Downloaded 462 times



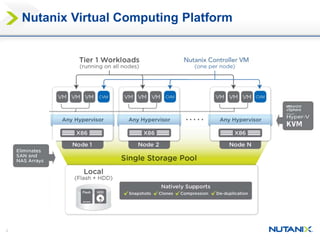
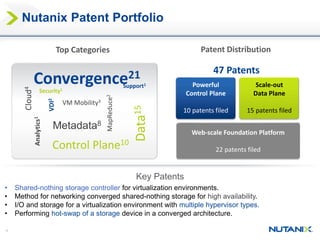
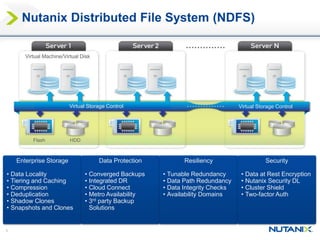

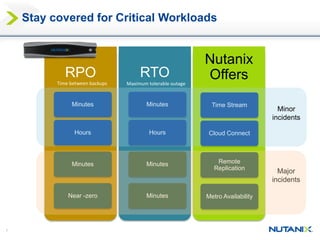
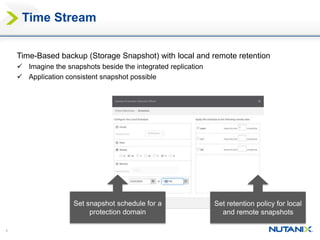
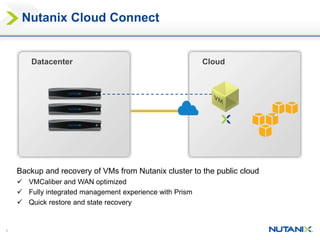
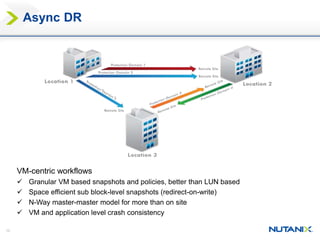


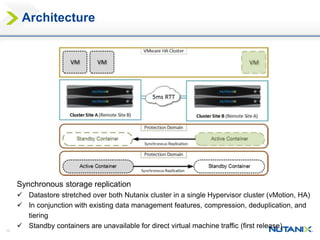
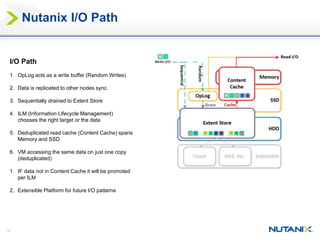
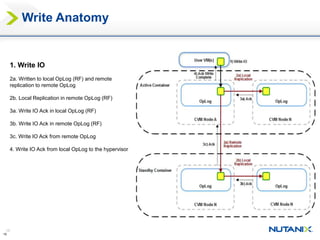
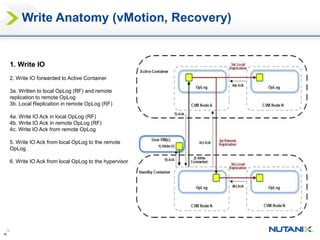
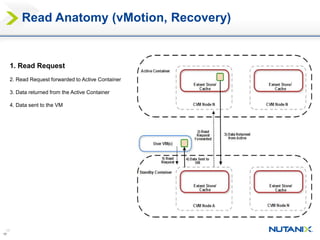
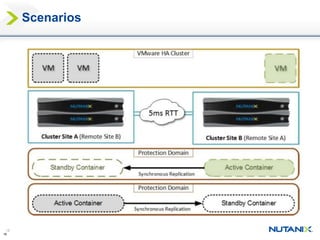
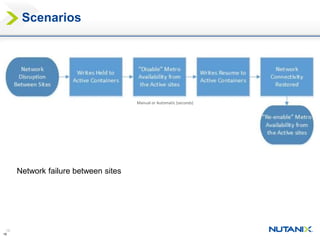
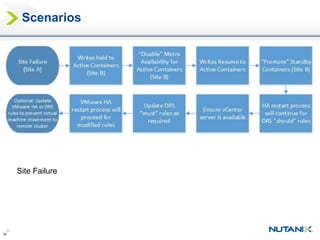



This document discusses Nutanix's Metro Availability feature, which provides geographic distributed high availability across an entire infrastructure stack. It leverages synchronous storage replication between two Nutanix clusters in different sites to provide redundancy. The architecture stretches data stores across both clusters so virtual machines can failover and migrate between sites. It requires less than 5ms latency and 400km or less of distance between sites.
















![[2018] 오픈스택 5년 운영의 경험](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra05-190131073350-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Webinar: Network Automation [Tips & Tricks]](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-nw-automation-august-2016-160901213303-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Event] Digital transformation : Enterprise cloud one os one click - PRESENTA...](https://cdn.slidesharecdn.com/ss_thumbnails/eventdigitaltransformation-enterprisecloudoneosoneclick-presentationnutanix-170922084203-thumbnail.jpg?width=640&height=640&fit=bounds)





















![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)






