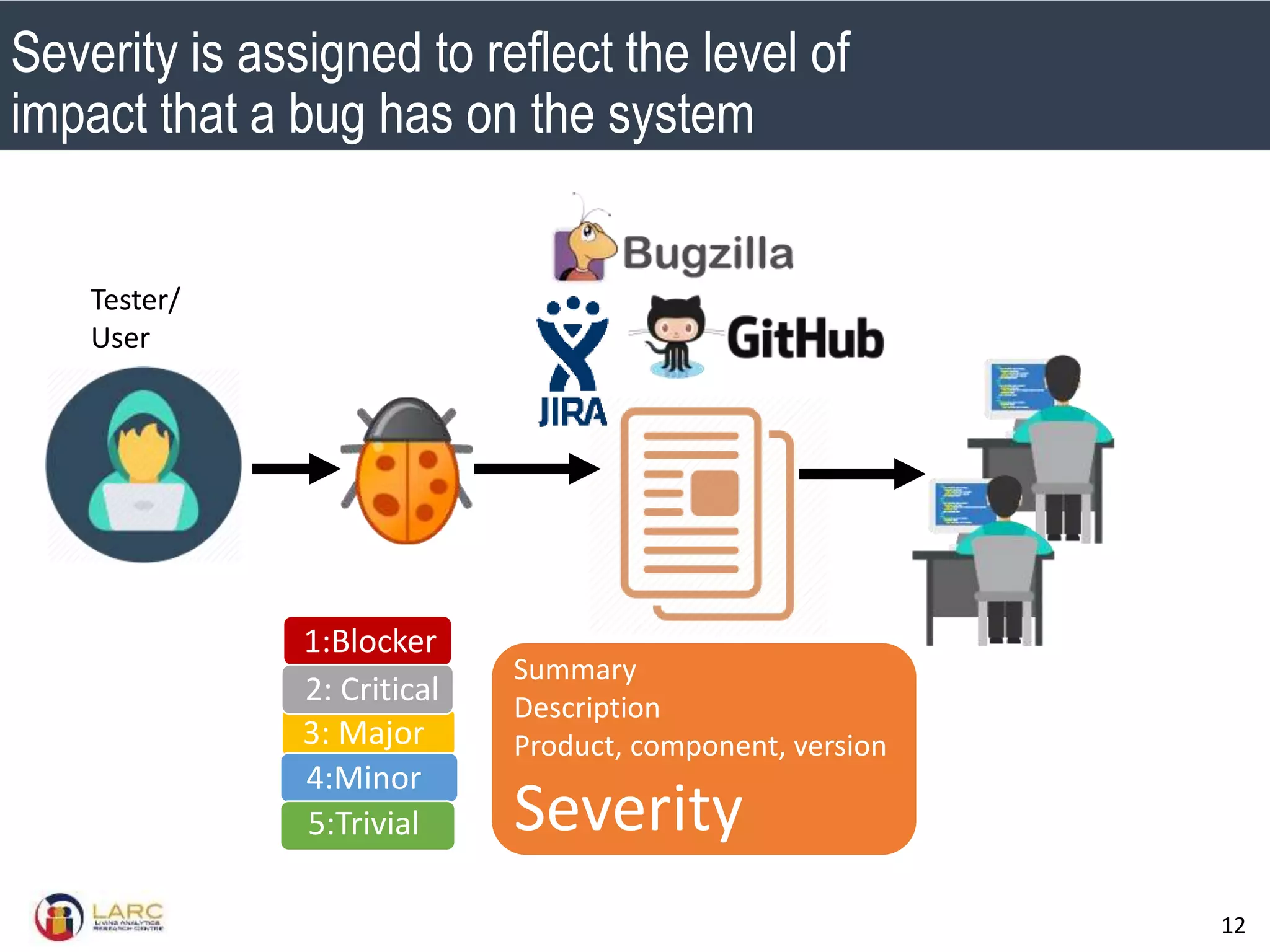
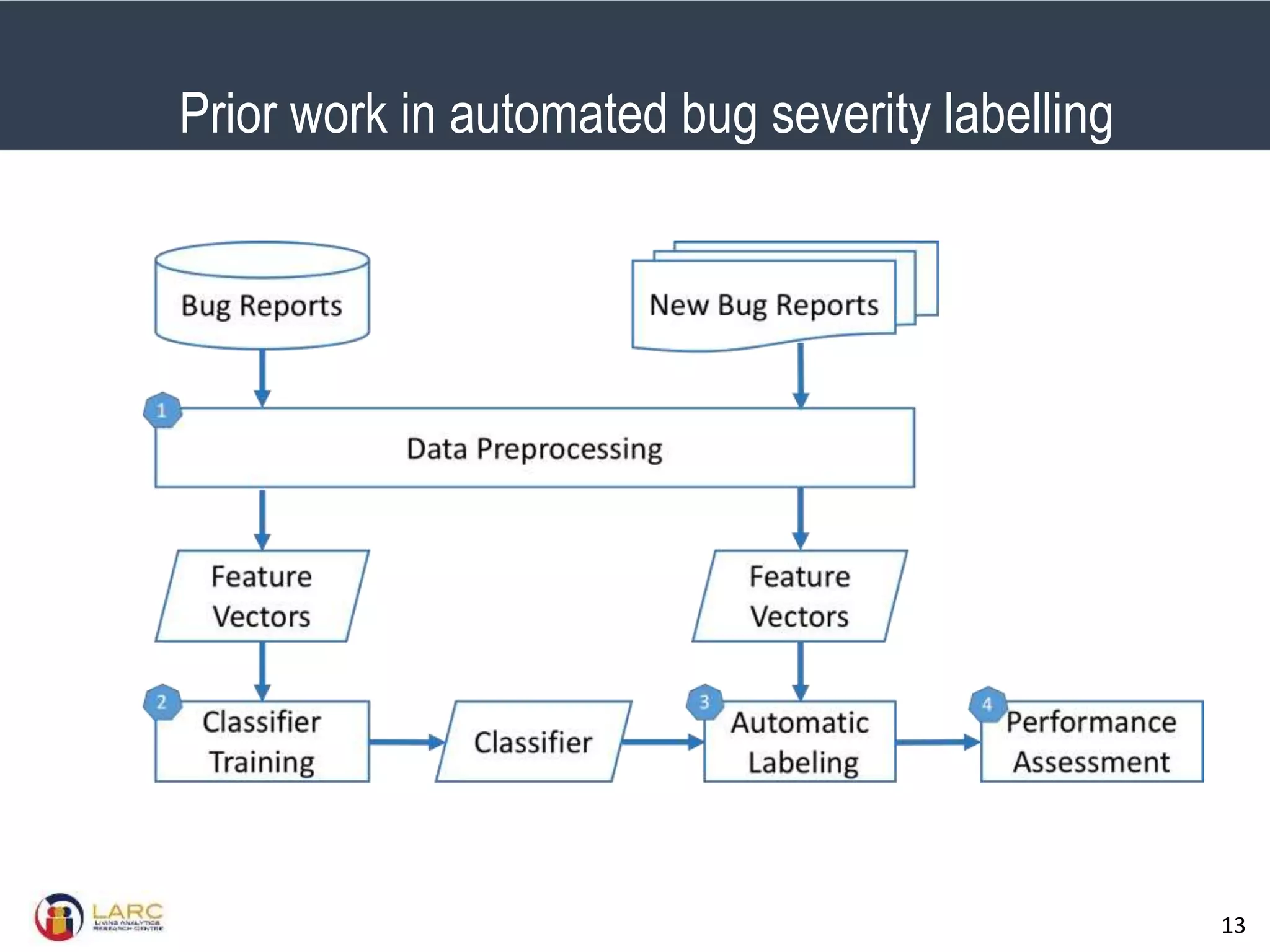
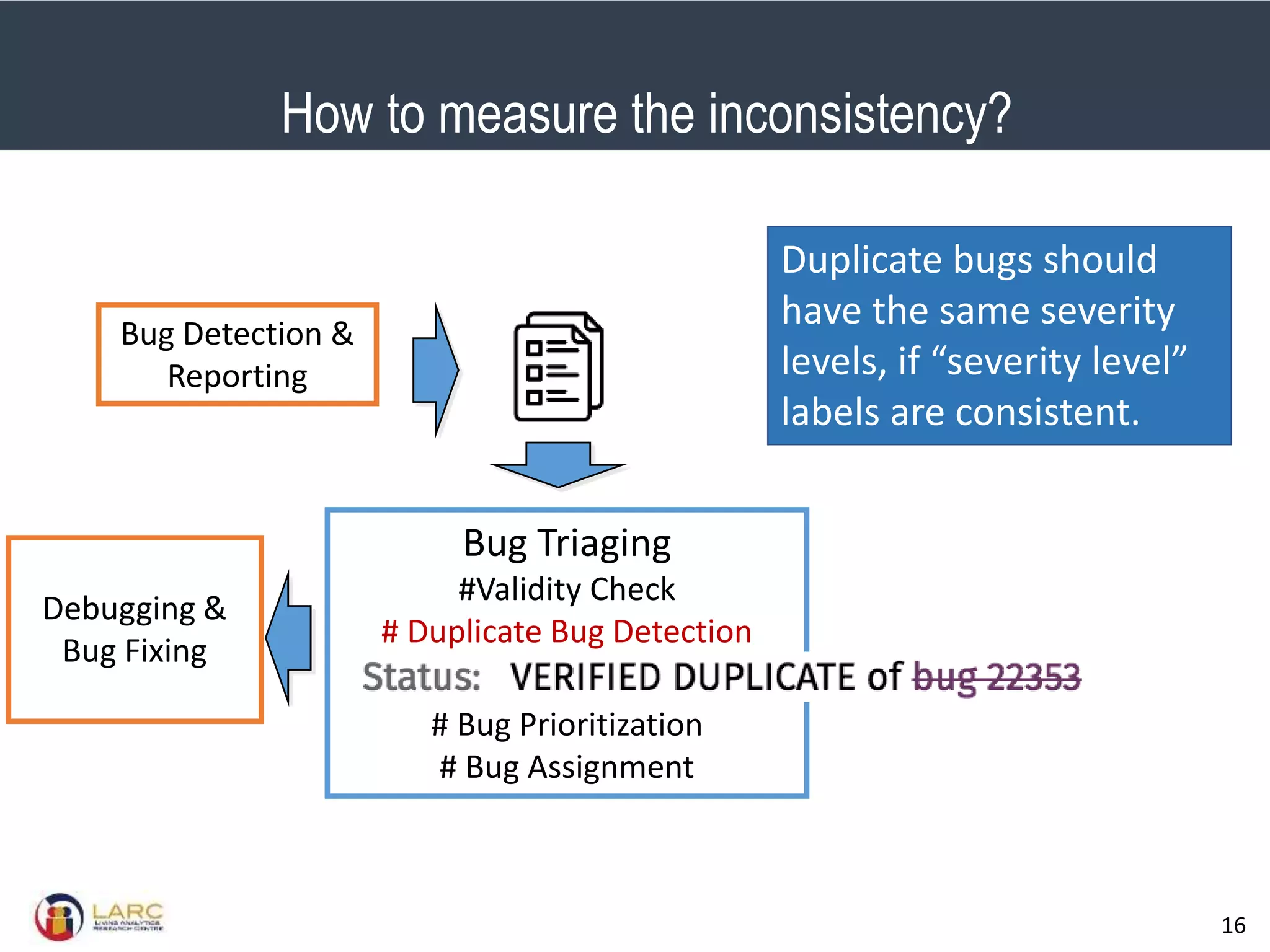
