


















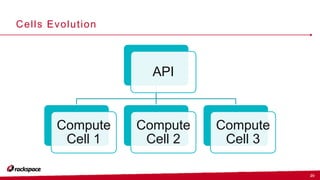







The document outlines updates and priorities for OpenStack Nova as discussed by John Garbutt during the OpenStack Ops Midcycle event in February 2016. Key focuses include a robust API, enhancements to the upgrade process, and the evolution of the API through microversions. It also addresses issues related to live migration and the architecture improvements aimed at maintaining system reliability and scalability.






































![[Enrico picciotto] fotos ator novela](https://cdn.slidesharecdn.com/ss_thumbnails/enrico-picciotto-fotos-ator-novela-160217181614-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[OpenStack Day in Korea 2015] Keynote 1 - OpenStack Mission Update](https://cdn.slidesharecdn.com/ss_thumbnails/01-150213032657-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






















