
Download to read offline


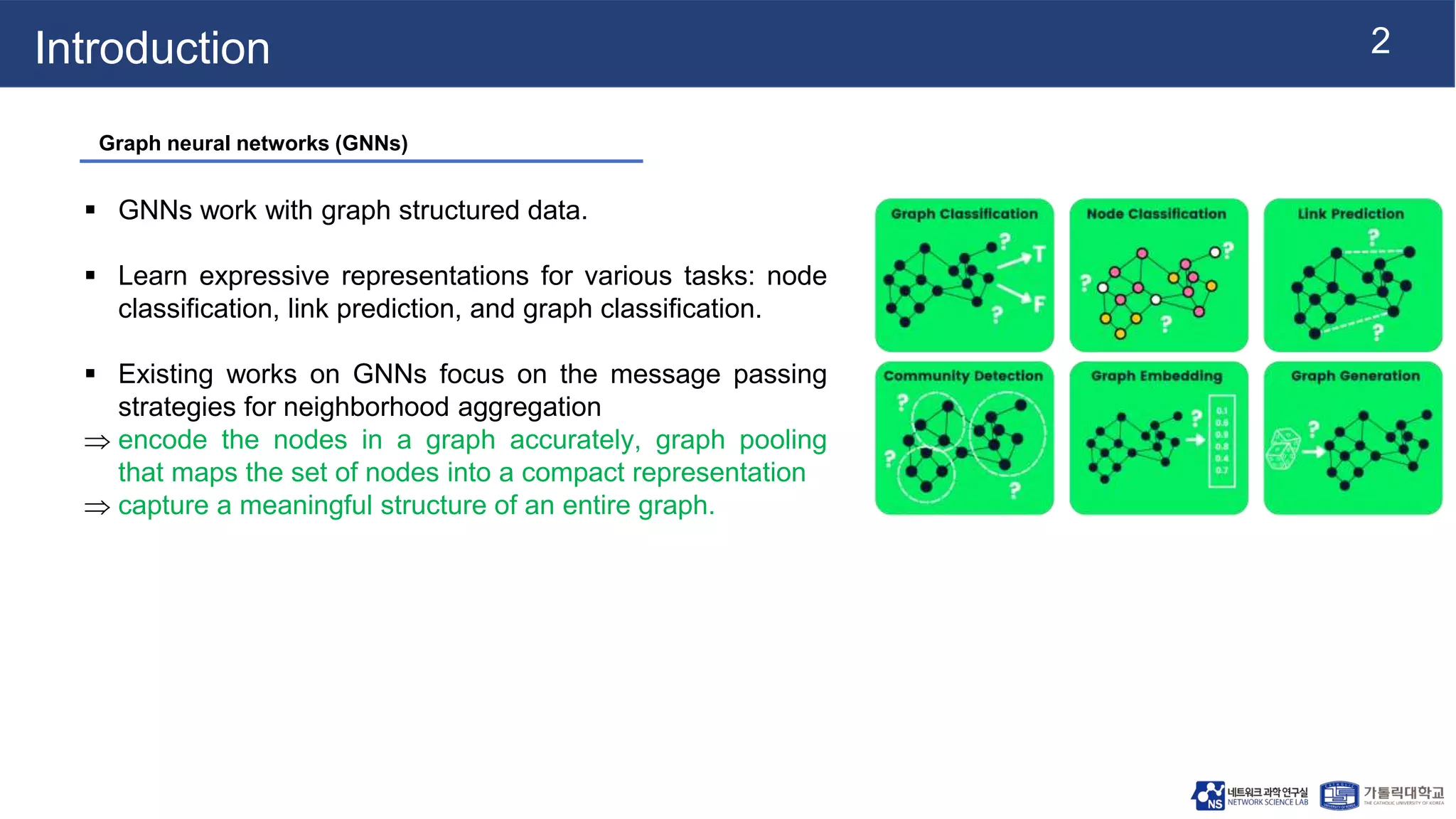
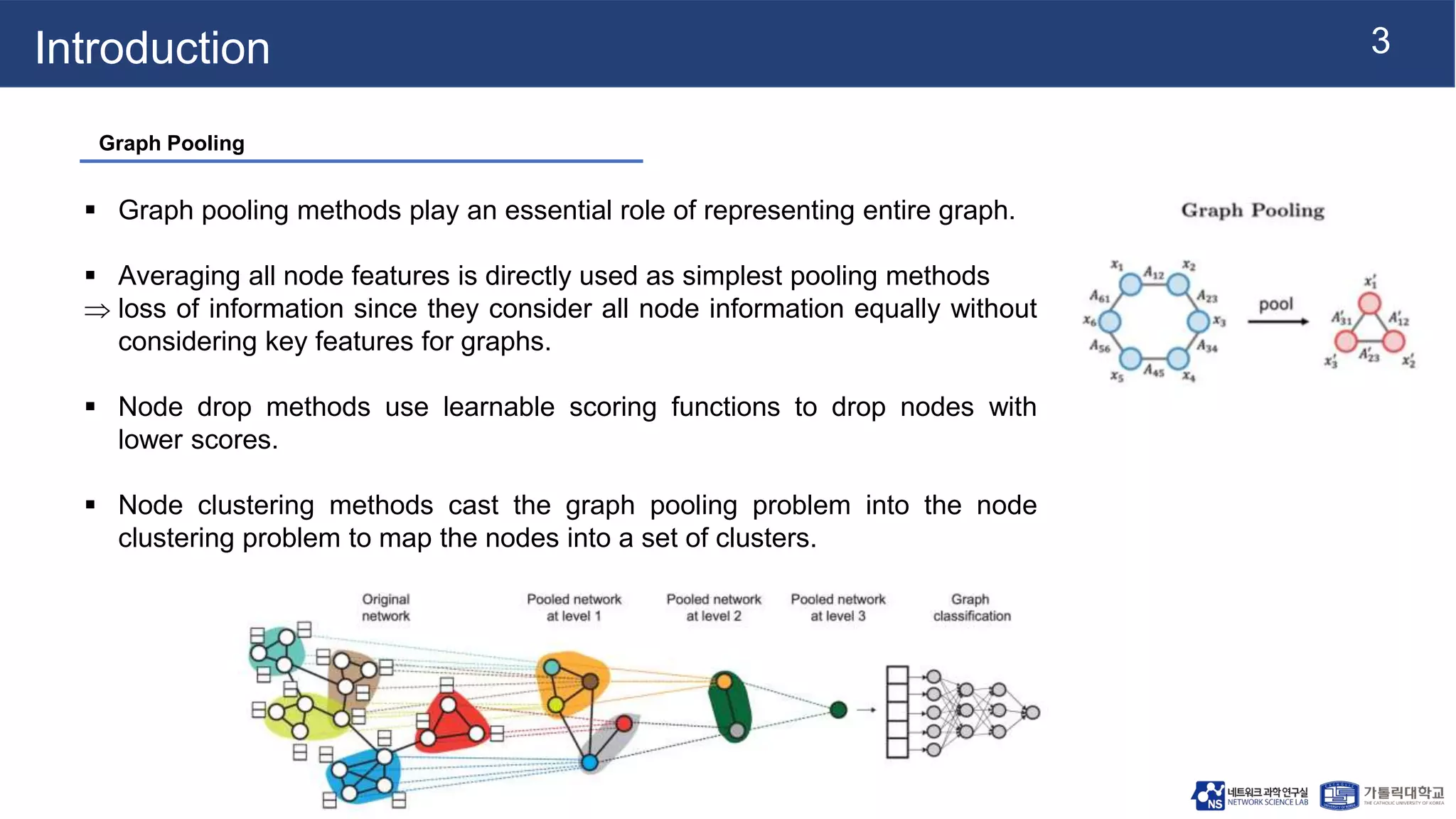
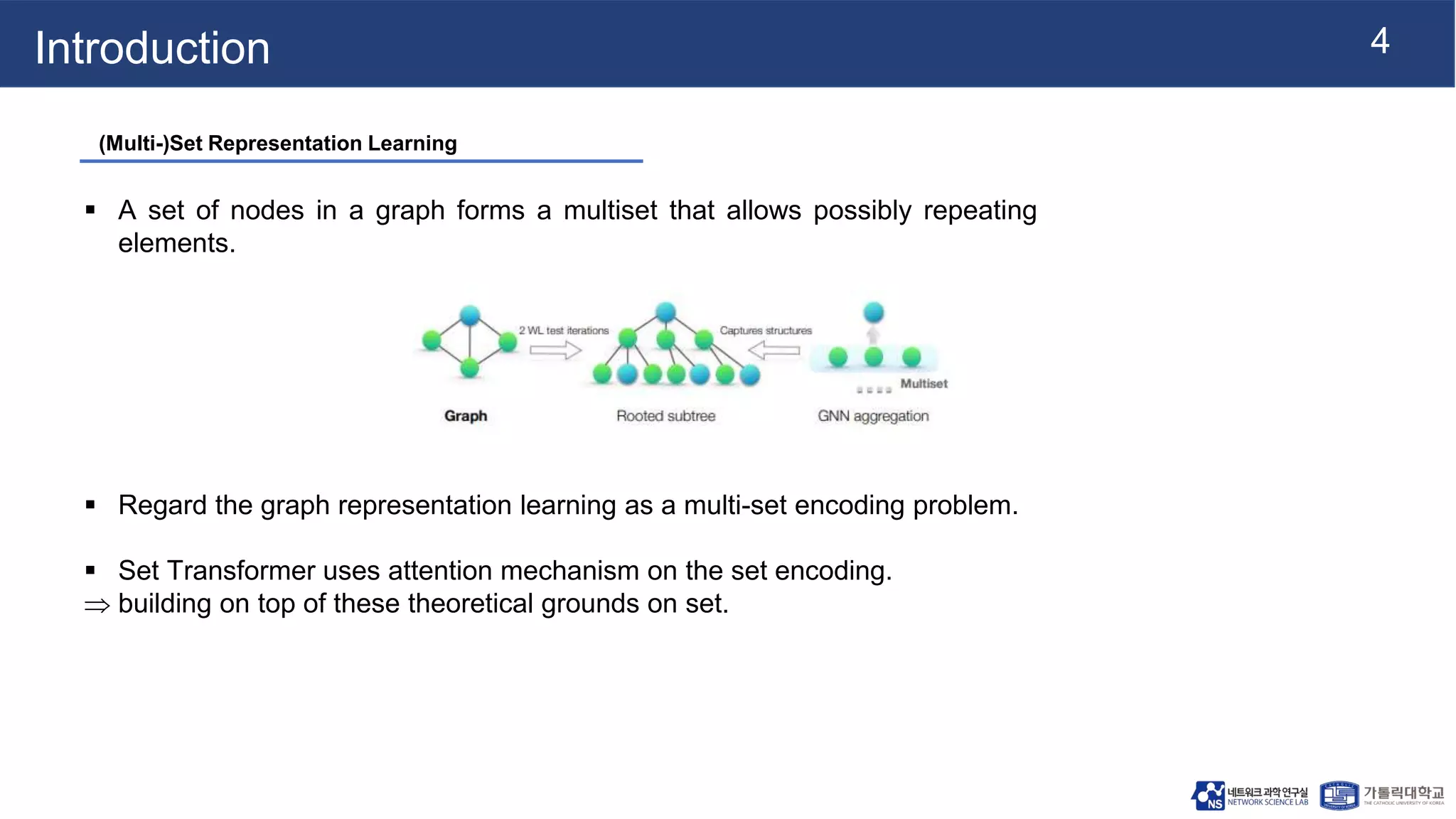
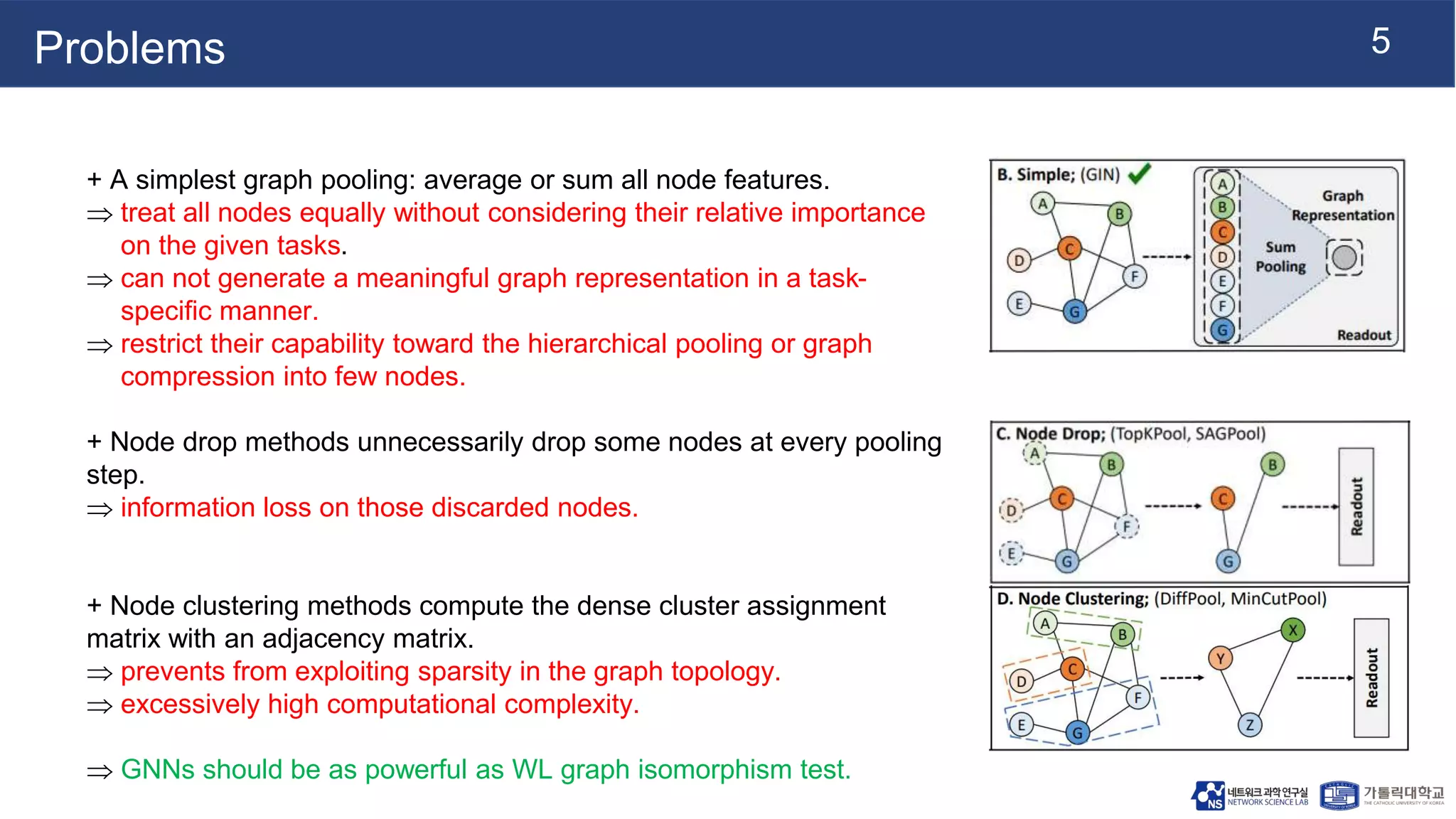