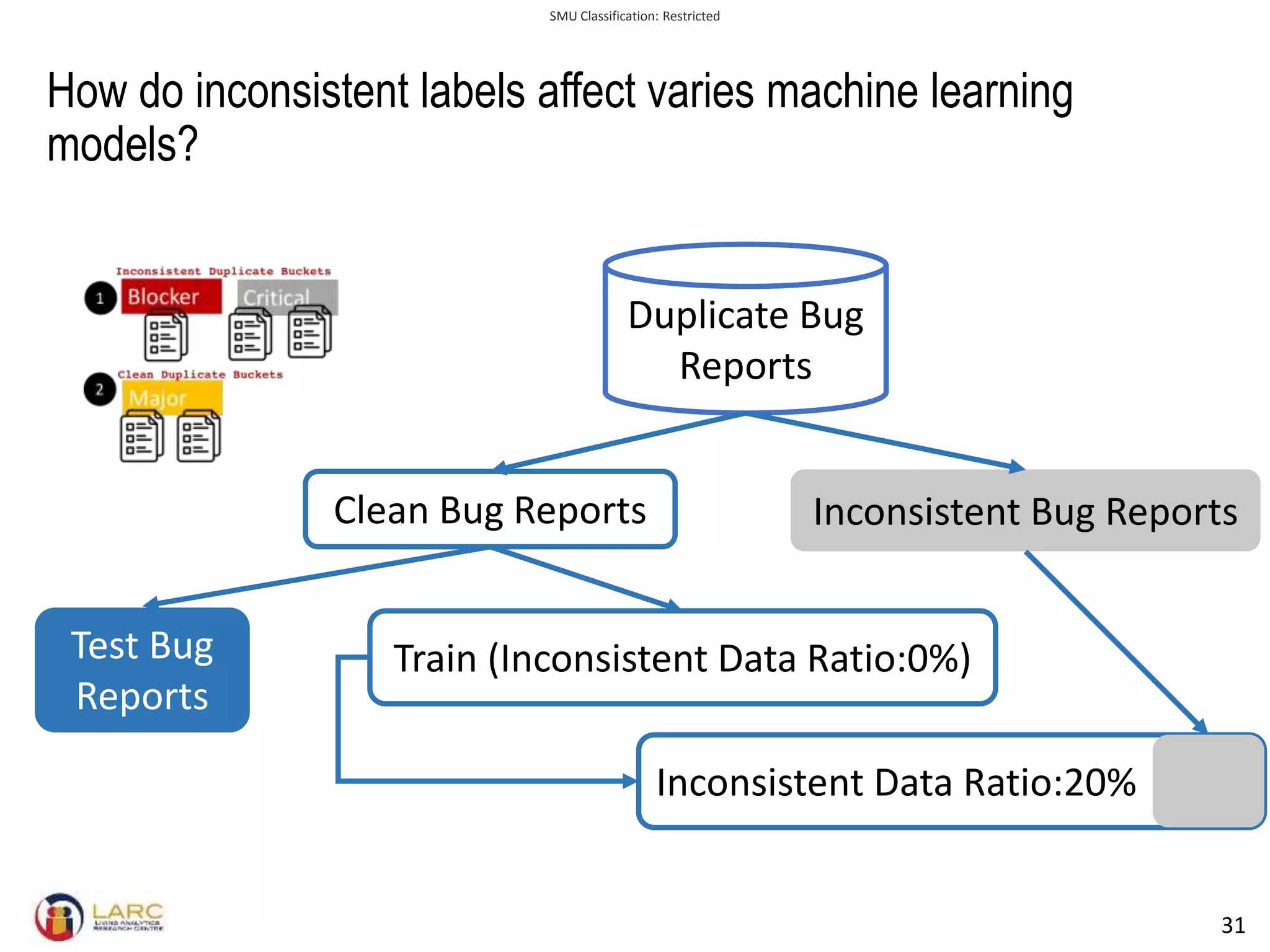
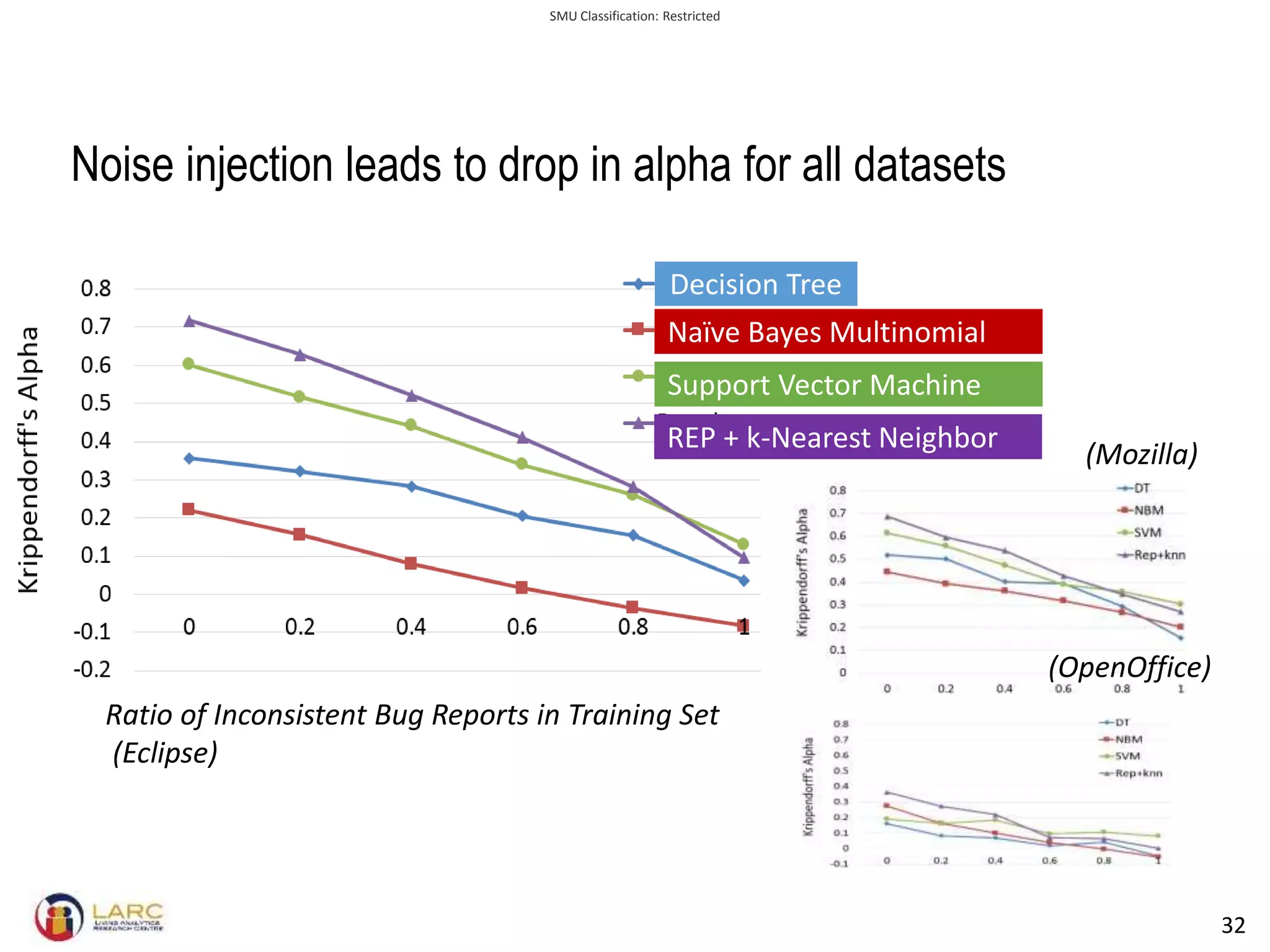
- Machine learning models are negatively