Download to read offline




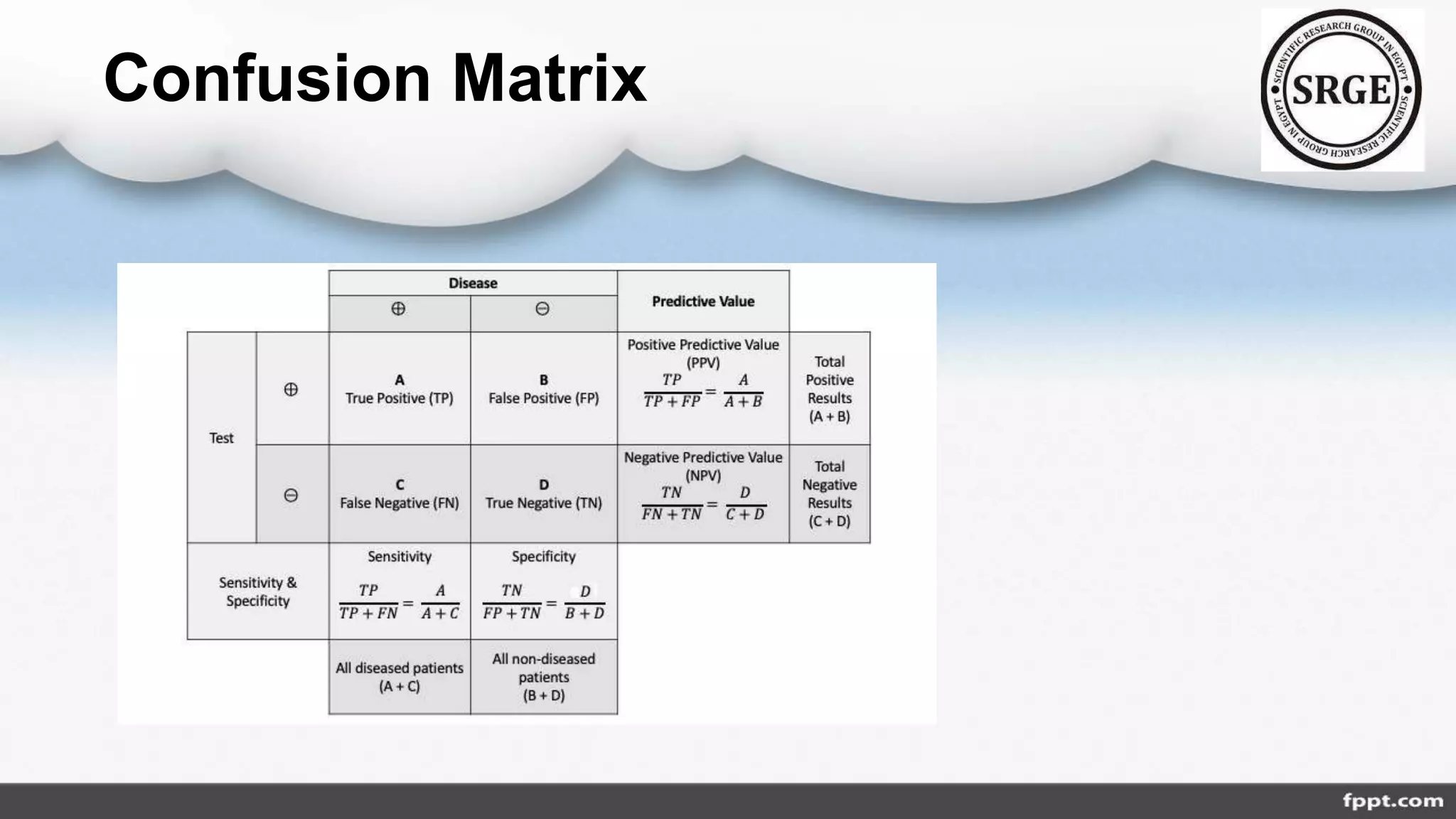









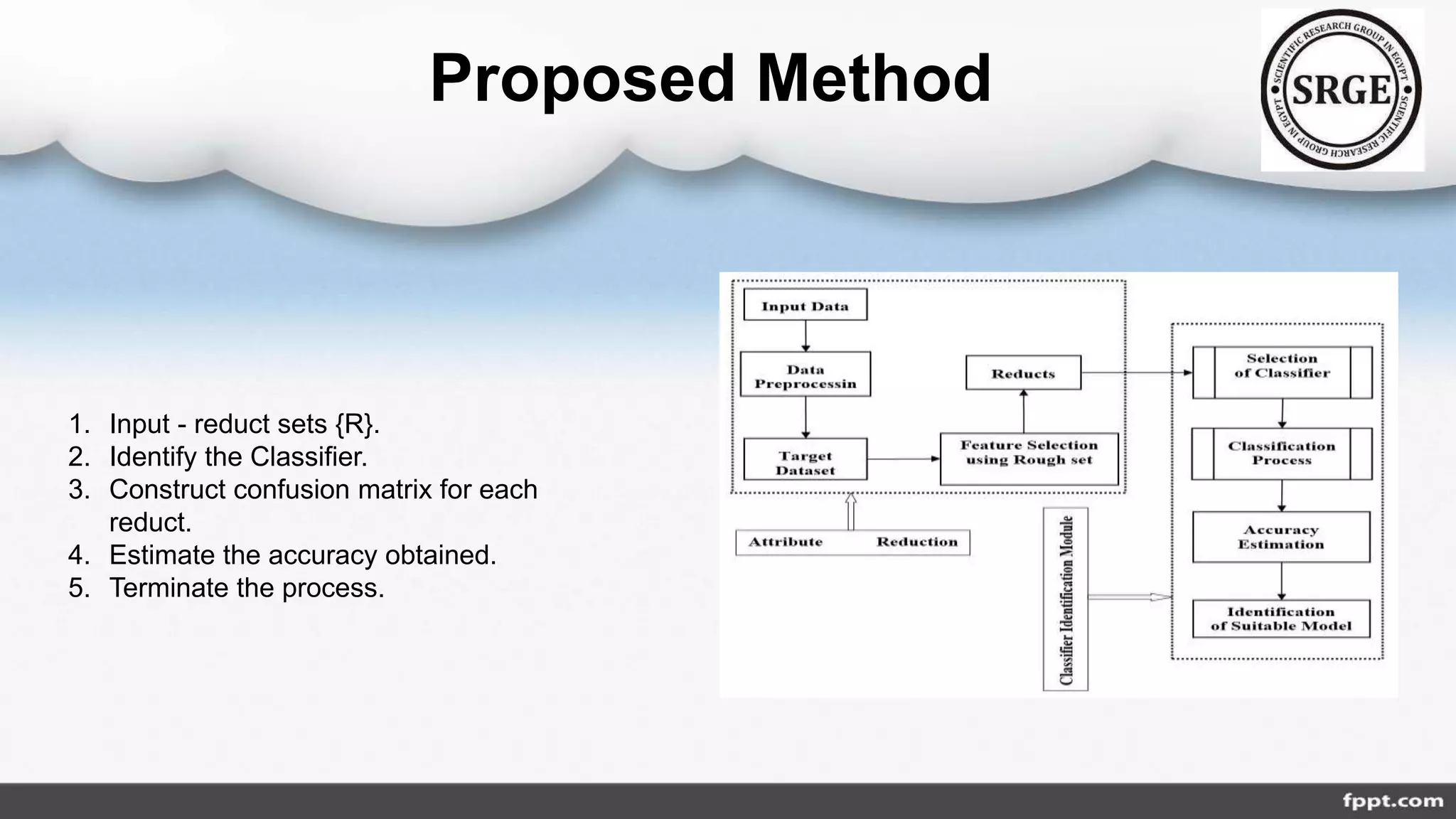


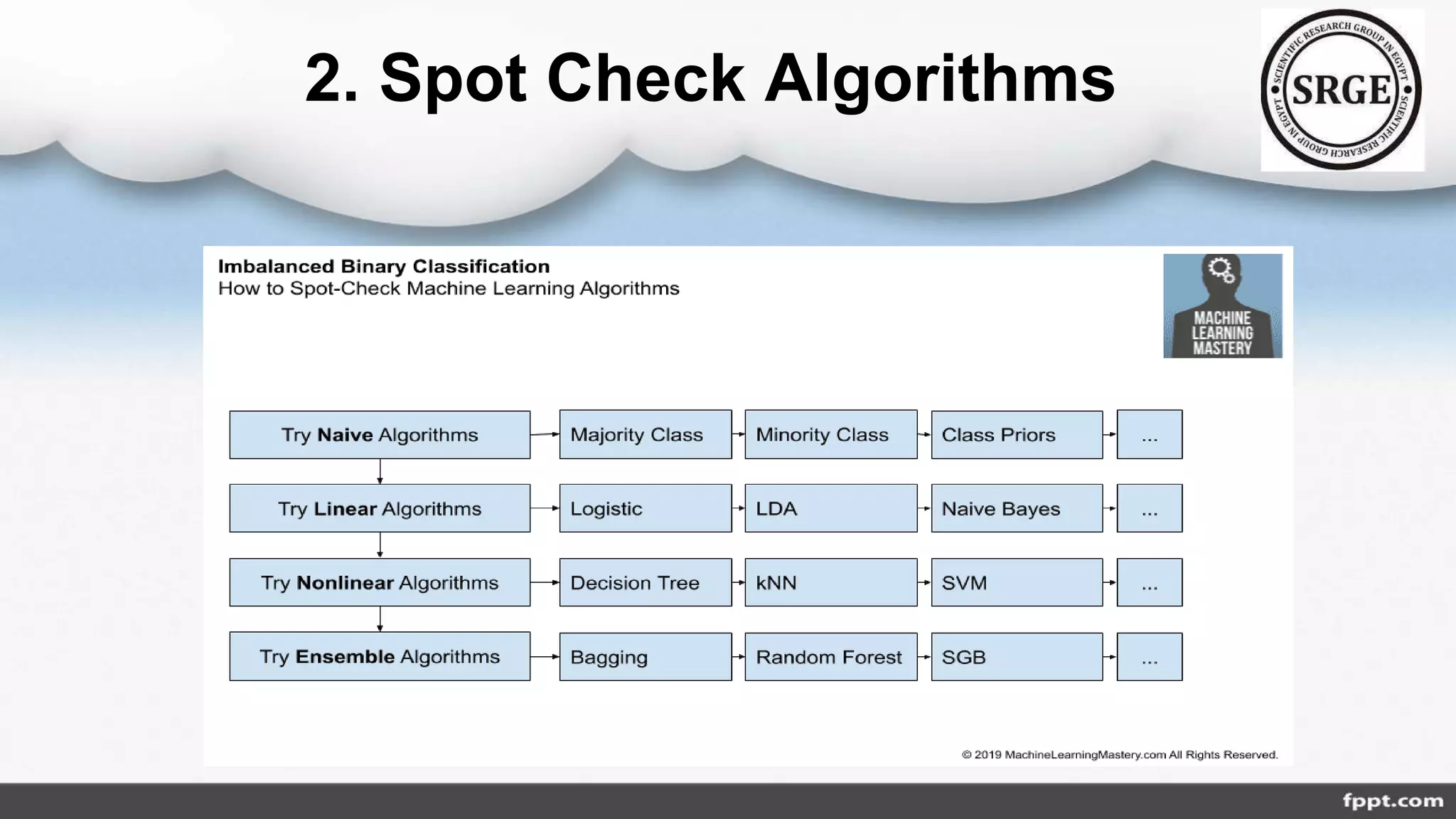




The document discusses the class imbalance problem in agricultural data analysis, highlighting its prevalence across various domains such as financial fraud and cancer detection. It presents approaches for addressing this issue, classified into data, algorithmic, ensemble, hybrid, and feature selection levels, while also detailing performance metrics like precision, recall, and F1 score. A proposed roadmap includes selecting metrics, checking algorithms, and hyper-parameter tuning to improve model accuracy and handling of imbalanced datasets.























































