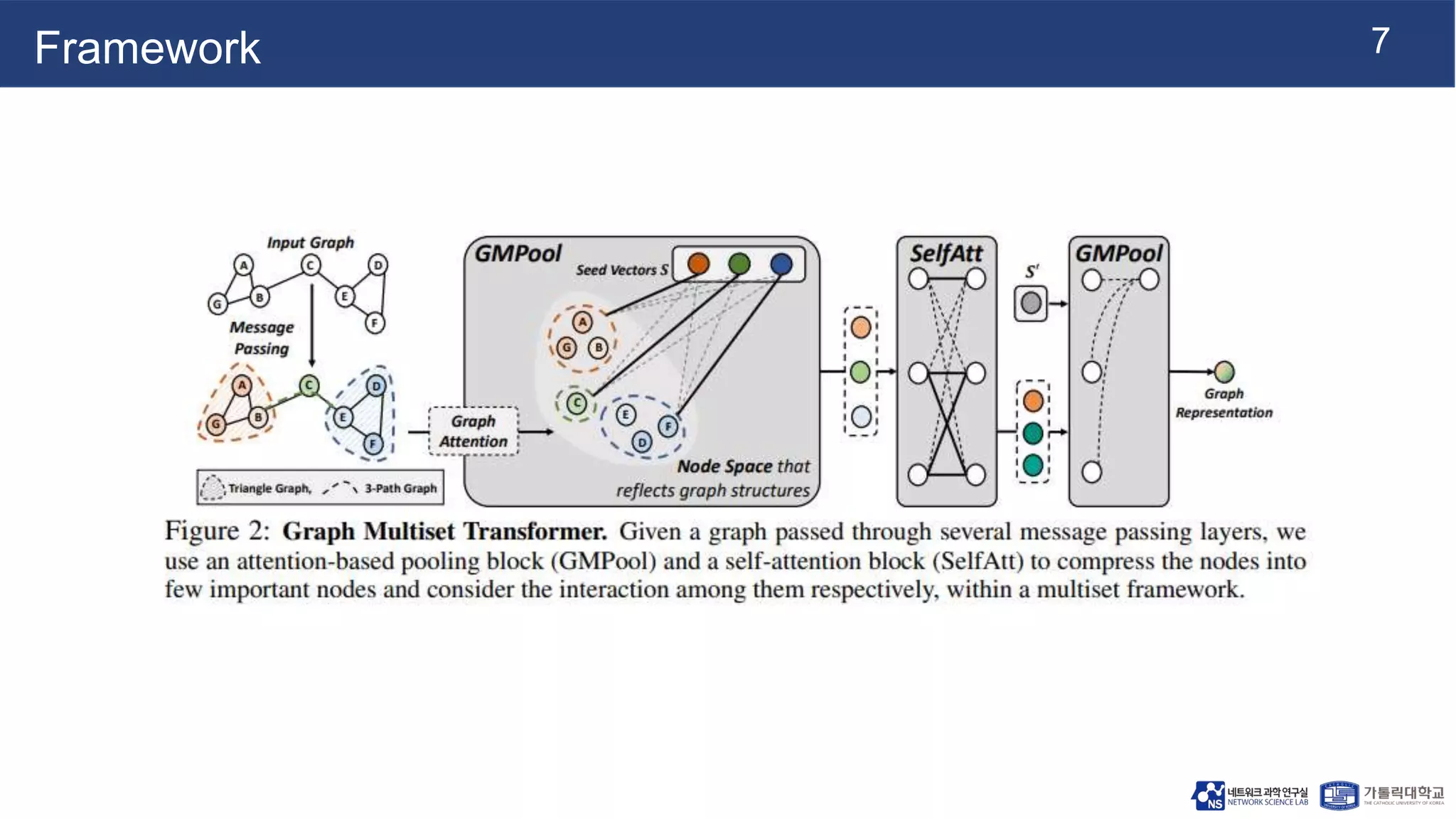






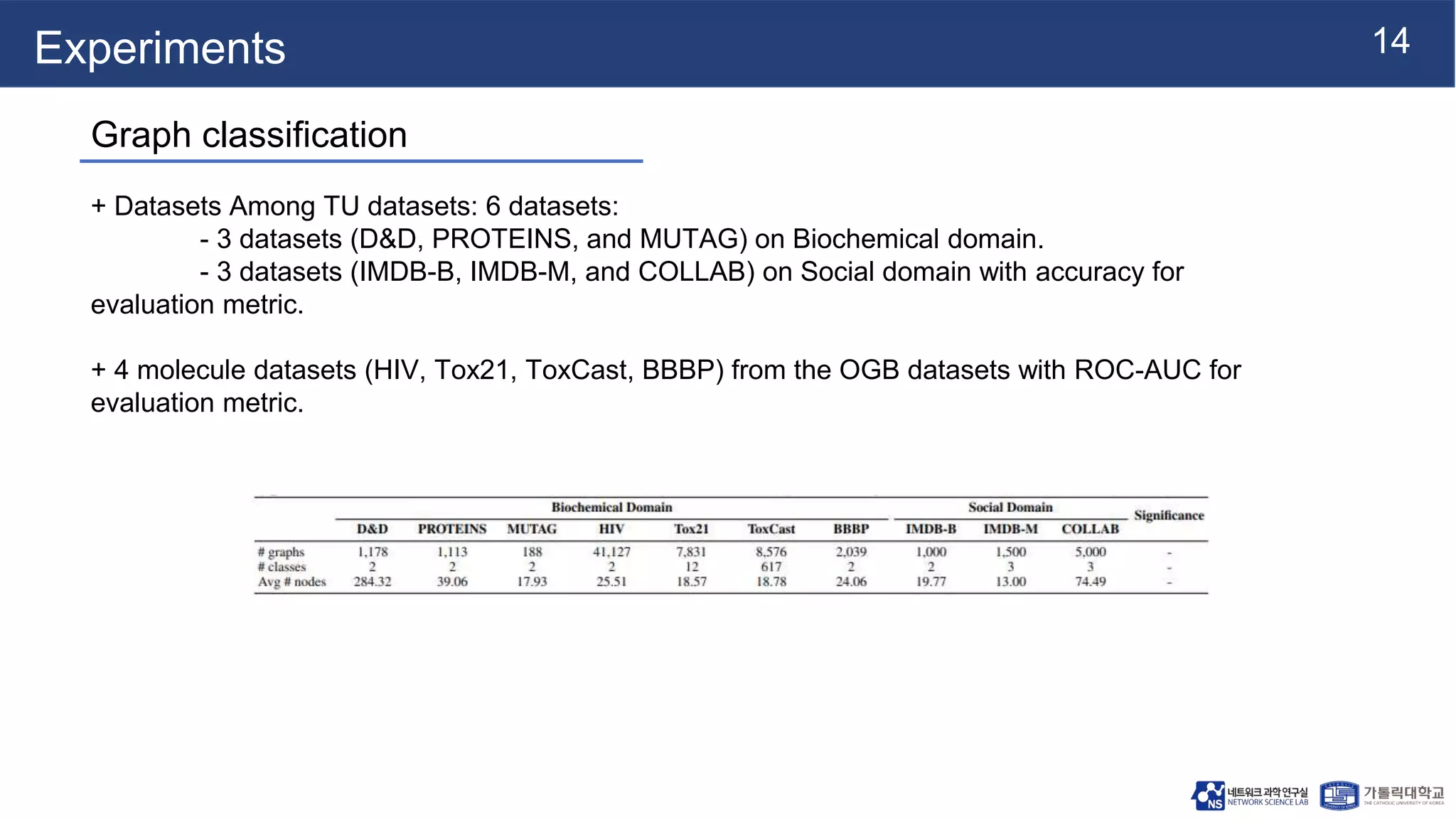
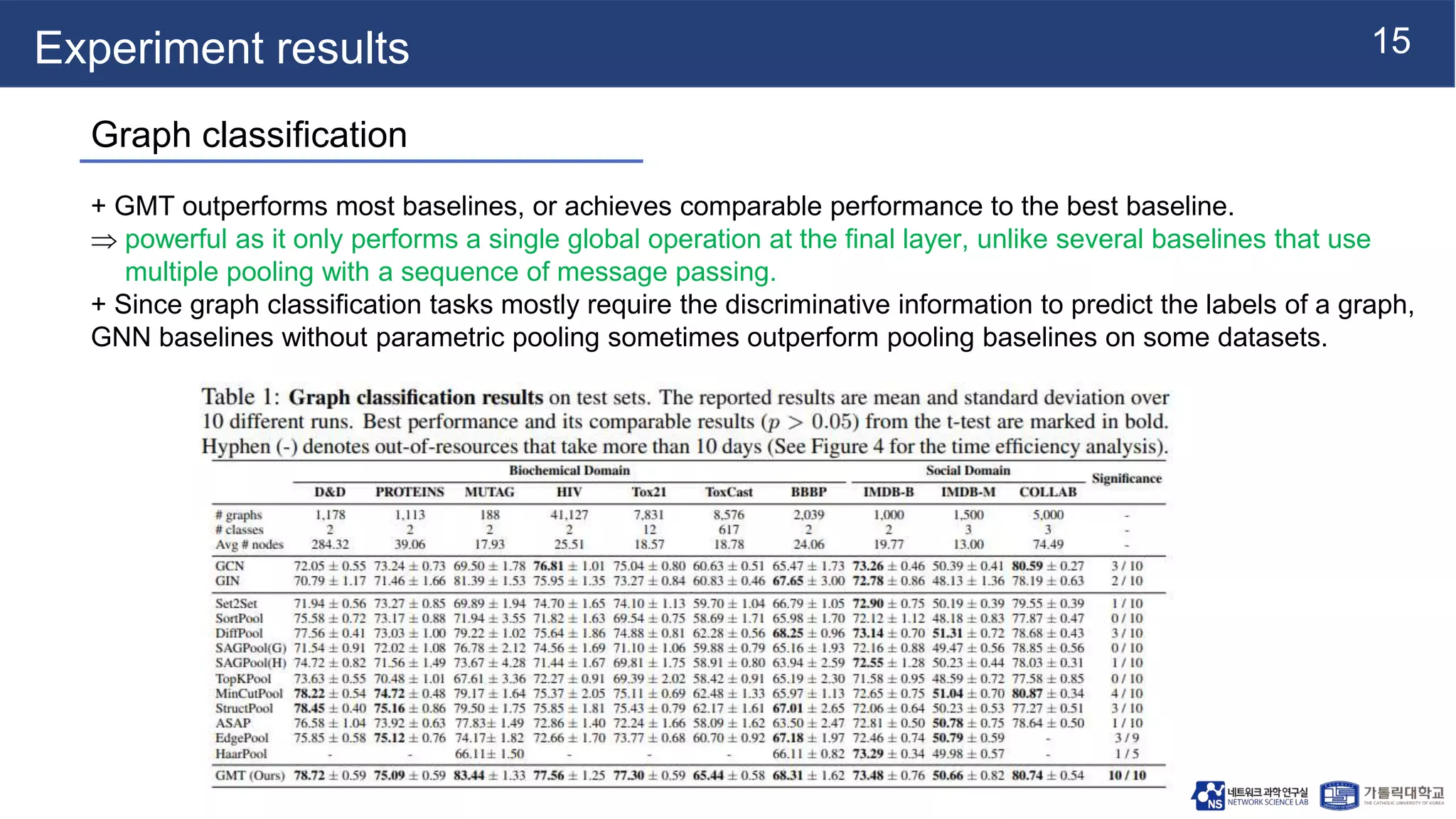
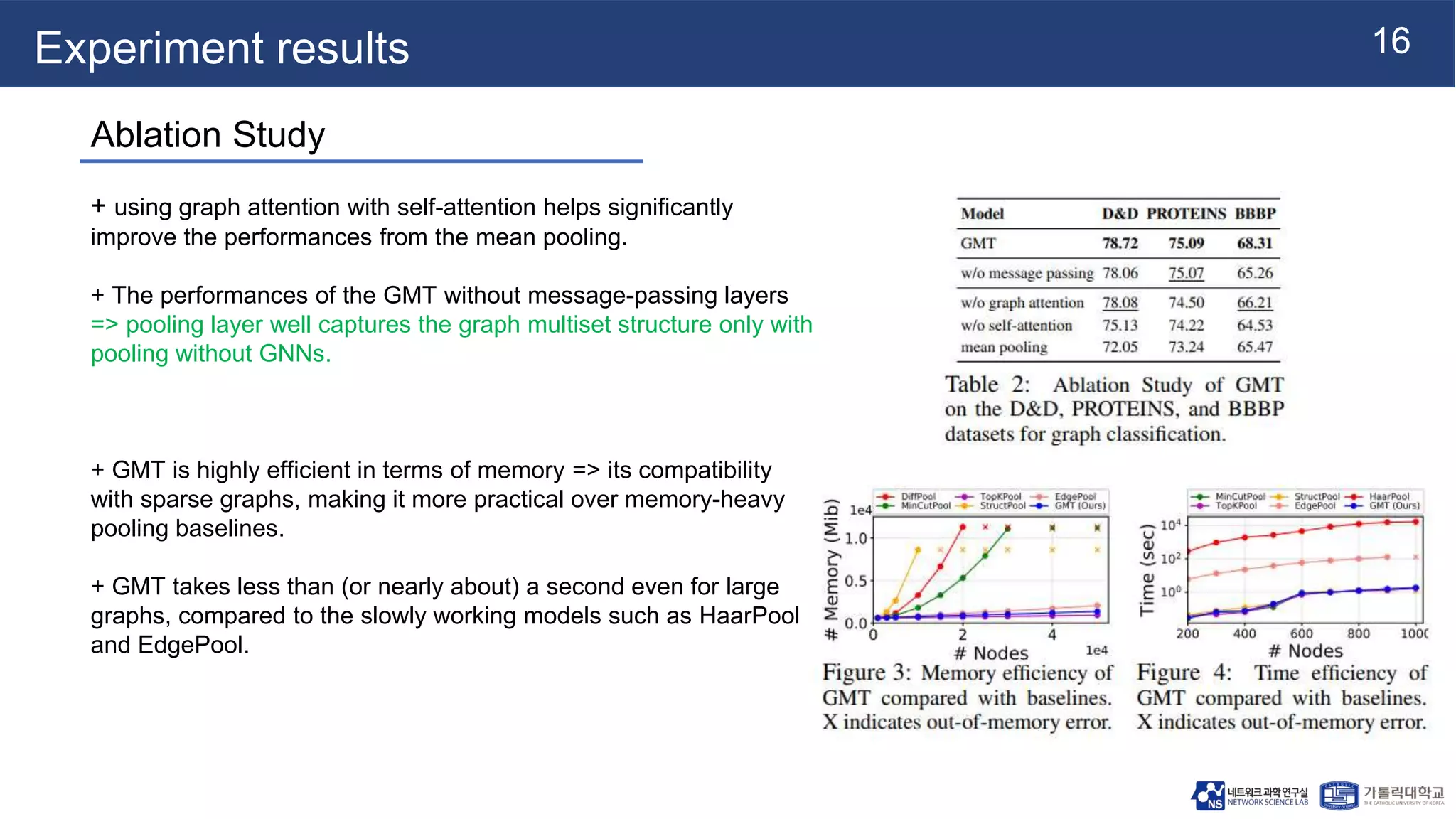




This document summarizes a research paper on Graph Multiset Pooling, a new method for graph pooling using a Graph Multiset Transformer (GMT). The GMT treats graph pooling as a multiset encoding problem and uses multi-head attention to capture relationships among nodes. It satisfies the injectiveness and permutation invariance properties needed to be as powerful as the Weisfeiler-Lehman graph isomorphism test. Experimental results show the GMT outperforms other pooling methods on tasks like graph classification, reconstruction, and generation. The GMT provides a powerful and efficient way to learn meaningful representations of entire graphs.




![240304_Thanh_LabSeminar[Pure Transformers are Powerful Graph Learners].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240304thanhlabseminartokengt-240409105926-a93f6988-thumbnail.jpg?width=640&height=640&fit=bounds)




![[NS][Lab_Seminar_250721]On Measuring Long-Range Interactions in Graph Neural ...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250721-250721114811-4cb18829-thumbnail.jpg?width=640&height=640&fit=bounds)
























