impacted by noisy or inconsistent labels in training data. This is a challenge for tasks like bug severity classification where labels can be subjective.
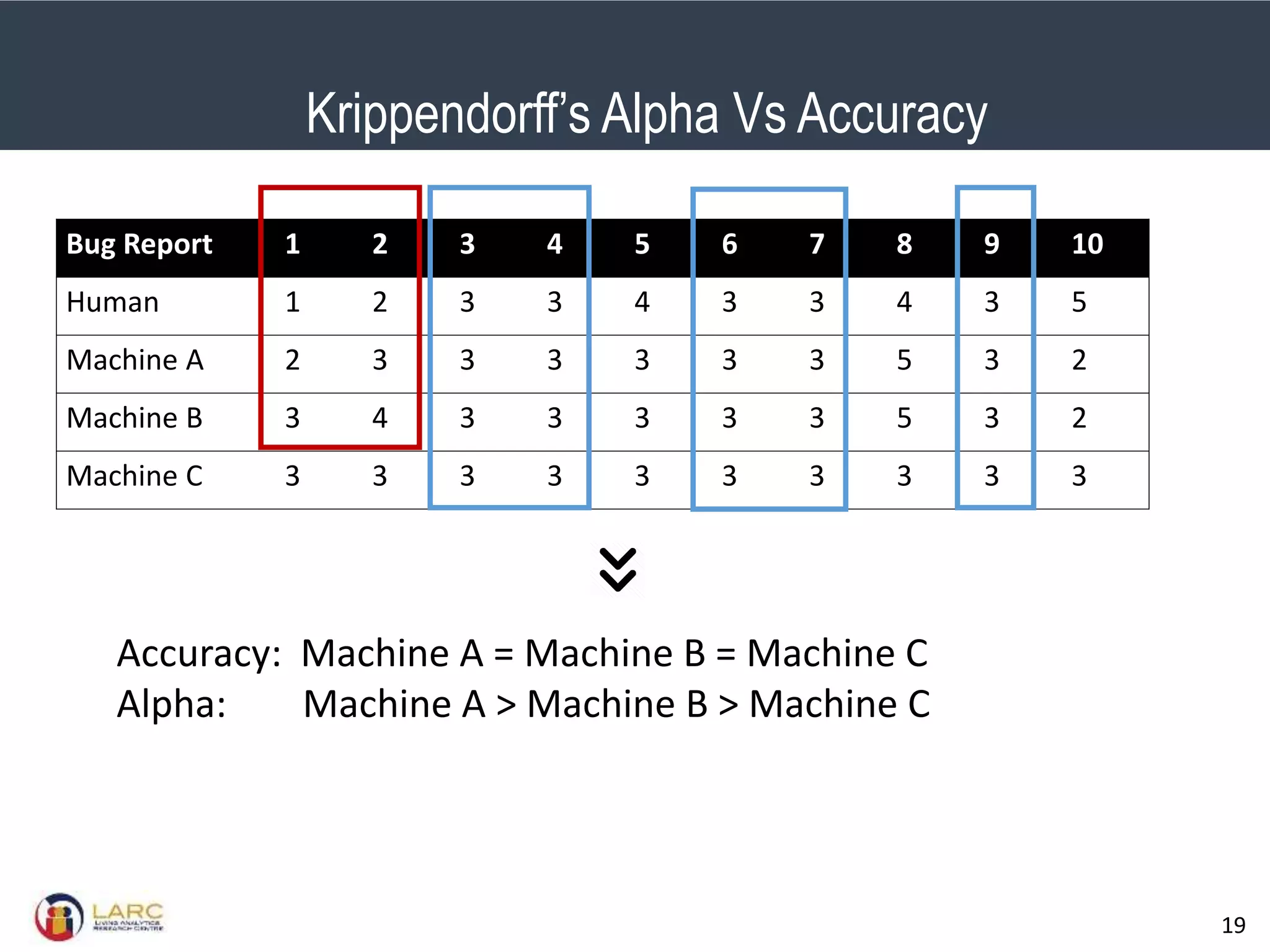
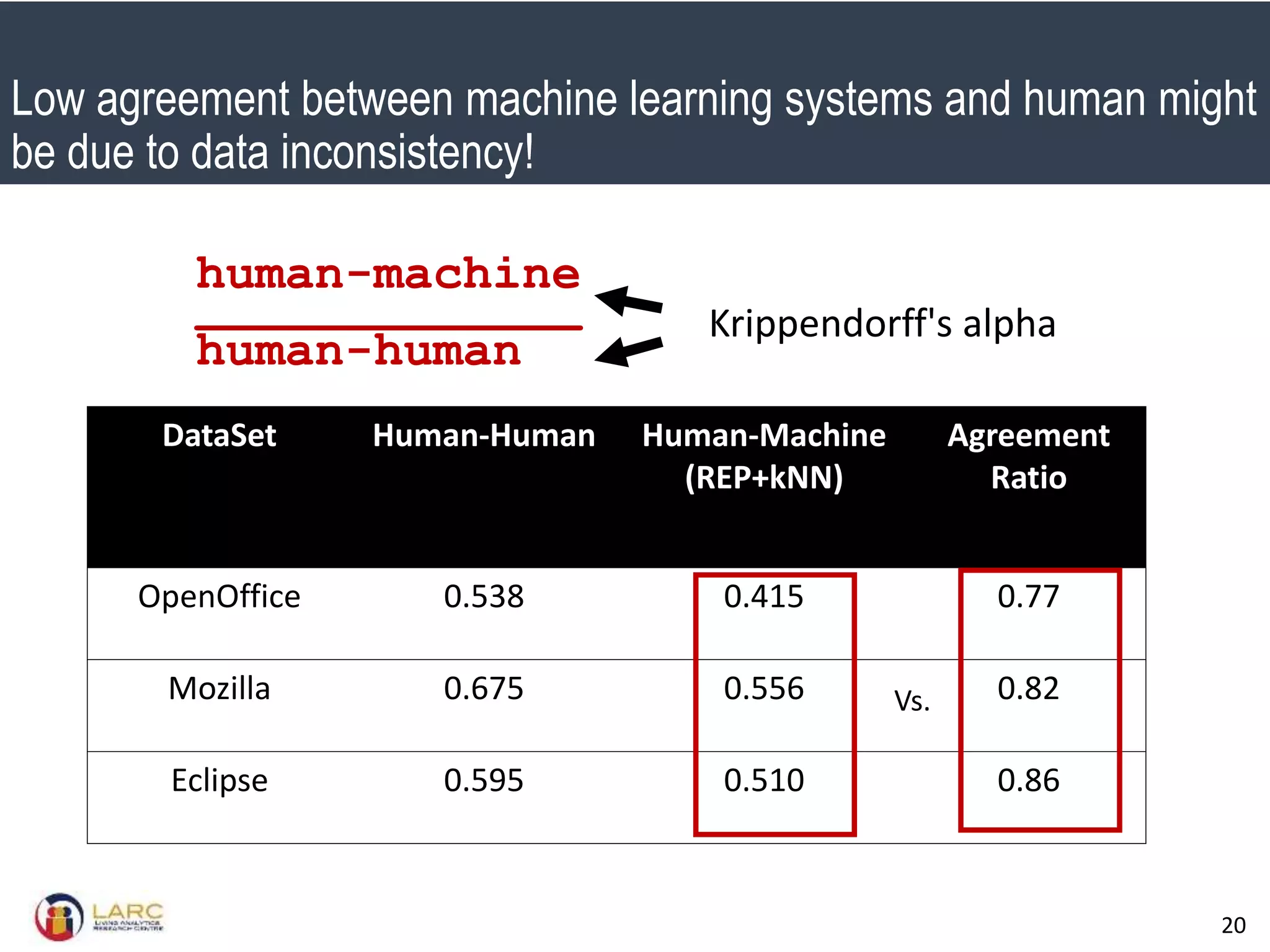
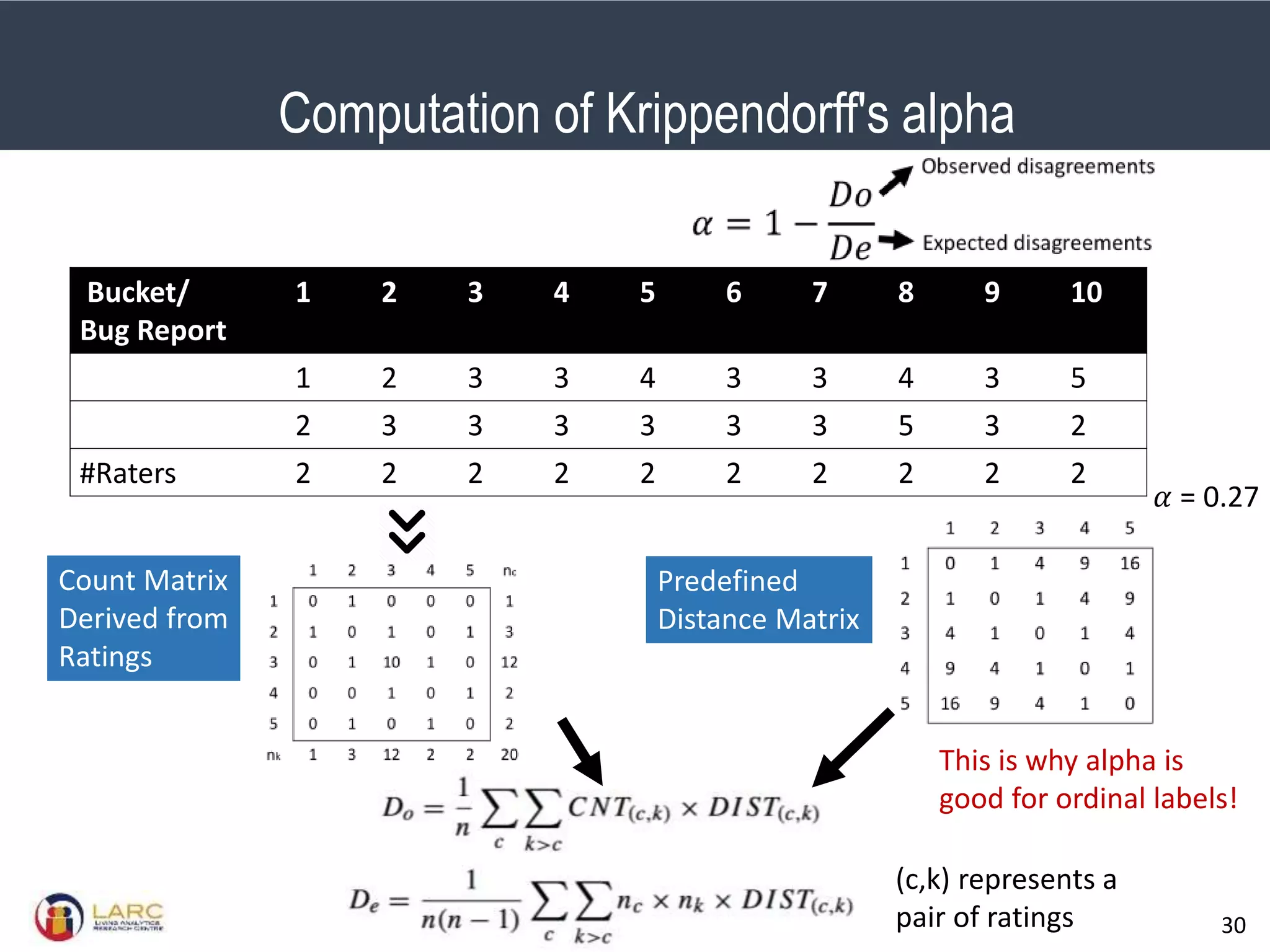
- A new evaluation metric called Krippendorff's alpha is proposed to measure agreement between labels while accounting for inconsistencies. It is shown to better reflect performance than accuracy when labels are inconsistent.
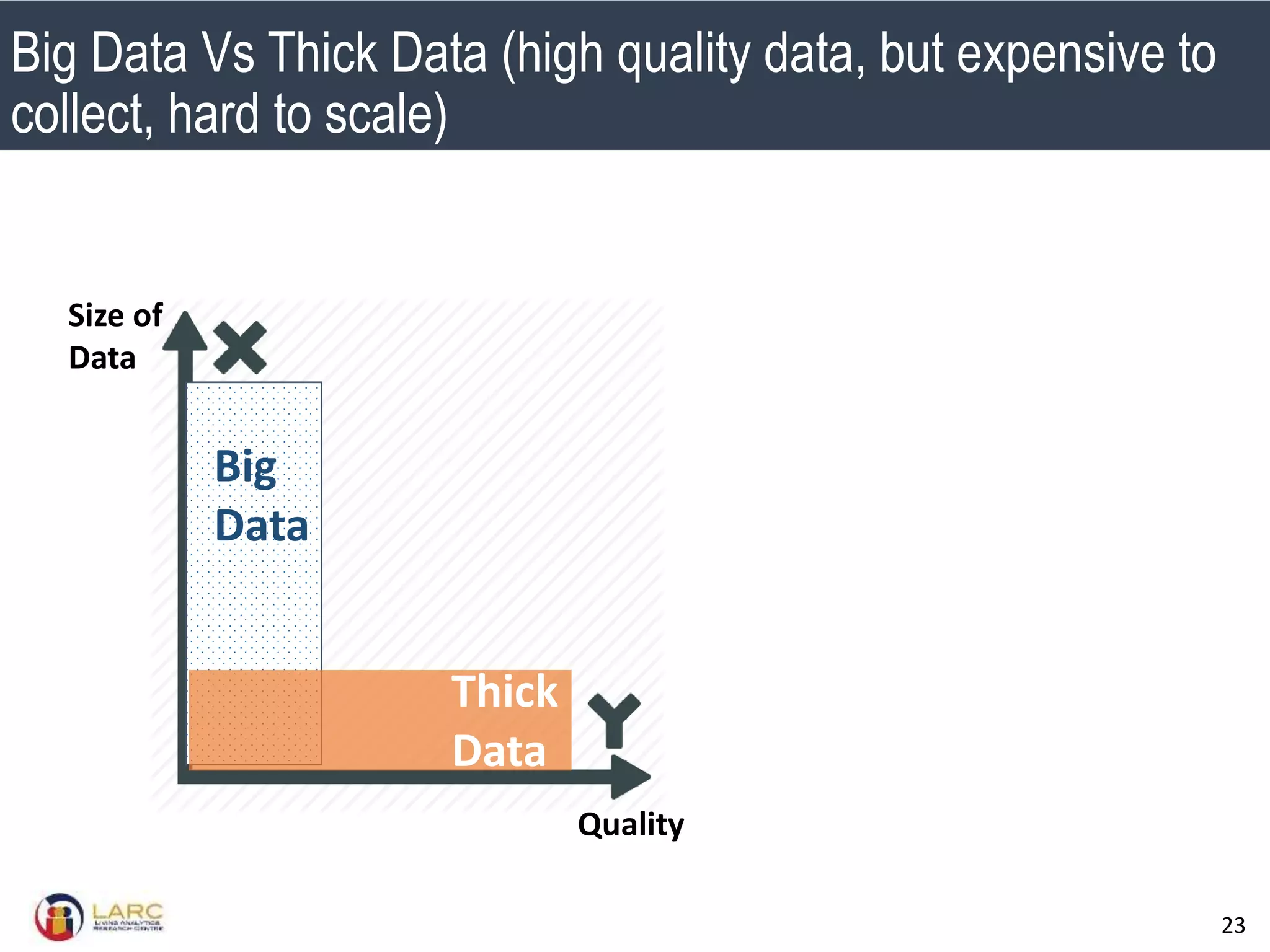
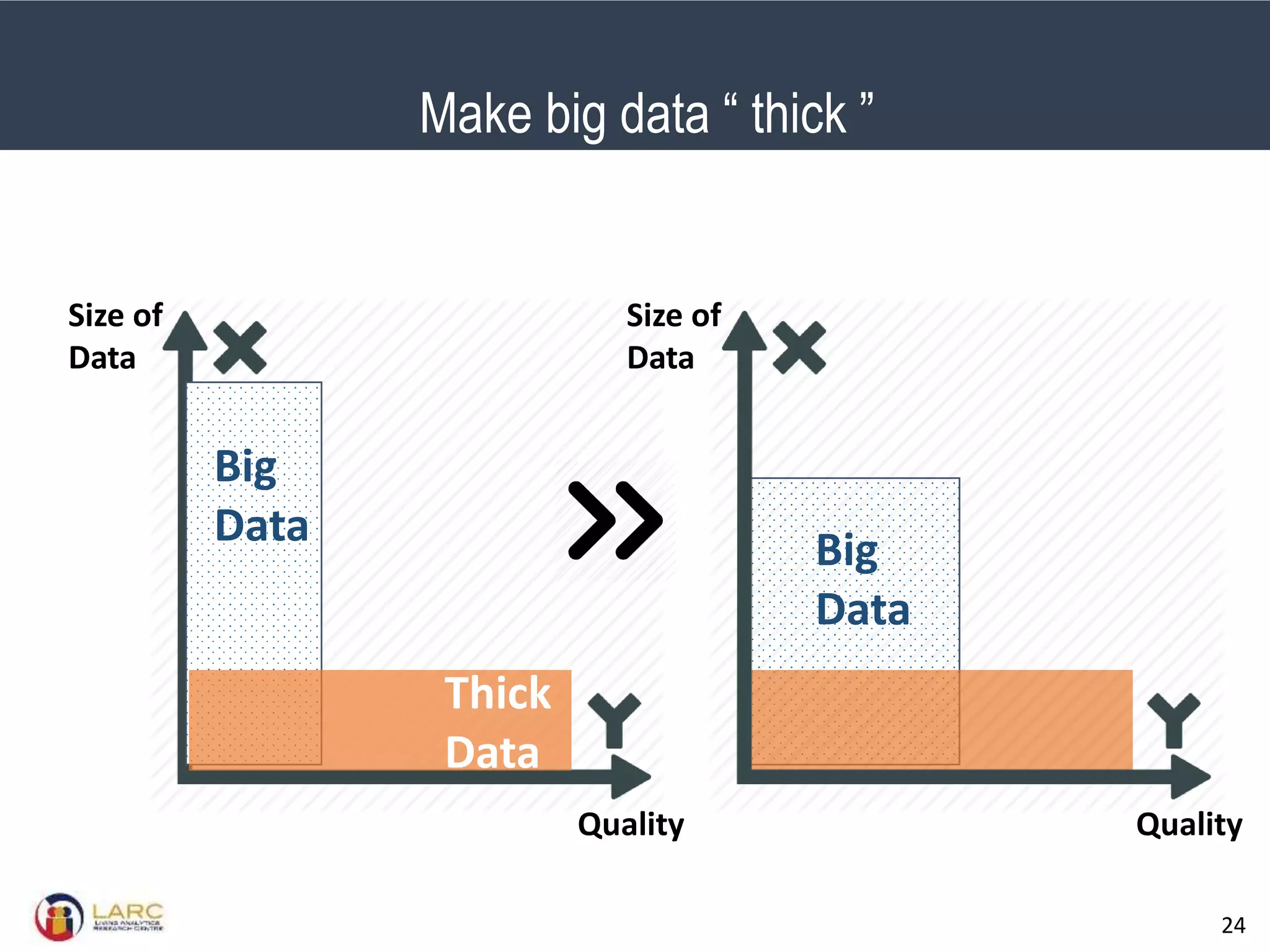
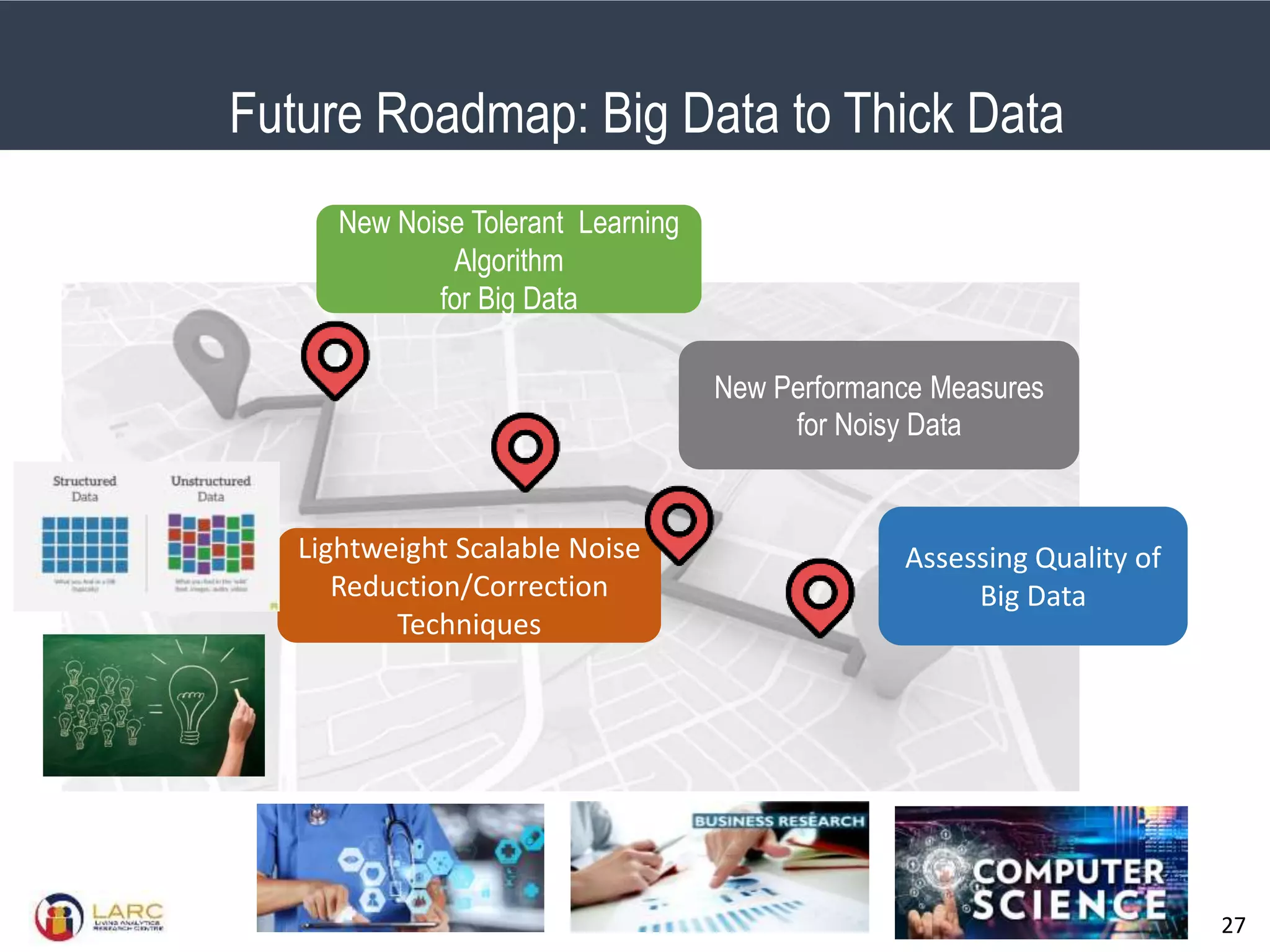
- Making "big data thick" by improving quality is an important future direction, but challenging at scale. Lightweight methods are needed to reduce noise without extensive manual labelling. Performance measures also need to account for noise inherent in some real-world problems.